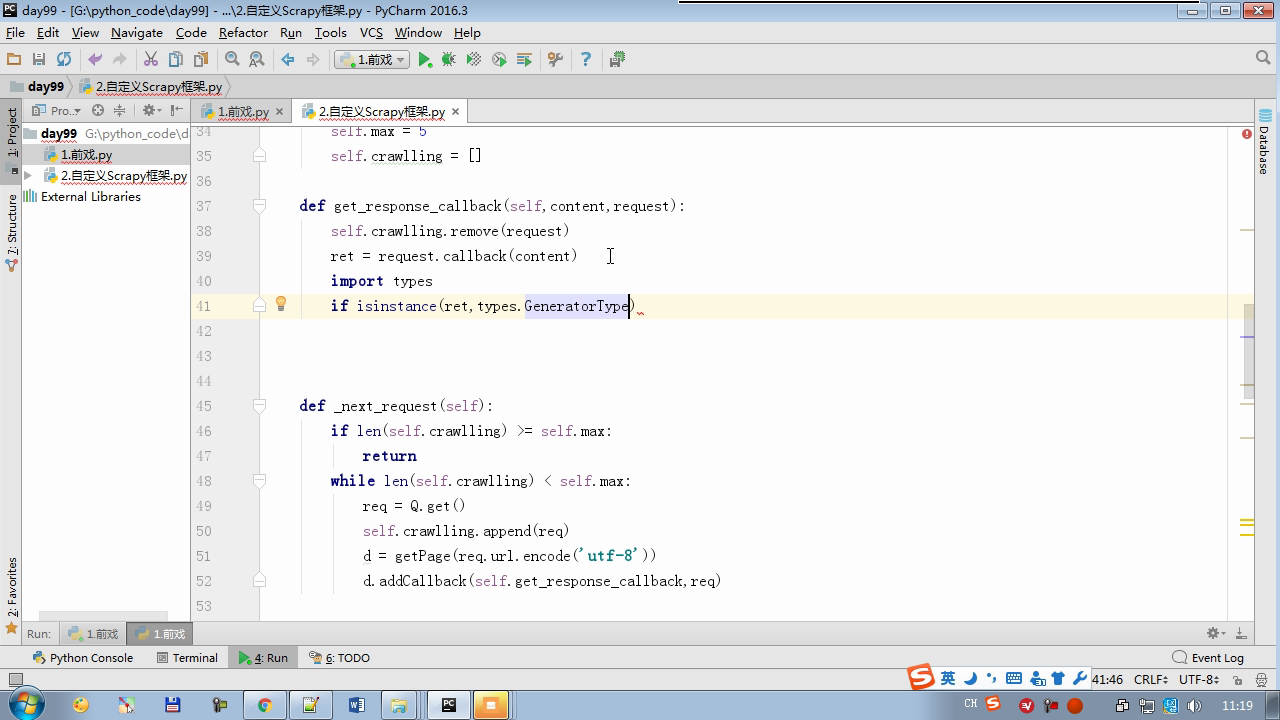
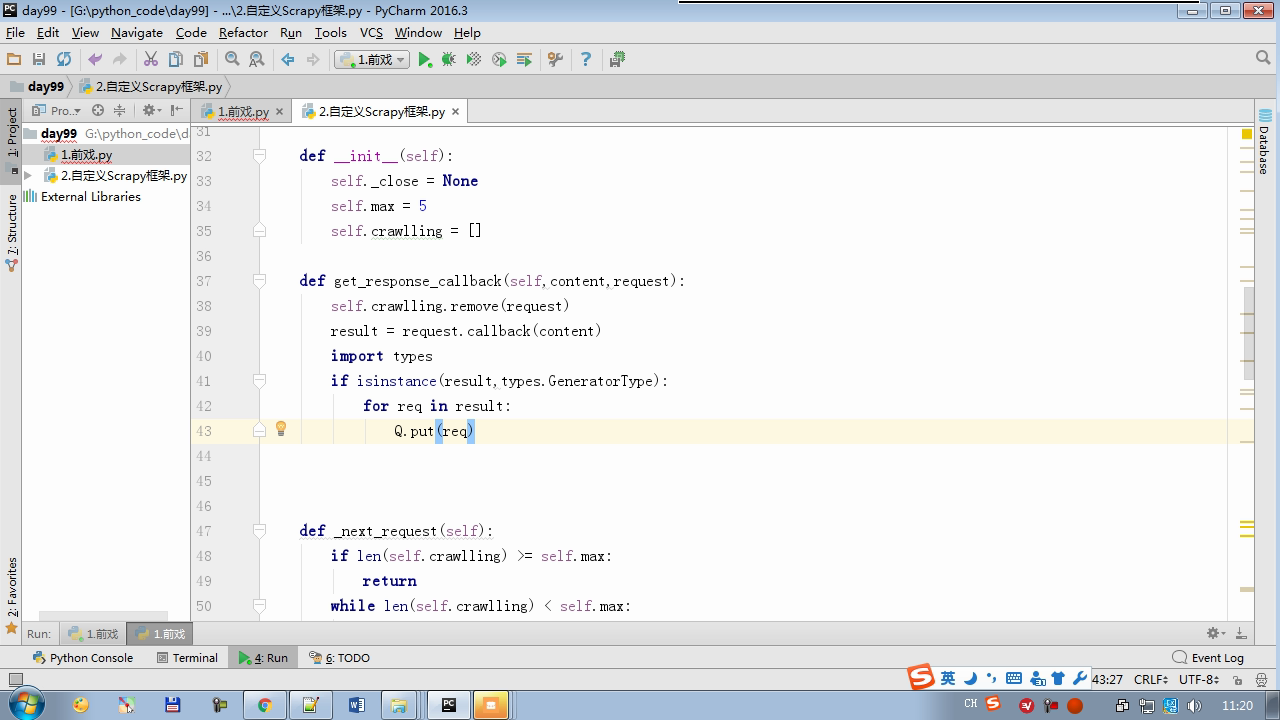
isinstance(result,types.GeneratorType) 判断是否生成器
队列为空会等,block=False 不等会报错
reactor.callLater(0,self.next_request)


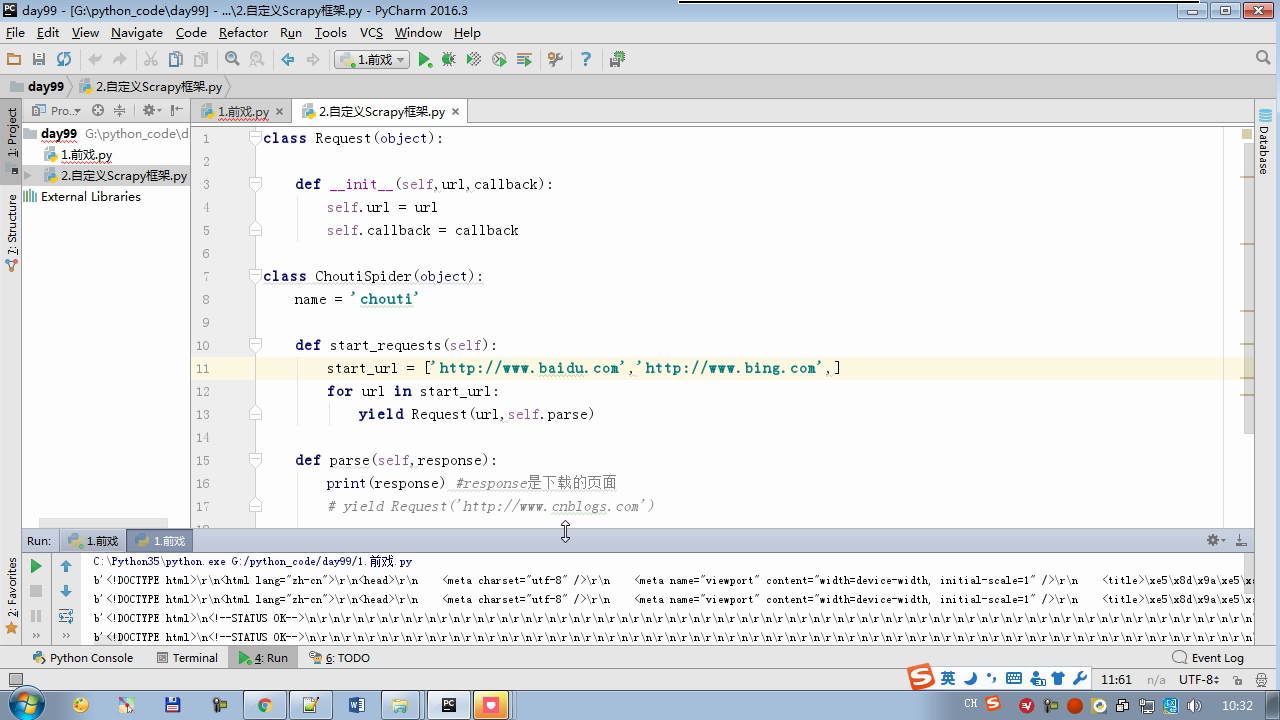
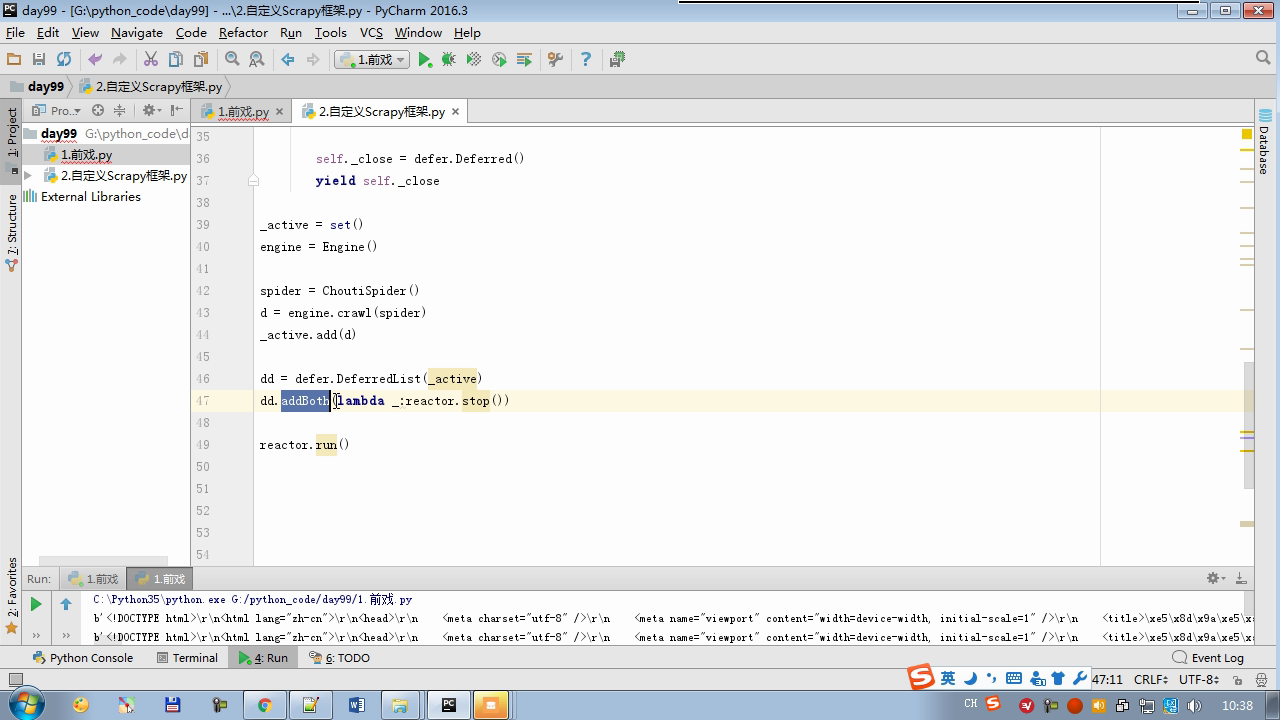
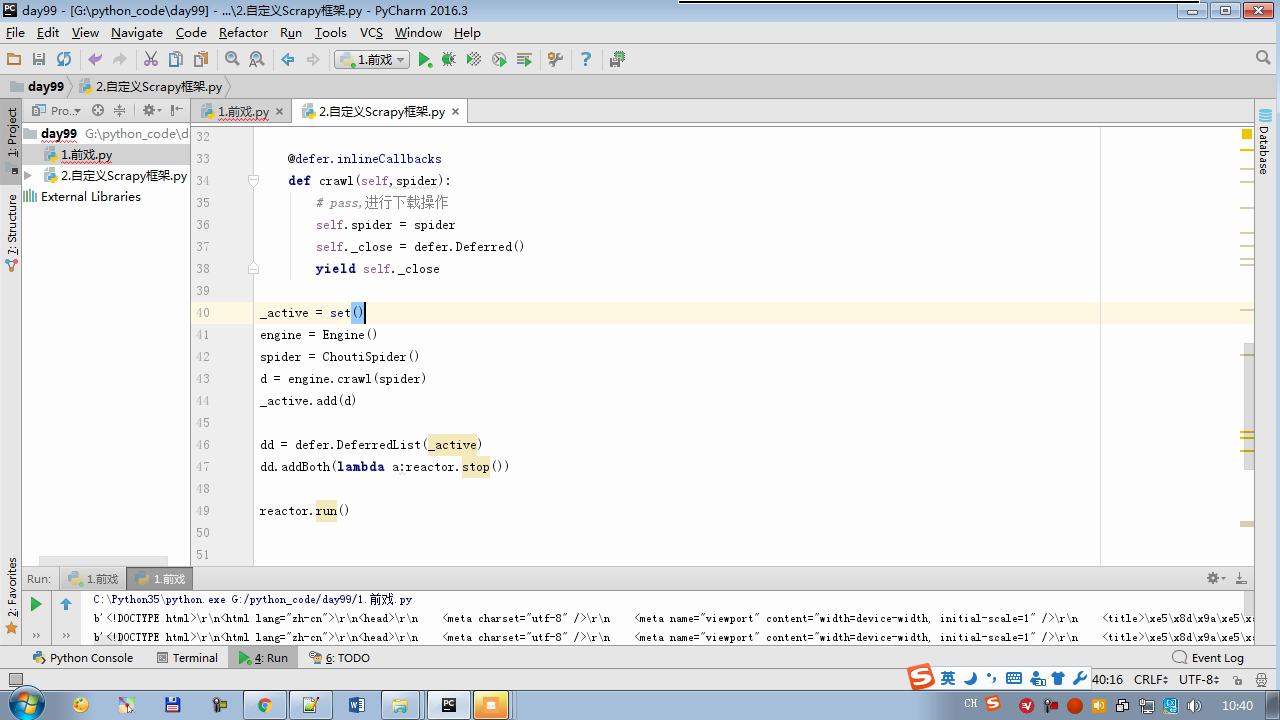
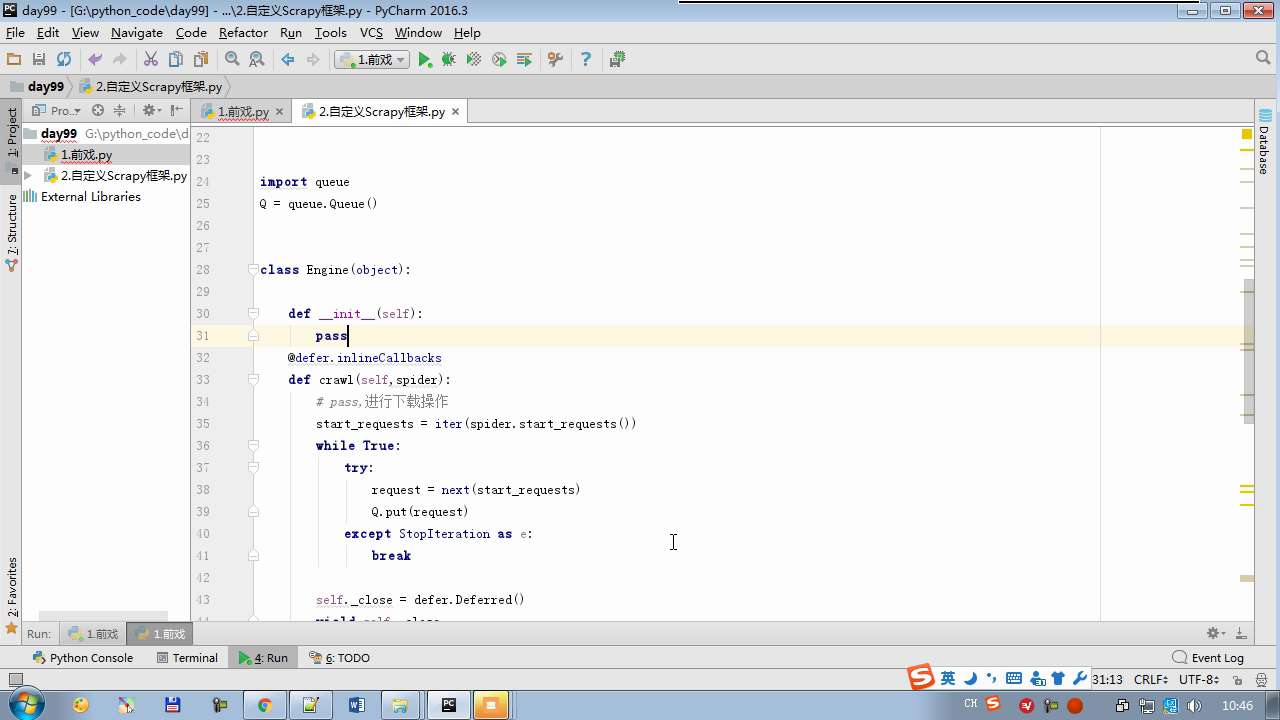
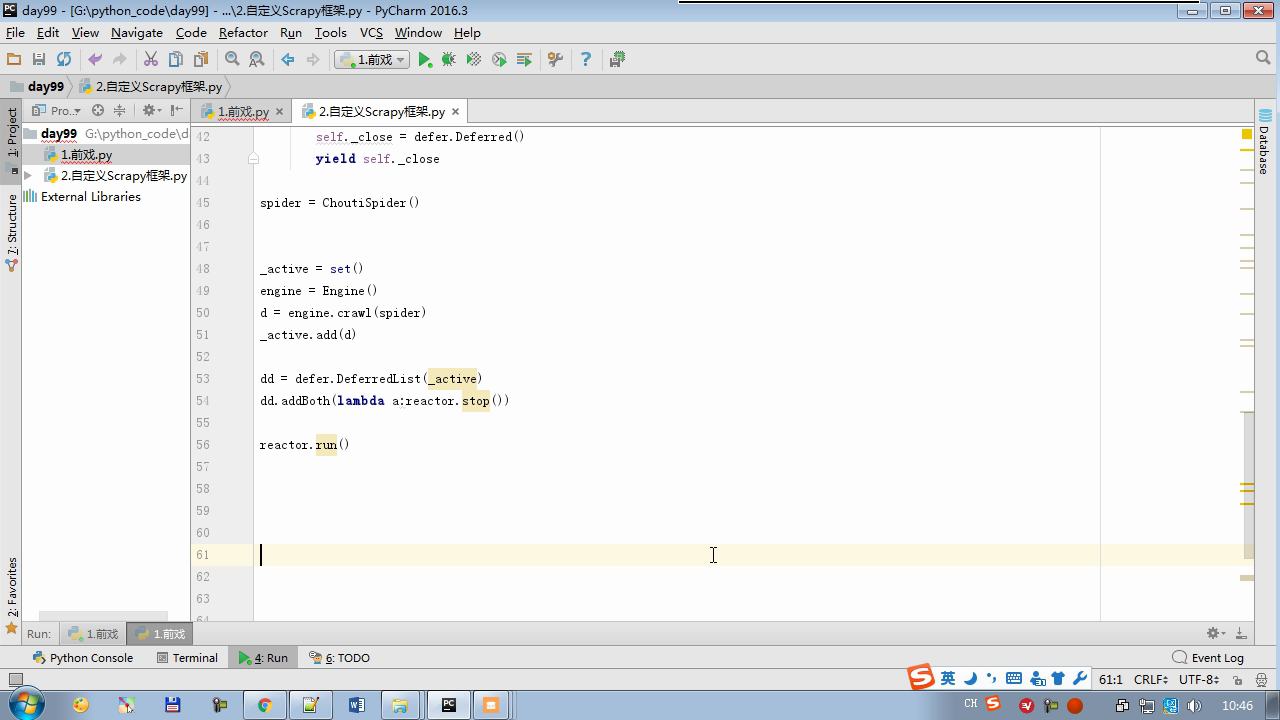
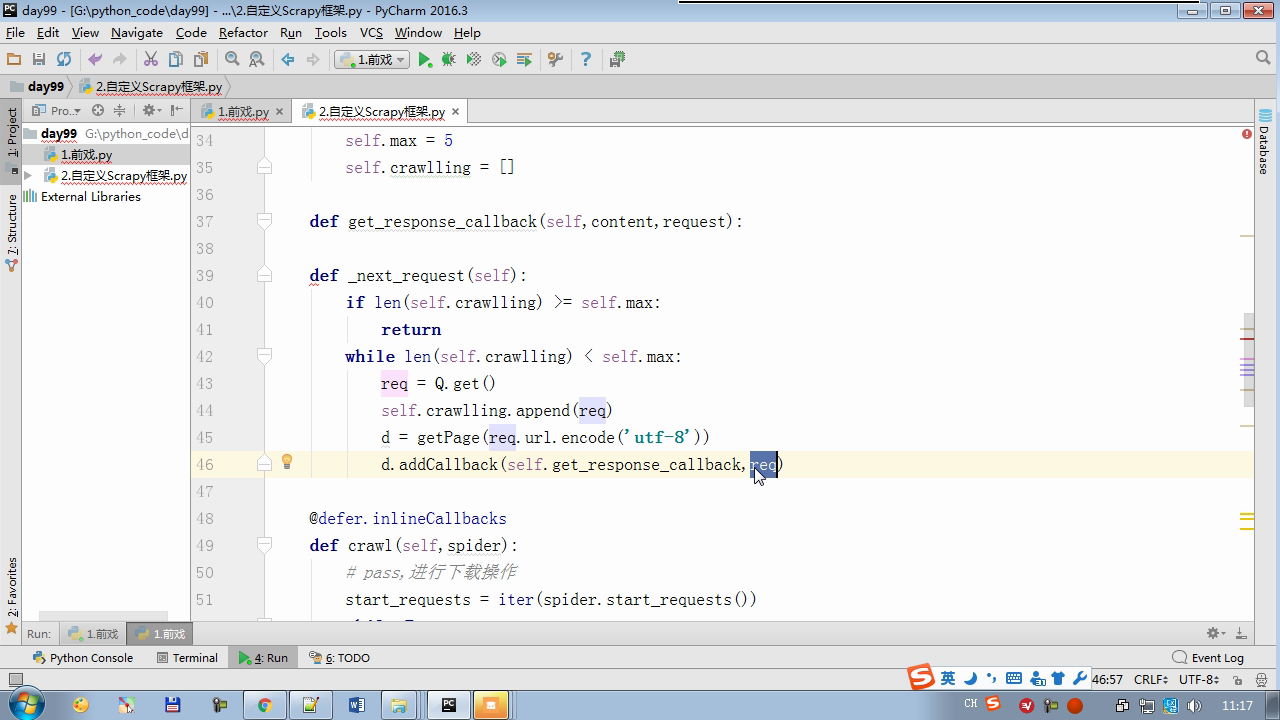
from twisted.internet import reactor # 事件循环(终止条件,所有的socket都已经移除) from twisted.web.client import getPage # socket对象(如果下载完成,自动从时间循环中移除...) from twisted.internet import defer # defer.Deferred 特殊的socket对象 (不会发请求,手动移除) class Request(object): def __init__(self,url,callback): self.url = url self.callback = callback class HttpResponse(object): def __init__(self,content,request): self.content = content self.request = request self.url = request.url self.text = str(content,encoding='utf-8') class ChoutiSpider(object): name = 'chouti' def start_requests(self): start_url = ['http://www.baidu.com','http://www.bing.com',] for url in start_url: yield Request(url,self.parse) def parse(self,response): print(response) #response是下载的页面 yield Request('http://www.cnblogs.com',callback=self.parse) import queue Q = queue.Queue() class Engine(object): def __init__(self): self._close = None self.max = 5 self.crawlling = [] def get_response_callback(self,content,request): self.crawlling.remove(request) rep = HttpResponse(content,request) result = request.callback(rep) import types if isinstance(result,types.GeneratorType): for req in result: Q.put(req) def _next_request(self): """ 去取request对象,并发送请求 最大并发数限制 :return: """ print(self.crawlling,Q.qsize()) if Q.qsize() == 0 and len(self.crawlling) == 0: self._close.callback(None) return if len(self.crawlling) >= self.max: return while len(self.crawlling) < self.max: try: req = Q.get(block=False) self.crawlling.append(req) d = getPage(req.url.encode('utf-8')) # 页面下载完成,get_response_callback,调用用户spider中定义的parse方法,并且将新请求添加到调度器 d.addCallback(self.get_response_callback,req) # 未达到最大并发数,可以再去调度器中获取Request d.addCallback(lambda _:reactor.callLater(0, self._next_request)) except Exception as e: print(e) return @defer.inlineCallbacks def crawl(self,spider): # 将初始Request对象添加到调度器 start_requests = iter(spider.start_requests()) while True: try: request = next(start_requests) Q.put(request) except StopIteration as e: break # 去调度器中取request,并发送请求 # self._next_request() reactor.callLater(0, self._next_request) self._close = defer.Deferred() yield self._close spider = ChoutiSpider() _active = set() engine = Engine() d = engine.crawl(spider) _active.add(d) dd = defer.DeferredList(_active) dd.addBoth(lambda a:reactor.stop()) reactor.run()