一、本文目标
1.用requests+BeautifulSoup抓取糗事百科的文字内容;
2.抓取昵称,性别,年龄,发表内容,点赞数,评论数;
2.将抓取的内容写入txt。
二、实现过程
1.获取网页源代码
def get_html(url): #用requests库得到网页源代码 html = requests.get(url).text return html
2.查看源代码结构找到要抓取的目标
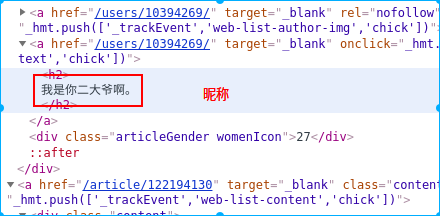

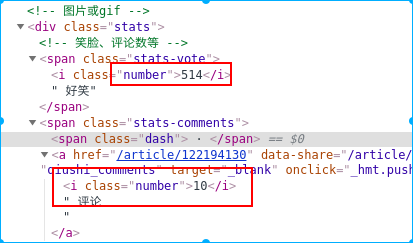
3.找到这几样就可以写抓取代码如下
soup = BeautifulSoup(html,'lxml') datas = soup.find(id="content-left")#获取全部内容标签 data_list = datas.find_all(class_="article") for data in data_list: contents = data.find(class_="content").text.replace('\n','')#获取内容 name = data.find('h2').text.replace('\n','')#获取昵称 age_gender = data.find(class_="articleGender")#获取性别 if age_gender is not None: cll = age_gender['class'] if 'womenIcon' in cll: gender = '女' elif 'manIcon' in cll: gender = '男' else: gender = '' age = age_gender.string else: gender = '' age = '' votes = data.find(class_="stats-vote").find(class_="number").text#获取点赞数 comments = data.find(class_="stats-comments").find(class_="number").text#获取评论数
4.全部代码肉如下
import requests from bs4 import BeautifulSoup def get_html(url): #用requests库得到网页源代码 html = requests.get(url).text return html def get_data(html): soup = BeautifulSoup(html,'lxml') datas = soup.find(id="content-left")#获取全部内容标签 data_list = datas.find_all(class_="article") for data in data_list: contents = data.find(class_="content").text.replace('\n','')#获取内容 name = data.find('h2').text.replace('\n','')#获取昵称 age_gender = data.find(class_="articleGender")#获取性别 if age_gender is not None: cll = age_gender['class'] if 'womenIcon' in cll: gender = '女' elif 'manIcon' in cll: gender = '男' else: gender = '' age = age_gender.string else: gender = '' age = '' votes = data.find(class_="stats-vote").find(class_="number").text#获取点赞数 comments = data.find(class_="stats-comments").find(class_="number").text#获取评论数 dict = { '昵称': name , '性别': gender , '年纪': age , '内容': contents, '点赞数': votes , '评论数': comments } yield dict def get_txt(dict): print('--'+'正在写入......') with open('糗事百科.txt','a+',encoding='utf-8') as f: for i in dict: f.write(str(i)+'\n') print('---'+'写入完毕') def main(): for i in range(1,20): print('正在爬取第%d页',i) url = 'https://www.qiushibaike.com/text/page/{}/'.format(i) html = get_html(url) dict = get_data(html) get_txt(dict) if __name__ == '__main__': main()
5.谢谢观看