介绍
中间件是Scrapy里面的一个核心概念。使用中间件可以在爬虫的请求发起之前或者请求返回之后对数据进行定制化修改,从而开发出适应不同情况的爬虫。
“中间件”这个中文名字和前面章节讲到的“中间人”只有一字之差。它们做的事情确实也非常相似。中间件和中间人都能在中途劫持数据,做一些修改再把数据传递出去。不同点在于,中间件是开发者主动加进去的组件,而中间人是被动的,一般是恶意地加进去的环节。中间件主要用来辅助开发,而中间人却多被用来进行数据的窃取、伪造甚至攻击。
在Scrapy中有两种中间件:下载器中间件(Downloader Middleware)和爬虫中间件(Spider Middleware)。
Scrapy的官方文档中,对下载器中间件的解释如下。
下载器中间件是介于Scrapy的request/response处理的钩子框架,是用于全局修改Scrapy request和response的一个轻量、底层的系统。
这个介绍看起来非常绕口,但其实用容易理解的话表述就是:更换代理IP,更换Cookies,更换User-Agent,自动重试。
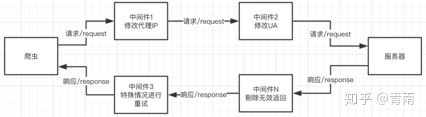
如果完全没有中间件,爬虫的流程如下图所示。

使用了中间件以后,爬虫的流程如下图所示。
代理中间件
在爬虫开发中,更换代理IP是非常常见的情况,有时候每一次访问都需要随机选择一个代理IP来进行。
中间件本身是一个Python的类,只要爬虫每次访问网站之前都先“经过”这个类,它就能给请求换新的代理IP,这样就能实现动态改变代理。
在创建一个Scrapy工程以后,工程文件夹下会有一个middlewares.py文件,打开以后其内容如下
from scrapy import signals class MeiziDownloaderMiddleware(object): # Not all methods need to be defined. If a method is not defined, # scrapy acts as if the downloader middleware does not modify the # passed objects. @classmethod def from_crawler(cls, crawler): # This method is used by Scrapy to create your spiders. s = cls() crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) return s def process_request(self, request, spider): # Called for each request that goes through the downloader # middleware. # Must either: # - return None: continue processing this request # - or return a Response object # - or return a Request object # - or raise IgnoreRequest: process_exception() methods of # installed downloader middleware will be called return None def process_response(self, request, response, spider): # Called with the response returned from the downloader. # Must either; # - return a Response object # - return a Request object # - or raise IgnoreRequest return response def process_exception(self, request, exception, spider): # Called when a download handler or a process_request() # (from other downloader middleware) raises an exception. # Must either: # - return None: continue processing this exception # - return a Response object: stops process_exception() chain # - return a Request object: stops process_exception() chain pass def spider_opened(self, spider): spider.logger.info('Spider opened: %s' % spider.name)
Scrapy自动生成的这个文件名称为middlewares.py,名字后面的s表示复数,说明这个文件里面可以放很多个中间件。Scrapy自动创建的这个中间件是一个爬虫中间件,这种类型在第三篇文章会讲解。现在先来创建一个自动更换代理IP的中间件。
在middlewares.py中添加下面一段代码:
class ProxyMiddleware(object): def process_request(self, request, spider): proxy = random.choice(settings['PROXIES']) request.meta['proxy'] = proxy
要修改请求的代理,就需要在请求的meta里面添加一个Key为proxy,Value为代理IP的项。
由于用到了random和settings,所以需要在middlewares.py开头导入它们:
import random from scrapy.conf import settings
在下载器中间件里面有一个名为process_request()的方法,这个方法中的代码会在每次爬虫访问网页之前执行。
打开settings.py,首先添加几个代理IP:
PROXIES = ['https://114.217.243.25:8118', 'https://125.37.175.233:8118', 'http://1.85.116.218:8118']
需要注意的是,代理IP是有类型的,需要先看清楚是HTTP型的代理IP还是HTTPS型的代理IP。如果用错了,就会导致无法访问。
激活中间件
中间件写好以后,需要去settings.py中启动。在settings.py中找到下面这一段被注释的语句:
# Enable or disable downloader middlewares # See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html #DOWNLOADER_MIDDLEWARES = { # 'AdvanceSpider.middlewares.MyCustomDownloaderMiddleware': 543, #}
解除注释并修改,从而引用ProxyMiddleware。修改为:
DOWNLOADER_MIDDLEWARES = { 'AdvanceSpider.middlewares.ProxyMiddleware': 543, }
这其实就是一个字典,字典的Key就是用点分隔的中间件路径,后面的数字表示这种中间件的顺序。由于中间件是按顺序运行的,因此如果遇到后一个中间件依赖前一个中间件的情况,中间件的顺序就至关重要。
如何确定后面的数字应该怎么写呢?最简单的办法就是从543开始,逐渐加一,这样一般不会出现什么大问题。如果想把中间件做得更专业一点,那就需要知道Scrapy自带中间件的顺序,如下所示。
DOWNLOADER_MIDDLEWARES_BASE { 'scrapy.contrib.downloadermiddleware.robotstxt.RobotsTxtMiddleware': 100, 'scrapy.contrib.downloadermiddleware.httpauth.HttpAuthMiddleware': 300, 'scrapy.contrib.downloadermiddleware.downloadtimeout.DownloadTimeoutMiddleware': 350, 'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': 400, 'scrapy.contrib.downloadermiddleware.retry.RetryMiddleware': 500, 'scrapy.contrib.downloadermiddleware.defaultheaders.DefaultHeadersMiddleware': 550, 'scrapy.contrib.downloadermiddleware.redirect.MetaRefreshMiddleware': 580, 'scrapy.contrib.downloadermiddleware.httpcompression.HttpCompressionMiddleware': 590, 'scrapy.contrib.downloadermiddleware.redirect.RedirectMiddleware': 600, 'scrapy.contrib.downloadermiddleware.cookies.CookiesMiddleware': 700, 'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware': 750, 'scrapy.contrib.downloadermiddleware.chunked.ChunkedTransferMiddleware': 830, 'scrapy.contrib.downloadermiddleware.stats.DownloaderStats': 850, 'scrapy.contrib.downloadermiddleware.httpcache.HttpCacheMiddleware': 900, }
数字越小的中间件越先执行,例如Scrapy自带的第1个中间件RobotsTxtMiddleware,它的作用是首先查看settings.py中ROBOTSTXT_OBEY这一项的配置是True还是False。如果是True,表示要遵守Robots.txt协议,它就会检查将要访问的网址能不能被运行访问,如果不被允许访问,那么直接就取消这一次请求,接下来的和这次请求有关的各种操作全部都不需要继续了。
开发者自定义的中间件,会被按顺序插入到Scrapy自带的中间件中。爬虫会按照从100~900的顺序依次运行所有的中间件。直到所有中间件全部运行完成,或者遇到某一个中间件而取消了这次请求。
Scrapy其实自带了UA中间件(UserAgentMiddleware)、代理中间件(HttpProxyMiddleware)和重试中间件(RetryMiddleware)。所以,从“原则上”说,要自己开发这3个中间件,需要先禁用Scrapy里面自带的这3个中间件。要禁用Scrapy的中间件,需要在settings.py里面将这个中间件的顺序设为None:
DOWNLOADER_MIDDLEWARES = { 'AdvanceSpider.middlewares.ProxyMiddleware': 543, 'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': None, 'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware': None }
配置好以后运行爬虫,爬虫会在每次请求前都随机设置一个代理。要测试代理中间件的运行效果,可以使用下面这个练习页面:
http://httpbin.org/get
这个页面会返回爬虫的IP地址;
案例演示:
免费代理:http://www.goubanjia.com/


import scrapy import json class MeinvSpider(scrapy.Spider): name = 'meinv' # allowed_domains = ['www.xxx.com'] start_urls = ['http://httpbin.org/get'] def parse(self, response): str_info = response.body.decode() dic_info = json.loads(str_info) print(dic_info["origin"])
import random from meizi.settings import PROXIES class ProxyMiddleware(object): def process_request(self, request, spider): proxy = random.choice(PROXIES) request.meta['proxy'] = proxy return None
# 代理池 PROXIES = ['http://117.191.11.102:80', 'http://117.191.11.107:80', 'http://117.191.11.72:8080'] # 开启代理中间件 DOWNLOADER_MIDDLEWARES = { 'meizi.middlewares.ProxyMiddleware': 543, }
输入信息

UA中间件
开发UA中间件和开发代理中间件几乎一样,它也是从settings.py配置好的UA列表中随机选择一项,加入到请求头中。代码如下:
class UAMiddleware(object): def process_request(self, request, spider): ua = random.choice(settings['USER_AGENT_LIST']) request.headers['User-Agent'] = ua
比IP更好的是,UA不会存在失效的问题,所以只要收集几十个UA,就可以一直使用。常见的UA如下:
USER_AGENT_LIST = [ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36", "Dalvik/1.6.0 (Linux; U; Android 4.2.1; 2013022 MIUI/JHACNBL30.0)", "Mozilla/5.0 (Linux; U; Android 4.4.2; zh-cn; HUAWEI MT7-TL00 Build/HuaweiMT7-TL00) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1", "AndroidDownloadManager", "Apache-HttpClient/UNAVAILABLE (java 1.4)", "Dalvik/1.6.0 (Linux; U; Android 4.3; SM-N7508V Build/JLS36C)", "Android50-AndroidPhone-8000-76-0-Statistics-wifi", "Dalvik/1.6.0 (Linux; U; Android 4.4.4; MI 3 MIUI/V7.2.1.0.KXCCNDA)", "Dalvik/1.6.0 (Linux; U; Android 4.4.2; Lenovo A3800-d Build/LenovoA3800-d)", "Lite 1.0 ( http://litesuits.com )", "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727)", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36 SE 2.X MetaSr 1.0", "Mozilla/5.0 (Linux; U; Android 4.1.1; zh-cn; HTC T528t Build/JRO03H) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30; 360browser(securitypay,securityinstalled); 360(android,uppayplugin); 360 Aphone Browser (2.0.4)", ]
配置好UA以后,在settings.py下载器中间件里面激活它,并使用UA练习页来验证UA是否每一次都不一样。练习页的地址为:
http://httpbin.org/get
案例演示:
import scrapy import json class MeinvSpider(scrapy.Spider): name = 'meinv' # allowed_domains = ['www.xxx.com'] start_urls = ['http://httpbin.org/get'] def parse(self, response): str_info = response.body.decode() dic_info = json.loads(str_info) print(dic_info["headers"]['User-Agent'])
import random from meizi.settings import USER_AGENT_LIST class UAMiddleware(object): def process_request(self, request, spider): ua = random.choice(USER_AGENT_LIST) request.headers['User-Agent'] = ua return None
USER_AGENT_LIST = [ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36", "Dalvik/1.6.0 (Linux; U; Android 4.2.1; 2013022 MIUI/JHACNBL30.0)", "Mozilla/5.0 (Linux; U; Android 4.4.2; zh-cn; HUAWEI MT7-TL00 Build/HuaweiMT7-TL00) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1", "AndroidDownloadManager", "Apache-HttpClient/UNAVAILABLE (java 1.4)", "Dalvik/1.6.0 (Linux; U; Android 4.3; SM-N7508V Build/JLS36C)", "Android50-AndroidPhone-8000-76-0-Statistics-wifi", "Dalvik/1.6.0 (Linux; U; Android 4.4.4; MI 3 MIUI/V7.2.1.0.KXCCNDA)", "Dalvik/1.6.0 (Linux; U; Android 4.4.2; Lenovo A3800-d Build/LenovoA3800-d)", "Lite 1.0 ( http://litesuits.com )", "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727)", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36 SE 2.X MetaSr 1.0", "Mozilla/5.0 (Linux; U; Android 4.1.1; zh-cn; HTC T528t Build/JRO03H) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30; 360browser(securitypay,securityinstalled); 360(android,uppayplugin); 360 Aphone Browser (2.0.4)", ] DOWNLOADER_MIDDLEWARES = { 'meizi.middlewares.ProxyMiddleware': None, 'meizi.middlewares.UAMiddleware': 543, }
输入结果:

Cookies中间件
对于需要登录的网站,可以使用Cookies来保持登录状态。那么如果单独写一个小程序,用Selenium持续不断地用不同的账号登录网站,就可以得到很多不同的Cookies。由于Cookies本质上就是一段文本,所以可以把这段文本放在Redis里面。这样一来,当Scrapy爬虫请求网页时,可以从Redis中读取Cookies并给爬虫换上。这样爬虫就可以一直保持登录状态。
以下面这个练习页面为例:
http://exercise.kingname.info/exercise_login_success
如果直接用Scrapy访问,得到的是登录界面的源代码,如下图所示。
