Java中的HashSet和TreeSet和LinkedHashSet区别
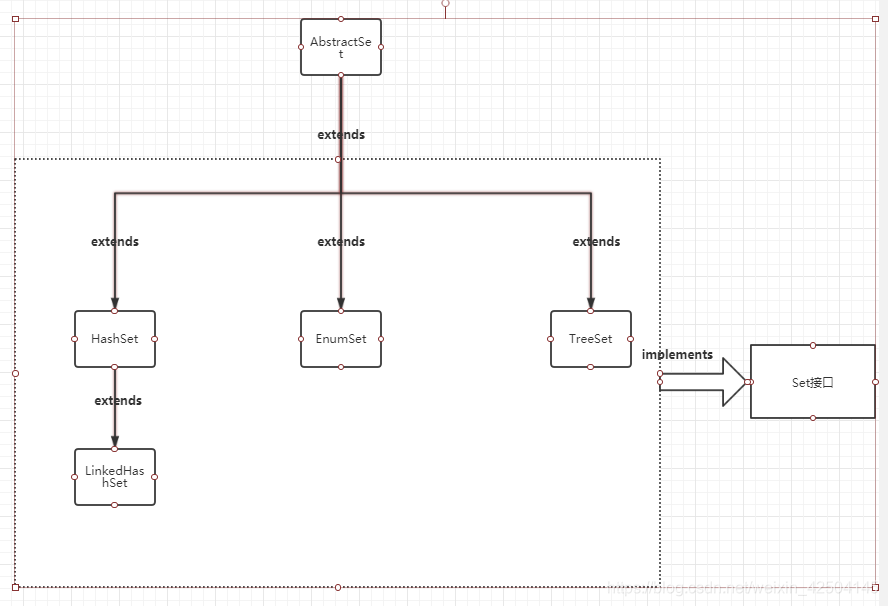
Set接口与三种实现之间的关系
Set是一个不包含重复元素的 collection。无序且唯一。
- HashSet
- LinkedHashSet
- TreeSet
HashSet是使用哈希表(hash table)实现的,其中的元素是无序的。HashSet的add、remove、contains方法 的时间复杂度为常量O(1)。
TreeSet使用树形结构(算法书中的红黑树red-black tree)实现的。TreeSet中的元素是可排序的,但add、remove和contains方法的时间复杂度为O(log(n))。TreeSet还提供了first()、last()、headSet()、tailSet()等方法来操作排序后的集合。
LinkedHashSet介于HashSet和TreeSet之间。它基于一个由链表实现的哈希表,保留了元素插入顺序。LinkedHashSet中基本方法的时间复杂度为O(1)。
~ HashSet
此类实现 Set 接口,由哈希表(实际上是一个 HashMap 实例)支持。它不保证 set 的迭代顺序;特别是它不保证该顺序恒久不变。此类允许使用 null 元素。
注意,此实现不是同步的。如果多个线程同时访问一个哈希 set,而其中至少一个线程修改了该 set,那么它必须 保持外部同步。
HashSet底层数据结构是哈希表(HashMap),哈希表依赖于哈希值存储,添加功能底层依赖两个方法:int hashCode(),boolean equals(Object obj)。
*构造方法

*常用方法

HashSet唯一性的解释,源码剖析:添加功能底层依赖两个方法:int hashCode(),boolean equals(Object obj)
//HashSet类
class HashSet implements Set{
private static final Object PRESENT = new Object();
private transient HashMap<E,Object> map;
// 构造方法,返回了一个HashMap
public HashSet() {
map = new HashMap<>();
}
//add方法
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
}
//HashMap类
class HashMap implements Map{
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
}一个实例问题,在这种添加自定义对象的时候,两个类的属性值相等,但是依然会被判定为不同的元素,因为没有重写hashCode(),所以默认调用的是Object类的hashCode(),而不同类的hashCode一般是不同的。
HashSet<Student> hashSet = new HashSet<>();
Student s1 = new Student("刘亦菲", 22);
Student s2 = new Student("章子怡", 25);
Student s3 = new Student("刘亦菲", 22);
hashSet.add(s1);
hashSet.add(s2);
hashSet.add(s3);
System.out.println(hashSet);解决方法就是自己重写hashCode() 和 equals()方法,使用idea的alt+insert可以自动生成。
public class Student {
private String name;
private Integer age;
Student(String name,int age)
{
this.name=name;
this.age=age;
}
@Override
public int hashCode() {
// return 0;<br> return this.name.hashCode()+this.age*11;
}
@Override
public boolean equals(Object obj) {
if(this == obj)
return true;
if(!(obj instanceof Student))
return false;
Student s = (Student) obj;
return this.name.equals(s.name) && this.age.equals(s.age);
}
}这里用到了instanceof操作符,这个操作符和== ,>=是同种性质的,只是是用英文描述的,是二元操作符,用来判断左边的是否为这个特定类或者是它的子类的一个实例。
~ LinkedHashSet
具有可预知迭代顺序的 Set 接口的哈希表和链接列表实现。此实现与 HashSet 的不同之外在于,后者维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,即按照将元素插入到 set 中的顺序(插入顺序)进行迭代。注意,插入顺序不 受在 set 中重新插入的 元素的影响。
哈希表保证元素的唯一性,链表保证元素有序,也就是存入顺序和取出顺序相同。
~ TreeSet
基于 TreeMap 的 NavigableSet 实现。使用元素的自然顺序对元素进行排序,或者根据创建 set 时提供的 Comparator 进行排序,具体取决于使用的构造方法。
注意,此实现不是同步的。如果多个线程同时访问一个 TreeSet,而其中至少一个线程修改了该 set,那么它必须 外部同步。
有两种排序方式:A-自然排序,也是默认排序(实现Comparable),B-比较器排序。取决于构造方法。
*构造方法

*常用方法
// 会自动排序
TreeSet<Integer> treeSet = new TreeSet<>();
treeSet.add(12);
treeSet.add(13);
treeSet.add(2);
treeSet.add(4);
for(int i:treeSet) System.out.println(i);TreeSet的唯一性解释,源码剖析:唯一性根据比较的返回值是否为0,如果为零,则相等;排序的方式有两种,自然排序和比较器排序。
//TreeSet类
class TreeSet implements Set{
private static final Object PRESENT = new Object();
private transient NavigableMap<E,Object> m;
TreeSet(NavigableMap<E,Object> m) {
this.m = m;
}
public TreeSet() {
this(new TreeMap<>());
}
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}
}
//TreeMap类
class TreeMap implements Map{
<br>//红黑树实现
public V put(K key, V value) {
Entry<K,V> t = root;<br> //建立根节点
if (t == null) {
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
// split comparator and comparable paths
Comparator<? super K> cpr = comparator;
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
else {
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
}对象中的实例,自然排序:具体类实现Comparable接口,重写Comparable方法。构造方法为默认构造
public class Student implements Comparable<Student>{
private String name;
private Integer age;
Student(String name,int age)
{
this.name=name;
this.age=age;
}
// @Override
// public int hashCode() {
// return 0;
// }
//
// @Override
// public boolean equals(Object obj) {
// if(this == obj)
// return true;
//
// if(!(obj instanceof Student))
// return false;
//
// Student s = (Student) obj;
// return this.name.equals(s.name) && this.age.equals(s.age);
// }
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
if (name != null ? !name.equals(student.name) : student.name != null) return false;
return age != null ? age.equals(student.age) : student.age == null;
}
@Override
public int hashCode() {
int result = name != null ? name.hashCode() : 0;
result = 31 * result + (age != null ? age.hashCode() : 0);
return result;
}
@Override
// 从小到大
public int compareTo(Student o) {
int num = this.age-o.age;
return num==0?this.name.compareTo(o.name):num;
}
}对象中的实例,比较器排序:自定义比较器,实现Comparator接口。构造方法为带比较器的构造
class MyComparator implements Comparator<Student>{
@Override
public int compare(Student o1, Student o2) {
int num = o1.age-o2.age;
return num==0?o1.name.compareTo(o2.name):num;
}
}总结:
HashSet
HashSet有以下特点
不能保证元素的排列顺序,顺序有可能发生变化
不是同步的
集合元素可以是null,但只能放入一个null
当向HashSet结合中存入一个元素时,HashSet会调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据 hashCode值来决定该对象在HashSet中存储位置。
简单的说,HashSet集合判断两个元素相等的标准是两个对象通过equals方法比较相等,并且两个对象的hashCode()方法返回值相等
注意,如果要把一个对象放入HashSet中,重写该对象对应类的equals方法,也应该重写其hashCode()方法。其规则是如果两个对象通过equals方法比较返回true时,其 hashCode也应该相同。另外,对象中用作equals比较标准的属性,都应该用来计算 hashCode的值。
TreeSet
TreeSet类型是J2SE中唯一可实现自动排序的类型
TreeSet是SortedSet接口的唯一实现类,TreeSet可以确保集合元素处于排序状态。TreeSet支持两种排序方式,自然排序 和定制排序,其中自然排序为默认的排序方式。向 TreeSet中加入的应该是同一个类的对象。
TreeSet判断两个对象不相等的方式是两个对象通过equals方法返回false,或者通过CompareTo方法比较没有返回0
自然排序
自然排序使用要排序元素的CompareTo(Object obj)方法来比较元素之间大小关系,然后将元素按照升序排列。
Java提供了一个Comparable接口,该接口里定义了一个compareTo(Object obj)方法,该方法返回一个整数值,实现了该接口的对象就可以比较大小。
obj1.compareTo(obj2)方法如果返回0,则说明被比较的两个对象相等,如果返回一个正数,则表明obj1大于obj2,如果是 负数,则表明obj1小于obj2。
如果我们将两个对象的equals方法总是返回true,则这两个对象的compareTo方法返回应该返回0
定制排序
自然排序是根据集合元素的大小,以升序排列,如果要定制排序,应该使用Comparator接口,实现 int compare(To1,To2)方法
LinkedHashSet
LinkedHashSet集合同样是根据元素的hashCode值来决定元素的存储位置,但是它同时使用链表维护元素的次序。这样使得元素看起 来像是以插入顺 序保存的,也就是说,当遍历该集合时候,LinkedHashSet将会以元素的添加顺序访问集合的元素。
LinkedHashSet在迭代访问Set中的全部元素时,性能比HashSet好,但是插入时性能稍微逊色于HashSet。
参考资料: