TensorFlow技术内幕(九):模型优化之分布式执行
随着模型和数据规模的不断增大,单机的计算资源已经无法满足算法的需求,本章分析一下TensorFlow内核中的对分布式执行支持。
GrpcSession
在第五章中,分析Graph的执行过程的时候,提到Graph的执行可以选择本地执行,对应的Session实现类是DirectSession,还可以选择服务端执行,对应的Session实现类就是GrpcSession.

第五章中我们只分析了这种分布式执行的客户端代码(见图1),但是并没有分析服务端的代码,本章来补上服务端的代码分析。
Master vs Worker
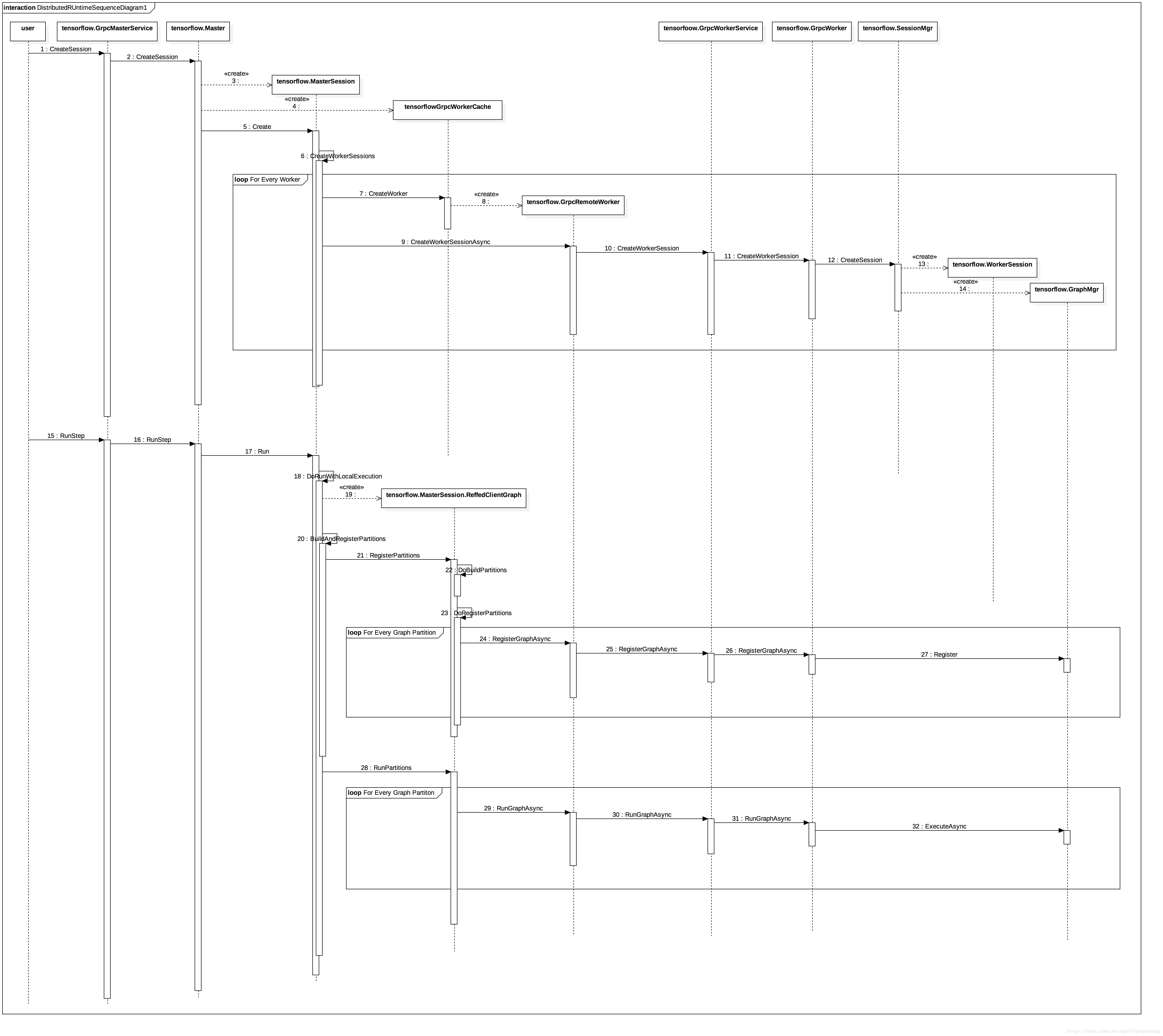
流程图见图2:
-
MasterService 和 WorkerSevice可以在同一个进程,也可以在不同的进程。所以图中的调用,部分是本地的直接调用,部分是RPC调用(例如User到GrpcMasterService的调用,GrpcRemoteWorker到GrpcWorkerService的调用,都是RPC调用)。
-
tensorflow.Master 与 tensorflow.GrpcMasterService 驻留在同一进程,后者会将来自RPC的调用全部交给前者处理。
-
tensorflow.GrpcWorker 与 tensorflow.GrpcWorkerService驻留在同一进程,类似地,后者也会将来自RPC的调用全部交给前者处理。
-
函数tensorflow.Master.CreateSession 根据配置选项创建一个MasterSession和一个或多个WorkerSession。
-
MasterSession负责调度和任务分配,WorkerSession绑定特定的设备,负责真正的执行。分别驻留在Master和Worker进程内。
-
GrpcWoker与WorkerSession驻留在同一进程。并通过SessionMgr管理所有的WorkerSession.
-
执行阶段MasterSession会负责将计算图分区(这部分逻辑在第五章中分析过),然后分别注册到不同的WorkerSession中去执行。
-
WorkerSession最终通过创建Executor来驱动注册过的计算图的执行。
TensorFlow技术内幕(十三):模型保存与恢复
模型训练过程中,我们希望在训练一段时间或一定次数之后,保存模型的当前状态,用于实验分析,或故障恢复,又或则是提供给线上服务使用。
Tensorflow中模型的状态包括两个方面,首先是模型的结构,其次是参数和参数的当前值。
本文介绍一下tensoflow中模型的这两类信息是如何保存和恢复的。
模型结构
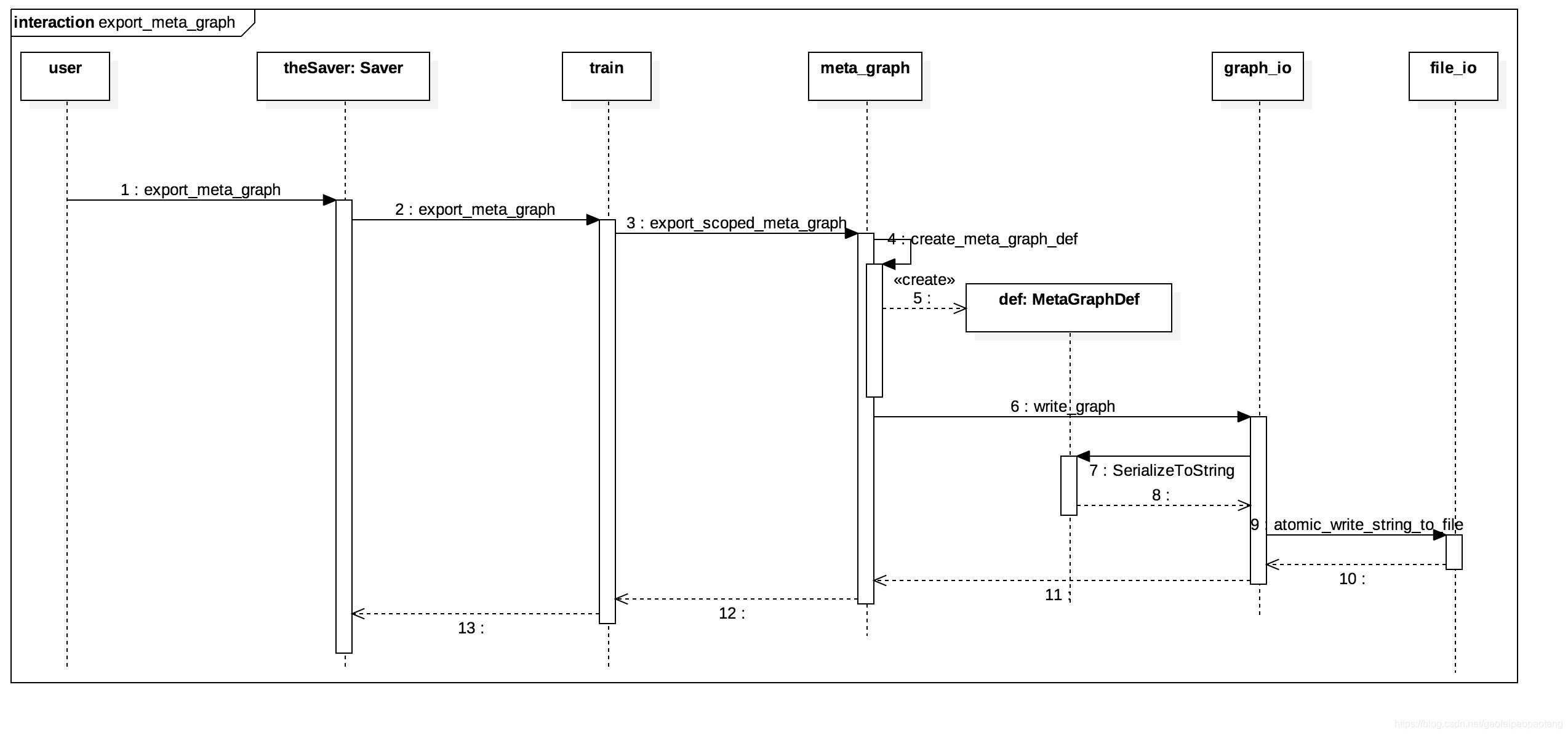
模型的结构信息是静态信息,在构建完成后一般不会再变化,保存的过程比较简单直接,首先将结构信息收集并写到MetaGraphDef对象中,然后将MetaGraphDef对象序列化后存储到外部存储.
MetaGraphDef是protobuf定义的message, 囊括了恢复模型结构的所有必要信息,简单介绍下面几类信息:
下面是结构信息保存过程的时序图:
模型参数
参数的个数一般是固定的,参数的值是随着训练的过程不断变化的。那么如果保存参数信息呢?
一般来说,一个比较朴素直接的方法就是遍历所有待保存的参数,获取参数的值并存储到外部存储中去。那么这个朴素版本的方案有没有什么问题呢?
其实,在设计方案的时候有一个原则,就是数据规模决定实现的方法。在数据量不大的情况下,这个保存参数值方法并没什么问题。但是当数据规模大了以后,这个方法就有很严重的效率问题,并且在超大规模的训练中,这个方法实际上是不可行的。
为什呢?我们知道,在tensoflow集群方式训练的过程中,集群会由若干个worker节点和若干个ps(parameter server)节点组成, worker节点承担主要的运算量,ps节点共同负责存储和更新所有的参数。
上述的参数保存方法中,保存过程的执行者是worker节点,它会将所有参数的参数值从ps节点拉取到本地,然后从本地写到外部存储中去,这样一来,如果参数的纬度比较大,参数的传输就会占用很大的带宽,造成性能问题,并且如果参数纬度更大,超过单机内存容量,那么这个方法就会耗尽worker的内存。
显然这个方法不是一个很好的方案,那么tensorflow是如何保存参数的呢?
tensorflow参数保存的功能,同样也实现在tf.train.Saver类里,通过两个步骤来实现:
- 第一步:在模型Graph中添加Save Node,并将所有需要保存值的Node(一般来说也就是Variable Node)作为Save Node的输入节点。
- 第二步:在需要保存参数值的时刻,运行Save Node,Save Node调用Save Op,将输入全部写到外部存储中。
这样的设计就避免了参数从ps到worker的传输,因为Save Node一般会分配到参数所在的ps上。
下面分析一下参数保存的具体过程,其中Save Node的添加发生在tf.train.Saver的构造函数内:
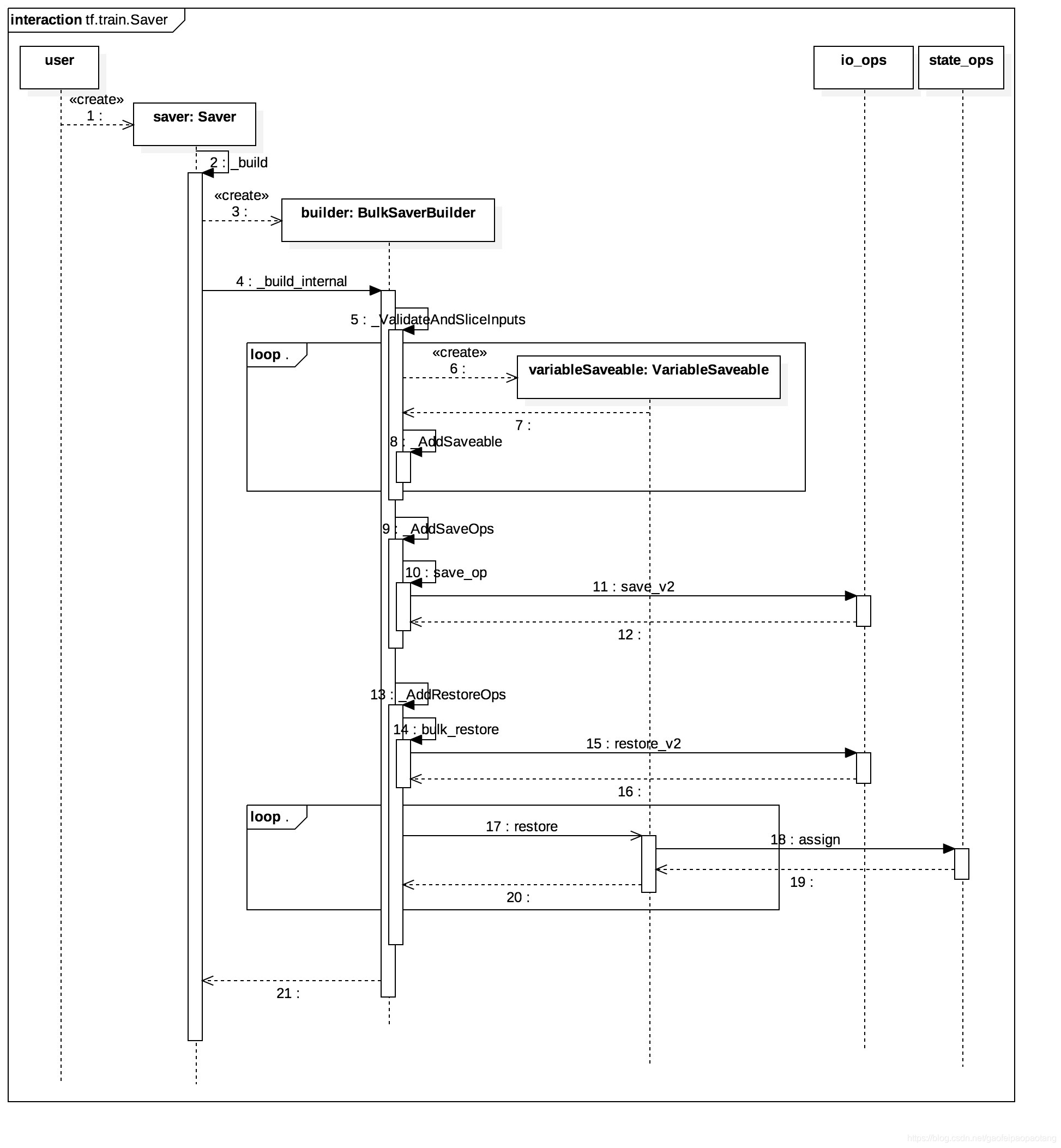
注意,上面的时序图中包括了Restore Node的添加过程,实际上也是这样的,Save和Restore都是在Saver的构造函数里添加的。
完成第一步之后,第二步就是在需要保存参数的时刻,调用Saver的Save方法,运行Save Node,时序图如下:
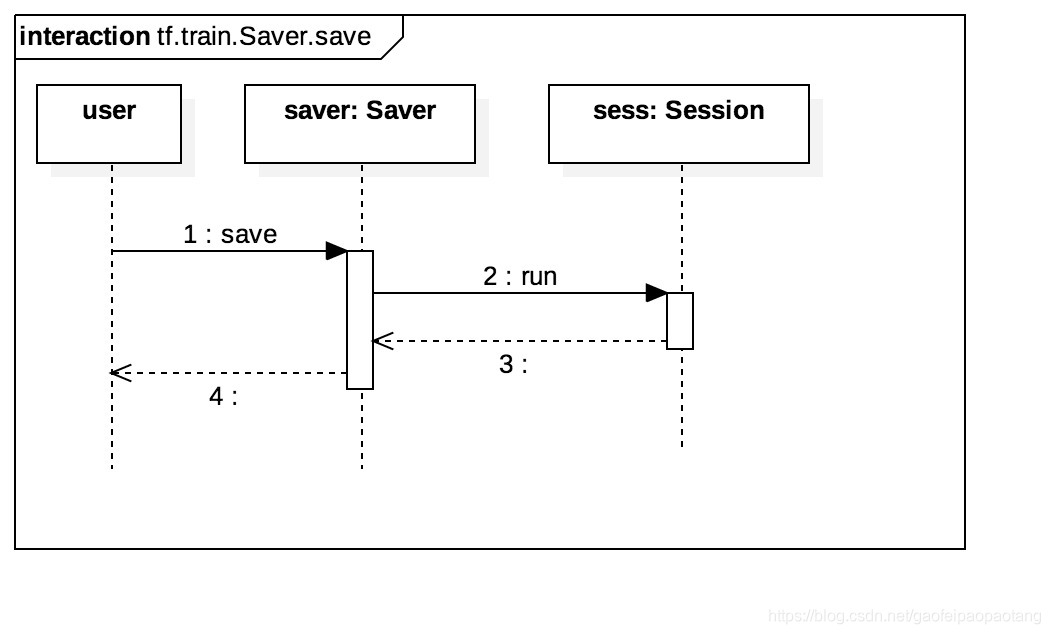
我们可能还比较关心的是,上面Saver构造函数里添加的Save Node和Restore Node的实现。我们以Saver Node为例介绍一下
SaveOp
Saver Node调用的是Save操作, Save操作在CPU上的操作核是SaveV2, 它继承自OpKnernel, 保存参数的功能在函数Compute中,保存的时序图如下: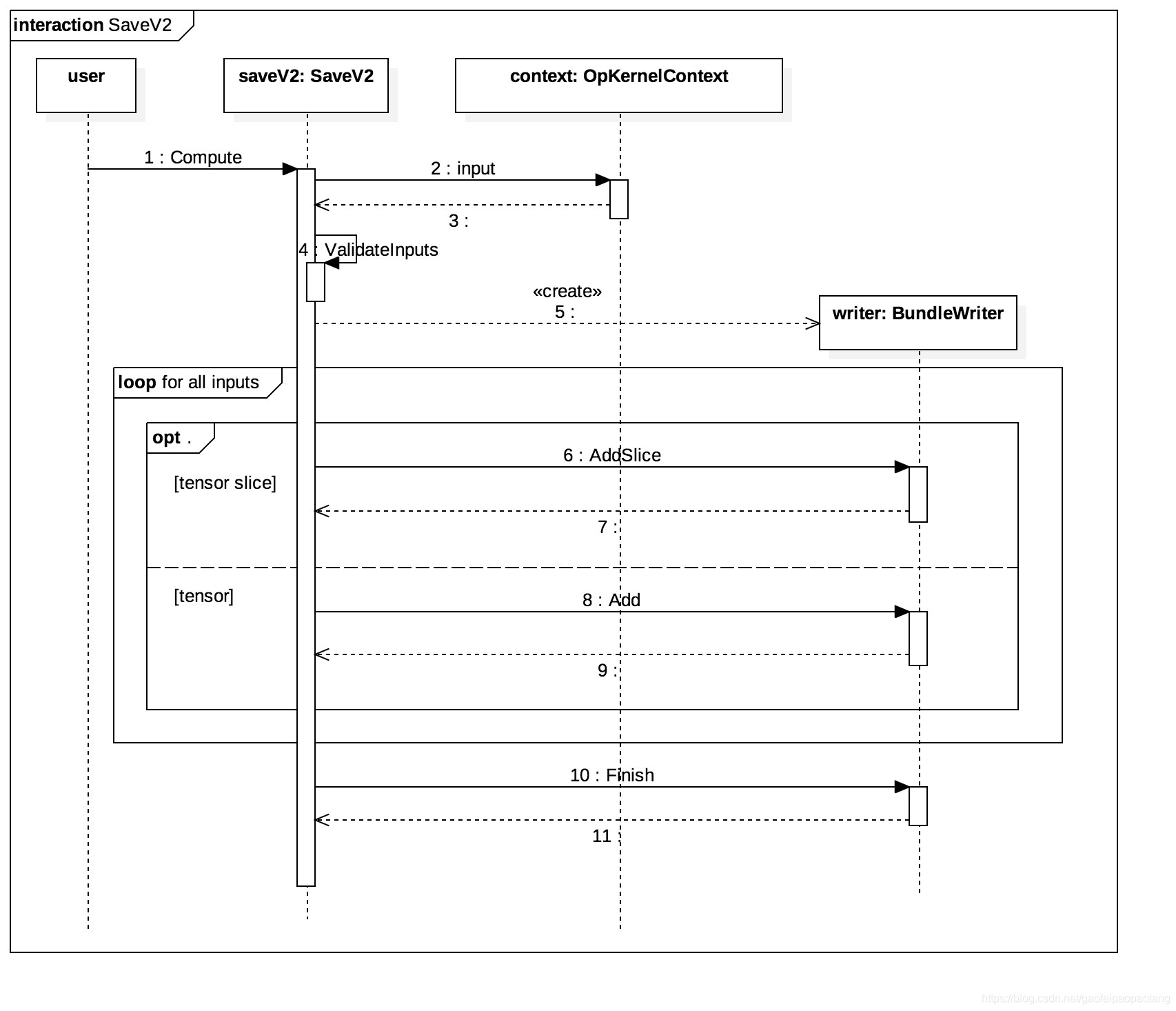
SaveV2有三个固定的输入,分别是prefix, tensor_names和shape_and_sclices, 分别表示保存目录、tensor名、tensor形状和切片信息;剩下的若干个输入都是需要保存的tensor的值,数量等于tensor_names数组的长度。
tensor形状和切片信息存在的原因是,作为SaveV2输入的tensor,可能是原始tensor的一部分,也就是所谓的原始tensor的一个分片,SaveV2支持tensor分片单独存储。例如当我们声明Partion Variable的时候,就会出现tensor分片的情况。
总结
上面我们详细分析了模型的保存过程,模型恢复的过程就是存储过程的逆向过程,了解了存储了过程之后,掌握恢复过程就比较简单了,这里就不再展开介绍了。
TensorFlow技术内幕(十四):在线学习
本文准备介绍tensorflow对在线学习的支持。所谓在线学习也就是模型一边训练一边服务,与之相对的则是离线学习(或称为批量学习):

在工程实现上,一般采用架构如下:
通过周期性的模型同步,将训练集群和服务集群相互隔离,这样做是有必要的,因为两个集群的业务场景不一样,对他们的要求也不一样:
- 模型服务集群承载着线上的真实流量,所以所有后端服务的常用指标都适用于服务模型服务集群,高可用性、高效率、高扩展性等等。
- 模型训练集群重在训练的效率,不要求有很高的热扩展性,可以停机添加机器或剔除机器,对可用性要求也不是很苛刻。
tensorflow体系中,模型训练集群采用tensorflow,模型服务集群一般采用tensorflow serving,模型以文件的形式存储,模型同步是通过文件系统完成的,比如HDFS。tensorflow serving是模型服务方面的高性能开源库,支持模型的版本管理和检查,以及自动更新。
这种结构能满足大多数情况下的业务场景的需求,但是在一些极端场景下,这些还不够。比如作者就曾遇到这样的常见,模型的体积超出了单机内存的上限,如何处理呢?
具体来说,在模型训练的时候,可以采用PS结构,将超大的模型分散到多台参数服务器上;但是到了模型服务的时候,tensorflow serving并不支持PS结构,模型必须单机完整加载模型。
也许你会想到,直接用tensorflow做模型服务,并且也同样采用PS结构呢?
这个架构的问题在于tensorflow ps集群不支持热扩展,当需要添加机器的时候,需要全部重启。
回到我们模型超大的问题,解决这个问题的关键在于tensorflow的一个很好的特征,那就是可以自定义OP。
这里提供一个解决的思路,具体实现的方式可以有很多种方式,就不在这里详述了:
- 有了自定义的OP的机制,模型训练集群可以将模型以我们自定义的格式存储到任何载体里,比如为了方便检索可以放到数据库,并且模型服务集群可以实现模型的按需查询,如此则服务集群不需要将完整的模型全部加载到单机内存里。
结构如下:
