一、java web中涉及的编解码
我们都知道对于中文来说,有I/O的地方就会涉及编码,前面已经提到了I/O操作会引起编码,而大部分I/O引起的乱码都是网络I/O,因为现在几乎所有的应用程序都涉及网络操作,而数据经过网络传输都是以字节为单位的,所以所有的数据都必须能够被序列化为字节。在java中数据要被序列化必须继承Serializable接口。
这里有一个问题,你是否认真考虑过一段文本它的实际大小应该怎么计算,我曾经碰到过一个问题,就是想办法压缩Cookie大小,减少网络传输量,当时有选择不能的压缩算法,发现压缩后字符数是减少了,但是并没有减少字节数。所谓的压缩只是将多个单字节字符通过编码转变成一个多字节字符,减少的是String.length(),而并没有减少最终的字节数。例如,整型数字1234567如果当成字符来存储,采用UTF-8来编码占用7个字节,采用UTF-16编码会占用14个字节,但是把它当成int型数字来存储只需要4个字节来存储,所以看一段文本的大小,看字符本身的长度是没有意义的,即使是一样的字符采用不同的编码最终存储的大小也会不同,所以从字符到字节一定要看编码类型。
另外一个问题,你是否考虑过当我们在电脑中某个文本编辑器里输入某个汉字时,它到底是怎么表示的?我们都知道,计算机里所有的信息都是0和1表示的,那么一个汉字,他到底是多少个0和1呢?
我们能够看到的汉字都是字符形式出现的,例如,在java中“淘宝”俩个字符在计算机中的数值十进制是28120和23453,16进制6bd8和5d9d,也就是这俩个字符是由这俩个数字唯一表示的,java中的一个char是16个bit,相当于俩个字节,所以俩个汉字用char表示在内存中占用相当于4个字节的空间。
步入正题,下面我们来看一下java Web中哪些地方可能会存在编码转换。
用户从浏览器端发起一个http请求,需要存在编码的地方是URL,Cookie,Paramiter。服务器端接收到HTTP请求后要解析HTTP协议,其中URL,Cookie和POST表单参数需要解码,服务器端可能还需要读取数据库中的数据--本地或网络中其他地方的文本文件,这些数据都可能存在编码问题,当servlet处理完所有请求的数据后,需要将这些数据在编码通过Socket发送到用户请求的浏览器里,再经过浏览器解码成为文本。过程如图3-1。
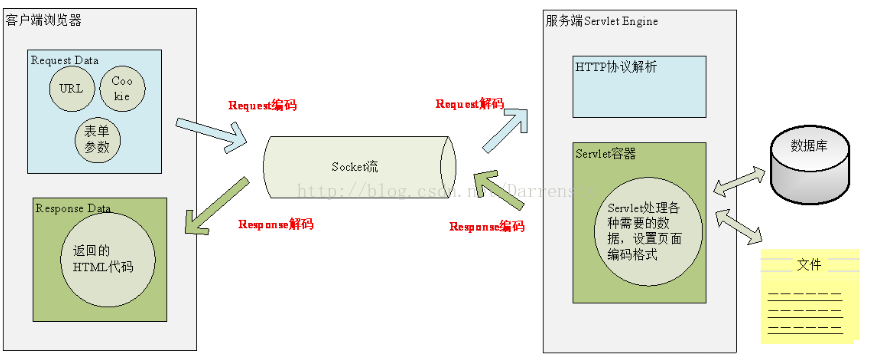
3.1URL的编解码
用户提交一个URL,这个url中可能存在中文,因此需要编码,如何对这个URL进行编码?根据什么规则来编码?又如何来解码?图3-2介绍URL的几个组成部分。
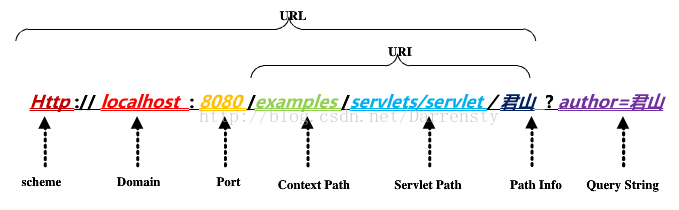
以Tomcat作为Servlet Engine为例,它们分别对应到下面这些配置文件中,Port对应在Tomcat的<Connector port="8080"/>中配置,而Context Path在<Context Path="/examples"/>中配置,Servlet Path在Web应用的web.xml中的<url-pattern>中配置,PathInfo是我们请求的具体的Servlet,QueryString是要传递的参数。注意这里是在浏览器里直接输入URL,所以是通过GET方法请求的,如果是POST方法请求的,QueryString将通过表单方式提交到服务器端。在PathInfo和QueryString部分出现了中文,当我们在浏览器中直接输入这个URL时,在浏览器和服务器端会如何编码和解析这个URL呢?大家有想过吗?为了验证浏览器是怎么编码url的。我们选择google浏览器察看请求URL的实际内容。以下是请求结果
对Header中的项进行解码也是在调用request.getHeader时进行的,如果请求的Header项没有解码则调用MessageBytes的toString的方法,这个方法将从byte到char的转化使用的默认编码也是IOS-8859-1,而我们也不能设置Header的其他解码格式,所以你设置的Header中有非ASCII字符解码肯定会乱码。我们在添加Header时也是同样的道理,不要在Header中传递非ASCII字符,如果一定要传递,可以先将这些字符用org.apache.catalina.util.URLEncoder编码,然后在添加到Header中,这样浏览器到服务器的传递过程就不会丢失信息了,我们要访问这些项时再按照相应的字符集解码就好了。
3.3POST表单的编解码
前面提到了POST表单提交的参数的解码是在第一次调用request.getParameter时发生的,POST表单参数传递方式与QueryString不同,它是通过HTTP的BODY传递到服务端的,当我们在页面上单击提交按钮时浏览器首先将根据ContentType的Charset编码格式对表单填的参数进行编码,然后提交到服务器端,在服务器端同样也是用contentType中的字符集进行解码的,所以通过POST表单提交的参数一般不会出现问题,而且这个字符集编码是我们自己设置的,可以通过request.setCharacterEncoding(charset)来设置。
注意,一定要在第一次调用request.getParameter方法之前就设置request.setCharacterEncoding(charset),否则你的POST表单提交上来的数据也可能出现乱码。
java编码-完!
文章借鉴于 《In-depth analysis of java web insider》