引言:
数据库的事务隔离级别相信很多同学都知道.MySQL默认的隔离级别为REPEATABLE READ(可重复读),其他大部分数据库的默认级别为READ COMMITTED(读已提交),但是大家有没有想过它是如何实现的呢?偷偷的翻了一些小本本后,先把我的理解写下来。。。。。
一:事务隔离级别
1, READ UNCOMMITTED(读未提交)
事务中的修改,即使没有提交,对其它事务也是可见的. 脏读(Dirty Read).
2, READ COMMITTED(读已提交)
一个事务开始时,只能"看见"已经提交的事务所做的修改. 这个级别有时候也叫不可重复读(nonrepeatable read).
3, REPEATABLE READ(可重复读)
该级别保证了同一事务中多次读取到的同样记录的结果是一致的. 但理论上,该事务级别还是无法解决另外一个幻读的问题(Phantom Read).
幻读: 当某个事务读取某个范围内的记录时,另外一个事务又在该范围内插入了新的记录.当之前的事务再次读取该范围时,会产生幻行.(Phantom Row).
幻读的问题理应由更高的隔离级别来解决,但mysql和其它数据库不一样,它同样在可重复读的隔离级别解决了这个问题.
也就是说, mysql的可重复读的隔离级别解决了 “不可重复读” 和 “幻读” 2个问题. 稍后我们可以看见它是如何解决的.
而oracle数据库,可能需要在 “SERIALIZABLE ” 事务隔离级别下才能解决 幻读问题.
4, SERIALIZABLE (可串行化)
强制事务串行执行,避免了上面说到的 脏读,不可重复读,幻读 三个的问题.
二:事务隔离级别的实现
2.1 引言
上篇已经说到Mysql隔离性的实现利用的是锁和MVCC机制。那么现在我们就来详细的分析一下Mysql是如何利用锁和MVCC机制来实现隔离性和隔离级别的。
2.1.1 MVCC(Multi-Version Concurrency Control) 多版本并发控制
MVCC的实现,是通过保存数据在某个时间点的快照来实现的.具体是通过版本链,Read View实现的。
InnoDB通过为每一行记录添加两个额外的隐藏的值来实现MVCC,这两个值一个记录这行数据何时被创建,另外一个记录这行数据何时过期(或者被删除)。但是InnoDB并不存储这些事件发生时的实际时间,相反它只存储这些事件发生时的系统版本号(LSN)。这是一个随着事务的创建而不断增长的数字。每个事务在事务开始时会记录它自己的系统版本号。每个查询必须去检查每行数据的版本号与事务的版本号是否相同。
MVCC最大的作用是: 实现了非阻塞的读操作,写操作也只锁定了必要的行.
MYSQL的MVCC 只在 read committed 和 repeatable read 2个隔离级别下工作.
2.1.1.1 版本链(数据库隔离性的实现)

每个事务都有自己的版本,各自操作各自的,就实现了数据库的隔离性。
2.1.1.2 readview(数据库隔离级别的实现)


2.1.2 Mysql所使用到的锁
行级别的锁:
共享锁:读锁(S锁)
排他锁:写锁(X锁)
Record Lock(行锁): 单个行记录的锁
GAP Lock(间隙锁):锁定一个范围,但不包含记录本身.
Next-Key Lock( Gap Lock+Record Lock): 锁定一个范围并锁定记录本身.
表级别的锁:锁定整个表
在对某个表执行Select,Insert,Delete,Update语句时,InnoDB存储引擎是不会为这个表添加表级别锁的。
在对某个表执行Alter Table, Drop Table这些DDL语句时,其他事务对这个表执行Select,Insert,Delete,Update
语句会发生阻塞,或者某个事务对某个表执行Select,Insert,Delete,Update语句时,另外一个事务对这个执行DDL语句也是发生阻塞。这个过程是使用的元数据锁(MDL)来实现的。使用的表级别的S锁和X锁。
LOCK TABLES T1 READ :对表T1加表级别的S锁。
LOCK TABLES T1 WRITE :对表T1加表级别的X锁。
注:尽量不用这两种方式去加锁,因为InnoDB的优点就是行锁,所以尽量使用行锁,性能更高。
IS锁(意向共享锁):当事务准备在某条记录上加S锁(行级)时,需要在表级别加上一个IS锁。
IX锁(意向排他锁):当事务准备在某条记录上加X锁(行级)时,需要在表级别加上一个IX锁。
IS, IX是表级锁,他们的提出仅仅为了在之后加表级别的S锁和X锁时可以快速判断表中是否有行锁(如果没有此优化,那么每当需要加表级别的S锁和X锁时,遍历全表查看是否存在行锁,这样的效率是相当低下的!)。
注 : READ UNCOMMITTED(读未提交), SERIALIZABLE (可串行化)就不谈了。。。。。
2.2 READ COMMITTED(读已提交)的实现原理
该事务隔离级别解决了—脏读问题
脏读解决方式:


这样的处理虽然解决了读已提交,但是未解决还未结束的事务读取其他事务已经提交修改的数据(某条数据不可重复读的问题)。
2.3 REPEATABLE READ(可重复读)的实现原理
该事务隔离级别解决了—脏读,不可重复读,幻读问题
脏读,不可重复读解决方式:


这样就解决了某条数据不可重复读的问题。
幻读解决方式:
通过Next-Key Lock( Gap Lock+Record Lock)范围锁解决幻读
具体实现另叙。。。。。。
案例分析:REPEATABLE READ隔离级别下,MVCC具体是如何操作的.
简单小例子
create table yang(
id int primary key auto_increment,
name varchar(20));
假设系统的版本号从1开始.
INSERT
InnoDB为新插入的每一行保存当前系统版本号作为版本号.
第一个事务ID为1;
开启事务;
insert into yang values(NULL,'yang') ;
insert into yang values(NULL,'long');
insert into yang values(NULL,'fei');
commit;
对应在数据中的表如下(后面两列是隐藏列,我们通过查询语句并看不到)

SELECT
InnoDB会根据以下两个条件检查每行记录:
a.InnoDB只会查找版本早于当前事务版本的数据行(也就是,行的系统版本号小于或等于事务的系统版本号),这样可以确保事务读取的行,要么是在事务开始前已经存在的,要么是事务自身插入或者修改过的.
b.行的删除版本要么未定义,要么大于当前事务版本号,这可以确保事务读取到的行,在事务开始之前未被删除.
只有a,b同时满足的记录,才能返回作为查询结果.
DELETE
InnoDB会为删除的每一行保存当前系统的版本号(事务的ID)作为删除标识.
看下面的具体例子分析:
第二个事务,ID为2;
start transaction;
select * from yang; //(1)
select * from yang; //(2)
commit;
假设1
假设在执行这个事务ID为2的过程中,刚执行到(1),这时,有另一个事务ID为3往这个表里插入了一条数据;
第三个事务ID为3;
start transaction;
insert into yang values(NULL,'tian');
commit;
这时表中的数据如下:
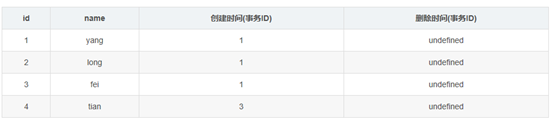
然后接着执行事务2中的(2),由于id=4的数据的创建时间(事务ID为3),执行当前事务的ID为2,而InnoDB只会查找事务ID小于等于当前事务ID的数据行,所以id=4的数据行并不会在执行事务2中的(2)被检索出来,在事务2中的两条select 语句检索出来的数据都只会下表:

假设2
假设在执行这个事务ID为2的过程中,刚执行到(1),假设事务执行完事务3后,接着又执行了事务4;
第四个事务:
start transaction;
delete from yang where id=1;
commit;
此时数据库中的表如下:
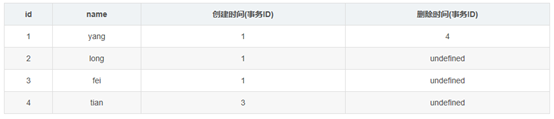
接着执行事务ID为2的事务(2),根据SELECT 检索条件可以知道,它会检索创建时间(创建事务的ID)小于当前事务ID的行和删除时间(删除事务的ID)大于当前事务的行,而id=4的行上面已经说过,而id=1的行由于删除时间(删除事务的ID)大于当前事务的ID,所以事务2的(2)select * from yang也会把id=1的数据检索出来.所以,事务2中的两条select 语句检索出来的数据都如下:

UPDATE
InnoDB执行UPDATE,实际上是新插入了一行记录,并保存其创建时间为当前事务的ID,同时保存当前事务ID到要UPDATE的行的删除时间.
假设3
假设在执行完事务2的(1)后又执行,其它用户执行了事务3,4,这时,又有一个用户对这张表执行了UPDATE操作:
第5个事务:
start transaction;
update yang set name='Long' where id=2;
commit;
根据update的更新原则:会生成新的一行,并在原来要修改的列的删除时间列上添加本事务ID,得到表如下:
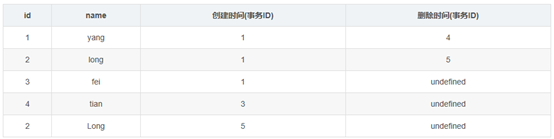
继续执行事务2的(2),根据select 语句的检索条件,得到下表:

还是和事务2中(1)select 得到相同的结果.
MVCC总结

理想的MVCC和InnoDB所实现的MVCC的区别:
根据各种策略读取时非阻塞就是MVCC,undo log中的行就是MVCC中的多版本,这个可能与我们所理解的MVCC有较大的出入
一般我们认为MVCC有下面几个特点:
1.每行数据都存在一个版本,每次数据更新时都更新该版本
2.修改时Copy出当前版本随意修改,各个事务之间无干扰
3.保存时比较版本号,如果成功(commit),则覆盖原记录;失败则放弃copy(rollback)
就是每行都有版本号,保存时根据版本号决定是否成功,听起来含有乐观锁的味道,
而Innodb的实现方式是:
1.事务以排他锁的形式修改原始数据
2.把修改前的数据存放于undo log,通过回滚指针与主数据关联
3.修改成功(commit)啥都不做,失败则恢复undo log中的数据(rollback)
二者最本质的区别是,当修改数据时是否要排他锁定,如果锁定了还算不算是MVCC?
Innodb的实现真算不上MVCC,因为并没有实现核心的多版本共存,undo log中的内容只是串行化的结果,记录了多个事务的过程,不属于多版本共存。但理想的MVCC是难以实现的,当事务仅修改一行记录使用理想的MVCC模式是没有问题的,可以通过比较版本号进行回滚;但当事务影响到多行数据时,理想的MVCC据无能为力了。
比如,如果Transaciton1执行理想的MVCC,修改Row1成功,而修改Row2失败,此时需要回滚Row1,但因为Row1没有被锁定,其数据可能又被Transaction2所修改,如果此时回滚Row1的内容,则会破坏Transaction2的修改结果,导致Transaction2违反ACID。 理想MVCC难以实现的根本原因在于企图通过乐观锁代替二段提交。修改两行数据,但为了保证其一致性,与修改两个分布式系统中的数据并无区别,而二提交是目前这种场景保证一致性的唯一手段。二段提交的本质是锁定,乐观锁的本质是消除锁定,二者矛盾,故理想的MVCC难以真正在实际中被应用,Innodb只是借了MVCC这个名字,提供了读的非阻塞而已。
