# -*- coding:utf-8 -*- """ author:Mr Yang data:2019/09/26 """ import itchat import matplotlib.pyplot as plt import matplotlib import os import re import numpy as np from PIL import Image from wordcloud.wordcloud import WordCloud class WeiXinAnalyze(): def __init__(self): self.sex_dict = {} self.city_dict = {} self.self_nickname = '' self.wordList = [] self.save_path = 'result' def wx_login(self): """微信登录及数据统计方法""" itchat.login() data = itchat.get_friends(update=True) self.self_nickname = data[0]['NickName'] # 获取此微信昵称 for item in data: sex = item.get('Sex') # 性别 province = item.get('Province') # 省份 city = item.get('City') # 城市 if sex or sex == 0: if sex not in self.sex_dict: self.sex_dict[sex] = 1 else: self.sex_dict[sex] += 1 if province and city: address = '-'.join([province, city]) if address not in self.city_dict: self.city_dict[address] = 1 else: self.city_dict[address] += 1 if item["Signature"]: signature = re.sub(r'<span.*</span>', '', item["Signature"]).strip().replace('\n', '') self.wordList.append(signature) if not os.path.exists(self.save_path): os.mkdir(self.save_path) def get_sex_info(self): """分析性别方法""" sex_dict = {} sex_dict['男'], sex_dict['女'], sex_dict['其它'] = self.sex_dict.pop(1), self.sex_dict.pop(2), self.sex_dict.pop(0) # 数据准备 data = sex_dict.items() labels = [i[0] for i in data] nums = [i[1] for i in data] # 使用Matplotlib画出饼图 matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 使用指定的汉字字体类型(此处为黑体) plt.title('微信好友性别统计({})'.format(self.self_nickname)) plt.pie(x=nums, labels=labels, autopct='%1.2f%%') plt.savefig(os.path.join(self.save_path,'wx_sex_data.png')) def get_address_info(self): """分析地址方法""" data = self.city_dict.items() sort_data = sorted(data, key=lambda i: i[1], reverse=True)[:20] x = [i[0] for i in sort_data] y = [i[1] for i in sort_data] matplotlib.rcParams['font.sans-serif'] = ['SimHei'] fig, ax = plt.subplots() rects = ax.barh(x, y, color='greenyellow', align="center") ax.set_yticks(x) # 设置标度的位置 ax.set_yticklabels(x) # 设置纵坐标的每一个刻度的属性值 ax.invert_yaxis() # 反转标度值 ax.set_xlabel('人数(位)') # 设置横坐标的单位 ax.set_title('微信好友所在城市统计({})'.format(self.self_nickname)) # 设定图片的标题 for rect, y, num in zip(rects, x, y): x = rect.get_width() plt.text(x + 0.05, y, "%d" % int(num)) plt.savefig(os.path.join(self.save_path,'wx_address_data.png')) def wx_ciyun(self): """微信词云方法""" text = " ".join(self.wordList) # 获取当前文件的执行路径 src_dir = os.getcwd() # 生成词云形状的图片地址 imagePath = os.path.join(src_dir , "timg.jpg") # 生成词云字体地址(防止中文乱码) font = os.path.join(src_dir ,"SimHei.ttf") # 生成的词云图地址 resultPath = os.path.join(self.save_path,'wx_ciyun.png') # 开始生成图片 bg = np.array(Image.open(imagePath)) wc = WordCloud( mode='RGBA', # 设置透明底色 mask=bg, # 造型遮盖 background_color="white", # 背景颜色 max_font_size=80, # 字体最大值 min_font_size=10, # 字体最小值 max_words=5000, # 词云显示的最大词数 random_state=100, # 设置有多少种随机生成状态,即有多少种配色方案 font_path=font, # 设置字体 ).generate(text) wc.to_file(resultPath) if __name__ == '__main__': weixin = WeiXinAnalyze() weixin.wx_login() weixin.get_sex_info() weixin.get_address_info() weixin.wx_ciyun()
最后看结果:

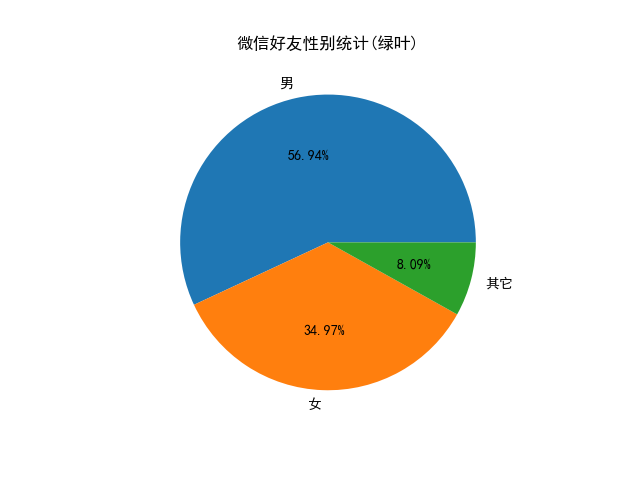

好累,第一次接触数据分析。