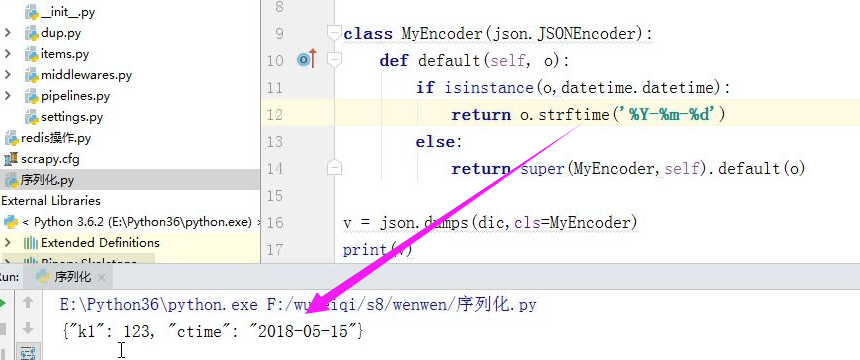
中间件
注意:这些中间件都放在middleware中
下载中间件
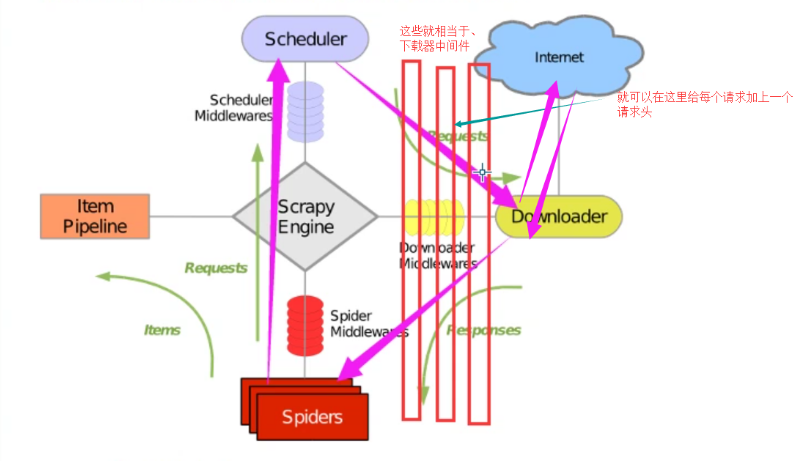
作用

实例:
代理被封,添加代理
方式一:内置添加代理功能
import os
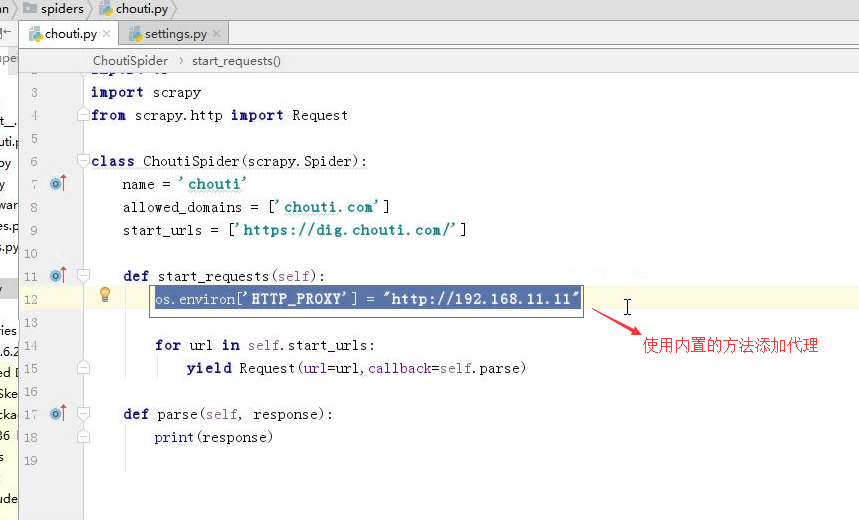


# -*- coding: utf-8 -*- import os import scrapy from scrapy.http import Request class ChoutiSpider(scrapy.Spider): name = 'chouti' allowed_domains = ['chouti.com'] start_urls = ['https://dig.chouti.com/'] def start_requests(self): os.environ['HTTP_PROXY'] = "http://192.168.11.11" for url in self.start_urls: yield Request(url=url,callback=self.parse) def parse(self, response): print(response)
方法二:自定义中间件添加代理 (有多个代理的时候,而且想要随机循环的使用某个代理,防止被封) 常用此方法,

然后再在middleware.py中添加上自定义的propxy类 和一个方法
代码如下:
import random import base64 import six def to_bytes(text, encoding=None, errors='strict'): """Return the binary representation of `text`. If `text` is already a bytes object, return it as-is.""" if isinstance(text, bytes): return text if not isinstance(text, six.string_types): raise TypeError('to_bytes must receive a unicode, str or bytes ' 'object, got %s' % type(text).__name__) if encoding is None: encoding = 'utf-8' return text.encode(encoding, errors) class MyProxyDownloaderMiddleware(object): def process_request(self, request, spider): proxy_list = [ {'ip_port': '111.11.228.75:80', 'user_pass': 'xxx:123'}, {'ip_port': '120.198.243.22:80', 'user_pass': ''}, {'ip_port': '111.8.60.9:8123', 'user_pass': ''}, {'ip_port': '101.71.27.120:80', 'user_pass': ''}, {'ip_port': '122.96.59.104:80', 'user_pass': ''}, {'ip_port': '122.224.249.122:8088', 'user_pass': ''}, ] proxy = random.choice(proxy_list) if proxy['user_pass'] is not None: request.meta['proxy'] = to_bytes("http://%s" % proxy['ip_port']) encoded_user_pass = base64.encodestring(to_bytes(proxy['user_pass'])) request.headers['Proxy-Authorization'] = to_bytes('Basic ' + encoded_user_pass) else: request.meta['proxy'] = to_bytes("http://%s" % proxy['ip_port']) 配置: DOWNLOADER_MIDDLEWARES = { # 'xiaohan.middlewares.MyProxyDownloaderMiddleware': 543, }
问题2

如果被爬取的网站是自己花钱买的证书(此证书就是为了防止用户发送的数据在中间环节被截获,没有证书相关的解密方式无法解析),可以直接正常爬取
如果是网站么钱,自己写的证书,发送爬取数据的时候,必须携带证书文件,才能爬取数据
方法: 现在Middleware.py中写入这些代码,然后再在配置文件中写上那两行配置(代码)
20. Https访问 Https访问时有两种情况: 1. 要爬取网站使用的可信任证书(默认支持) DOWNLOADER_HTTPCLIENTFACTORY = "scrapy.core.downloader.webclient.ScrapyHTTPClientFactory" DOWNLOADER_CLIENTCONTEXTFACTORY = "scrapy.core.downloader.contextfactory.ScrapyClientContextFactory" 2. 要爬取网站使用的自定义证书 DOWNLOADER_HTTPCLIENTFACTORY = "scrapy.core.downloader.webclient.ScrapyHTTPClientFactory" DOWNLOADER_CLIENTCONTEXTFACTORY = "step8_king.https.MySSLFactory" # https.py from scrapy.core.downloader.contextfactory import ScrapyClientContextFactory from twisted.internet.ssl import (optionsForClientTLS, CertificateOptions, PrivateCertificate) class MySSLFactory(ScrapyClientContextFactory): def getCertificateOptions(self): from OpenSSL import crypto v1 = crypto.load_privatekey(crypto.FILETYPE_PEM, open('/Users/wupeiqi/client.key.unsecure', mode='r').read()) v2 = crypto.load_certificate(crypto.FILETYPE_PEM, open('/Users/wupeiqi/client.pem', mode='r').read()) return CertificateOptions( privateKey=v1, # pKey对象 certificate=v2, # X509对象 verify=False, method=getattr(self, 'method', getattr(self, '_ssl_method', None)) ) 其他: 相关类 scrapy.core.downloader.handlers.http.HttpDownloadHandler scrapy.core.downloader.webclient.ScrapyHTTPClientFactory scrapy.core.downloader.contextfactory.ScrapyClientContextFactory 相关配置 DOWNLOADER_HTTPCLIENTFACTORY DOWNLOADER_CLIENTCONTEXTFACTORY """
爬虫中间件
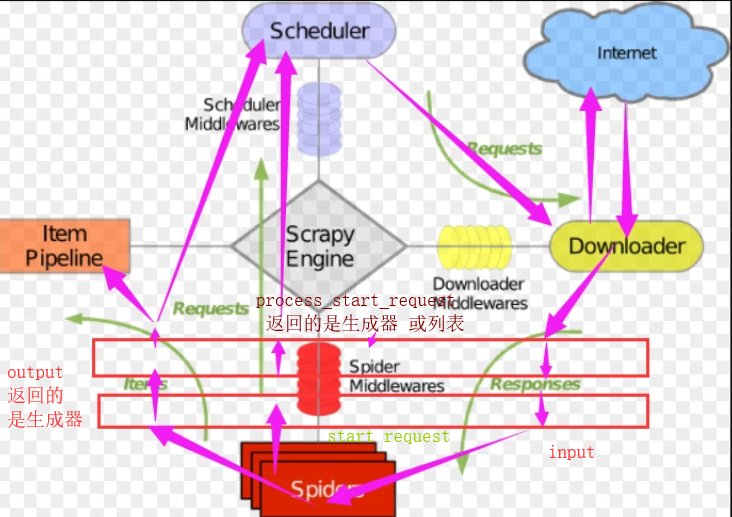
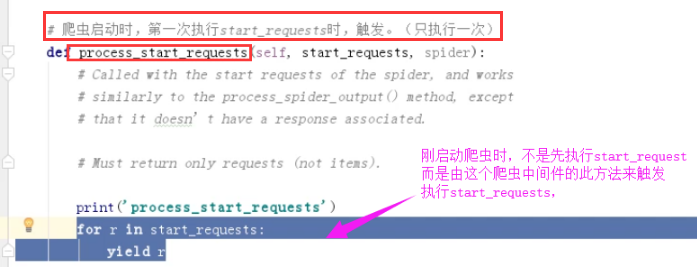
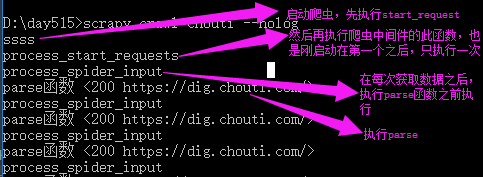
这里注意
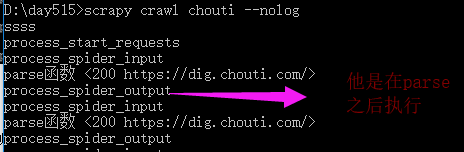
代码
middlewares.py class XiaohanSpiderMiddleware(object): # Not all methods need to be defined. If a method is not defined, # scrapy acts as if the spider middleware does not modify the # passed objects. def __init__(self): pass @classmethod def from_crawler(cls, crawler): # This method is used by Scrapy to create your spiders. s = cls() return s # 每次下载完成之后,未执行parse函数之前。 def process_spider_input(self, response, spider): # Called for each response that goes through the spider # middleware and into the spider. # Should return None or raise an exception. print('process_spider_input',response) return None def process_spider_output(self, response, result, spider): # Called with the results returned from the Spider, after # it has processed the response. # Must return an iterable of Request, dict or Item objects. print('process_spider_output',response) for i in result: yield i def process_spider_exception(self, response, exception, spider): # Called when a spider or process_spider_input() method # (from other spider middleware) raises an exception. # Should return either None or an iterable of Response, dict # or Item objects. pass # 爬虫启动时,第一次执行start_requests时,触发。(只执行一次) def process_start_requests(self, start_requests, spider): # Called with the start requests of the spider, and works # similarly to the process_spider_output() method, except # that it doesn’t have a response associated. # Must return only requests (not items). print('process_start_requests') for r in start_requests: yield r
settings中的配置
SPIDER_MIDDLEWARES = { 'xiaohan.middlewares.XiaohanSpiderMiddleware': 543, }
扩展 信号
单纯扩展:
无意义
extends.py class MyExtension(object): def __init__(self): pass @classmethod def from_crawler(cls, crawler): obj = cls() return obj 配置: EXTENSIONS = { 'xiaohan.extends.MyExtension':500, }
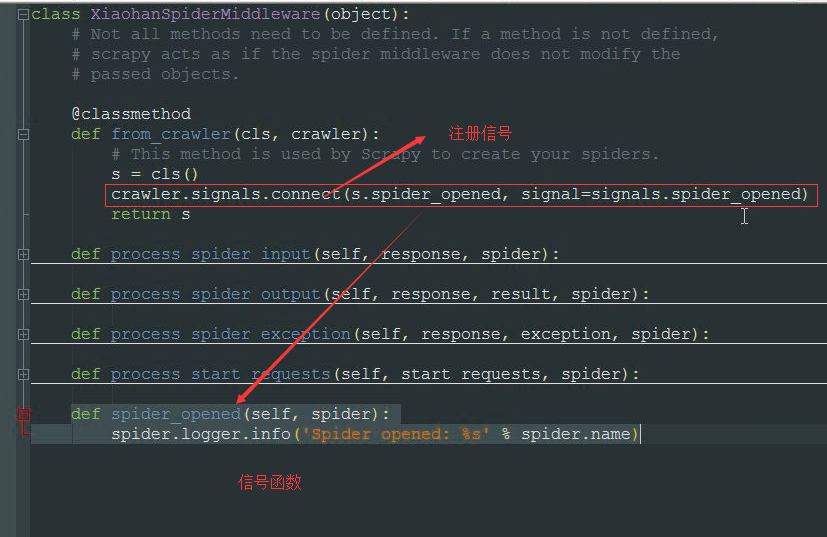
扩展+信号:
extends.py
from scrapy import signals class MyExtension(object): def __init__(self): pass @classmethod def from_crawler(cls, crawler): obj = cls() # 在爬虫打开时,触发spider_opened信号相关的所有函数:xxxxxxxxxxx crawler.signals.connect(obj.xxxxxxxxxxx1, signal=signals.spider_opened) # 在爬虫关闭时,触发spider_closed信号相关的所有函数:xxxxxxxxxxx crawler.signals.connect(obj.uuuuuuuuuu, signal=signals.spider_closed) return obj def xxxxxxxxxxx1(self, spider): print('open') def uuuuuuuuuu(self, spider): print('close') return obj
配置:
EXTENSIONS = { 'xiaohan.extends.MyExtension':500, }
7. 自定制命令
- 在spiders同级创建任意目录,如:commands
- 在其中创建 crawlall.py 文件 (此处文件名就是自定义的命令)
from scrapy.commands import ScrapyCommand from scrapy.utils.project import get_project_settings class Command(ScrapyCommand): requires_project = True def syntax(self):
#支持的语法 return '[options]' def short_desc(self): return 'Runs all of the spiders' def run(self, args, opts): #获取所有的爬虫 spider_list = self.crawler_process.spiders.list() for name in spider_list:
#craewler_process是执行爬虫的入口,如self.crawler_process.crawl('chouti') self.crawler_process.crawl(name, **opts.__dict__) #让爬虫开始做操作 self.crawler_process.start()
11.TinyScrapy
from twisted.web.client import getPage from twisted.internet import reactor from twisted.internet import defer url_list = ['http://www.bing.com', 'http://www.baidu.com', ] def callback(arg): print('回来一个', arg) defer_list = [] for url in url_list: ret = getPage(bytes(url, encoding='utf8')) ret.addCallback(callback) defer_list.append(ret) def stop(arg): print('已经全部现在完毕', arg) reactor.stop() d = defer.DeferredList(defer_list) d.addBoth(stop) reactor.run()
#!/usr/bin/env python # -*- coding:utf-8 -*- from twisted.web.client import getPage from twisted.internet import reactor from twisted.internet import defer @defer.inlineCallbacks def task(url): ret = getPage(bytes(url, encoding='utf8')) ret.addCallback(callback) yield ret def callback(arg): print('回来一个', arg) url_list = ['http://www.bing.com', 'http://www.baidu.com', ] defer_list = [] for url in url_list: ret = task(url) defer_list.append(ret) def stop(arg): print('已经全部现在完毕', arg) reactor.stop() d = defer.DeferredList(defer_list) d.addBoth(stop) reactor.run()
#!/usr/bin/env python # -*- coding:utf-8 -*- from twisted.internet import defer from twisted.web.client import getPage from twisted.internet import reactor import threading def _next_request(): _next_request_from_scheduler() def _next_request_from_scheduler(): ret = getPage(bytes('http://www.chouti.com', encoding='utf8')) ret.addCallback(callback) ret.addCallback(lambda _: reactor.callLater(0, _next_request)) _closewait = None @defer.inlineCallbacks def engine_start(): global _closewait _closewait = defer.Deferred() yield _closewait @defer.inlineCallbacks def task(url): reactor.callLater(0, _next_request) yield engine_start() counter = 0 def callback(arg): global counter counter +=1 if counter == 10: _closewait.callback(None) print('one', len(arg)) def stop(arg): print('all done', arg) reactor.stop() if __name__ == '__main__': url = 'http://www.cnblogs.com' defer_list = [] deferObj = task(url) defer_list.append(deferObj) v = defer.DeferredList(defer_list) v.addBoth(stop) reactor.run()
补充

如何创建第二个爬虫

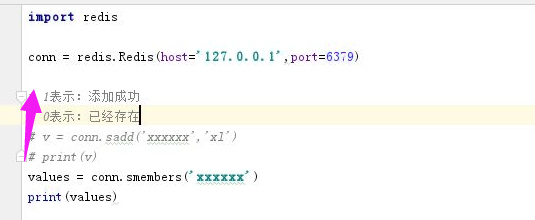
利用 scrapy- redis去重
原理就是把访问过的额地址放到一个集合总,然后判断时候访问过
redis只是补充
源码解析:
配置文件(要想使用就是修改这些内容)

代码(老师笔记中)
如果想要自定义去重规则 或者扩展
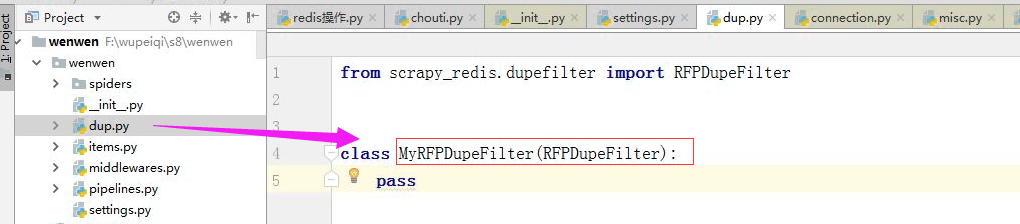

redis知识补充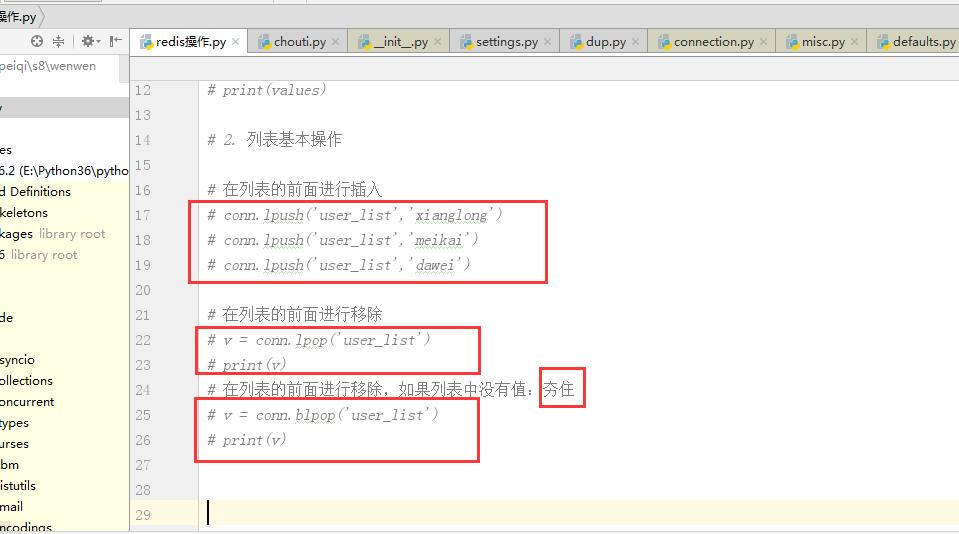

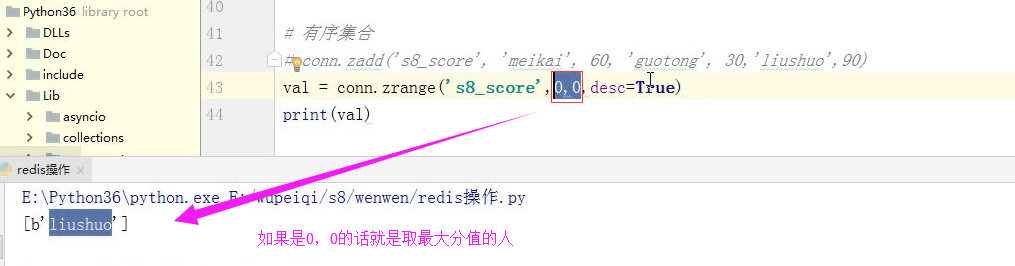
博客

自定义调度器


位置
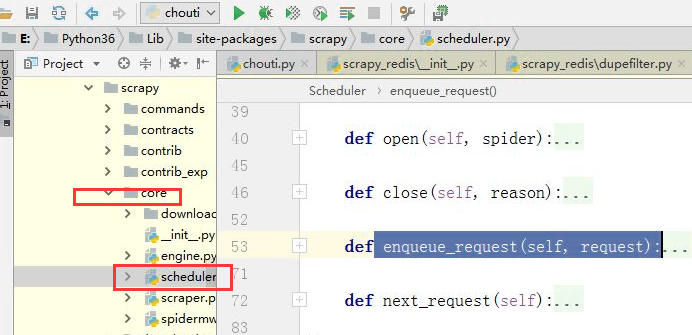
调度器和去重规则的使用的三中情况: 老师的代码(笔记中)