一、为什么要编码?
为了让计算机理解我们的语言,我们假定计算机能够理解的语言为英语,其他语言要能够在计算机中使用必须经过一次翻译,把它翻译成英语,这个翻译的过程就是编码,所以可以想象,只要不 是说英语的国家要想使用计算机就必须要经过编码。
总的来说,编码的原因可以总结为:
计算机中存储信息的最小单元是一个字节,即8个bit,所以能表示的字符范围是0~255。
人类要表示的符号太多,无法用一个字节来完全表示。
二、如何翻译
明白了各种语言需要交流,经过翻译是必要的,势在必行,那又如何翻译呢?
计算机中提供了多种翻译方式,常见的有ASCII,ISO-8859-1,GB2312,GBK,UTF-8,UTF-16等,它们都可以看成做字典, 它们规定了转化的规 则,按照这种规则就可以让计算机正确的表示我们的字符。具体使用那种编码来存储?这就要考虑存储空间重要还是编码的效率重要了(介绍三种常见的)。
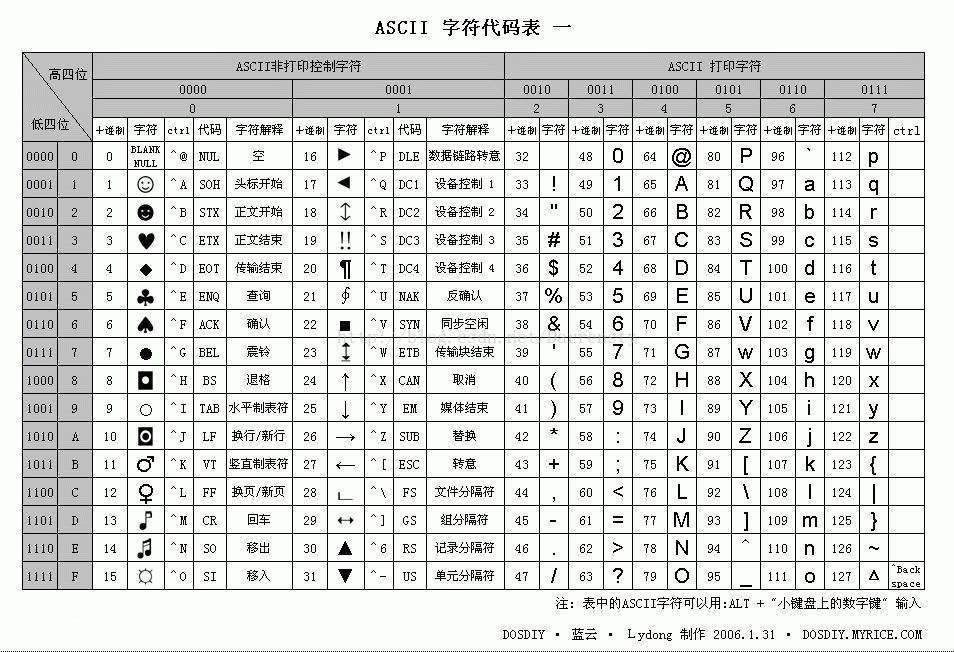
1、ASCII码
大家都知道ASCII码,总共有128个,用一个字节的低7位表示,0-31是控制字符如空格,回车,删除等32-126是打印字符,可以通过键盘输入并且能够显示出来的。
2、UTF-16
说到UTF必须提到Unicode,ISO试图创建一个全新的超语言字典,世界上所有的语言都可以通过这本字典相互翻译,可想而知这本字典是多么复杂的了,关于Unicode的详细规范可以参考相应文档。Unicode是java和xml的基础,那UTF-16具体怎么样定义了Unicode字符在计算机中的存取方法呢?
UTF-16用俩个字节来表示Unicode转化格式,它是定长的表示方法,不论什么字符都可以用俩个字节表示,俩个字节是16bit,所以叫UTF-16。UTF-16表示字符非常方便,每俩个字节表示一个字符,这就大大简化了字符串操作,这也是java以UTF-16作为内存的字符存储格式的一个很重要的原因。
3、UTF-8
UTF-16统一采用俩个字节表示一个字符,虽然表示上简单方便了,但是也有其缺点,有很大一部分字符用一个字节就可以表示的现在却要俩个字节表示,存储空间放大了一倍,在现在的网络带宽还非常有限的情况下,这样会增大网络传输的流量。UTF-8采用了一种变长技术,每个编码区域有不同的字码长度,不同类型的字符可以由1-6个字节来组成。
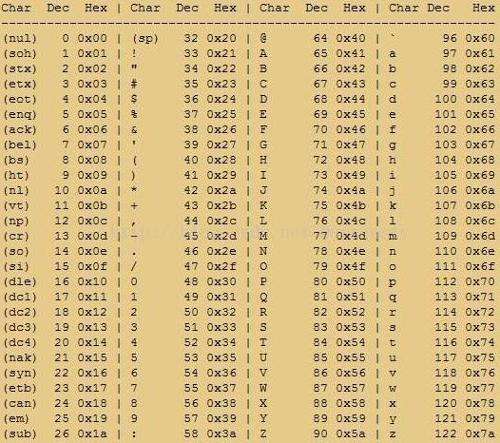
图2-Unicode码
下一篇将介绍-java中需要编码的场景
文章借鉴于 《In-depth analysis of java web insider》