博客园有一个很不友好的地方,那就是没有自带博客访问量统计功能.
之前有尝试使用flagcount进行统计,但是不知道什么时候开始这个插件被博客园屏蔽了.具体原因可自行百度...
反正有学Python的打算,于是就尝试(copy)写个脚本,统计我的博客园博客访问量,更确切地说,应该是统计每篇随笔地阅读量
首先,我找到一篇关于使用python统计博客园访问量地文章,对于大部分博客园用户来说,应该是可以用的
博客地址
https://www.cnblogs.com/-wenli/p/12464545.html
但是很可惜,并不适用于我的,可能是因为我的博客园做了一些自定义配置,导致统计失败.后来胡乱改了一下代码,总算可以在我自己的博客上进行统计.我的代码在旧代码上进行了简化
大概原理如下:
1. 配置headers模拟浏览器访问
2. 指定博客园地址
3. 配置博客园随笔地每一页地址
4. 通过get_one_page分析该页面时候存在,如果不存在则返回空...(这里是根据返回码检测,但是我发现访问不存在的页码,实际上curl -I还是会返回200,后续再研究一下.这里不影响统计,可先忽略)
5. 统计每一页随笔的访问量
6. 匹配div类,精确到阅读量所在地那个div标签,我这里对应地是p标签
这个需要自己确认.可以通过快捷键F12调出调试工具
慢慢找一下某篇文章对应的div.点击这个,对应文章区域会亮起.原代码的div是day,而我这里是post.另外阅读量在的div也不一样,原作者是div class="postDesc",我的是p class="postfoot"
对比一下.下面第一张图是原文博客的页面源代码,第二张是我的.
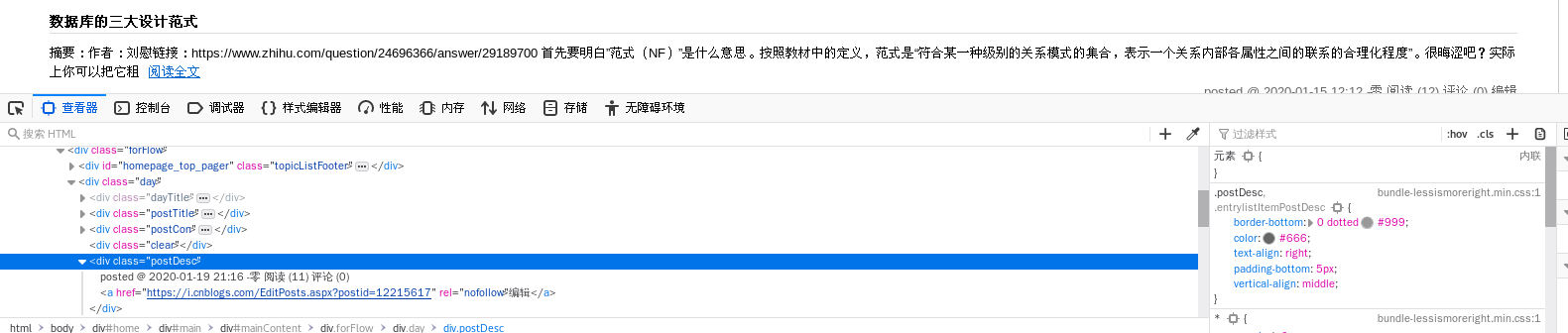
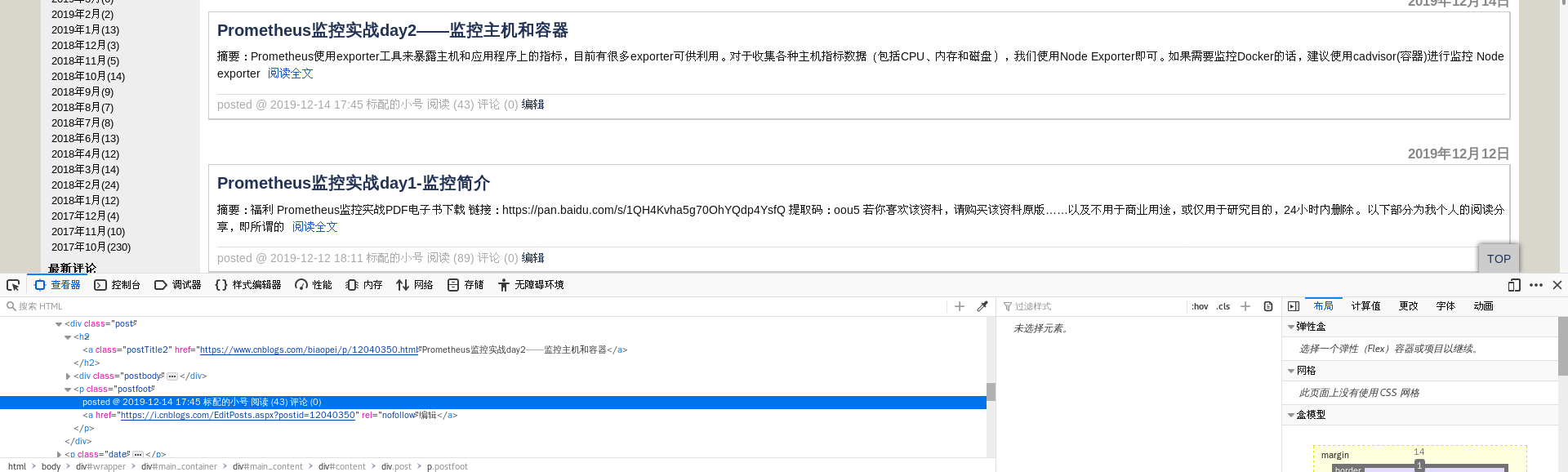
7. 提取p标签里的数字,得到一个数字列表
8. 再次从数字列表中提取出我们想要的阅读量
9. 最后将这些阅读量相加即可得总浏览量
先安装以下python模块(python2.7)
pip install beautifulsoup4 pip install lxml
具体python脚本如下
[root@instance-u5vn5wqr ~]# cat blogviewcount.py # -*- coding: utf-8 -*-
#第一行指定中文编码 from bs4 import BeautifulSoup import requests from requests.exceptions import RequestException import re import time def get_one_page(url,headers): try: response = requests.get(url,headers=headers) if response.status_code ==200: return response.text except RequestException: return None def parse_one_page(html): global flag global pertotal pertotal = 0 soup = BeautifulSoup(html, 'lxml') divs = soup.find_all('div',class_='post') if(len(divs) == 0): flag = False return "" for child in enumerate(divs): infomations = child.find_all('p', class_='postfoot') for infomation in infomations: info = infomation.get_text() info = info.replace('\n', '') info = info.replace(' ', '') #print info #info的具体值类似posted@2020-01-1019:29-零阅读(271)评论(0)编辑 #下面使用findall获取所有数字 result = re.findall("\d+", info) #print result #findall返回的结果实际是一个数字列表 #result返回的结果数字列表类似[u'2020', u'01', u'1019', u'29', u'271', u'0']. #其中对应的result[4]就是我们需要的阅读量 #print result[4] pertotal = pertotal + int(result[4]) print ('pertotal is:',pertotal) def main(): headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko'} headurl = 'https://www.cnblogs.com/biaopei/default.html?page=' i = 1 global pertotal global total pertotal = 0 total = 0 while flag: url = headurl + str(i) print(url) html = get_one_page(url,headers) parse_one_page(html) print(total,'+',pertotal,'=') total = total + pertotal print(total) i += 1if __name__ == '__main__': flag = True main() [root@instance-u5vn5wqr ~]#