通用唯一识别码(英语:Universally Unique Identifier,简称UUID)是一种软件建构的标准,亦为自由软件基金会组织在分散式计算环境领域的一部份。
UUID的目的,是让分散式系统中的所有元素,都能有唯一的辨识信息,而不需要通过中央控制端来做辨识信息的指定。如此一来,每个人都可以创建不与其它人冲突的UUID。
一组UUID,是由一串16位组(亦称128位)的16进位数字所构成,是故UUID理论上的总数为216 x 8=2128,约等于3.4 x 1038。也就是说若每纳秒产生1兆个UUID,要花100亿年才会将所有UUID用完。所以无需考虑它的重复性。
UUID的标准型式包含32个16进位数字,以连字号分为五段,形式为8-4-4-4-12的32个字符,加上“-”一共是36位,所以咱们可以先取出uuid,再把“-”去掉。
import java.util.UUID; import org.apache.commons.lang3.RandomStringUtils; public class RandomUtils { public RandomUtils() { } public static String generateTicket() { String ticket = UUID.randomUUID().toString(); return ticket.replaceAll("-", ""); } public static String generateRandomString(int count) { return RandomStringUtils.random(count, true, true); } public static String generateRandomNum(int count) { return RandomStringUtils.random(count, false, true); } public static String generateRandomFileName() { return String.join("", generateTicket(), generateRandomString(6)); } }
<dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-lang3</artifactId> </dependency>
public static void main(String[] args) { byte[] b = {0}; System.out.println(UUID.randomUUID()); System.out.println(UUID.randomUUID()); System.out.println(UUID.nameUUIDFromBytes(b)); System.out.println(UUID.nameUUIDFromBytes(b)); }
上边是代码,下边是结果
feb860b4-9bc2-4bab-8844-83c9a6d22aa6
09289276-0af0-4ee8-9e14-e7a0df30aeb8
93b885ad-fe0d-3089-8df6-34904fd59f71
93b885ad-fe0d-3089-8df6-34904fd59f71
比较明显就是randomUUID()目前还是不重复的,
但是nameUUIDFromBytes()已经重复了
解析:看源码是用byte[]的MD5 生成uuid,也就是根据byte[]生成uuid,所以同一个byte[]返回的结果肯定是相同的。
文章目录
一、解释
二、使用示例
三、原理概述
四、源码解析
五、奇技淫巧
六、参考文献
一、解释
维基百科
UUID 是有一定格式的,满足8-4-4-4-12这种格式,如下面这个 UUID :
6b349832-0470-4692-befd-6037b280bbc5
UUID由32 个字母数字字符组成(没有包括连字符),每一个字符是一个16进制的数字(0-f)。UUID 有一定的结构: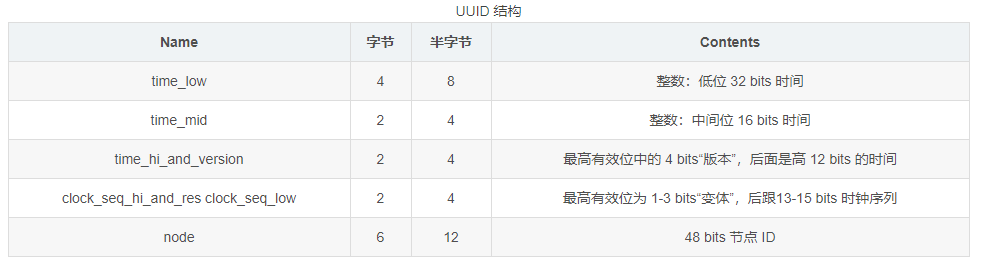
注意:16进制用 半个字节 表示,1个字节等于两个半字节,1个字节等于8位,半字节等于4个位。
UUID产生方式:
“版本1” UUID 是根据时间和节点 ID(通常是MAC地址)生成;
“版本2” UUID是根据标识符(通常是组或用户ID)、时间和节点ID生成;
“版本3” 和 “版本5” 确定性UUID 通过散列 (hashing) 名字空间 (namespace) 标识符和名称生成;
“版本4” UUID 使用随机性或伪随机性生成。
二、使用示例
public static void main(String[] args) { String uuid=""; uuid=UUID.randomUUID().toString(); System.out.println(uuid); }
结果:
60cc1ff0-4b30-4e35-a0a6-940934ac756b
对,在java中产生 UUID 就是这么简单。
三、原理概述
public static void main(String[] args) { byte[] randomBytes = new byte[16];//数组每一个元素都为0,所以需要产生随机的16字节 SecureRandom secureRandom=new SecureRandom(); secureRandom.engineNextBytes(randomBytes); System.out.println(DatatypeConverter.printHexBinary(randomBytes)); /** *为了满足RFC 4122规范,需要对参数这个16个字节的随机数据进行一些设置。这里我们拿用随机方式产生UUID * 随机生成 "版本4" UUID。与其他 UUID 一样,4-bit 用于指示 "版本4",2-bit 或 3-bit 用于指示变体(variant)(10 或 110 分别用于 变体 1 和 2)。 * 因此,对于变体1(即大多数 UUID),随机 "版本4" UUID 将具有 6 个预定的变体和版本位,为随机生成的部分留下122位,"版本4" 变体1 UUID 可能共计2的122次方个。 * "版本4" 变体2 UUID (传统GUID)的可能有一半,因为可用的随机位少一个,变量消耗 3 bits。 */ } }
运行结果:
82D68D2051EAF9610D36C33642E02594
产生大小为16的字节数组(转换为16进制就是32个字符)
为数组赋值(因为产生的初始数组每一个元素都为0)
其实到这里,我们的唯一id就产生了。只不过 UUID 要满足一定的规范,还有对产生的结果进行一些设置。如设置版本,设置变体。最后,我通过javax.xml.bind包下的DatatypeConverter将我们的字节数组以16进制的方式打印出来。
四、源码解析
UUID
public static UUID randomUUID() { SecureRandom ng = Holder.numberGenerator;//用于产生byte型的随机数组。 byte[] randomBytes = new byte[16];//产生大小为16的byte数组 ng.nextBytes(randomBytes);//给byte赋随机值。其实调用的是engineNextBytes。 // UUID 要满足一定的规范,还有对产生的结果进行一些设置。如设置版本,设置变体 randomBytes[6] &= 0x0f; /* clear version */ randomBytes[6] |= 0x40; /* set to version 4 */ randomBytes[8] &= 0x3f; /* clear variant */ randomBytes[8] |= 0x80; /* set to IETF variant */ return new UUID(randomBytes); }
private UUID(byte[] data) { long msb = 0; long lsb = 0; assert data.length == 16 : "data must be 16 bytes in length"; for (int i=0; i<8; i++) //为什么要&0xff?是因为要不能或上一个负数byte,char,short的&都是转换为int的 //因为long类型是64位,在进行|运算时,需要补全0才可以运算 msb = (msb << 8) | (data[i] & 0xff); for (int i=8; i<16; i++) lsb = (lsb << 8) | (data[i] & 0xff); this.mostSigBits = msb; this.leastSigBits = lsb; }
Java中的UUID是用两个long型的变量mostSigBits 、leastSigBits 来存放UUID的。还有需要注意0xff,这是为了避免|上一个负数。为了阐述不能|一个负数,我举个例子:
最后就导致意外情况
五、奇技淫巧
1、long转16进制
long x=15L; String temp=Long.toHexString(x); System.out.println(temp);
结果:f
2、byte数组转16进制
byte[] randomBytes={15,14,12,11,-6}; System.out.println(DatatypeConverter.printHexBinary(randomBytes));
结果:0F0E0C0BFA
六、参考文献
维基百科
JAVA byte数组转化为16进制字符串输出
https://blog.csdn.net/wobushixiaobailian/article/details/86065041