针对爬虫首先声明只是哥玩具爬虫,得到自己的所有博客地址,然后随机访问,最后增加TamperMonkey插件
python爬虫
思想很简单,包含了2个类IPSpyder和CSDN类,前者保证一周内get一次ip代理到本地,后者包含3个方法负责随机读取博客,getBlogList()方法的输入是个人博客的主页地址,输出是个人博客所有的链接,getBlogTitleAndCount()的输入时单个博客的url地址,拿到当前博客的访问量和标题,输出;
后续优化:
- 增加tdqm的进度条显示;
- 考虑多线程方式
IP代理的爬虫参考:爬取IP代理
import requests
import lxml
from bs4 import BeautifulSoup
import os
import string
import random
import time
import aiohttp
import asyncio
from tqdm import tqdm
import os
import datetime
class IPSpyder(object):
def __init__(self):
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
self.sixsix_url_range = 35
self.kaixin_url_range = 2
self.kuai_url_range = 2
self.ip_list_all = []
self.ip_ok_list_all = []
self.url = 'https://blog.csdn.net/yezonggang/article/details/112991188'
self.ip_avaliable_file = 'F:/2020-11-04/csdn_sypder_20210124/ip_avaliable.txt'
def get_html(self, url, flag):
try:
headers = self.headers
response = requests.get(url, headers=headers)
response.raise_for_status()
if flag:
response.encoding = 'utf-8'
else:
response.encoding = 'gb2312'
return response.text
except Exception as err:
return '请求异常'
def get_66ip(self):
#ip_list = []
for index in range(1, self.sixsix_url_range):
count = 0
province = ''
url = 'http://www.66ip.cn/areaindex_{}/1.html'.format(index)
html = self.get_html(url, flag=False)
soup = BeautifulSoup(html, 'lxml')
tr_list = soup.find_all(name='tr')
for tr_ in tr_list[2:]:
td_list = tr_.find_all(name='td')
ip = td_list[0].string
port = td_list[1].string
province = td_list[2].string
ip_port = ip + ':' + port
self.ip_list_all.append(ip_port)
count += 1
print('Saved {0} {1} ip.'.format(province, count))
# 速度不要太快哦!, 否则获取不到页面内容
time.sleep(3)
print('66 daili Finished!!!')
def get_kaixinip(self):
#ip_list = []
for index in range(1, self.kaixin_url_range):
count = 0
url = 'http://www.kxdaili.com/dailiip/1/{}.html'.format(index)
html = self.get_html(url, False)
soup = BeautifulSoup(html, 'lxml')
tr_list = soup.find_all(name='tr')
for tr_ in tr_list[2:]:
td_list = tr_.find_all(name='td')
ip = td_list[0].string
port = td_list[1].string
ip_port = ip + ':' + port
self.ip_list_all.append(ip_port)
count += 1
print('Saved {0} page {1} ip.'.format(index, count))
# 速度不要太快哦!, 否则获取不到页面内容
time.sleep(3)
print('kaixindaili Finished!!!')
def get_goubanjiaip(self):
#ip_list = []
url = 'http://www.goubanjia.com/'
html = self.get_html(url, False)
soup = BeautifulSoup(html, 'lxml')
td_list = soup.find_all(class_='ip')
for td_ in td_list:
ip_ = ''
for child in td_.children:
if child == ':':
ip_ += child
elif not child.attrs:
ip_ += child.get_text()
elif list(child.attrs.keys())[0] == 'class':
ip_ = ip_ + child.get_text()
elif child.attrs['style'] == 'display:inline-block;' or child.attrs['style'] == 'display: inline-block;':
ip_ += child.get_text()
self.ip_list_all.append(ip_)
print('quanwang daili Finished!!!')
# 快代理
def get_kuaidaili(self):
#ip_list = []
for index in range(1, self.kuai_url_range):
count = 0
url = 'https://www.kuaidaili.com/free/inha/{}/'.format(index)
html = self.get_html(url, False)
soup = BeautifulSoup(html, 'lxml')
tr_list = soup.find_all(name='tr')
for tr_ in tr_list[1:]:
td_list = tr_.find_all(name='td')
ip = td_list[0].string
port = td_list[1].string
ip_port = ip + ':' + port
self.ip_list_all.append(ip_port)
count += 1
print('Saved {0} page {1} ip.'.format(index, count))
# 速度不要太快哦!, 否则获取不到页面内容
time.sleep(3)
print('kuaidaili Finished!!!')
async def test_ip(self, ip_, url):
#global ip_ok
conn = aiohttp.TCPConnector(verify_ssl=False)
async with aiohttp.ClientSession(connector=conn) as session:
try:
proxy_ip = 'http://' + ip_
print('正在测试: ' + proxy_ip)
async with session.get(url=url, headers=self.headers, proxy=proxy_ip, timeout=15) as response:
if response.status == 200:
print('代理可用: ' + ip_)
self.ip_ok_list_all.append(ip_)
else:
print('请求响应码不合法 ' + ip_)
except:
print('代理请求失败', ip_)
def run_test_ip_write_to_file(self):
#csdn 点赞关注私聊发^-^
print('csdn 点赞关注私聊发')
# 我的博客列表,后面要跟翻页list/1
# 我的博客列表有几页?
# header
# 定义一个类 CSDN
# csdn_url='https://blog.csdn.net/yezonggang/article/details/106344148'
class CSDN(object):
# 类的静态变量
def __init__(self):
self.my_csdn = 'https://blog.csdn.net/yezonggang/article/list/'
self.my_list = 5
self.csdn_url = ''
self.proxies = [{'http': 'socks5://183.195.106.118:8118'}]
self.blogList = []
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
}
# 从博客首页进去,遍历得到我的博客列表,把博客地址塞进self.blogList[]
def getBlogList(self):
i = 1
print('-------------------------------begin----------------------------')
while(i <= self.my_list):
response = requests.get(self.my_csdn+str(i), headers=self.headers)
response.enconding = 'utf-8'
conent = response.content.decode('utf-8')
soup = BeautifulSoup(conent, 'lxml')
a_tag_content = soup.findAll('a')
for a_tag in a_tag_content:
a_tag_content = str(a_tag.get('href'))
if('details' in a_tag_content and 'comments' not in a_tag_content):
self.blogList.append(a_tag_content)
#print (a_tag_content)
print('Success, already append ' +
str(len(self.blogList)) + ' to the blogList!')
i = i+1
# print (self.blogList)
# 随机遍历self.blogList[]里面的博客链接,得到博客的标题和次数,并输出
def getBlogTitleAndCount(self, proxy):
proxy_support = {
'http': 'http://'+proxy,
'https': 'https://'+proxy,
}
response = requests.get(
self.csdn_url, headers=self.headers, proxies=proxy_support)
response.enconding = 'utf-8'
conent = response.content.decode('utf-8')
soup = BeautifulSoup(conent, 'lxml')
# 得到当前博客的标题:数据挖掘算法和实践(二十一):kaggle经典-职场离职率分析案例解读
blog_title = soup.title.string
# 得到当前博客的访问量统计值,显示出来
blog_counts = soup.find_all('span')
for blog_count in blog_counts:
blog_count_single_class = blog_count.get('class')
if(blog_count_single_class is not None and blog_count_single_class[0] == 'read-count'):
blog_count_now = blog_count.string
print('当前读取的博客地址是:【'+self.csdn_url+'】\n' +
'当前读取的博客地址是:【'+blog_title + '】\n' +
'当前使用的代理IP是:【'+proxy + '】\n' +
'当前博客的阅读统计是:【_' + blog_count_now + '_次】')
def beginTO(self, proxy):
self.getBlogList()
self.csdn_url = random.choice(self.blogList)
self.getBlogTitleAndCount(proxy)
#random_time=random.uniform(sleepTimeMin, sleepTimeMax)
#print("Begin to sleep now,Sleep time: "+str(random_time))
# time.sleep(random_time)
self.blogList = []
# 逻辑开始,首先判定本地的可用ip文件的创建戳是不是超过1周或者文件是空,若是就重新刷新,不然直接开始刷;
ip_avaliable = "F:/2020-11-04/csdn_sypder_20210124/ip_avaliable.txt"
mtime = os.stat(ip_avaliable).st_ctime
# 如果文件存在,并且创建时间是7天内,并且非空
if(not os.path.exists(ip_avaliable) or ((time.time()-mtime)/(3600*24) > 7) or not os.path.getsize(ip_avaliable)):
# 先刷代理后刷博客
ipSpyder = IPSpyder()
ipSpyder.get_66ip()
#ipSpyder.get_kaixinip()
#ipSpyder.get_goubanjiaip()
#ipSpyder.get_kuaidaili()
ipSpyder.run_test_ip_write_to_file()
# 直接调用开始刷
file_ip = open(ip_avaliable, 'r')
ip_avaliable_list = file_ip.read().split(",")
file_ip.close()
# print(ip_avaliable_list)
proxy_now = random.choice(ip_avaliable_list)
csdn = CSDN()
while True:
print('csdn 点赞关注私聊发')
csdn.beginTO(proxy_now)
time.sleep(10)
#csdn 点赞关注私聊发^-^
#ipSpyder =IPSpyder()
# ipSpyder.get_66ip()
# ipSpyder.get_kaixinip()
# ipSpyder.get_goubanjiaip()
# ipSpyder.get_kuaidaili()
# ipSpyder.run_test_ip()
#
# time.localtime(statinfo)
#print ('得到了一系列的IP代理,总共有 '+str(len(ipSpyder.ip_list_all))+' 个;')
#print ('经过测试总共有 '+str(len(ipSpyder.ip_ok_list_all))+' 个IP代理可用;')
#file = open("ip_avaliable.txt", 'w')
# file.write(ip_ok_list_all)
# file.close()
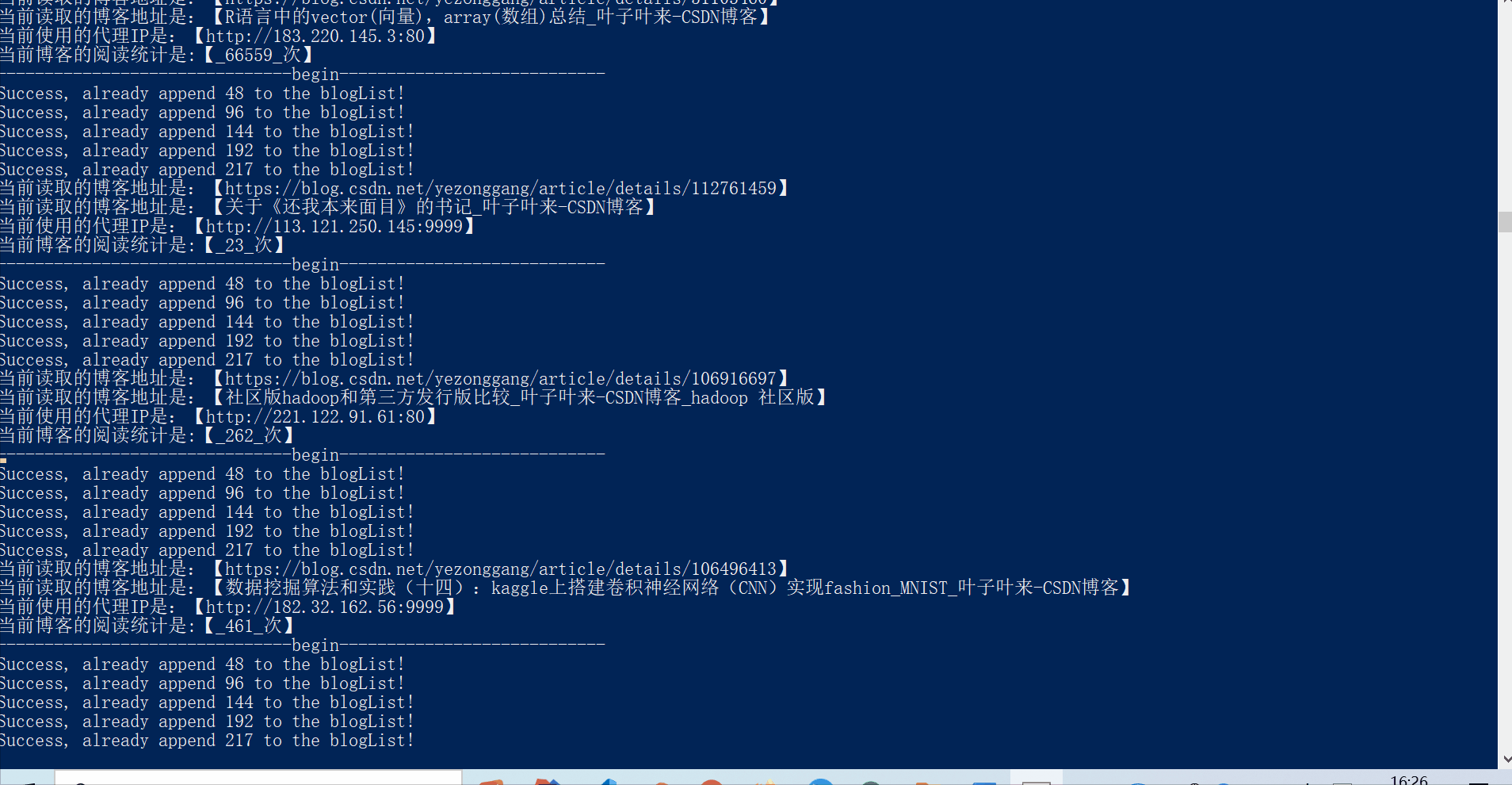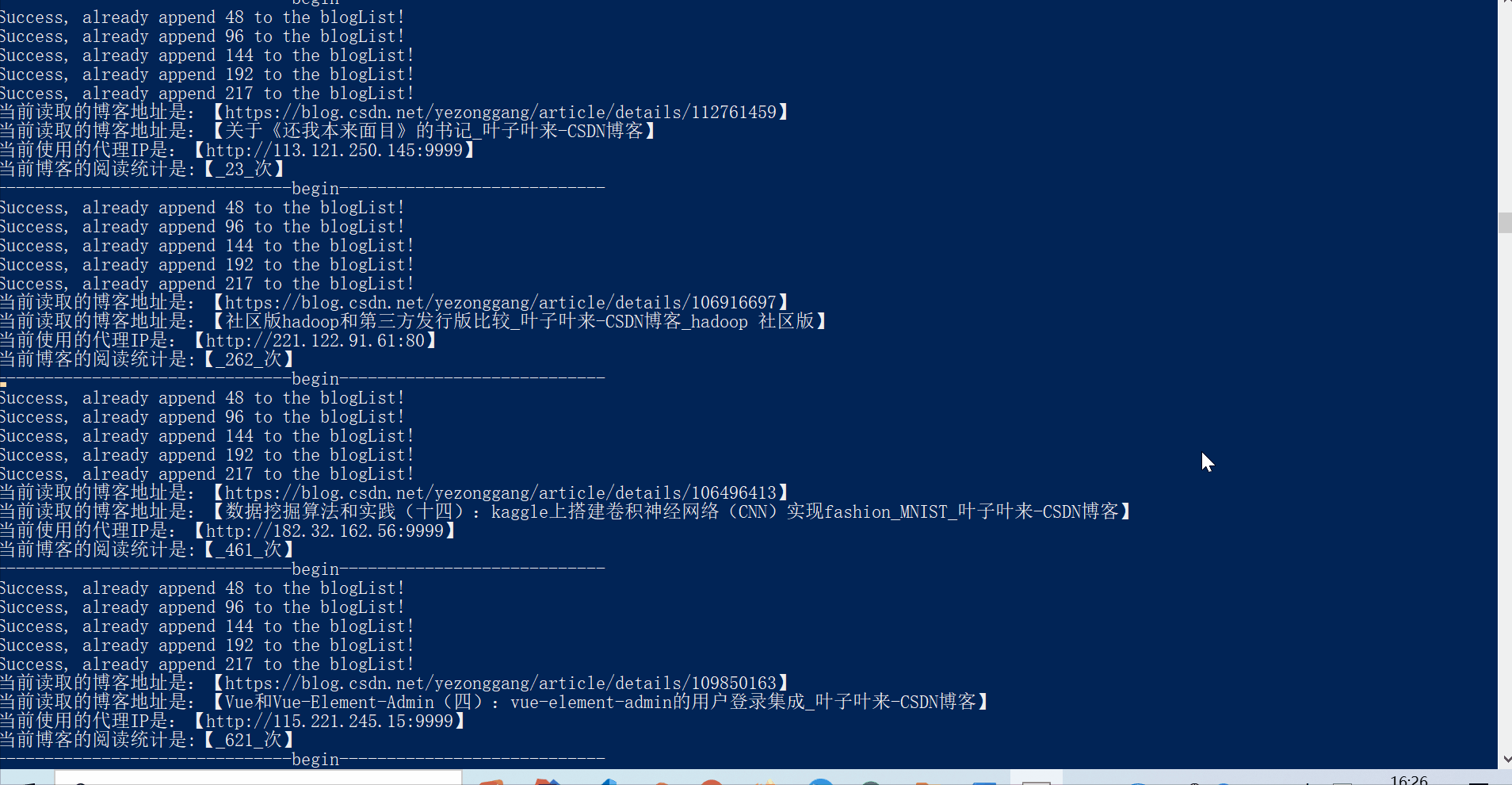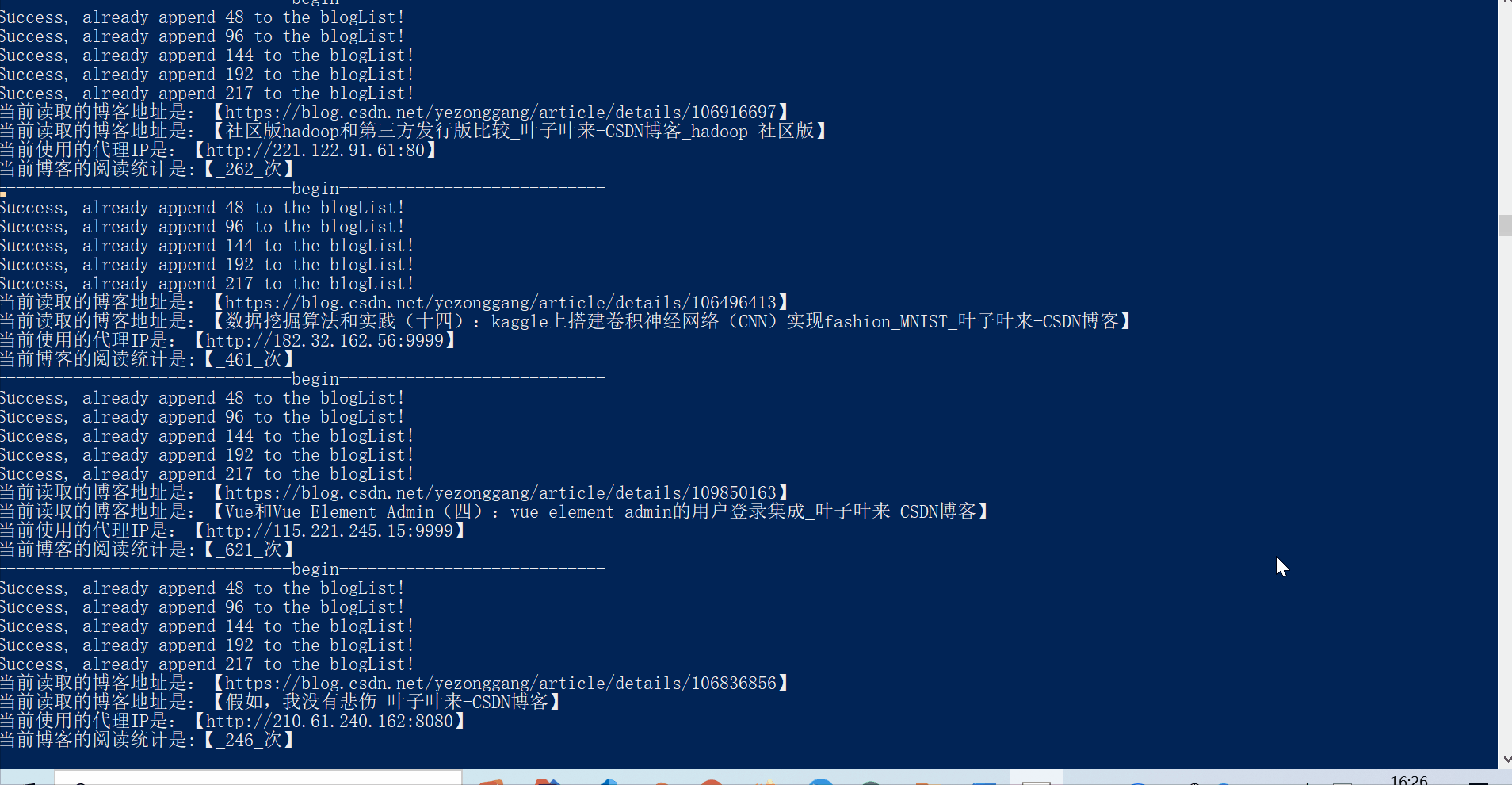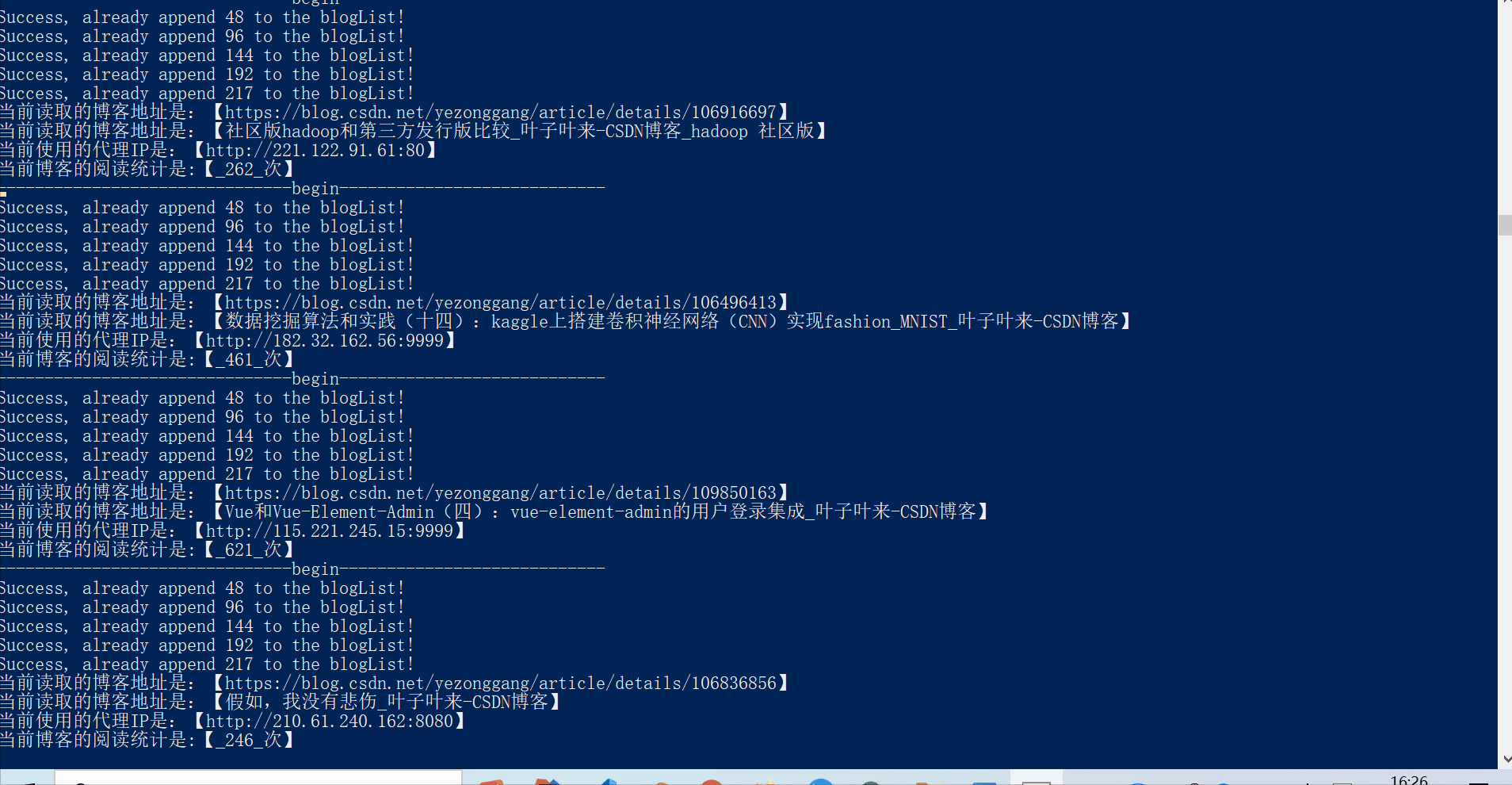
输出的范例如下:
Success, already append 48 to the blogList!
Success, already append 96 to the blogList!
Success, already append 144 to the blogList!
Success, already append 192 to the blogList!
Success, already append 211 to the blogList!
当前读取的博客地址是:【https://blog.csdn.net/yezonggang/article/details/105723456】
当前读取的博客地址是:【数据挖掘算法和实践(一):线性回归和逻辑回归(house_price数据集)_叶子叶来-CSDN博客】
当前使用的代理IP是:【211.144.213.145:80】
当前博客的阅读统计是:【_351_次】