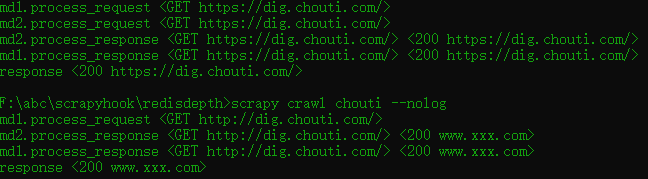
执行流程
1.引擎找到要执行的爬虫,并执行爬虫的start_requests方法,并得到一个迭代器
2.迭代器循环时候会获取到Request对象,而request对象中封装了要访问的url和回调函数
3.将所有的request对象(任务)放到调度器中,用于以后被下载器下载
4.下载器去调度器中获取要下载任务(就是Request对象),下载完成后执行回调函数
5.回到spider的回调函数中
yield Resquest()
yield Item()
下载中间件(之前代理就是下载中间件做的)
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 from scrapy.http import HtmlResponse 4 from scrapy.http import Request 5 6 7 class Md1(object): 8 9 @classmethod 10 def from_crawler(cls, crawler): 11 # This method is used by Scrapy to create your spiders. 12 s = cls() 13 return s 14 15 def process_request(self, request, spider): 16 # Called for each request that goes through the downloader 17 # middleware. 18 19 # Must either: 20 # - return None: continue processing this request 21 # - or return a Response object 22 # - or return a Request object 23 # - or raise IgnoreRequest: process_exception() methods of 24 # installed downloader middleware will be called 25 print('md1.process_request', request) 26 # return None # 默认返回None 27 # 1.返回Response对象 28 # 如果有返回值md2的process_request都不执行了,直接跳到最后一个中间件的process_response方法一层层的返回, 29 # 而在django中,它会从当前中间件的process_response直接返回(这点和Django有点大不相同) 30 # 而且中间件我直接截获了 伪造之前的url,我自己去www.xxx.com下载,下载的结果body 31 # url = request.url 32 # return HtmlResponse(url='www.xxx.com', status=200, headers=None, body=b'innerjob') 33 # import requests 34 # result = requests.get(request.url) 35 # return HtmlResponse(url=request.url, status=200, headers=None, body=result.content) 36 37 # 2.返回Request对象 这样的话就会在一直转圈,来回跑到调度器 38 # return Request(url='https://dig.chouti.com/r/tec/hot/1') 39 40 # 3.抛出异常 就必须写上process_exception()方法 不然报错 41 # from scrapy.exceptions import IgnoreRequest 42 # raise IgnoreRequest 43 44 # 4.一般是对请求加工 但是这个功能内置有了 加cookie也都可以各种加东西内置也有了cookie 45 request.headers['user_agent'] = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36' 46 47 def process_response(self, request, response, spider): 48 # Called with the response returned from the downloader. 49 50 # Must either; 51 # - return a Response object 52 # - return a Request object 53 # - or raise IgnoreRequest 54 print('md1.process_response', request, response) 55 return response 56 57 def process_exception(self, request, exception, spider): 58 # Called when a download handler or a process_request() 59 # (from other downloader middleware) raises an exception. 60 61 # Must either: 62 # - return None: continue processing this exception 63 # - return a Response object: stops process_exception() chain 64 # - return a Request object: stops process_exception() chain 65 pass 66 67 68 class Md2(object): 69 70 def process_request(self, request, spider): 71 # Called for each request that goes through the downloader 72 # middleware. 73 74 # Must either: 75 # - return None: continue processing this request 76 # - or return a Response object 77 # - or return a Request object 78 # - or raise IgnoreRequest: process_exception() methods of 79 # installed downloader middleware will be called 80 print('md2.process_request', request) 81 return None 82 83 def process_response(self, request, response, spider): 84 # Called with the response returned from the downloader. 85 86 # Must either; 87 # - return a Response object 88 # - return a Request object 89 # - or raise IgnoreRequest 90 print('md2.process_response', request, response) 91 return response 92 93 def process_exception(self, request, exception, spider): 94 # Called when a download handler or a process_request() 95 # (from other downloader middleware) raises an exception. 96 97 # Must either: 98 # - return None: continue processing this exception 99 # - return a Response object: stops process_exception() chain 100 # - return a Request object: stops process_exception() chain 101 pass
应用
1 DOWNLOADER_MIDDLEWARES = { 2 # 'redisdepth.middlewares.RedisdepthDownloaderMiddleware': 543, 3 # 'redisdepth.md.Md1': 666, 4 # 'redisdepth.md.Md2': 667 5 }
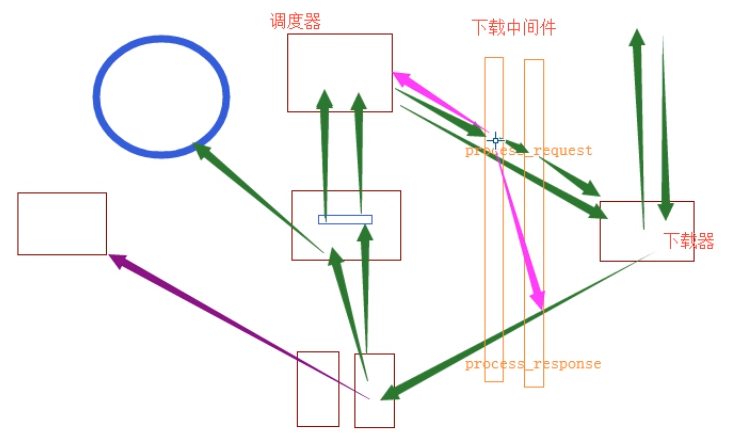
流程图:
爬虫中间件(之前深度就是这样子做的)
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 4 5 class Sd1(object): 6 # Not all methods need to be defined. If a method is not defined, 7 # scrapy acts as if the spider middleware does not modify the 8 # passed objects. 9 10 @classmethod 11 def from_crawler(cls, crawler): 12 # This method is used by Scrapy to create your spiders. 13 s = cls() 14 # crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) #这是关于扩展需要用的先不看 信号,在Django里边也有信号这个东西 15 return s 16 17 def process_spider_input(self, response, spider): 18 # Called for each response that goes through the spider 19 # middleware and into the spider. 20 21 # Should return None or raise an exception. 22 # 下载完成之后执行,然后交给parse处理 23 return None 24 25 def process_spider_output(self, response, result, spider): 26 # Called with the results returned from the Spider, after 27 # it has processed the response. 28 29 # Must return an iterable of Request, dict or Item objects. 30 # spider处理完成 31 for i in result: 32 yield i 33 34 def process_spider_exception(self, response, exception, spider): 35 # Called when a spider or process_spider_input() method 36 # (from other spider middleware) raises an exception. 37 38 # Should return either None or an iterable of Request, dict 39 # or Item objects. 40 # 异常调用 41 # return: None,继续交给后续中间件处理异常;含 Response 或 Item 的可迭代对象(iterable),交给调度器或pipeline 42 pass 43 44 # 只在爬虫启动时候,只执行一次 读取最开始爬虫start_requests方法中返回生成器的 然后循环在这儿一个个的返回 45 def process_start_requests(self, start_requests, spider): 46 # Called with the start requests of the spider, and works 47 # similarly to the process_spider_output() method, except 48 # that it doesn’t have a response associated. 49 50 # Must return only requests (not items). 51 for r in start_requests: 52 yield r 53 54 def spider_opened(self, spider): 55 spider.logger.info('Spider opened: %s' % spider.name) 56 57 58 class Sd2(object): 59 # Not all methods need to be defined. If a method is not defined, 60 # scrapy acts as if the spider middleware does not modify the 61 # passed objects. 62 63 @classmethod 64 def from_crawler(cls, crawler): 65 # This method is used by Scrapy to create your spiders. 66 s = cls() 67 # crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) #这是关于扩展需要用的先不看 信号,在Django里边也有信号这个东西 68 return s 69 70 def process_spider_input(self, response, spider): 71 # Called for each response that goes through the spider 72 # middleware and into the spider. 73 74 # Should return None or raise an exception. 75 return None 76 77 def process_spider_output(self, response, result, spider): 78 # Called with the results returned from the Spider, after 79 # it has processed the response. 80 81 # Must return an iterable of Request, dict or Item objects. 82 for i in result: 83 yield i 84 85 def process_spider_exception(self, response, exception, spider): 86 # Called when a spider or process_spider_input() method 87 # (from other spider middleware) raises an exception. 88 89 # Should return either None or an iterable of Request, dict 90 # or Item objects. 91 pass 92 93 def process_start_requests(self, start_requests, spider): 94 # Called with the start requests of the spider, and works 95 # similarly to the process_spider_output() method, except 96 # that it doesn’t have a response associated. 97 98 # Must return only requests (not items). 99 for r in start_requests: 100 yield r 101 102 def spider_opened(self, spider): 103 spider.logger.info('Spider opened: %s' % spider.name)
应用
1 SPIDER_MIDDLEWARES = { 2 # 'redisdepth.middlewares.RedisdepthSpiderMiddleware': 543, 3 'redisdepth.sd.Sd1': 666, 4 'redisdepth.sd.Sd2': 667, 5 6 }
流程图

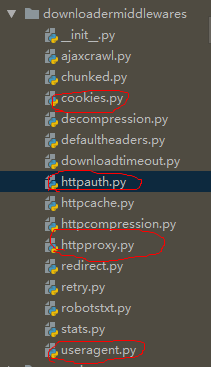
内置的下载中间件
内置的爬虫中间件
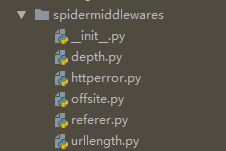
这是做实验的截图