一直都想搞明白printf("HelloWorld!\n")是怎么在屏幕上打印出来的,所以趁着中秋节尽可能的深挖一下。这篇文章会保持持续的更新。
1. 编译链接阶段
1.1 预处理
首先,我们编写如下程序并命名为main.c。
#include <stdio.h>
int main(int argc,char **argv()){
printf("HelloWorld!\n");
return 0;
}
输入gcc -E main.c -o main.i 进行预处理工作,在此处,选项"-o"是指输出目标文件为main.i
预编译的处理规则:
将所有的 “#define” 删除,并展开所有的宏定义
处理所有的条件预编译指令,比如:" #if #ifdef #elif #else #endif "
处理所有的 “#include” 预编译指令
删除所有的注释 “//” 、 “/* */”
添加行号和文件名标识,以便编译时产生的行号信息以及用于编译错误或警告时能够显示行号
保留所有的 “#pragma” 编译器指令
我们可以打开main.i看看,里面的头文件stdio.h已经被展开了,包括一些类型定义函数定义等等,截取片段如下:

这里找到了printf的外部声明如下:
extern int printf (const char *__restrict __format, ...);
printf()函数的调用格式为:printf("格式化字符串",输出表列)。参考例子为printf("%2c-%2c-%2c-%2c\n",'D','e','m','o');
1.2 编译(生成汇编代码 main.s)
编译过程是编译器gcc把预处理完的文件进行词法分析、语法分析、语义分析及优化后生成相应的汇编代码文件。使用命令gcc -S main.i -o main.s将前面预处理的main.i文件编译成汇编语言文件main.s
.file "main.c";
.text
.section .rodata
.LC0:
.string "HelloWorld!"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushq %rbp;
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $16, %rsp
movl %edi, -4(%rbp)
movq %rsi, -16(%rbp)
leaq .LC0(%rip), %rdi
call puts@PLT
movl $0, %eax
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu 7.4.0-1ubuntu1~18.04.1) 7.4.0"
.section .note.GNU-stack,"",@progbits我们发现printf函数调用被转化为call puts指令,而不是call printf指令,这好像有点出乎意料。不过不用担心,这是编译器对printf的一种优化。实践证明,对于printf的参数如果是以'\n'结束的纯字符串,printf会被优化为puts函数,而字符串的结尾'\n'符号被消除。除此之外,都会正常生成call printf指令。
puts()函数有两个特点:
- puts()在显示字符串时会自动在其末尾添加一个换行符。
- puts()遇到空字符时就停止输出,所以必须确保有空字符。
注意汇编程序由三个不同的元素组成:
指示(Directives) 以点号开始,用来指示对编译器,连接器,调试器有用的结构信息。指示本身不是汇编指令。例如,.file 只是记录原始源文件名。.data表示数据段(section)的开始地址, 而 .text 表示实际程序代码的起始。.string 表示数据段中的字符串常量。 .globl main指明标签main是一个可以在其它模块的代码中被访问的全局符号 。至于其它的指示你可以忽略。
标签(Labels) 以冒号结尾,用来把标签名和标签出现的位置关联起来。例如,标签.LC0:表示紧接着的字符串的名称是 .LC0. 标签main:表示指令 pushq %rbp是main函数的第一个指令。按照惯例, 以点号开始的标签都是编译器生成的临时局部标签,其它标签则是用户可见的函数和全局变量名称。
指令(Instructions) 实际的汇编代码 (pushq %rbp), 一般都会缩进,以便和指示及标签区分开来。
小贴士: AT&T 语法和 Intel 语法
注意GNU工具使用传统的AT&T语法。类Unix操作系统上,AT&T语法被用在各种处理器上。Intel语法则一般用在DOS和Windows系统上。下面是AT&T语法的指令:
movl %esp, %ebp
movl是指令名称。%则表明esp和ebp是寄存器.在AT&T语法中, 第一个是源操作数,第二个是目的操作数。
在其他地方,例如interl手册,你会看到是没有%的intel语法, 它的操作数顺序刚好相反。下面是Intel语法:
MOVQ EBP, ESP
当在网页上阅读手册的时候,你可以根据是否有%来确定是AT&T 还是 Intel 语法。
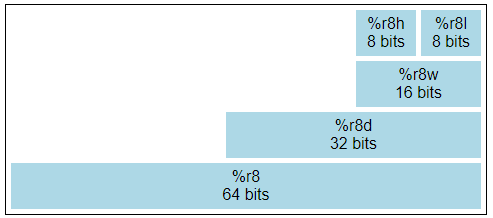
每个寄存器都有其特殊用途,并不是所有指令都可以应用到每一个寄存器。随着设计的进展,新的指令和寻址模式被添加进来,使得很多寄存器变成了等同的。少数留下来的指令,特别是和字符串处理相关的,要求使用%rsi 和%rdi。另外,两个寄存器被保留下来分别作为栈指针 (%rsp) 和基址指针 (%rbp)。最后的8个寄存器是编号的并且没有特殊限制。多年来,体系结构从8位扩展到16位,32位,因此每个寄存器都有一些内部结构:

%rax的低8位是8位寄存器%al, 仅靠的8位是%ah。低16位是 %ax, 低32位是 %eax,整个64位是%rax。
寄存器%r8-%r15也有相同结构,但命名方式稍有不同:
1.3 汇编(生成main.o文件)
汇编是汇编器把汇编代码转变成中间目标文件。汇编过程可以使用如下命令:
gcc -c main.s -o main.o
main.o已经是二进制文件了,直接打开会发现乱码一片,我们可以用objdump或者gdb的反汇编指令打开obj文件,如下:

??目标文件是什么?
--目标文件是指编译器编译源代码后生成的二进制文件,再通过链接器和资源文件链接就成可执行文件了。OBJ只给出了程序的【相对地址】,而可执行文件是【绝对地址】。CPP对应的二进制代码格式obj,是未经重定位的!以下摘自《程序员的自我修养》
现在PC平台流行的可执行文件格式(Executable),主要是Windows下的PE(Portable Executable)和linux的ELF (Executable Linkable Format),他们都是COFF(Common File Format)格式的变种。COFF是由Unix System VRelease 3首先提出并且使用的文件规范,后来微软公司基于COFF格式,制定了PE格式标准,并将其用于当时的Windows NT系统。System VRelease 4在COFF的基础上引入了ELF格式,目前流行的Linux系统也是以ELF作为基本的可执行文件格式。这也能解释为什么目前PE和ELF如此相似的主要原因,因为他们都是来源于同一种可执行文件格式COFF。目标文件就是源代码编译后为进行链接的那些中间文件(Windows下面为.obj文件;Linux下面为.o文件),它和可执行文件的内容和结构很相似,所以一般和可执行文件采用同一种格式进行存储。从广义上来讲,目标文件与可执行文件的格式其实几乎是一模一样的,所以,我们可以广义的将目标文件和可执行文件看成是同一种类型的文件。在Windows下,我们把目标文件和可执行文件都统一称为PE-COFF文件,在Linux下,我们把它们统称为ELF文件。
当然,事情没有这么简单!不光是可执行文件(Windows下面的.exe和Linux下面的ELF文件)按照可执行文件格式存储。动态链接库(DLL,dynamic linking library)[Windows下面的.dll文件和Linux下面的.a文件]以及静态链接库(Static linking Library)[Windows下面的.lib文件和Linux下面的.a文件]都是按照可执行文件格式存储的。只不过,在Windows平台下,他们按照PE-COFF格式存储,而在Linux平台下按照ELF格式进行储存。
ELF文件标准里面把系统中采用ELF格式的文件归为以下四类:
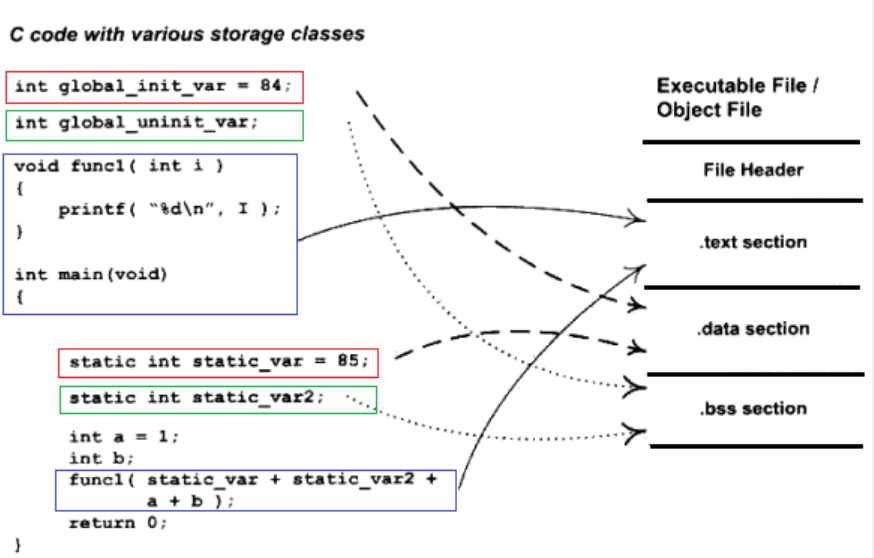
假设上图的可执行文件格式是ELF,从图中可以看到,ELF文件的开头是一个“文件头”,他描述了整个文件的文件属性,包括文件是否可执行、是静态链接还是动态链接以及入口地址(如果是可执行文件)、目标硬件、目标操作系统等信息。头文件包含一个段表(Section Table),段表事实是一个描述文件中各个段的数组。段表描述了文件中各个段在文件中的偏移位置及段的属性,从段表里面可以得到每个段的所有信息。文件头后面就是各个段的内容,比如代码段保存的就是程序的指令,数据段里面保存的就是程序的静态变量等。

1.4 链接(生成可执行程序)
链接器 ld:负责将程序的目标文件与所需的所有附加的目标文件连接起来,附加的目标文件包括静态连接库和动态连接库,链接是链接器ld把中间目标文件和相应的库一起链接成为可执行文件。
gcc main.o -o main
如果前面使用的是$ gcc main.c命令,默认会产生一个a.out 的可执行文件,使用命令./a.out执行该可执行文件
??为什么会使用a.out作为名字?
-- 《Expert C Programming》中提到它是assembler output(汇编程序输出)的缩写,默认使用a.out的名字是UNIX“没什么理由,但是我们就是这么做的”思维的一个例子。