版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/weixin_37720172/article/details/78581518
周末没啥事花了几个钟写了这个爬虫。下面是结构图。
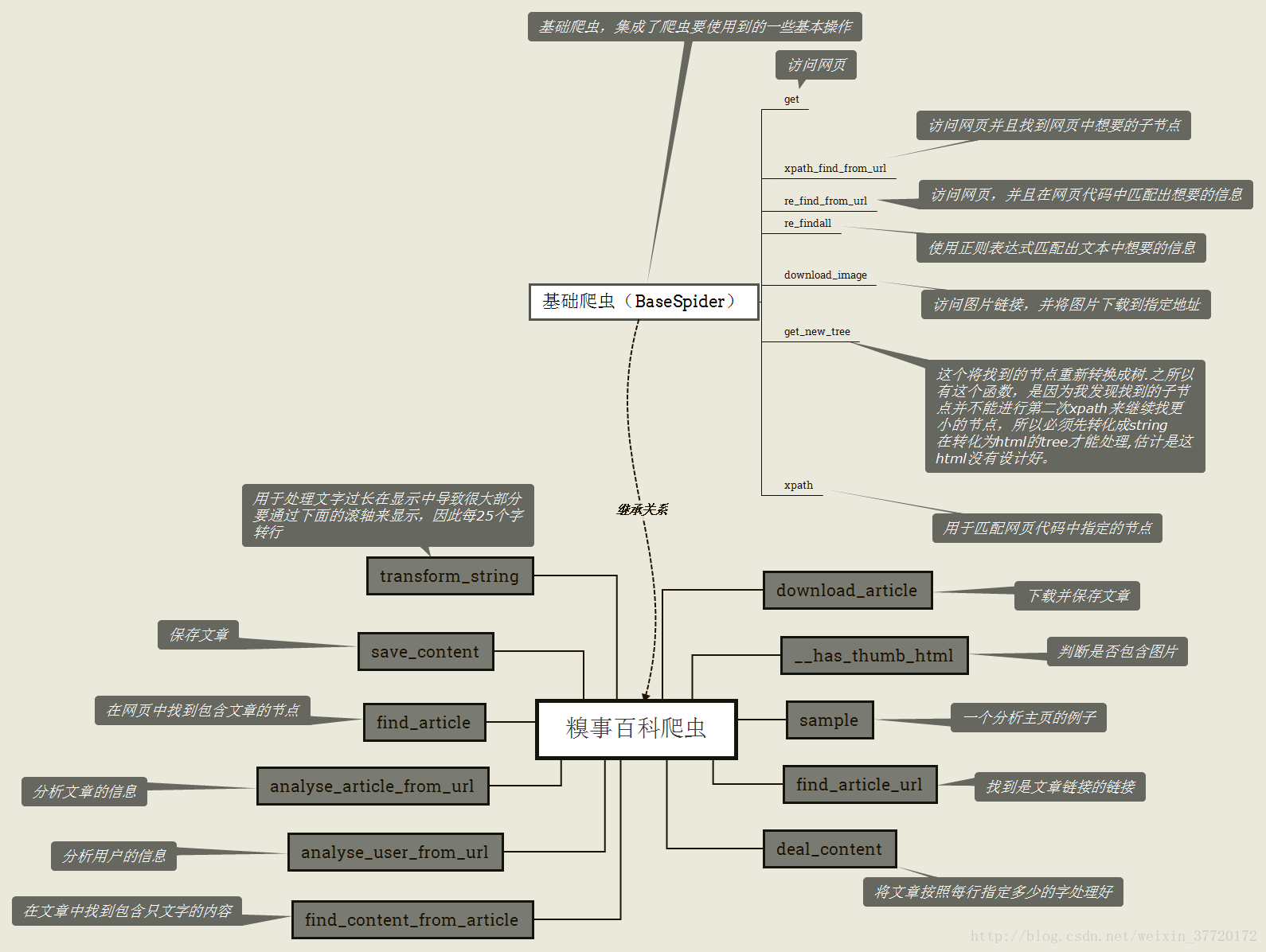
里面的功能已经足以帮我很好的分析糗事百科这个网站了。当然我知道别人也写过糗事百科的爬虫,不得不承认糗事百科的网页架构很简单,很适合作为爬虫初学者去练手。我是在没有任何参考的情况下一点点摸索写完这个爬虫的,也许比不上资深程序员写的,但也学到了很多
废话少说,下面我就举几个例子来感受下我写的爬虫吧。
1.分析用户
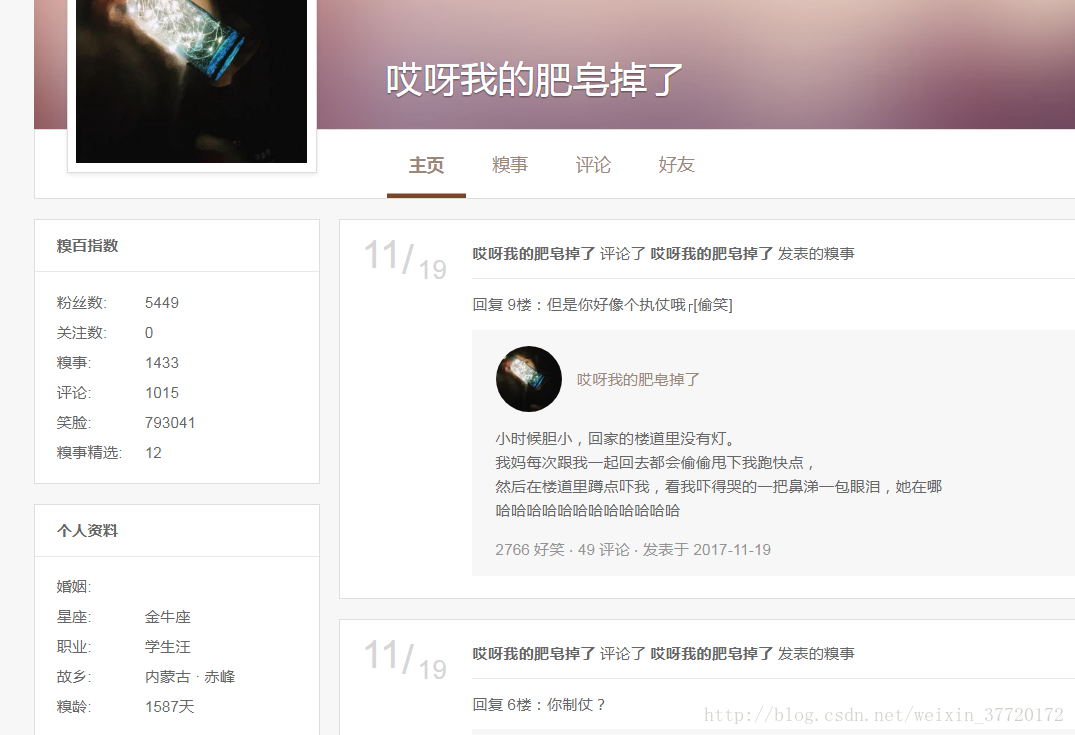
用户主页:
代码:
qiushi = QiuShi()
_user_url = 'https://www.qiushibaike.com/users/10074783/'
_user_message = qiushi.analyse_user_from_url(_user_url)
for item in _user_message.items():
print(item)分析结果

2.分析文章
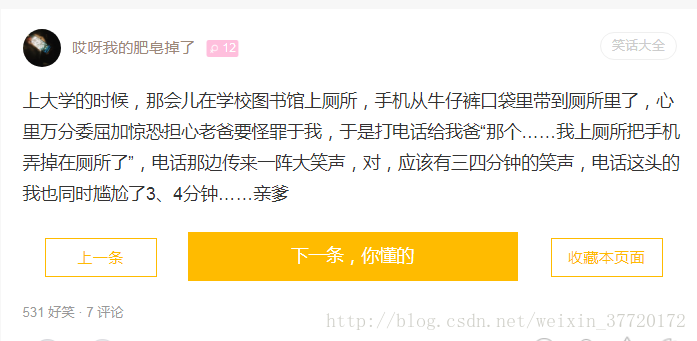
文章页面:
代码:
qiushi = QiuShi()
_article_url = 'https://www.qiushibaike.com/article/119762872'
_article_message = qiushi.analyse_article_from_url(_article_url)
for item in _article_message.items():
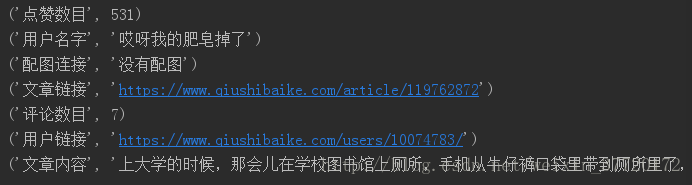
print(item)分析结果:
3.还可以分析并下载用户的所有文章
代码:
qiushi = QiuShi()
_user_url = 'https://www.qiushibaike.com/users/10074783/'
_user_message = qiushi.analyse_user_from_url(_user_url)
_user_name = _user_message['用户名']
_article_urls = _user_message['所有糗事链接']
qiushi.download_article(_article_urls, _user_name)效果:

4.当然除了上面的例子还可以利用我里面的函数自由组合,达到自己想要爬取的结果
最后如果想要源代码的,请关注我的微信公众号,并回复“糗事百科爬虫”便可获取代码:
