初识spark,需要对其API有熟悉的了解才能方便开发上层应用。本文用图形的方式直观表达相关API的工作特点,并提供了解新的API接口使用的方法。例子代码全部使用python实现。
1. 数据源准备
准备输入文件:
$ cat /tmp/in
apple
bag bag
cat cat cat启动pyspark:
$ ./spark/bin/pyspark使用textFile创建RDD:
>>> txt = sc.textFile("file:///tmp/in", 2)查看RDD分区与数据:
>>> txt.glom().collect()
[[u'apple', u'bag bag'], [u'cat cat cat']]2. transformation
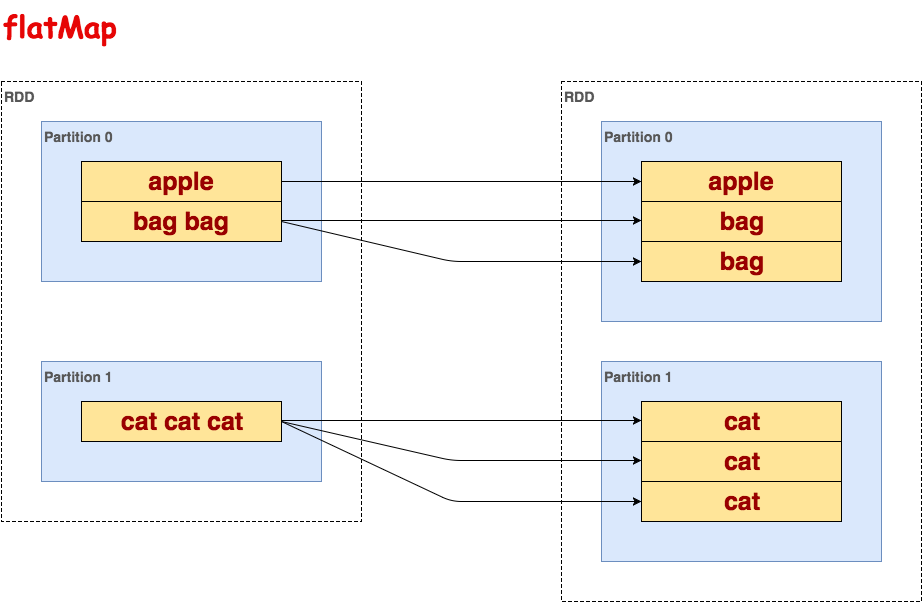
flatMap
处理RDD的每一行,一对多映射。
代码示例:
>>> txt.flatMap(lambda line: line.split()).collect()
[u'apple', u'bag', u'bag', u'cat', u'cat', u'cat']示意图:
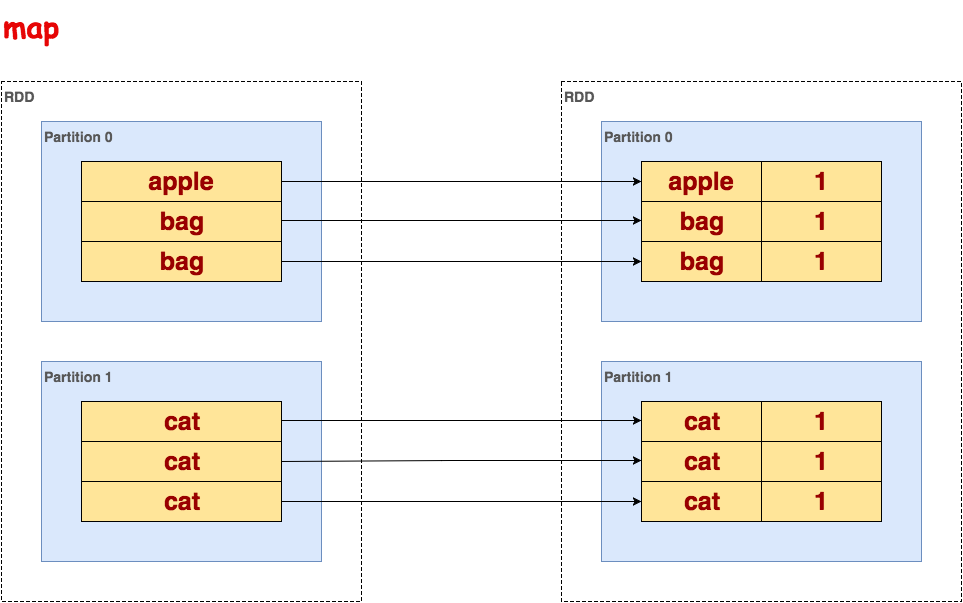
map
处理RDD的每一行,一对一映射。
代码示例:
>>> txt.flatMap(lambda line: line.split()).map(lambda word: (word, 1)).collect() [(u'apple', 1), (u'bag', 1), (u'bag', 1), (u'cat', 1), (u'cat', 1), (u'cat', 1)]示意图:
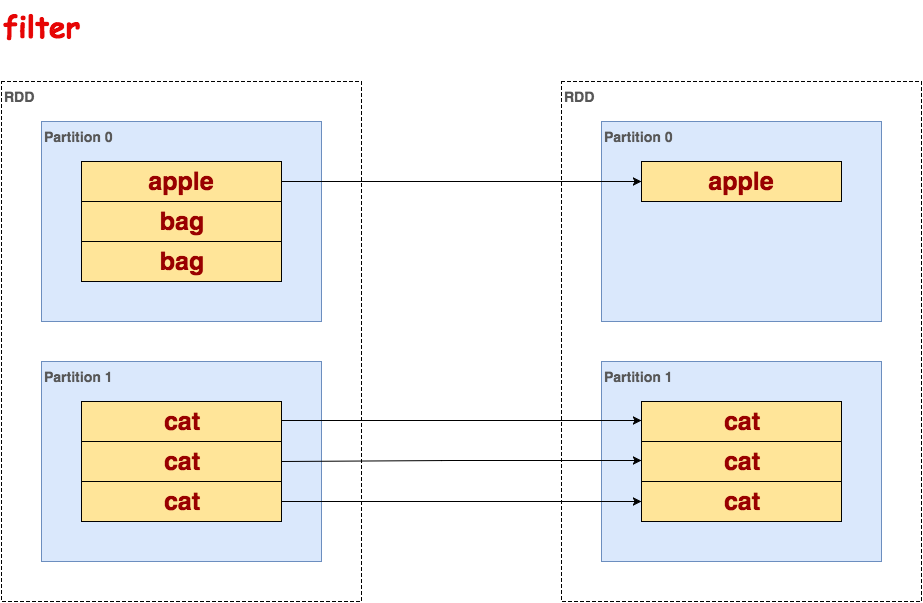
filter
处理RDD的每一行,过滤掉不满足条件的行。
代码示例:
>>> txt.flatMap(lambda line: line.split()).filter(lambda word: word !='bag').collect() [u'apple', u'cat', u'cat', u'cat']
mapPartitions
逐个处理每一个partition,使用迭代器it访问每个partition的行。
代码示例:
>>> txt.flatMap(lambda line: line.split()).mapPartitions(lambda it: [len(list(it))]).collect() [3, 3]示意图:

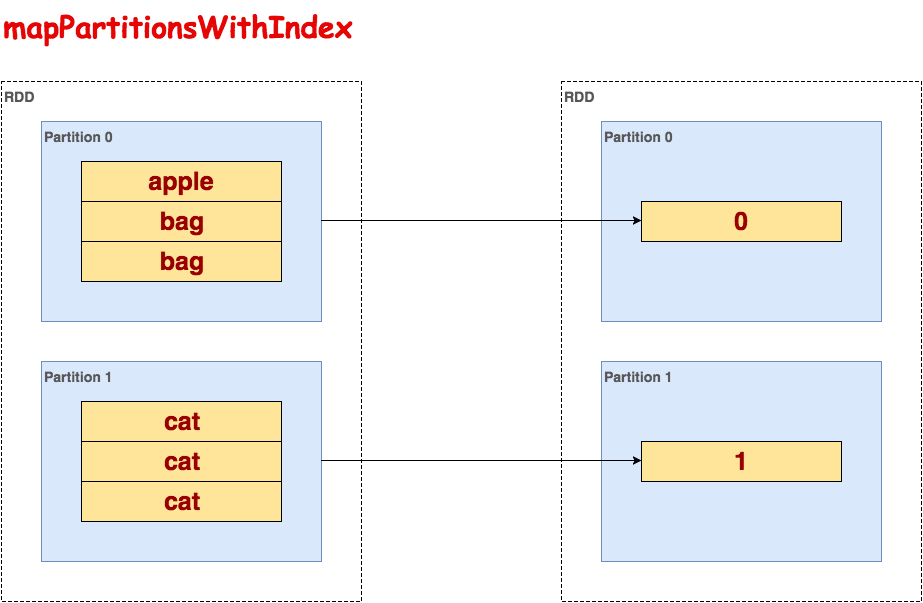
mapPartitionsWithIndex
逐个处理每一个partition,使用迭代器it访问每个partition的行,index保存partition的索引,等价于mapPartitionsWithSplit(过期函数)。
代码示例:
>>> txt.flatMap(lambda line: line.split()).mapPartitionsWithIndex(lambda index, it: [index]).collect() [0, 1]示意图:
sample
根据采样因子指定的比例,对数据进行采样,可以选择是否用随机数进行替换,seed用于指定随机数生成器种子。第一个参数表示是否放回抽样,第二个参数表示抽样比例,第三个参数表示随机数seed。
代码示例:
>>> txt.flatMap(lambda line: line.split()).sample(False, 0.5, 5).collect() [u'bag', u'bag', u'cat', u'cat']示意图:
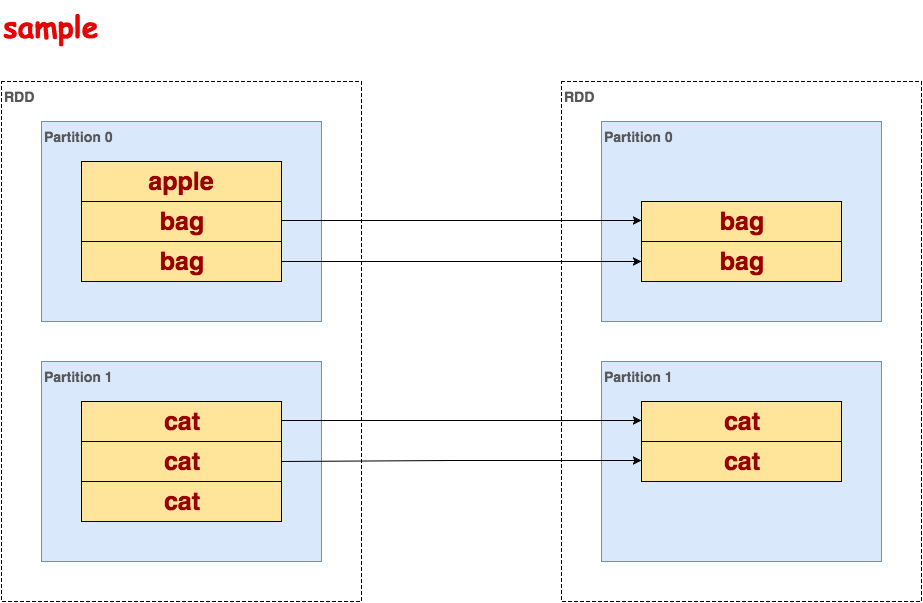
union
合并RDD,不去重。
代码示例:
>>> txt.union(txt).collect()
[u'apple', u'bag bag', u'cat cat cat', u'apple', u'bag bag', u'cat cat cat']示意图:

distinct
对RDD去重。
代码示例:
>>> txt.flatMap(lambda line: line.split()).distinct().collect()
[u'bag', u'apple', u'cat']示意图:

groupByKey
在一个(K,V)对的数据集上调用,返回一个(K,Seq[V])对的数据集。
代码示例:
>>> txt.flatMap(lambda line: line.split()).map(lambda word: (word, 1)).groupByKey().collect() [(u'bag', <pyspark.resultiterable.ResultIterable object at 0x128a150>), (u'apple', <pyspark.resultiterable.ResultIterable object at 0x128a550>), (u'cat', <pyspark.resultiterable.ResultIterable object at 0x13234d0>)] >>> txt.flatMap(lambda line: line.split()).map(lambda word: (word, 1)).groupByKey().collect()[0][1].data [1, 1]示意图:

reduceByKey
在一个(K,V)对的数据集上调用时,返回一个(K,V)对的数据集,使用指定的reduce函数,将相同key的值聚合到一起。
代码示例:
>>> txt.flatMap(lambda line: line.split()).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b).collect() [(u'bag', 2), (u'apple', 1), (u'cat', 3)]示意图:

aggregateByKey
自定义聚合函数,类似groupByKey。在一个(K,V)对的数据集上调用,不过可以返回一个(K,Seq[U])对的数据集。
代码示例(实现groupByKey的功能):
>>> txt.flatMap(lambda line: line.split()).map(lambda word: (word, 1)).aggregateByKey([], lambda seq, elem: seq + [elem], lambda a, b: a + b).collect() [(u'bag', [1, 1]), (u'apple', [1]), (u'cat', [1, 1, 1])]sortByKey
在一个(K,V)对的数据集上调用,K必须实现Ordered接口,返回一个按照Key进行排序的(K,V)对数据集。升序或降序由ascending布尔参数决定。
代码示例:
>>> txt.flatMap(lambda line: line.split()).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b).sortByKey().collect() [(u'apple', 1), (u'bag', 2), (u'cat', 3)]示意图:
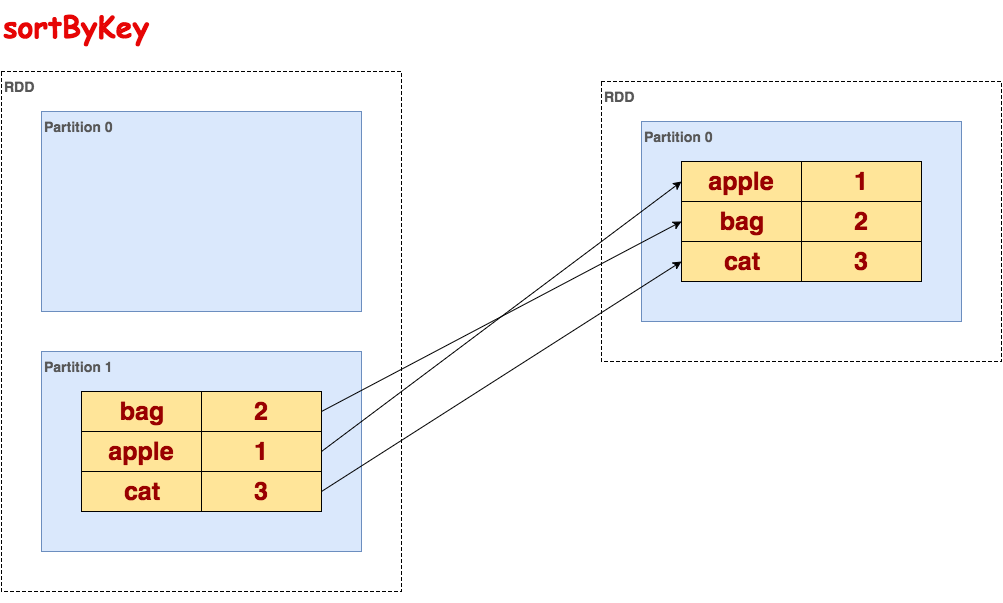
join
在类型为(K,V)和(K,W)类型的数据集上调用时,返回一个相同key对应的所有元素对在一起的(K, (V, W))数据集。
代码示例:
>>> sorted_txt = txt.flatMap(lambda line: line.split()).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b).sortByKey() >>> sorted_txt.join(sorted_txt).collect() [(u'bag', (2, 2)), (u'apple', (1, 1)), (u'cat', (3, 3))]示意图:

cogroup
在类型为(K,V)和(K,W)的数据集上调用,返回一个 (K, (Seq[V], Seq[W]))元组的数据集。这个操作也可以称之为groupwith。
代码示例:
>>> sorted_txt = txt.flatMap(lambda line: line.split()).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b).sortByKey() >>> sorted_txt.cogroup(sorted_txt).collect() [(u'bag', (<pyspark.resultiterable.ResultIterable object at 0x1323790>, <pyspark.resultiterable.ResultIterable object at 0x1323310>)), (u'apple', (<pyspark.resultiterable.ResultIterable object at 0x1323990>, <pyspark.resultiterable.ResultIterable object at 0x1323ad0>)), (u'cat', (<pyspark.resultiterable.ResultIterable object at 0x1323110>, <pyspark.resultiterable.ResultIterable object at 0x13230d0>))] >>> sorted_txt.cogroup(sorted_txt).collect()[0][1][0].data [2]示意图:
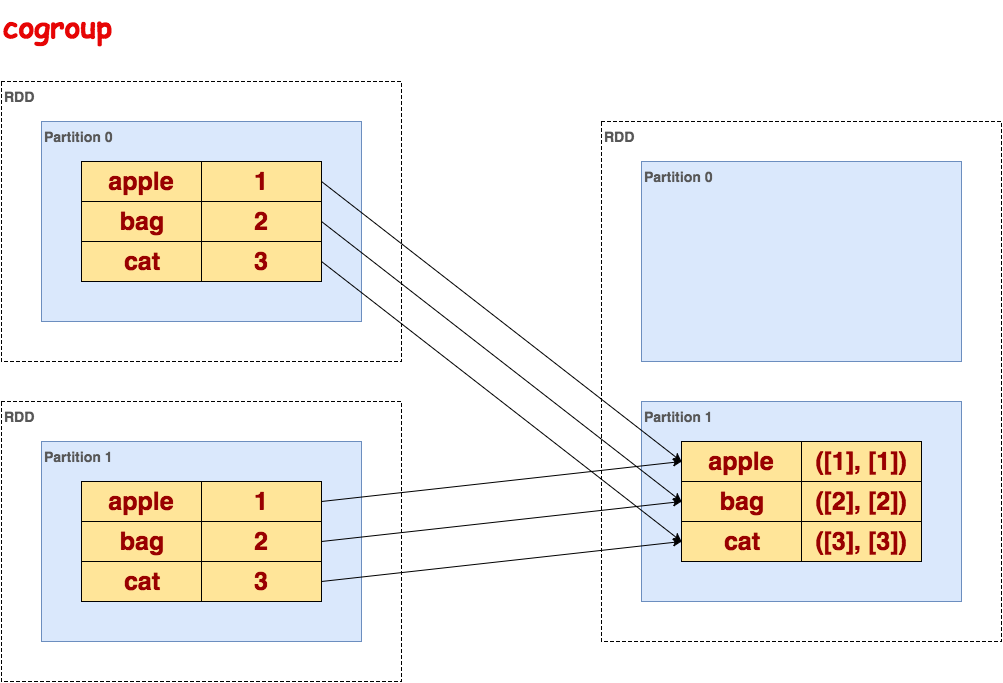
cartesian
笛卡尔积,在类型为 T 和 U 类型的数据集上调用时,返回一个 (T, U)对数据集(两两的元素对)。
代码示例:
>>> sorted_txt = txt.flatMap(lambda line: line.split()).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b).sortByKey() >>> sorted_txt.cogroup(sorted_txt).collect() [(u'bag', (<pyspark.resultiterable.ResultIterable object at 0x1323790>, <pyspark.resultiterable.ResultIterable object at 0x1323310>)), (u'apple', (<pyspark.resultiterable.ResultIterable object at 0x1323990>, <pyspark.resultiterable.ResultIterable object at 0x1323ad0>)), (u'cat', (<pyspark.resultiterable.ResultIterable object at 0x1323110>, <pyspark.resultiterable.ResultIterable object at 0x13230d0>))] >>> sorted_txt.cogroup(sorted_txt).collect()[0][1][0].data [2]示意图:
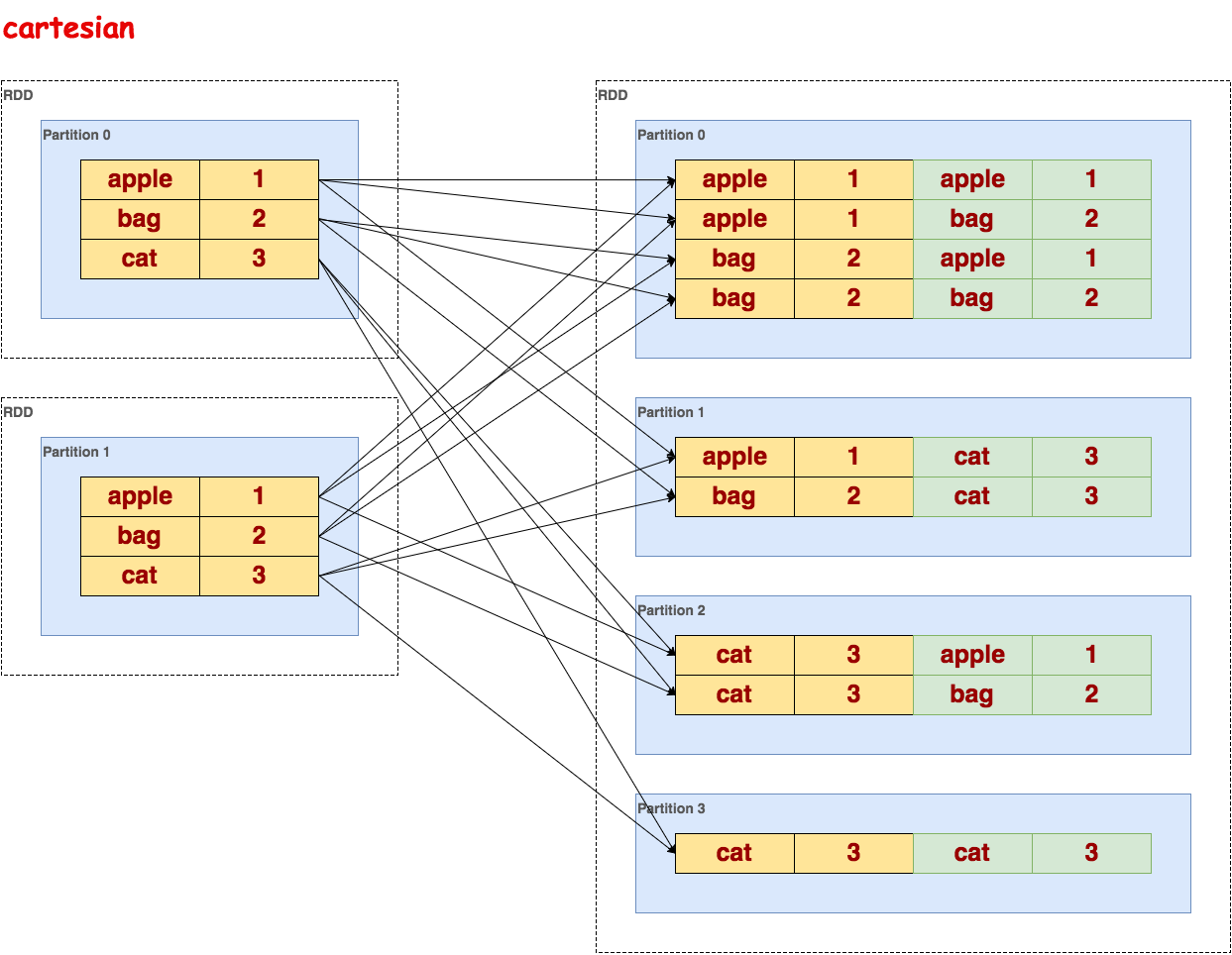
pipe
处理RDD的每一行作为shell命令输入,shell命令结果为输出。
代码示例:
>>> txt.pipe("awk '{print $1}'").collect()
[u'apple', u'bag', u'cat']示意图:

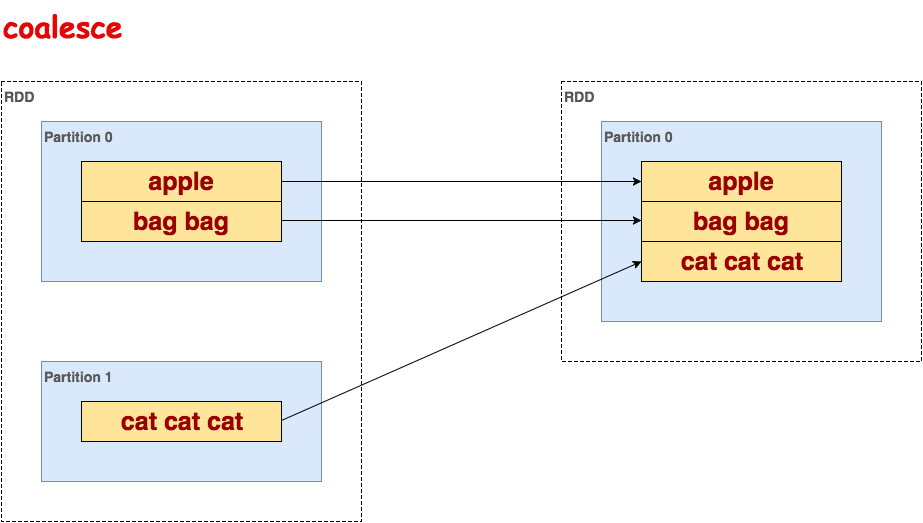
coalesce
减少RDD分区数。
代码示例:
>>> txt.coalesce(1).collect()
[u'apple', u'bag bag', u'cat cat cat']示意图:
repartition
对RDD重新分区,类似于coalesce。
代码示例:
>>> txt.repartition(1).collect()
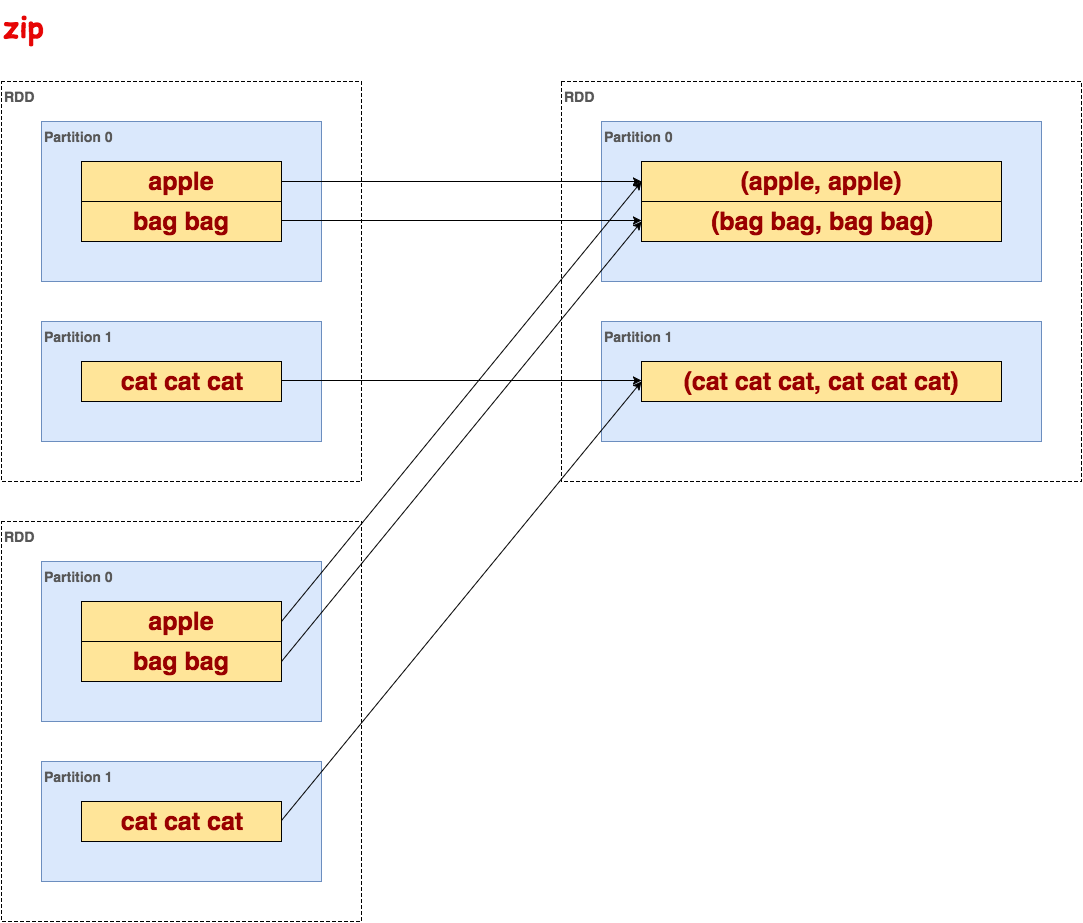
[u'apple', u'bag bag', u'cat cat cat']zip
合并两个RDD序列为元组,要求序列长度相等。
代码示例:
>>> txt.zip(txt).collect()
[(u'apple', u'apple'), (u'bag bag', u'bag bag'), (u'cat cat cat', u'cat cat cat')]示意图:
3. action
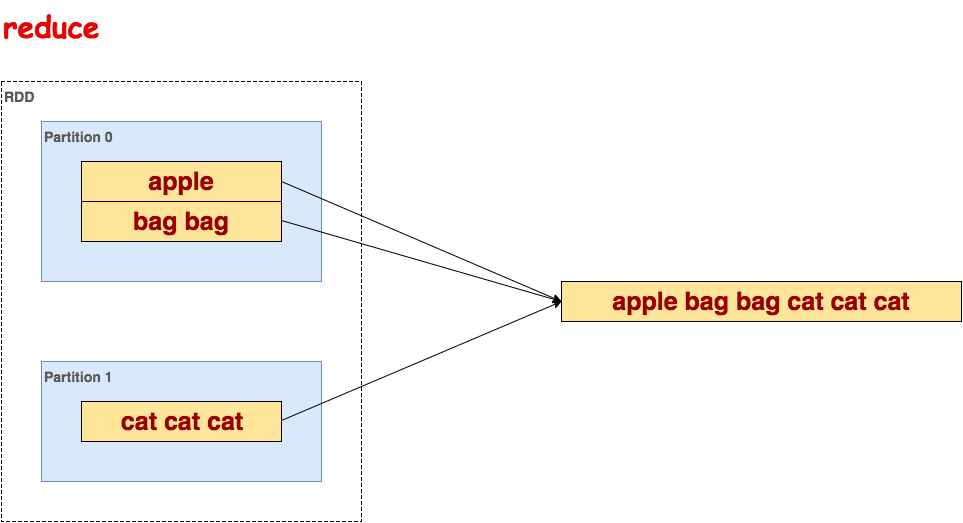
reduce
聚集数据集中的所有元素。
代码示例:
>>> txt.reduce(lambda a, b: a + " " + b) u'apple bag bag cat cat cat'示意图:
collect
以数组的形式,返回数据集的所有元素。
代码示例:
>>> txt.collect()
[u'apple', u'bag bag', u'cat cat cat']count
返回数据集的元素的个数。
代码示例:
>>> txt.count()
3first
返回数据集第一个元素。
代码示例:
>>> txt.first()
u'apple'take
返回数据集前n个元素。
代码示例:
>>> txt.take(2)
[u'apple', u'bag bag']takeSample
采样返回数据集前n个元素。第一个参数表示是否放回抽样,第二个参数表示抽样个数,第三个参数表示随机数seed。
代码示例:
>>> txt.takeSample(False, 2, 1) [u'cat cat cat', u'bag bag']takeOrdered
排序返回前n个元素。
代码示例:
>>> txt.takeOrdered(2)
[u'apple', u'bag bag']saveAsTextFile
将数据集的元素,以textfile的形式,保存到本地文件系统,HDFS或者任何其它hadoop支持的文件系统。
代码示例:
>>> txt.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b).saveAsTextFile("file:///tmp/out")查看输出文件:
$cat /tmp/out/part-00001
(u'bag', 2) (u'apple', 1) (u'cat', 3)saveAsSequenceFile
将数据集的元素,以Hadoop sequencefile的格式,保存到指定的目录下,本地系统,HDFS或者任何其它hadoop支持的文件系统。这个只限于由key-value对组成,并实现了Hadoop的Writable接口,或者隐式的可以转换为Writable的RDD。
countByKey
对(K,V)类型的RDD有效,返回一个(K,Int)对的Map,表示每一个key对应的元素个数。
代码示例:
>>> txt.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1)).countByKey() defaultdict(<type 'int'>, {u'bag': 2, u'apple': 1, u'cat': 3})foreach
在数据集的每一个元素上,运行函数func进行更新。这通常用于边缘效果,例如更新一个累加器,或者和外部存储系统进行交互。
代码示例:
>>> def func(line): print line >>> txt.foreach(lambda line: func(line)) apple bag bag cat cat cat