文章来源:公众号-智能化IT系统。
爬虫技术目前越来越流行,这里介绍一个爬虫的简单应用。
爬取的内容为糗事百科文字内容中的信息,如图所示:

爬取糗事百科文字35页的信息,通过手动浏览,以下为前四页的网址:
http://www.qiushibaike.com/text/
http://www.qiushibaike.com/text/page/2/?s=4964629
http://www.qiushibaike.com/text/page/3/?s=4964629
http://www.qiushibaike.com/text/page/4/?s=4964629
这里的?s=4964629应该只是从Cookies里提取的用户标识,去掉后依然能打开网页。然后把第一页的网址改为http://www.qiushibaike.com/text/page/1/也能正常浏览,故只需更改page后面的数字即可,以此来构造出35页的网址。
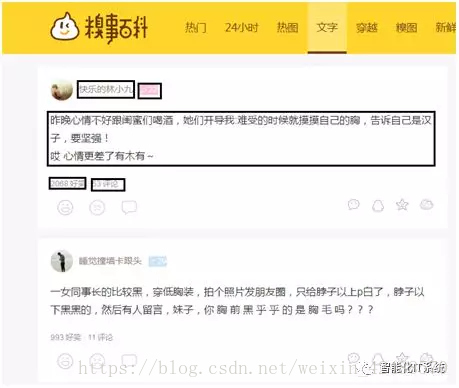
需要爬取的信息有:用户ID,用户等级,用户性别,发表段子文字信息,好笑数量和评论数量,如下图所示:
案例中运用Python对文件的操作,把爬取的信息存储在本地的txt文本中。
一. 前置工作:
1. 安装python
2. 安装PyCharm
python不用说了。Pycharm是python的开发工具。具体安装可以百度参考。
二. 技术点介绍
爬虫技术并不需要掌握python非常精通,本案例只是涉及到python如下的基本技术点:
1. 字符串的基本操作
2. python函数
3. python元组应用
4. python的for循环
5. python的条件判断
6. python文件操作
另外需要了解一下http的请求,涉及如下:
1. http请求和响应基本原理
2. get和post请求基本知识
3. http请求头中的User-Agent,便于伪造精确的请求信息
本案例是针对python的爬取网页数据,所以python针对爬虫的相关技术需要熟悉:
1. Requests库(模拟请求)
2. Re模块(正则表达式的应用,在请求结果中匹配数据)
最后就是网页元素的基本知识了,包括如下:
1. html元素
2. chrome浏览器的使用,以及获取网页指定元素的标签
本文不对上述技术点进行讲述,读者如果有问题可以百度搜索一下,应该很快就能熟悉。熟悉了上述技术点,就可以完全掌握下面的爬取代码了。
三. 爬取代码
如下代码可以直接复制执行:
import requests
import re
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'
}
info_lists = []
defjudgment_sex(class_name):
if class_name == 'womenIcon':
return '女'
else:
return '男'
def get_info(url):
res = requests.get(url)
ids = re.findall('<h2>(.*?)</h2>',res.text,re.S)
levels = re.findall('<div class="articleGender\D+Icon">(.*?)</div>',res.text,re.S)
sexs = re.findall('<div class="articleGender(.*?)">',res.text,re.S)
contents = re.findall('<divclass="content">.*?<span>(.*?)</span>',res.text,re.S)
laughs = re.findall('<spanclass="stats-vote"><iclass="number">(\d+)</i>',res.text,re.S)
comments = re.findall('<iclass="number">(\d+)</i> 评论',res.text,re.S)
for id,level,sex,content,laugh,comment inzip(ids,levels,sexs,contents,laughs,comments):
info = {
'id':id,
'level':level,
'sex':judgment_sex(sex),
'content':content,
'laugh':laugh,
'comment':comment
}
info_lists.append(info)
if __name__ =='__main__':
urls = ['http://www.qiushibaike.com/text/page/{}/'.format(str(i))for i in range(1,36)]
for url in urls:
get_info(url)
for info_list in info_lists:
f = open('C:/Users/Administrator//Desktop/qiushi.text','a+')
try:
f.write(info_list['id']+'\n')
f.write(info_list['level'] + '\n')
f.write(info_list['sex'] + '\n')
f.write(info_list['content'] + '\n')
f.write(info_list['laugh'] + '\n')
f.write(info_list['comment'] + '\n\n')
f.close()
except UnicodeEncodeError:
pass
print(info_list)
运行的结果保存在电脑,文件名为qiushi的文档中,如图所示

四. 代码分析
(1)1~2行
导入程序需要的库,Requests库用于请求网页获取网页数据。运用正则表达式不需要用BeautifulSoup解析网页数据,而是使用Python中的re模块匹配正则表达式。
(2)4~7行
通过Chrome浏览器的开发者工具,复制User-Agent,用于伪装为浏览器,便于爬虫的稳定性。
(3)17~34行
定义get_info()函数,用于获取网页信息并把数据传入到info_lists列表中。传入URL后,进行请求。
(4)第9行
定义了一个info_lists空列表,用于存放爬取的信息,每条数据为字典结构。
(5)11~15行
定义judgment_sex()函数,用于判断用户的性别。
(5)36~51行
为程序的主入口。通过对网页URL的观察,通过列表的推导式构造35个URL,并依次调用get_info()函数,循环遍历info_lists列表,存入到文件名qiushi的TXT文档中。
公众号-智能化IT系统。每周都有技术文章推送,包括原创技术干货,以及技术工作的心得分享。扫描下方关注。

公众号-智能化IT系统。每周都有技术文章推送,包括原创技术干货,以及技术工作的心得分享。扫描下方关注。
