前言:回溯法和动态规划应该是考察率最多的两类算法,参考《从“排列问题”理解“回溯搜索”(DFS + 状态重置)、位掩码技巧、递归交换》,做一次总结
力扣No. 46 全排列
解决回溯问题,我的经验是 一定不要偷懒,拿起纸和笔,把这个问题的递归结构画出来,一般而言,是一个树形结构,这样思路和代码就会比较清晰了。而写代码即是将画出的图用代码表现出来。
方法:“回溯搜索”算法即“深度优先遍历 + 状态重置 + 剪枝”(这道题没有剪枝)
以示例输入: [1, 2, 3] 为例,因为是排列问题,只要我们按照顺序选取数字,保证上层选过的数字不在下一层出现,就能够得到不重不漏的所有排列。
画出树形结构如下图
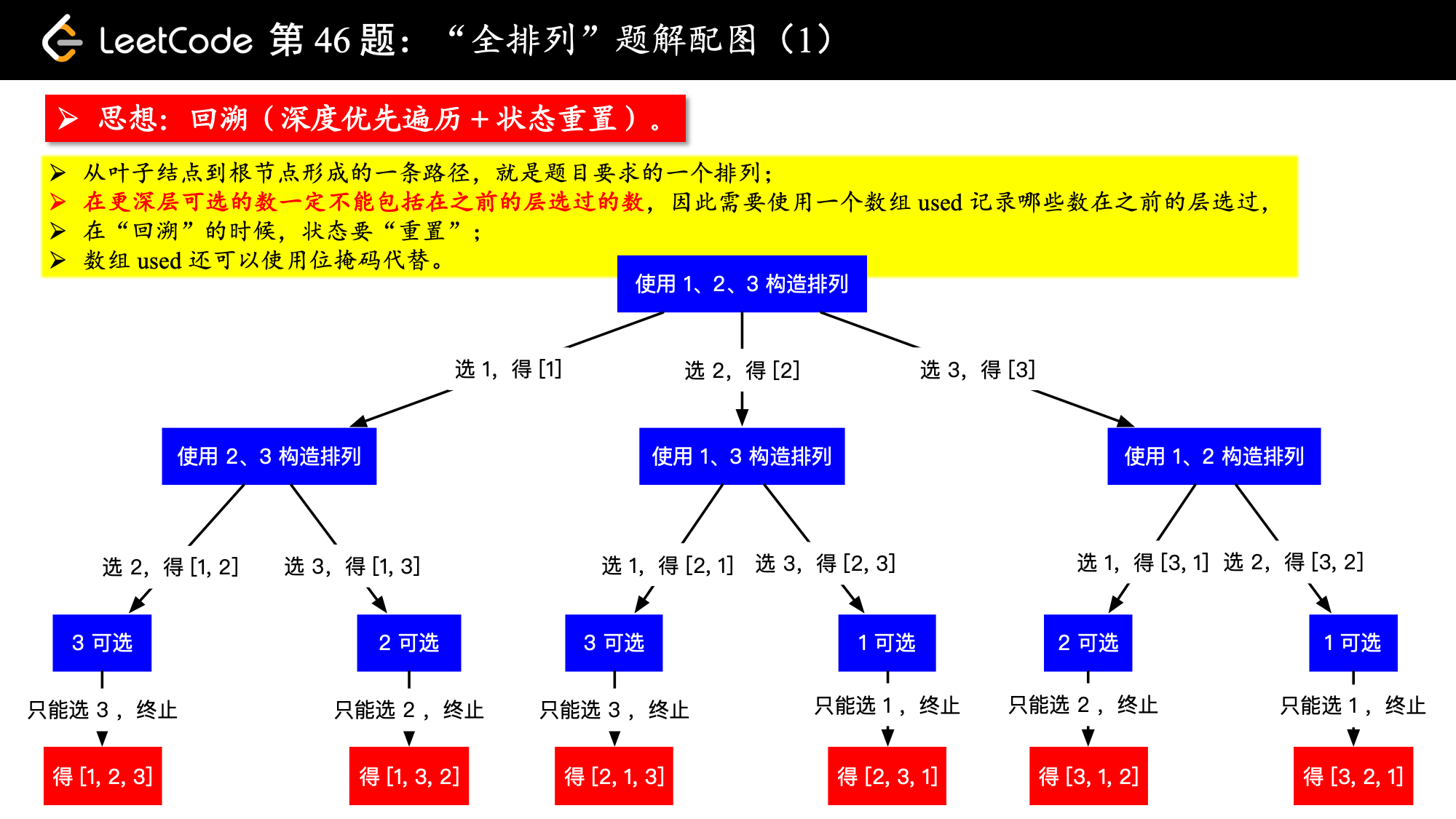
注意:
1、这里特别说明一点:虽然我的图是一下子展示出来的,但是我想你画出的图应该是一层一层画出来的;
2、在每一层,我们都有若干条分支供我们选择。下一层的分支数比上一层少 1 ,因为每一层都会排定 1 个数,从这个角度,再来理解一下为什么要使用额外空间记录那些元素使用过;
3、全部的“排列”正是在这棵递归树的所有叶子结点。
我们把上面这件事情给一个形式化的描述:问题的解空间是一棵递归树,求解的过程正是在这棵递归树上搜索答案,而搜索的路径是“深度优先遍历”,它的特点是“不撞南墙不回头”。
在程序执行到上面这棵树的叶子结点的时候,此时递归到底,当前根结点到叶子结点走过的路径就构成一个全排列,把它加入结果集,我把这一步称之为“结算”。
此时递归方法要返回了,对于方法返回以后,要做两件事情:
(1)释放对最后一个数的占用;
(2)将最后一个数从当前选取的排列中弹出。
事实上在每一层的方法执行完毕,即将要返回的时候都需要这么做。这棵树上的每一个结点都会被访问 2 次,绕一圈回到第 1 次来到的那个结点,第 2 次回到结点的“状态”要和第 1 次来到这个结点时候的“状态”相同,这种程序员赋予程序的操作叫做“状态重置”。
状态重置”是“回溯”的重要操作,“回溯搜索”是有方向的搜索,否则我们要写多重循环,代码量不可控。
说明:
1、数组 used 记录了索引 i 在递归过程中是否被使用过,还可以用哈希表、位图来代替,在下面的参考代码 2 和参考代码 3 分别提供了 Java 的代码;
2、当程序第 1 次走到一个结点的时候,表示考虑一个数,要把它加入列表,经过更深层的递归又回到这个结点的时候,需要“状态重置”、“恢复现场”,需要把之前考虑的那个数从末尾弹出,这都是在一个列表的末尾操作,最合适的数据结构是栈(Stack)。
class Solution:
def permute(self, nums):
if len(nums) == 0:
return []
used = [False] * len(nums)
res = []
self.__dfs(nums, 0, [], used, res)
return res
def __dfs(self, nums, index, pre, used, res):
# 先写递归终止条件
if index == len(nums):
res.append(pre.copy())
return
for i in range(len(nums)):
if not used[i]:
# 如果没有用过,就用它
used[i] = True
pre.append(nums[i])
# 在 dfs 前后,代码是对称的
self.__dfs(nums, index + 1, pre, used, res)
used[i] = False
pre.pop()
总结:
可以通过这个例子理解“回溯”算法的“状态重置”的操作,“回溯搜索” = “深度优先遍历 + 状态重置 + 剪枝”。
1、“深度优先遍历” 就是“不撞南墙不回头”;
2、回头的时候要“状态重置”,即回到上一次来到的那个地方,“状态”要和上一次来的时候一样。
3、在代码上,往往是在执行下一层递归的前后,代码的形式是“对称的”。
注意:
ask: 为什么 代码 res.append(pre.copy()):
liweiwei14199 : 这是因为在 Python、Java 语言中“可变对象”在“方法传参”中传递的是引用,如果使用 res.append(pre) 的话,在 res 变量里存的就是在叶子结点处 pre 变量的引用,而 pre 变量在最终回溯完成以后是空列表 [],使用 res.append(pre) 您会看到一堆空列表。
因此,需要使用 pre[:] 切片操作,得到一个拷贝,或者使用 pre.copy() 方法。
这部分的知识您可以在网络中搜索“Python 传参机制”、“值传递”、“引用传递”、“深拷贝”、“浅拷贝”、“列表的拷贝和切片”等关键字获得相关的知识。解释清楚这些知识已经在我的能力范围之外了。
如果我有解释错误的地方,欢迎您指出。
作者:liweiwei1419
链接:https://leetcode-cn.com/problems/permutations/solution/hui-su-suan-fa-python-dai-ma-java-dai-ma-by-liweiw/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
力扣No.17 电话号码的字母组合
class Solution:
def letterCombinations(self, digits: str) -> List[str]:
if not digits:
return []
dict1 = {'2':'abc', '3':'def', '4':'ghi', '5':'jkl', '6':'mno', '7':'pqrs', '8':'tuv', "9":'wxyz'}
paths = []
self.__dfs(paths, [], digits, 0, dict1)
return paths
def __dfs(self, paths, path, digits, index, dict1):
if index == len(digits):
paths.append(''.join(path.copy()))
return
for i in range(len(dict1[digits[index]])):
path.append(dict1[digits[index]][i])
self.__dfs(paths, path, digits, index+1, dict1)
path.pop()
注意:
path 列表中数据为 ['a', 'e', 'i', ...]
所以需要用: paths.append(''.join(path.copy()))
path.copy() 千万不能忘!!!