一、OpenStack 概述
1、OpenStack 简介
简单来说,OpenStack就是一种用于部署虚拟环境(虚拟机和容器)以及互连这些虚拟环境所需网络的软件应用程序。
OpenStack主要使用Python编程语言,需要运行在Linux环境中。虽然没有OpenStack也能部署虚拟机和容器,但是OpenStack提供了一整套部署虚拟环境的平台及公共接口。
对于提供公有云服务的CSP(Cloud Service Provider,云服务提供商)来说,他们可以通过OpenStack等类似工具,让用户利用前端接口(通常是GUI接口,可以在后台调用OpenStack API)来编排并部署虚拟环境,包括应用程序、虚拟机、VNF以及互联这些组件的网桥等。希望部署私有云的客户也跟随CSP的脚步,逐步采用OpenStack来部署他们的私有云。
OpenStack并不是唯一提供虚拟环境部署能力的工具,还有很多其他方式也能部署和提供公有云(如前所述),AWS(Amazon Web Services,亚马逊Web服务)就是其中的佼佼者,事实上,OpenStack模仿的就是AWS的功能,只不过OpenStack的普及性以及创建自身术语及体系架构的复杂性,使得其更值得人们关注。
2、OpenStack 发展
OpenStack自2010年出现以来获得了长足发展,最初只有Swift和Nebula两大组件,Swift的主要开发者和贡献者是Rackspace,Rackspace将其作为存储管理的开源软件,而Nebula则源于NASA的一个开源项目,主要目的是管理复杂的数据集。将Swift项目和Nebula项目整合在一起,就是OpenStack的雏形。
后来很多企业都加入到OpenStack开源项目中,贡献了大量代码和软件功能。目前OpenStack的版本及代码由OpenStack基金会负责管理,OpenStack技术委员会负责管理OpenStack的技术问题,以确保OpenStack贡献代码的质量、集成性和开放性。
OpenStack得到普及推广的主要原因在于OpenStack的免费许可、社区开发、完全开源以及与厂商无关性,所有人都可以免费复制、修改和使用。另一方面,开源的OpenStack没有任何支持模式,完全采取社区化开发和支持模式,虽然OpenStack基金会负责管理OpenStack版本的内容及修改操作,但是该论坛仅负责协调参与者的开发与贡献,并不提供任何开发与使用方面的官方支持。
很多公司都基于开源的OpenStack创建了自己的定制化版本,并为此提供技术支持,Mirantis、Red Hat、Canonical以及Cisco-Metacloud等公司都有自己的OpenStack版本,并提供相应的开发与支持服务。
OpenStack在开发之初是作为部署应用程序及存储托管服务并加以管理的工具,后来逐步发展成为云部署工具,很多云服务提供商(如Rackspace)正逐步将OpenStack用于公有云产品,而有些公司(如GoDaddy)则利用OpenStack来部署自己的私有云。不过近年来,NFV的目标之一是实现供应商的独立性,而OpenStack正好能够满足该需求,可以避免锁定任何特定供应商。
对于那些正逐渐采用NFV的服务提供商(许多都脱胎于传统的电信运营商)来说,他们通常都希望创建自己的私有云(托管并运行自己的网络服务),并广泛利用OpenStack对各种供应商的支持能力。
因此,开源及低成本特性使得OpenStack有望成为服务提供商部署NFV基础设施的首选技术。
3、OpenStack 版本
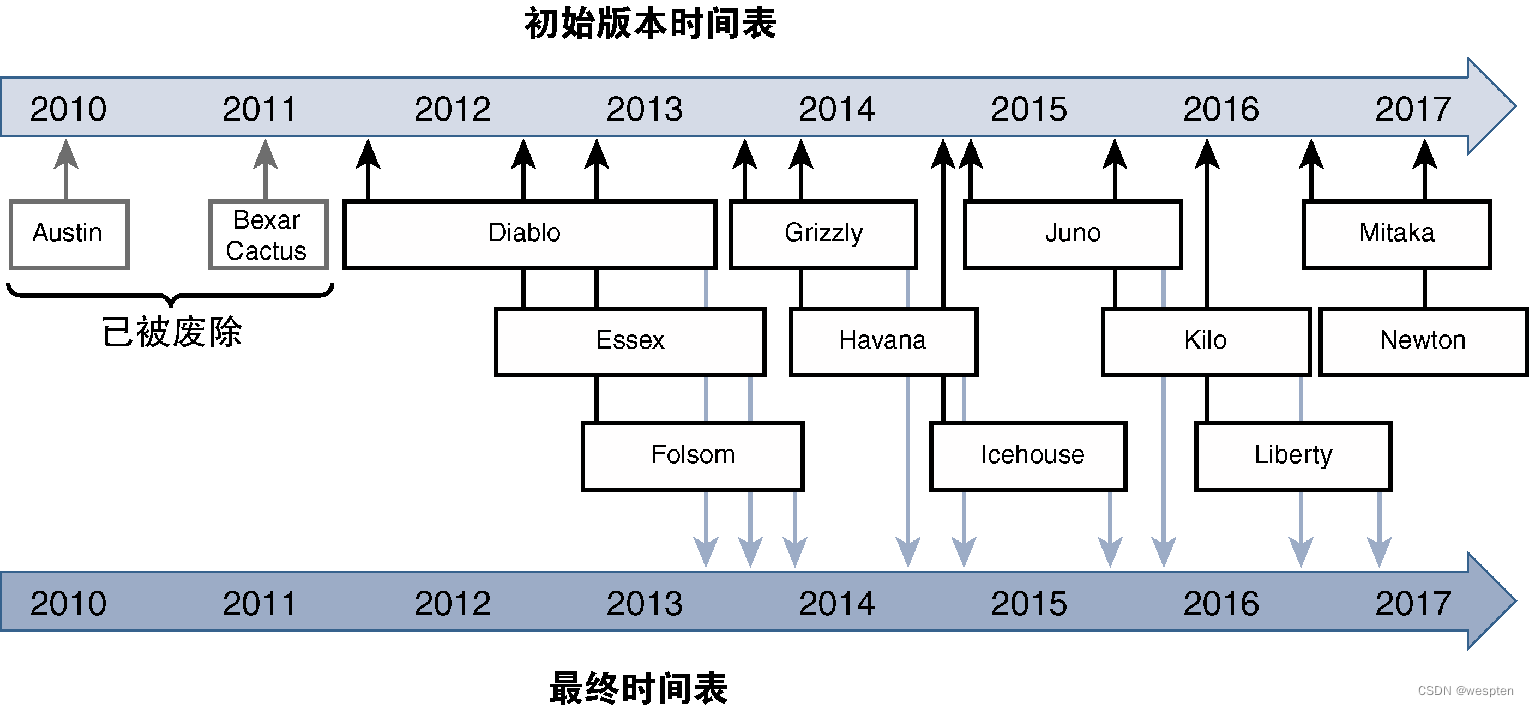
OpenStack采用基于时间的版本发布模式,上一个版本发布之后大概6个月再发布新的OpenStack稳定版本,使用时间大概1年左右。OpenStack的版本以字母顺序进行命名,每个新版本都会融入社区开发和贡献的最新代码,这些代码必须得到OpenStack基金会技术委员会的批准和接受。
下图给出了OpenStack版本历史及演进路线图,可以看出,OpenStack版本的发布周期是6个月,有效期是1年。
二、OpenStack 架构
1、OpenStack 体系架构
OpenStack并不是一个单一软件,而是由多个模块组成,可以提供多种功能。运行OpenStack软件的服务器称为OpenStack节点,由于OpenStack是模块化软件,因而并不需要在OpenStack所管理的每个OpenStack节点上都运行所有的OpenStack组件。如果服务器仅提供虚拟化的计算资源,那么只要在这些节点上运行计算虚拟化管理模块(Nova)即可,这些节点则被称OpenStack计算节点。
同样,有些服务器可能仅提供虚拟化的存储资源,那么只要在这些节点上运行OpenStack存储管理模块即可,这些节点被称OpenStack存储节点。对于网络虚拟化来说,某些OpenStack网络节点可能仅提供虚拟化的网络模块,因而只要运行用于网络虚拟化管理的OpenStack模块即可。根据所要提供的服务类型,网络中可能还存在其他类型的OpenStack节点,如运行负载平衡和集群服务的端节点或类似于存储节点的卷节点。当前,常见的OpenStack节点还是前面说的几种节点。
除了这些节点之外,OpenStack还要部署OpenStack控制器节点以管理其模块并执行特定的集中功能,这些节点可以分布在不同的位置上(支持不同的地理位置)。
控制器节点是所有OpenStack环境都必不可少的,而且前面提到的所有节点都能共存在同一台服务器上,可以共享相同的服务器,也可以在不同的服务器上分别实现。如果所有类型的OpenStack节点都集中在同一台服务器上,那么就将这种包含控制器、网络、计算及存储节点的组合称为OpenStack的AIO(All-In-One,全合一)部署模式。对于最终用户来说,这些节点的分布情况是不可见的,看到的始终是OpenStack云的单个接口。
下图给出了使用单独互连的节点或AIO部署模式的OpenStack部署情况:
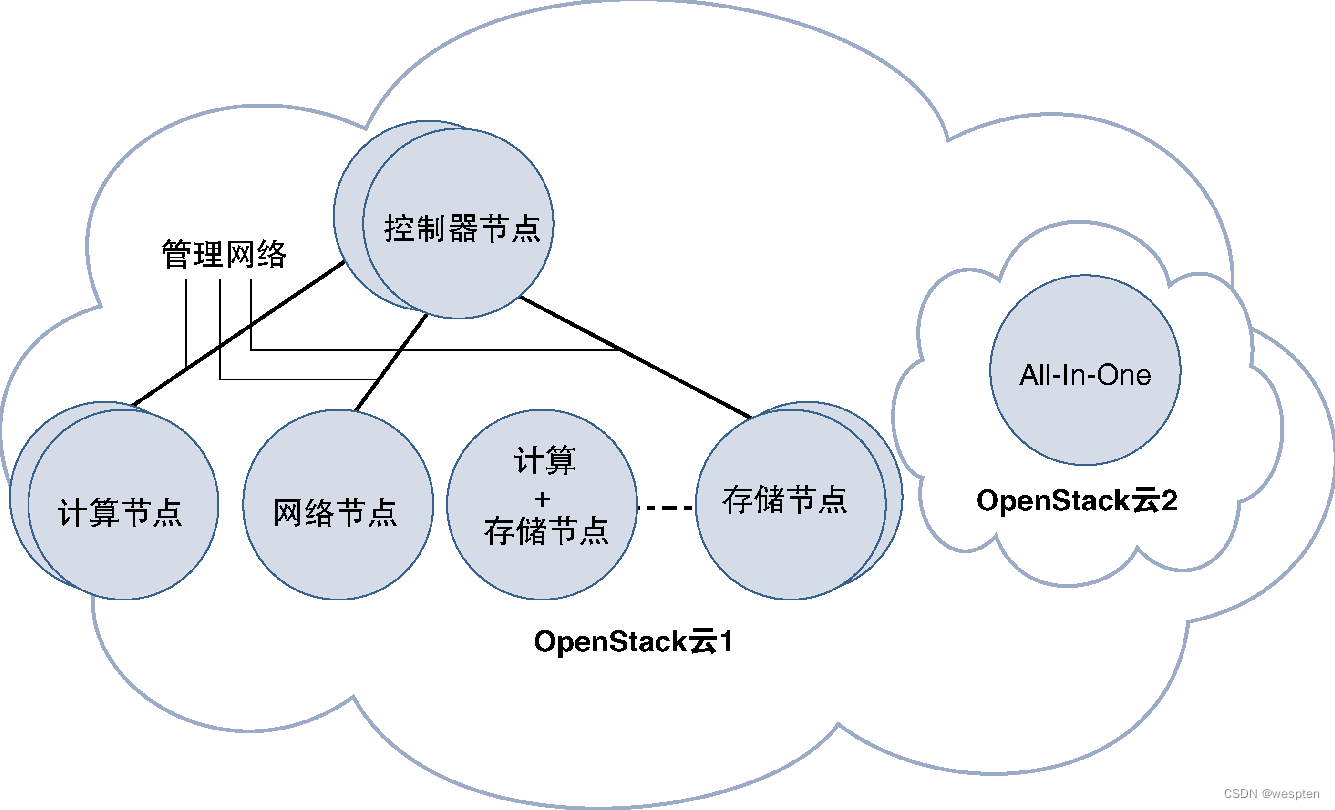
从图中可以看出,同一个OpenStack云中可以存在多个相同类型的节点,由于控制器节点是将OpenStack云基础设施整合在一起的关键,因而部署多个控制器节点以避免单点故障是非常有意义的,这样做的好处是能够确保OpenStack的高可用性,但是为了保证多个控制器节点之间能够协同工作,同样也会增加一定的复杂性。
下图给出了OpenStack体系架构中的主要模块信息(以OpenStack的Liberty版本为例),虽然每个模块都被设计为执行特定功能,但相互之间仍然可能存在彼此依存关系,可能需要在OpenStack生态系统中进行交互。
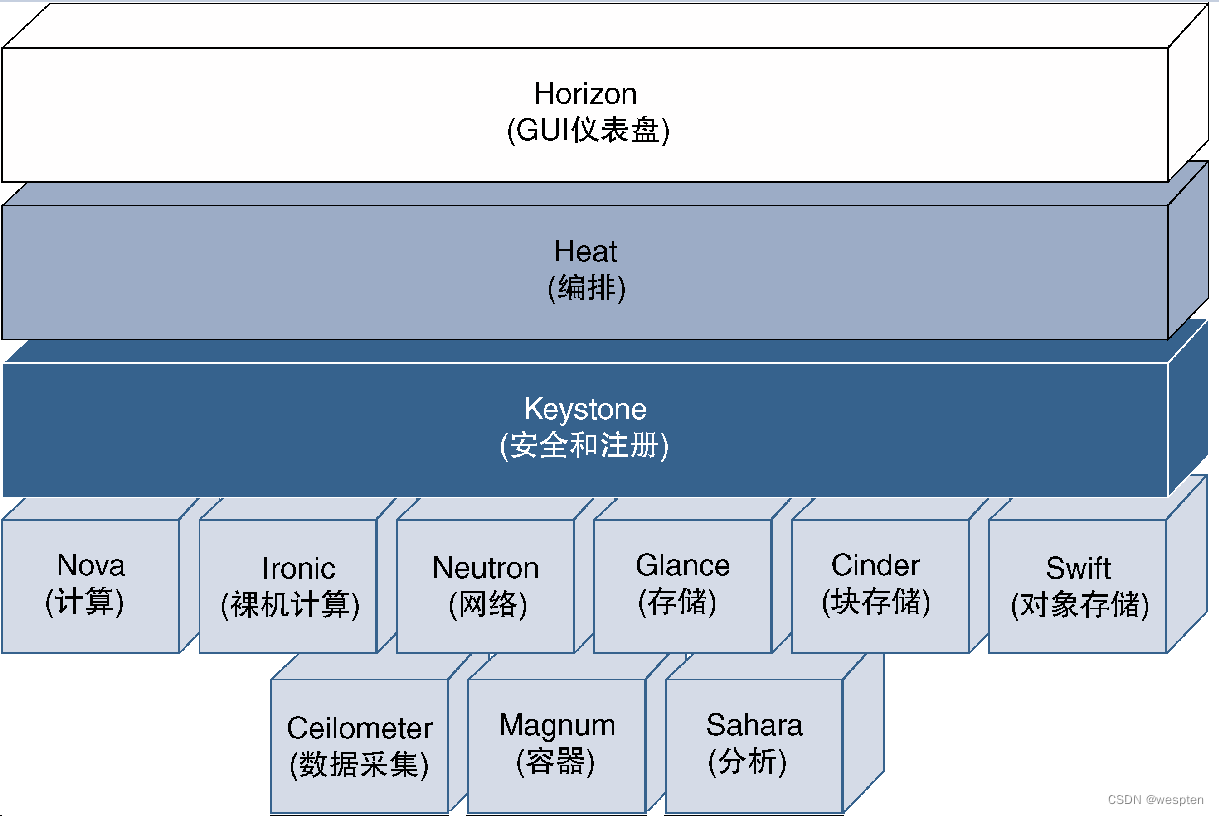
采用OpenStack的NFV部署方案可能需要这里给出的部分或全部组件,甚至还可能需要其他组件来构建和管理NFVI层。
OpenStack创建云环境(称为项目或租户),并将其提供给用户以建立自己的云。用户可以访问多个云,而且在不同的云中具有不同的权限等级。
在租户内部,OpenStack用户不仅可以创建自己的虚拟机、为虚拟机设置网络、实施监控和分析操作、对存储及镜像进行管理,还可以完成各种所允许的其他功能。对于租户环境来说,能够使用的选项功能取决于安装的OpenStack模块类型以及OpenStack管理员对该OpenStack模块所做的配置。
除了虚拟机管理功能之外,OpenStack还可以提供各种服务的构建模块,如DHCP(Dynamic Host Configuration Protocol,动态主机配置协议)即服务、DNS(Domain Name System,域名系统)即服务或防火墙即服务。因而了解OpenStack的角色是充分理解其能力的关键。
2、Horizon
为了与OpenStack进行交互,每个模块都提供了一组可以传递参数和检索响应信息的API(REST API),而且这些模块都带有脚本,它们作为这些REST API的包装器,并提供一个命令行工具来传递参数或显示响应,因而对于用户和管理员来说交互过程较为友好。
不过,OpenStack也支持图形用户界面,由Horizon模块提供图形界面,Horizon基于Django的网站应用程序进行开发,提供仪表盘功能。Django是一种利用Python语言编写的框架,主要用于Web应用程序开发,可以为数据库驱动的GUI提供一种简单的Web界面开发方法,无须为编写后端程序而耗费精力。
虽然很多管理功能都无法通过Horizon仪表盘进行操作,仍然需要使用命令行包装器工具。但是对于OpenStack用户来说,Horizon提供了一种非常好的界面和图形环境来监控并管理他们的云。
与命令行包装器相似,Horizon也在后台使用REST API调用机制。如果用户(或管理员)希望实现自己的仪表盘,那么也可以使用相同的API调用并替换Horizon来创建自己的用户界面。
由于OpenStack模块通过REST API调用机制进行交互,因而会侦听发送给它们的REST查询的特定端口号。这些API调用可能来自用户、管理员,甚至可能来自另一个模块,可以为OpenStack模块单独配置这些端口号,并通过集中式注册表将这些端口号(包括IP地址)提供给其他模块。在此背景下,作为OpenStack框架一部分的模块可以安装在不同的三层域中,只要它们能够路由REST流量(默认使用HTTP,也可以改成HTTPS[Secure HTTP,安全HTTP]),就可以将OpenStack框架分布到这些三层域中。
每个OpenStack模块都能在代码的多个功能块中实现(可能会运行为单独的进程)。如果OpenStack模块需要在自己的功能块中进行通信,那么就会通过消息队列使用更有效的通信方法,因而运行OpenStack的主机系统都应该安装消息队列功能。实现该功能的应用程序比较多,只要符合AMQP(Advanced Message Queuing Protocol,高级消息队列协议),OpenStack就能使用该应用程序,默默认建议使用RabbitMQ,它是AMQP的一种开源实现。
3、Nova
Nova是Nebula的演进版本,是OpenStack较早的模块之一。Nova的主要功能是与Hypervisor进行交互,以创建、删除和修改已分配资源并管理虚拟机的镜像。从本质上来说,Nova提供了虚拟机生命周期的管理手段,Nova界面为OpenStack用户云提供了虚拟机设置能力,因而是NFV部署方案中非常重要的OpenStack模块。
Nova可以通过Nova-Network子模块为用户提供非常基本的网络功能,不过目前已被弃用,被更为强大的Neutron模块所取代。
4、Neutron
Neutron通过OpenStack为网络服务提供部署和配置能力。对于NFV来说,Neutron模块扮演着非常重要的角色,因为该模块负责建立网络并与VNF进行对接,从而在虚拟机或VNF与外部广域网(WAN)或局域网(LAN)之间建立连接。
Neutron源自Nova的网络模块,是Nova网络模块的演进版本。不过,由于Neutron模块在实现网络服务时依赖Nova模块,因而使用Neutron模式时需要Nova模块。虽然Neutron模块的网络能力有限,但完全可以通过Neutron插件进行扩展和增强。由于Neutron模块与云环境及NFV的网络实现密切相关。
5、Ironic
很多应用程序都需要专用服务器(也称为裸机),而不支持共享环境,不过这些应用程序仍然可能是虚拟化环境的一部分,并与在虚拟机或容器中运行的应用程序一起工作。OpenStack支持这种混合部署模式,将某些应用程序部署到裸机上,而将其他应用程序部署到虚拟机上。
Ironic是OpenStack的一种模块,可以提供裸机服务器并在其中部署应用程序,Ironic起源于Nova裸机驱动程序项目,目前已成为OpenStack的独立项目。
在默认情况下,Ironic使用PXE(Preboot Execution Environment,预启动执行环境)和IPMI(Intelligent Platform Management Interface,智能平台管理接口)基础设施在裸机服务器上部署应用程序。此外,Ironic支持为特定厂商的API使用厂商插件,这样就可以使用其他方法在裸机服务器上部署应用程序了。
PXE是Preboot Execution Environment(预启动执行环境)的缩写,它为管理员提供了一种标准方式,可以在裸机设备上远程部署操作系统或完整的应用程序。
IPMI是Intelligent Platform Management Interface(智能平台管理接口)的缩写,它是一组与计算资源硬件的CPU或固件进行交互的规范,IPMI允许管理员在无操作系统依存关系的情况下(即使无操作系统或者系统未加电)直接管理系系统。
6、Magnum
就像Nova用于部署和管理虚拟机的生命周期一样,Magnum模块提供的是容器的管理和部署功能,Magnum使用Docker和Kubernetes组件,并向OpenStack客户提供API,以便OpenStack客户能够以与部署虚拟机相同的方式部署容器。
Kubernetes是一款由Google开发的开源容器编排工具,其目的是管理容器集群。Docker负责管理容器的生命周期,而Kubernetes则辅助完成部署操作并将容器放置在新的或现有虚拟机中。
7、Keystone
顾名思义,Keystone模块是OpenStack体系架构中的核心模块,负责将所有的OpenStack模块组织在一起,在OpenStack中充当了非常重要的角色。
Keystone通过维护一个服务目录来作为OpenStack服务及模块的集中式注册表,所有安装的模块都要向Keystone进行注册,注册完成之后,Keystone就知道哪些模块属于OpenStack云以及如何到达这些模块(去往这些模块的IP地址以及这些模块所监听的端口)。如果模块之间需要进行相互通信(如Neutron希望与Nova进行通信),那么就需要利用Keystone模块来确定目标模块是否存在以及如何到达。
用户认证和授权均由Keystone模块完成。用户登录时,会将身份认证凭证发送给Keystone,由Keystone确定该用户是否有效。此外,Keystone还定义了用户可以访问的项目以及用户对每个租户的访问权限。Keystone模块可以为这些身份认证和授权信息维护自己的数据库,也可以使用现有的LDAP(Lightweight Directory Access Protocol,轻量级目录访问协议)等后端数据库。
注意:OpenStack中的权限分配不是分配给用户,而是分配给用户和租户(需要记住的是,OpenStack中的租户与项目相同,表示OpenStack用户所创建的虚拟环境的一个实例)。
从下图可以看出,用户可以访问多个项目,同一个用户可能在Project-A中拥有管理员权限,而在Project-B中仅拥有非常有限的权限。

通过身份认证和授权的用户对每个模块都有特定的访问权限。例如,允许用户使用Nova启动新虚拟机,但不允许用户通过Neutron将虚拟机连接到网络上,或者不允许使用块存储设备为虚拟机创建存储空间。因此,每个模块都要检查用户的权限信息,以确定允许用户执行哪些操作或者不允许用户执行哪些操作,检查操作可以利用授权令牌来完成,授权令牌由Keystone负责分配和维护。
授权令牌是传递给用户所调用的每个模块的“临时证件”,这些模块可以验证来自Keystone的令牌并了解该用户的权限。如果该用户对虚拟机的操作请求涉及网络创建操作,那么Neutron将不允许这样做,因为Keystone已经告知Neutron,该令牌无权创建网络。
8、Glance
如果要创建虚拟机和容器并在其中运行应用程序,那么就需要该应用程序的源镜像,源镜像由应用程序开发者提供,如Windows虚拟机需要Microsoft提供的Windows镜像文件,F5负载均衡器虚拟机需要运行由F5提供的负载均衡器应用程序镜像。
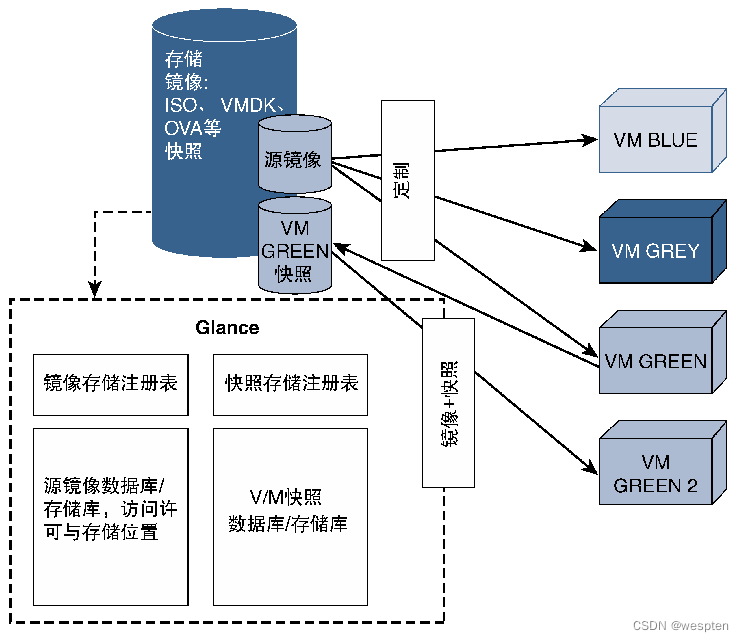
这些镜像可以存储在地理上分散的存储设备中,而且拥有不同的访问方法,虽然有模块负责存储设备的访问方式,但是对于最终用户来说,镜像的存在性才是最重要的。Glance是OpenStack的一种模块,旨在发现和管理镜像存储库以及镜像注册表。此外,Glance还可以使用现有的虚拟机快照(Snapshot)并将其存储为模板镜像。
快照镜像是虚拟机当前运行状态的捕获信息。刚创建虚拟机的时候,假设需要实现执行路由功能的VNF,此时无任何自定义配置,用户可能会在其中配置特定的路由协议(如BGP全路由反射器),那么该VNF的运行状态就是一个BGP-RR,可以拍摄快照来及时冻结当前状态。可以为虚拟机拍摄多个快照。
快照主要有两大作用。一是可以为当前的虚拟机状态创建备份,而且可以随时将虚拟机恢复到某个冻结或快照阶段。如果给路由反射器VNF增加了新的地址簇,此后又希望回滚这些变更操作,那么用户就可以简单地告诉OpenStack恢复快照。拍摄快照的另一个原因是复制当前的服务器状态。
如果需要生成另一个路由反射器,那么就可以使用第一台路由反射器的快照来实现,在这种情况下,启动新实例时,就会将VNF的基础镜像与该快照组合在一起。
可以利用虚拟机源镜像实例化多个处于运行状态的虚拟机。Glance负责存储源镜像以及运行镜像的所有快照信息。
从下图可以看出,Glance与存储单元进行交互,并维护一个有关镜像和快照位置、访问权限以及其他文件细节的数据库。
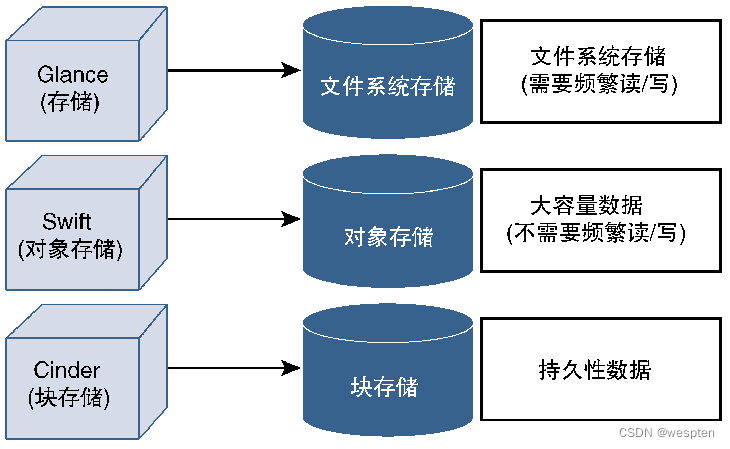
9、Swift和Cinder
Cinder是用于管理块存储设备虚拟化的OpenStack模块,最初的Cinder是Nova的功能延伸(称为Nova-Volume),后来逐步发展成为独立模块。Cinder模块可以为OpenStack管理的虚拟机提供永久存储服务,通常将Cinder块存储设备称为Cinder卷(Cinder Volume)。CSP可以提供基于服务产品(如数据库存储、文件存储或使用Cinder模块的快照)的块存储目录。
存储Cinder所用数据的物理磁盘可以是本地存储器,也可以是安装在远程设备上的外部存储器。与外部存储设备进行通信时,可以使用iSCSI、光纤通道、NFS(Network File System,网络文件系统)或专有协议等传输机制。可以利用特定厂商的驱动程序来支持一些附加功能或者由使用第三方插件的特定厂商驱动程序对Cinder模块进行增强,支持的第三方存储阵列主要有EMC、HP、IBM、Pure Storage以及Solid Fire等。
Swift是OpenStack的另一个存储模块,可以提供对象存储功能,与Amazon S3非常相似。Swift使用HTTP来访问存储设备,由于采用HTTP访问方式,因而并不要求将Swift存储在本地计算节点上,它可以存储在任何远端设备中(包括Amazon S3或任何其他平台)。
利用这种可以将数据存储在任意平台上的能力,Swift为人们提供了一种性价比非常好的基于任意商业平台实现存储需求的方法。
虽然OpenStack的多种存储选项看起来可能很复杂,但这些模块一直都在改进并提供越来越优异的特性及功能。Swift和Cinder可以根据数据需求提供差异化的存储产品,例如,Cinder非常适合存储虚拟机永久数据并支持传统的数据存储功能,而Swift则非常适用于高度可扩展的大批量数据,如图像或媒体文件,如下图所示。
1. 文件系统存储
该数据存储方式采用层次化格式保存信息,通过路径信息来定位文件,文件属性(如所有者、读/写权限等)存储在元数据中并由文件系统进行处理。该存储方式适用于本地存储或局域网存储。不过,由于元数据空间有限,基于文件系统的存储方式扩展性较差且缺少文件存储属性(如所有者、组),因而它不适用于大量文件的存储场景。
2. 块存储
块存储将数据保存在大小相同的块(Block)中,可以将一个文件切割成多个块,除了与每个块相关联的地址之外,这些单独的块没有任何相关联的元数据,必须由应用程序来跟踪文件所分发的块,并在需要时组合这些块以提取文件内容。该存储方式提供了高性能的数据处理能力,通常用于数据库或事务型数据挖掘(此时只需要处理一小段信息)。
此外,由于块存储方式不存储元数据,因而不存在困扰文件存储方式的扩展性问题,这使其成为存储运行时数据的理想选择。OpenStack支持块存储,在支持块存储之前,虚拟机使用的是所谓的临时存储,意味着虚拟机的内容会在虚拟机关闭时丢失。
3. 对象存储
对于对象存储(也称为基于对象的存储)来说,完整的数据或文件及其元数据都作为单个实体进行保存,通常将该实体称为对象。与块存储相比,对象存储不会将文件拆分为块。将文件存储为对象时会有多种属性,如唯一标识符以及与这些文件相关联的应用程序。对象不采用层次化格式进行组织,而是与其他对象都放置在相同层次上,形成平面式结构。
服务器或应用程序可以利用唯一标识符来快速访问任意对象,因而该存储技术为云体系架构提供了有效的存储解决方案。对象存储也有其缺点,如果要对对象存储进行任何编辑,那么都要检索整个对象以进行编辑并保存。
10、Ceilometer
Ceilometer(云高仪)一词用于描述测量云层和高度的设备。OpenStack中的Ceilometer模块可以对采用OpenStack方式部署的云提供相似功能,旨在收集云资源的统计数据及使用数据,这些数据对于跟踪云资源的利用率、计费以及其他意图来说非常有用。
11、Heat
OpenStack的编排服务被称为Heat,该服务定义了云应用的部署方式。对于NFV来说,指的就是要部署的NFV网络以及每个虚拟机所需的资源。最初的Heat与AWS CloudFormation服务非常相似,现在已经逐步发展壮大,包括了更多的服务,可以提供比CloudFormation更多的功能。
部署由虚拟机、网络、子网、端口等组成的云时,需要在Heat模块中将这些要素定义成文本文件(称为Heat模板)。Heat支持两种格式的模板,其中的HOT(Heat Orchestration Template,Heat编排模板)与AWS CloudFormation不兼容,因而通常使用基于YAML规范的模板格式,该模板格式称为CFN(CloudFormation Compatible Format,CloudFormation兼容格式),顾名思义,该格式与AWS CloudFormation相兼容。CFN模板使用JSON(JavaScript Object Notation,JavaScript对象表示法)规范来格式化模板。
YAML是一种标记语言,首字母缩写YAML是递归缩写方式,因为它代表“YAML Ain’t Markup Language”(YAML不是标记语言)。
Heat编制服务同时支持基于虚拟机和基于容器的云部署需求,Heat服务通常运行在OpenStack控制器节点中。与其他OpenStack模块相似,Heat模块也支持两种访问方式,一种是通过CLI客户端实现API调用,另一种是在Horizon仪表盘中通过Web客户端进行访问。
有关Heat模板的具体格式信息,大家可以参阅OpenStack的相关文档。理解Heat模板所定义的参数(如需要使用的镜像、需要分配的资源以及网络类型等)以及这些参数对构建虚拟环境的作用,对于大家的学习来说非常有帮助。此后就可以利用Heat模板来部署已定义的虚拟环境的多个实例。完成部署操作之后,Heat将调用Nova进行计算,调用Neutron实现网络功能,或者调用其他OpenStack模块来获得其所需的资源。
注:YAML和JSON都属于数据格式化与编码语言。JSON指的是由RFC 7150定义的JavaScript对象表示法。这里所说的数据编码并不是指比特和字节层面的低级编码,而是指数据结构、变量及其数值以及应用层参数的编码。
常见的数据编码方式还有XML(Extensible Markup Language,可扩展标记语言)、谷歌的ProtoBuf(Protocol Buffer,协议缓冲区)以及Facebook的Thrift等多种方法。目前有很多开源工具都能实现这些格式的相互转换,因为这些编码方式在本质上只是以不同的方式打包相同的数据,因而可以在这些格式之间进行翻译。
JSON格式使用大括号来界定数据结构,使用“:”来链接键值对:
{
"Books":
{
"Technology":
{
"title":"NFV with a touch of SDN",
"ISBN" :"0134463056"
},
"Fiction":
{
"title" : "To Kill a Mocking Bird",
"ISBN" : "0446310786"
}
}
}YAML也使用“:”来分隔键值对,并采用缩进方式来定义数据结构或对象块。
将JSON转换成YAML格式则如下所示:
Books:
Technology:
title: "NFV with a touch of SDN"
ISBN: "0134463056"
Fiction:
title: "To Kill a Mocking Bird"
ISBN: "0446310786"12、总结
下图列出了这些模块的功能与作用:
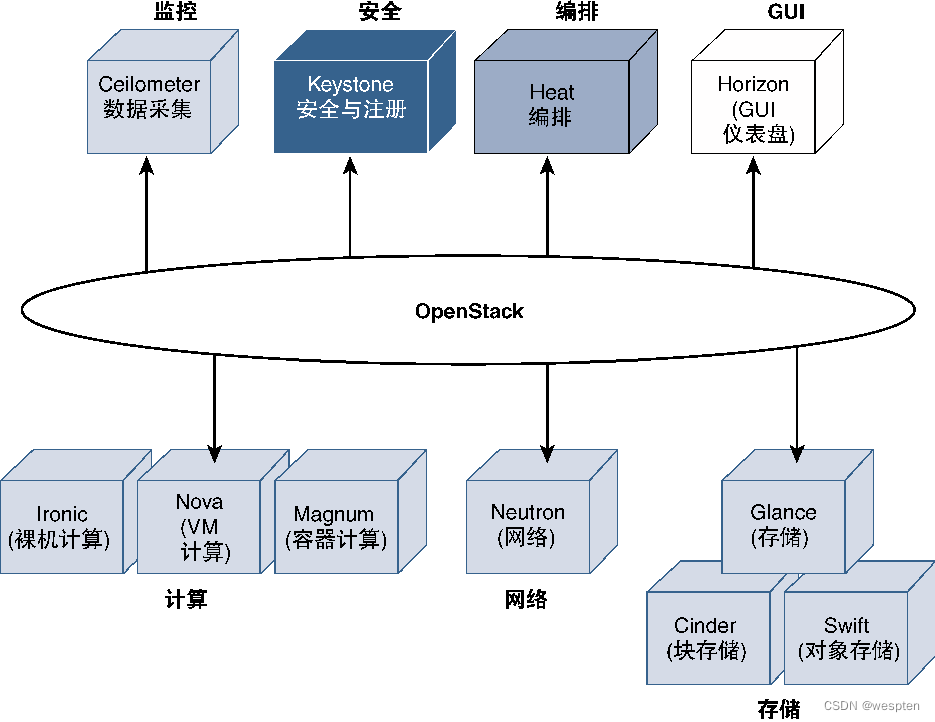
需要强调的是,OpenStack及其模块属于NFVI体系架构中的MANO模块,这意味着这些模块本身并不会部署虚拟机。例如,Nova只能请求需要为虚拟机配置的计算资源量,但实际使该配置可用并生成虚拟机的是Hypervisor。同样,Glance和Cinder/Swift的作用也只是管理和方便使用虚拟化存储资源,其本身并不创建虚拟存储。
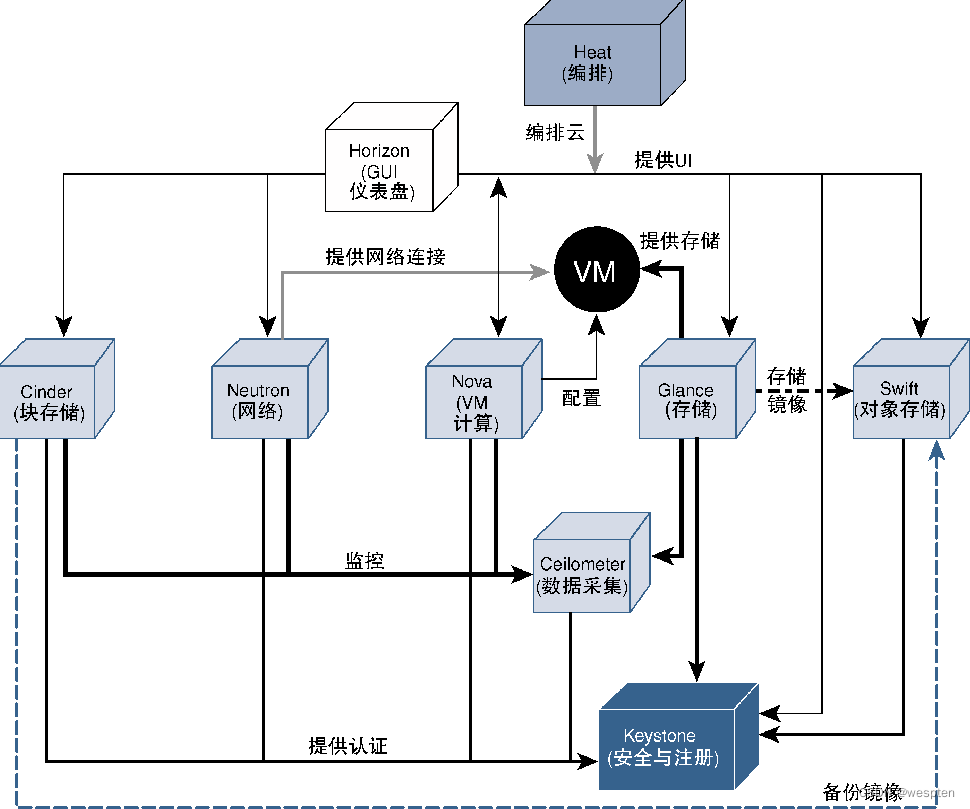
下图给出了OpenStack各个模块之间协同工作的示例,可以看出这些模块相互交互以实现OpenStack云的概念模型。
三、OpenStack 网络
OpenStack利用Neutron模块来实现OpenStack云中的网络能力,考虑到使用OpenStack实现NFVI的重要性。
1、Neutron简介
Neutron模块可以管理包括子网、端口及网络在内的3类实体,简单而言,这3类实体组合起来就可以定义一个虚拟二层网络,其中包括为连接在该二层网络上的所有虚拟机都定义的IP地址空间。为了更好地理解Neutron模块,有必要理解Neutron对这些术语的定义方式。
1. 子网
子网表示可以分配给虚拟机的IP地址块,因而子网块就是一个二层广播域,而且可以选择一个与外部进行通信的默认网关。如果OpenStack用户希望在他们的虚拟环境中创建网络,那么就可以通过Neutron API调用来定义子网,方法是提供希望虚拟机所使用的IP地址空间。
2. 端口
Neutron将连接在虚拟机上的虚接口称为端口,并从这些端口所属的子网IP池中为这些端口分配IP地址,因而端口负责将虚拟机纳入特定网络。可以利用Neutron API创建、读取、更新和删除(称为CRUD[Create、Read、Update、Delete]功能)这些虚接口。
3. 网络
Neutron将整个虚拟二层域称为网络,网络包括已定义的子网以及相关联的端口。 OpenStack用户需要在关联子网以及端口之前先定义网络,并通过OpenStack API(更准确的说法应该是Neutron API)来管理网络。如果用户希望在虚拟环境中使用多个子网,那么就可以定义多个网络。单个网络中的设备可以通过二层方式进行通信,但是如果定义了多个网络,那么就必须通过路由器来连接这些网络,否则这些网络将无法相互通信。
下图给出了Neutron模块所管理的这些实体之间的关系图。

从图中可以看出,端口与虚拟机/VNF相关联,网络包括了端口及子网,存在多个网络时需要通过路由器进行相互通信。此外,从图中还可以看出Neutron及其实现的网络是NFV基础设施的一部分。
OpenStack租户可以利用Neutron API在其虚拟环境中创建和管理自己的私有网络,下图给出了OpenStack租户在使用这些Neutron API时所必须遵循的流程。

2、Neutron网络类型
Neutron可以创建多种类型的网络,其中值得关注的网络类型主要有以下几种。
- 扁平化网络:扁平化网络只有单个网段,所有设备都属于同一个广播域,因而扁平化网络的子网使用的IP地址对于主机及其他网络实体来说都是共享、可见的。
- 本地网络:该网络与扁平化网络正好相反,这类网络可以进行分段,而且每个网段都包含一个独立的广播域,因而本地网络中的每个网段都要占用一个IP地址空间,而且该IP地址空间完全本地化,对于同一网络中的其他网段来说不可见。
- VLAN网络:该网络利用802.1Q VLAN标记来区分用于外部通信的网络,所有离开网络的流量均采用802.1Q进行封装,允许同一VLAN中的虚拟机使用交换机(通常是虚拟交换机,不过也可以是物理交换机)进行相互通信,而不需要通过路由器进行互连。如果要与外部的其他VLAN进行通信,那么就需要利用路由器(虚拟路由器或物理路由器)来互连这些VLAN网络。
3、Neutron提供商和租户网络
到目前为止所讨论的Neutron网络主要集中在利用Neutron模块配置租户网络,OpenStack本身还需要一个由服务提供商管理的网络,通过该网络将OpenStack服务器与物理网络相连,同时互连多个OpenStack服务器。
该网络(在OpenStack术语中称为提供商网络)由OpenStack管理员进行部署并管理,Neutron也能提供该网络的管理和配置功能。通常情况下,这类网络应该是扁平化网络或VLAN网络,且拥有指向外部网关的连接。
租户或用户为各自的云创建的网络(同样使用Neutron功能)称为租户网络,每个租户都维护自己的租户网络,OpenStack利用Linux命名空间方法来实现这些网络的相互隔离。
4、Neutron插件
可以通过Neutron插件来扩展和增强Neutron的核心网络功能,这些插件都是附加软件,对Neutron的基本API进行了扩展,可以由OpenStack管理员添加这些插件并提供给最终用户,使得Neutron能够支持更加广泛的网络技术,并且为客户利用这些技术(如VXLAN[Virtual Extensible LAN,虚拟可扩展局域网]或GRE[Generic Routing Encapsulation,通用路由封装])管理自己的云网络提供更多选择,或者提供防火墙、路由器或负载平衡器等附加服务,从而在虚拟网络中使用这些服务。
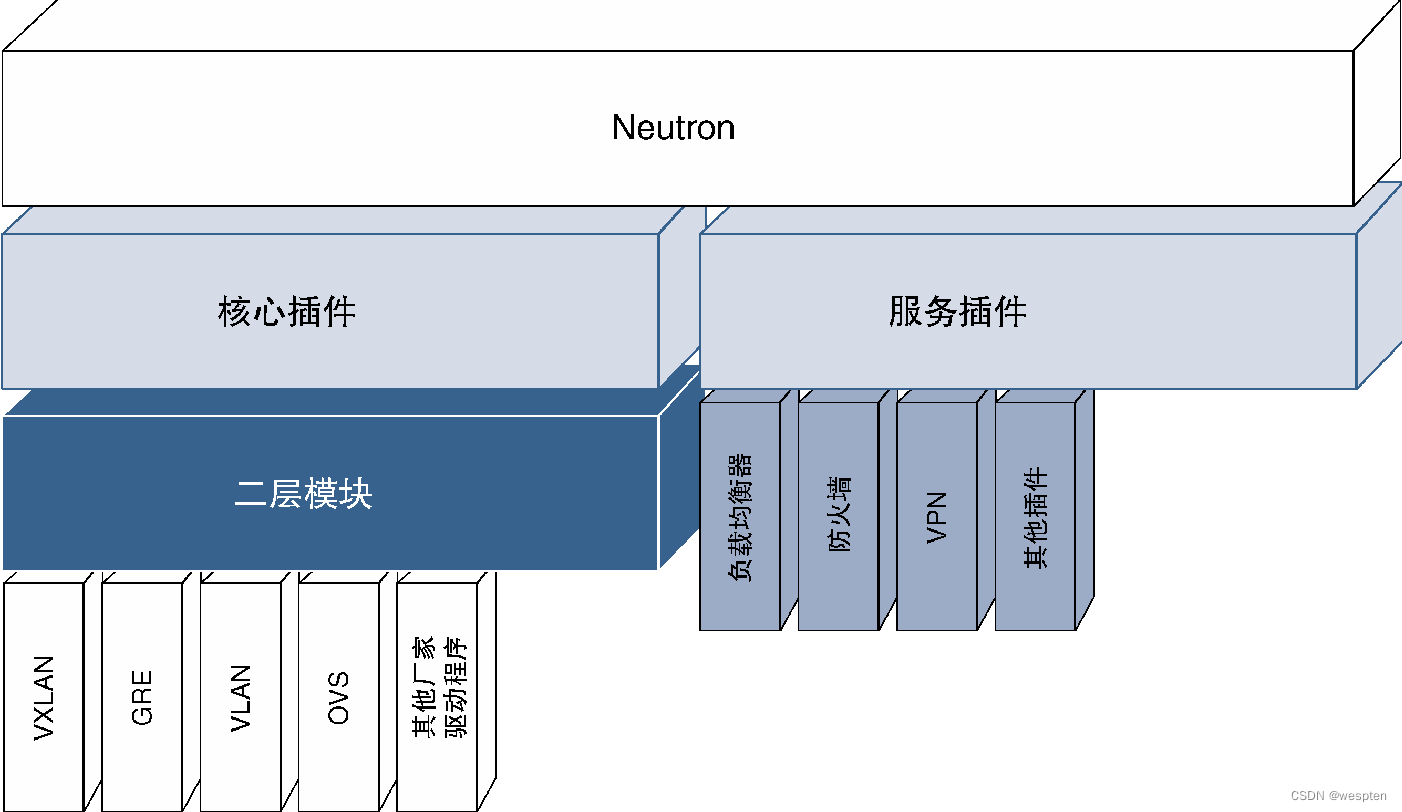
下图给出了常见的Neutron插件信息,可以看出Neutron插件主要分为核心插件(Core Plug-In)和服务插件(Service Plug-In)两类。对于最终用户(只是简单地利用OpenStack的前端环境以及API来部署它们的云环境)来说,可以不必过分关注这些插件的分类信息,只需要了解CSP所提供的Neutron功能即可。下面将简单介绍这些Neutron插件。
1. 核心插件
这类插件可以增强Neutron对于网络协议及设备的理解与管理能力,如Neutron可以利用核心插件来增加对VXLAN或GRE协议的支持能力,提供协议增强能力的核心插件通常被称为Type Driver。与此相似,Neutron在各种厂商设备上使用这些协议的能力是由另一类名为Mechanism Driver的核心插件实现的。
下图给出了这两种核心插件的示例。简而言之,核心插件负责处理二层和三层功能,而且可以通过Neutron在不同的厂商设备(虚拟或物理设备)上实现这些功能。
2. 服务插件
服务插件支持网络服务且允许通过Neutron来管理这些网络服务(从而允许OpenStack用户管理、配置及使用这些服务),常见的服务主要有实现路由协议的路由服务、实现流量过滤与阻塞的防火墙服务以及负载均衡服务等。
这些插件通常由网络厂商开发并提供,使得Neutron能够与VNF协同工作。例如,对于通过Neutron API管理的Cisco CSR1000v或Nexus1000v来说,可以在Neutron中使用IOS-XE或NX-OS的Cisco插件(确切而言,应该是Mechanism Driver核心插件)。
如果OpenStack管理员(实际上是CSP)选择使用设备商的插件以及该设备商的VNF,那么CSP的客户就可以在他们的虚拟环境中选择使用该VNF的实例(可能是路由器、防火墙、交换机或其他网络功能),并且可以使用可调用的Neutron API来管理这些实例(请注意,这些API可能是标准API,也可以是标准API的扩展)。
对于CSP来说,这样做的好处是可以在自己的OpenStack服务中提供更多的高级网络功能,从而大大增强服务提供能力,并实现与竞争对手的差异化竞争。对于厂商来说,则可以根据VNF的使用及许可情况获得收入。
请注意,Neutron管理的厂商设备并不一定非得是VNF,也可以利用物理设备或集成在Hypervisor中的软件来实现该网络功能。如果使用物理设备(如ToR[Top-of- Rack,架顶式]交换机)来实现该网络功能,那么只要有相应的可交互插件,Neutron就能管理该物理设备。在这种情况下,虽然客户不能在自己的虚拟环境中创建实例,但是仍然可以通过OpenStack环境中的Neutron API设置相关的设备参数。如果这些网络功能集成在Hypervisor中,那么就可以像VNF一样将这些网络功能所提供的能力提供给CSP的客户,不过这种紧密集成方式可以提供更好的性能及管理能力。
一般情况下并不直接将Type Driver和Mechanism Driver用作插件,而是将其纳入ML2(Modular Layer 2,二层模块)驱动程序插件。根据设计规则,Neutron只能添加一个核心插件,那就意味着如果Neutron将某个设备商的插件用作核心插件,那么Neutron就无法同时将其他插件用作核心插件。
ML2核心插件则可以解决这个问题,ML2核心插件可以同时使用多个设备商插件,允许不同的二层/三层技术同时存在。这些API扩展能力是通过驱动程序(Type Driver和Mechanism Driver)代码实现的,我们可以将驱动程序视为ML2的插件,将ML2视为Neutron的插件,不过为了将它们与插件区分开来,这里仍然使用术语驱动程序。对于Neutron来说,ML2是Neutron的唯一核心插件,充当Neutron与驱动程序之间的中介。
5、OVS
传统网络中的服务器都通过物理交换机连接网络,从而实现网络的连接性。
服务器虚拟化之后,不同的虚拟机之间也需要建立连接能力,从而催生出了与物理交换机相似的软件实体,该交换机不但可以互连不同的虚拟机,而且可以连接物理接口,从而提供物理服务器的外部连接。OpenStack将提供该功能的软件模块称为虚拟交换机。
OVS(Open Virtual Switch或Open vSwitch,开放虚拟交换机)是一种开源虚拟交换机,最初由Nicira(现已被VMware收购)开发并提供,后来将其代码作为开源软件对外发布。OVS是一种多层虚拟交换机,可以提供虚拟接口与物理接口之间的标准交换协议。
其他厂商也推出了很多类似的软件交换机,常见的有Cisco的Nexus 1000v以及VMware的虚拟交换机(分布式vSwitch或标准vSwitch)。不过,考虑到OVS是开源软件,所以OpenStack社区将OVS作为默认交换机。除此之外,所有的外部控制器都能控制OVS,而且对于OpenStack来说,利用Neutron的OVS插件就能轻松实现OVS功能。不过,OVS并不是OpenStack的一部分,OpenStack也可以使用其他可用虚拟交换机,只要这些交换机有一个可用于Neutron的插件(更确切地说是一个ML2模块)即可。
OVS支持802.1ag、NetFlow、sFlow以及IPFIX等多种协议,而且还支持GRE、VxLAN、链路绑定以及BFD等。
OpenStack在Neutron中支持SR-IOV(Single-Root-I/O Virtualization,单根I/O虚拟化),方法是使用ML2模块实现具有SR-IOV功能的NIC(Network Interface Card,网卡)。如果使用了该软件,那么就可以利用具备SR-IOV功能的硬件所提供的虚拟化I/O端口来替代软件vSwitch。
6、配置OpenStack网络
前面描述了包括子网、端口以及网络在内的3个基本网络实体,为了更好地理解Neutron通过这些参数配置网络的方式,下面将详细解释相应的配置步骤。
虽然这里给出的配置步骤使用的是Horizon仪表盘(基于Icehouse版本),但是与其他OpenStack模块一样,所有步骤都可以通过API调用来实现,使用GUI仪表盘是为了更加友好。不过对于自动化脚本来说,通过API调用的方式更加直接有效。
第1步:配置网络。登录Horizon仪表盘之后,OpenStack租户通过Keystone进行身份验证,然后输入网络名称来配置网络,如下图所示。
第2步:定义3个网络实体中的第一个实体——子网。可以利用IPv4或IPv6地址来定义子网,如下图所示。

此时可以将网络与新创建的虚拟机相关联,并将该网络的端口与虚拟机相关联。这样一来,与该网络相关联的所有虚拟机都位于同一个二层网络中,可以进行相互通信。
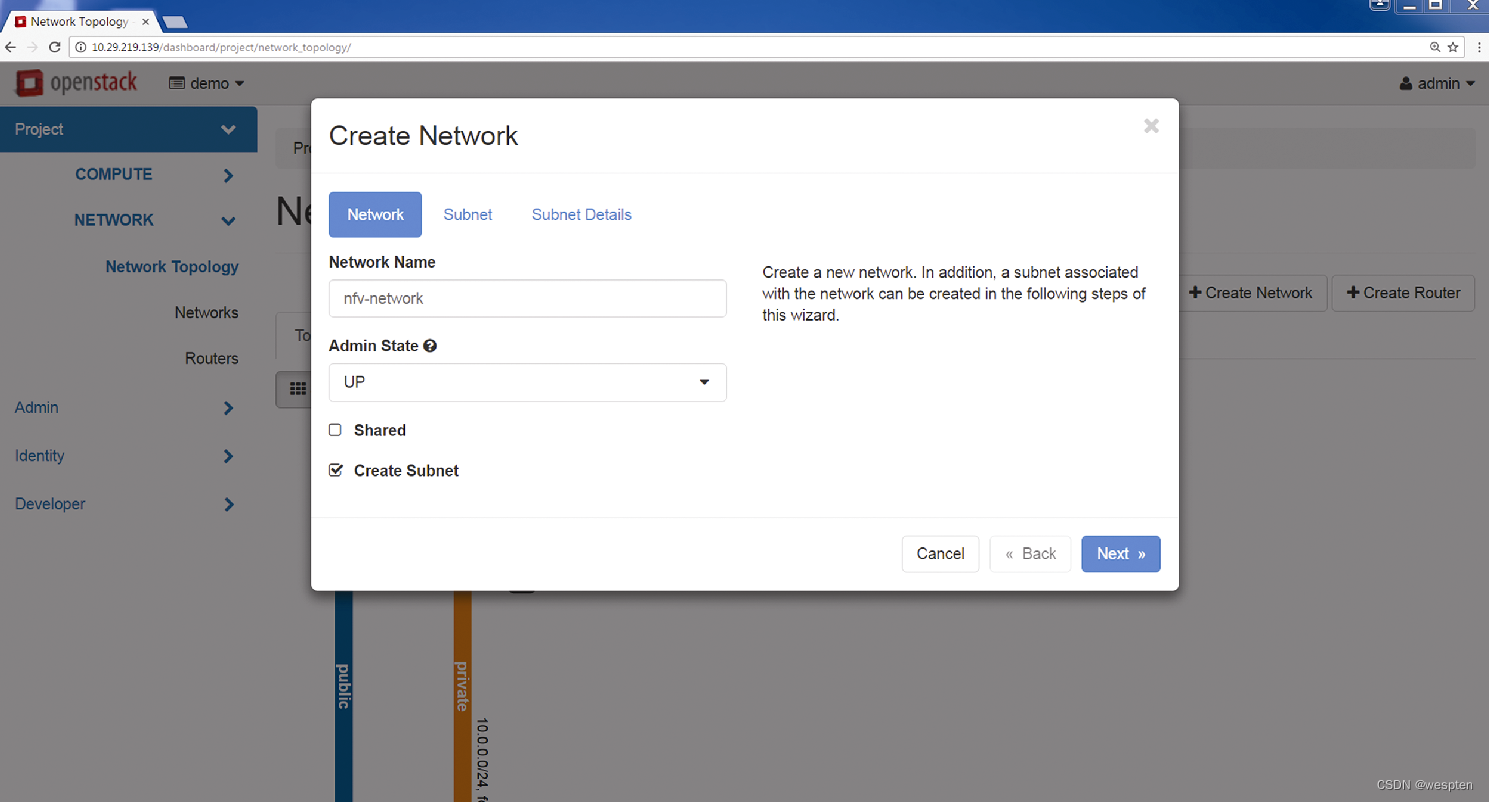
第3步:如果虚拟机需要与外部网络或者其他二层域进行通信,那么就需要通过路由器设备。此时可以通过同样的GUI创建路由器,然后再将路由器连接到可路由域。
从下图可以看出,路由器还连接了外部网络,从而提供了外部云环境的网络可达性。
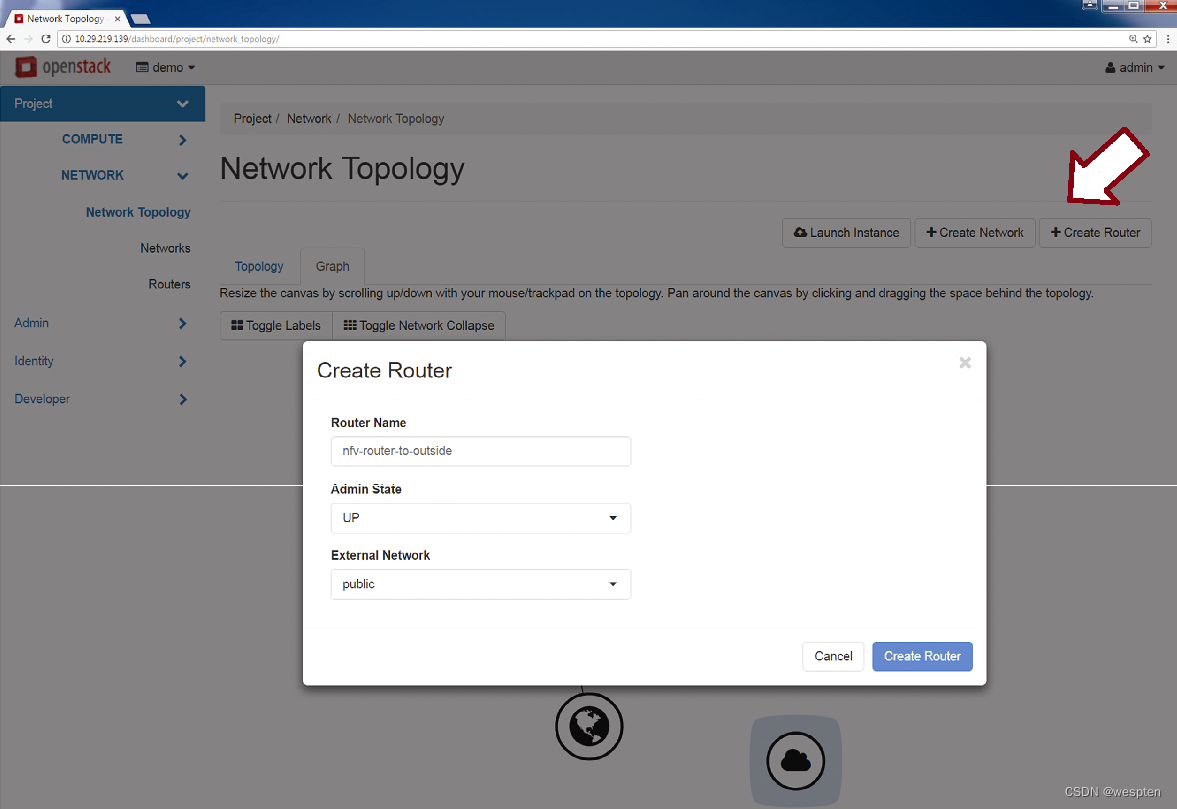
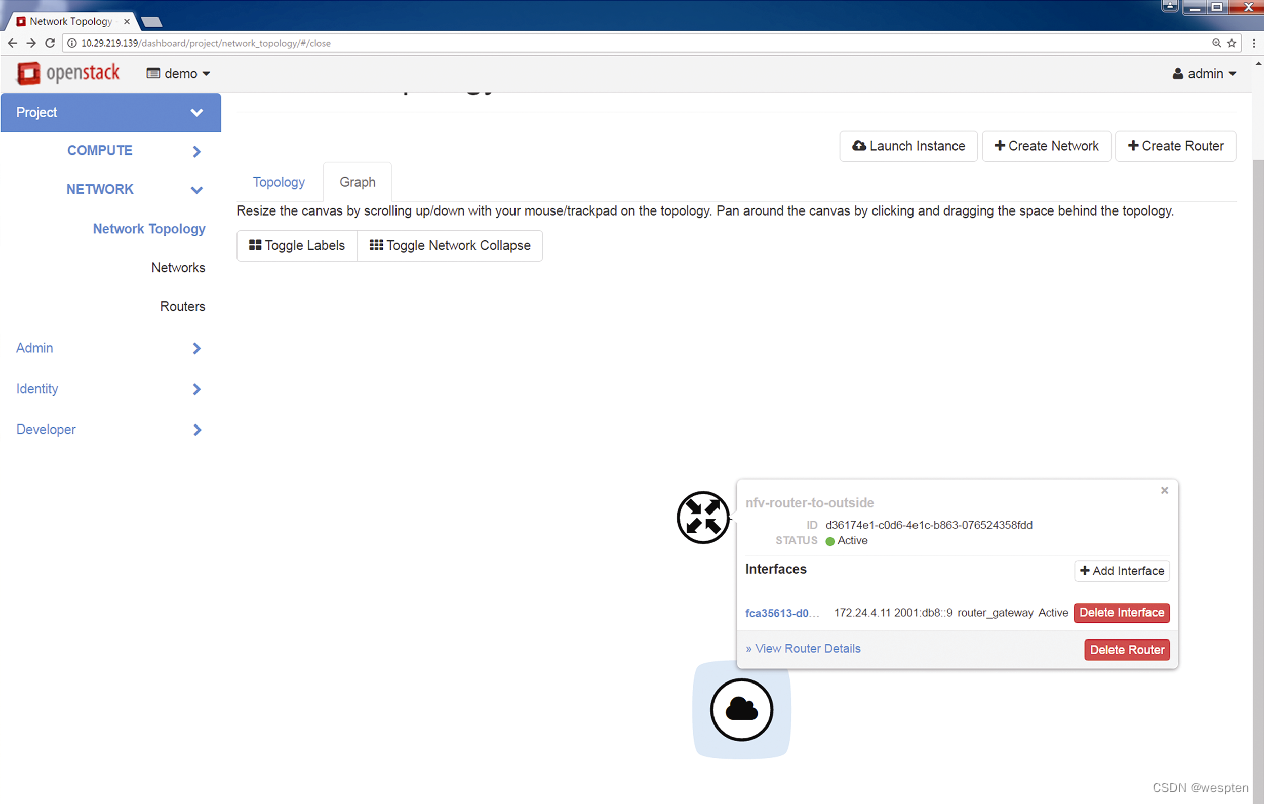
下图给出了创建拥有外部网络连接的路由器之后的拓扑结构图。
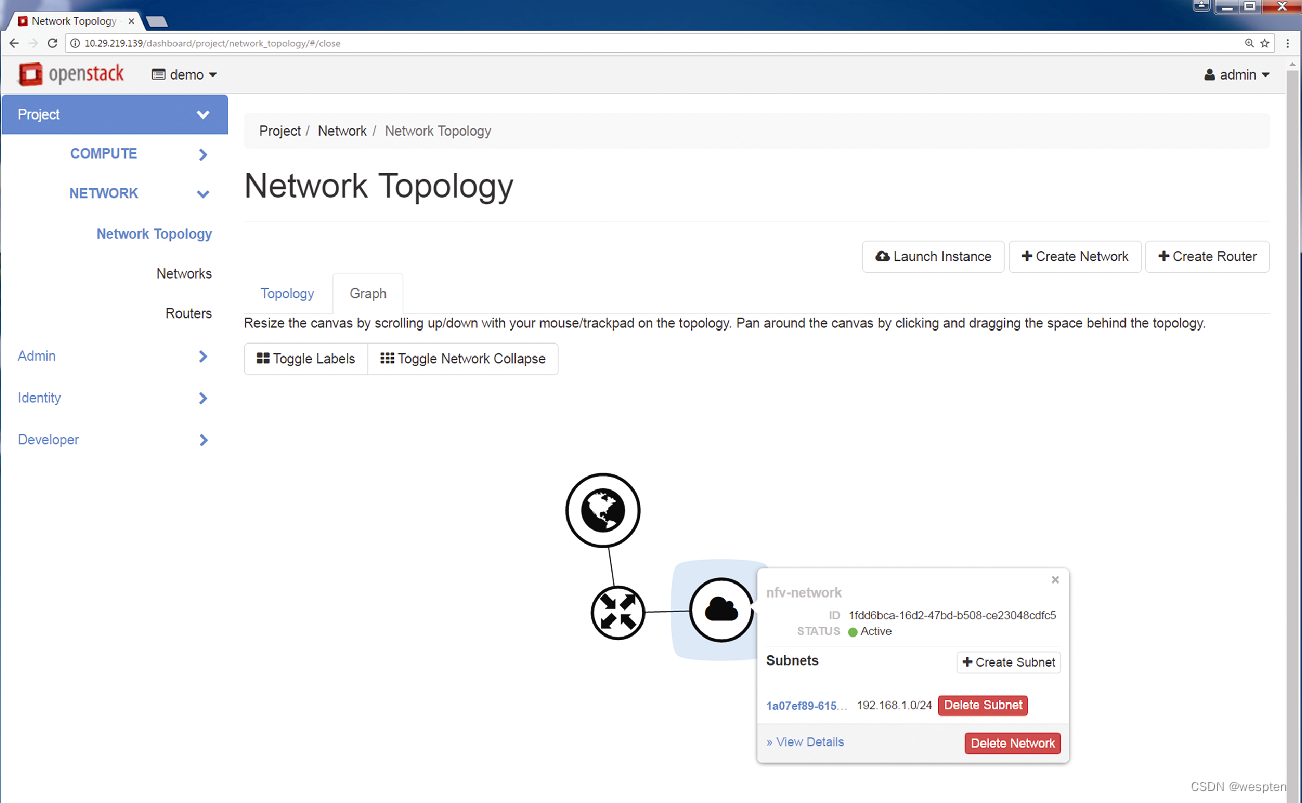
第4步:为了将二层网络连接到路由器,需要在路由器上创建一个接口,从而将路由器连接到前面定义的子网上,如下图所示。

完成该步骤之后,子网就拥有了外部网络可达性,如下图所示,并通过为该子网定义的默认网关访问路由接口。
四、OpenStack 高可用性
基础设施的高可用性意味着需要部署高可用性机制及设计选项,以避免硬件、应用程序或操作系统中的任何SPOF(Single Point Of Failure,单点故障)对基础设施上运行的服务造成影响。对于NFV部署方案来说,网络的高可用性极其关键,运营商级的实现方案需要确保99.999%的可用性。
NFV部署方案中的服务器、网络传输设备、NFVI组件、MANO工具、OSS/BSS(Operational and Business Support System,运营和业务支持系统)层以及VNF都可能存在故障点,必须对这些故障点加以保护。如果由故障原因而导致管理及编排功能受到影响,虽然不一定会影响VNF或VNF所执行的功能,但是一定会影响NFV的功能,如敏捷性、弹性以及所有的常规管理功能。
1、OpenStack服务的高可用性
虽然OpenStack的基础设施并没有提供大量措施来保障其弹性能力,但完全可以依靠主机操作系统提供的弹性和集群技术以及各种常规的高可用性机制来实现高可用性。
借助OpenStack的模块化基础设施(如Nova、Swift、Glance、Neutron以及Keystone等多种服务),可以采用多种形式的高可用性机制。
OpenStack的每个模块或服务都有各自的高可用性机制,随着这些服务的逐渐成熟,新的功能和特性不断被添加到OpenStack当中,这种高可用性实现机制可能还会不断发展变化并最终形成一个通用架构。每项OpenStack服务的高可用性都遵循以下概念,而且要根据具体的业务需求进行评估,因而基础设施的总体部署方案可以是这些模型的任意组合。
1. 有状态与无状态服务
OpenStack服务分为有状态服务和无状态服务。无状态服务在响应其客户的请求时无须额外的握手进程,对无状态服务的查询与请求都是相互独立的,而且响应也与之前的历史状态无关。因而复制无状态服务的服务模块较为简单,可以同时使用多个副本来提供服务的冗余性与负载平衡,任意实例出现故障后,其他实例都能接管其负载而不会出现服务中断。
常见的无状态OpenStack服务主要有nova-api、glance-api、keystone-api、neutron-api以及nova-scheduler。为了降低服务中断的可能性,CSP可以运行服务的多个副本,并将它们分散到不同的服务器或OpenStack节点中,向这些服务发出请求的客户端可以访问任何可用的有效服务,而且可以随时访问这些服务。
与此相对,有状态服务则要求服务模块与发出服务请求的客户端之间执行数据交换或握手进程。有状态服务对于后续请求的响应可能依赖于该客户端先前请求的响应,这就意味着对于同一个事务来说,客户端的每个请求或查询都必须连接到同一个服务实例。这类服务的高可用性实现机制相对较为复杂,服务模块的简单重复已无法保证会话期间客户端的每次请求都能到达同一个服务实例。
对于这类服务来说,如果要通过服务模块的复制方式来实现冗余性,那么就需要在这些重复的服务模块之间执行某种程度的协调操作,以便让它们知道彼此的状态,此时可以采用主动—主动冗余技术(Active-Active Redundancy)或主动—被动冗余(Active-Passive Redundancy)技术。常见的OpenStack有状态服务主要有数据库服务以及消息队列。
有状态服务与无状态服务之间的关系可以用TCP(Transport Control Protocol,传输控制协议)与UDP(User Datagram Protocol,用户数据报协议)进行类比。与TCP需要握手且面向连接一样,有状态服务也需要在客户端与服务模块之间建立连接,而且每次查询及响应都与之前的查询及响应结果相关。UDP的无连接实现与无状态服务相似,客户端与服务模块之间的每次请求、查询以及响应结果都完全独立。
2. 主动-主动冗余与主动-被动冗余
使用多个有状态服务实例的常见方法之一就是将这些实例部署为主动—被动或主动—主动实例。在主动—被动冗余模式下,每次只有一个服务实例处于有效状态,其他服务实例则作为备份而处于备用状态,这样就能确保客户端始终可以到达相同的实例(有效实例)。
如果有效实例出现故障,那么就由某个备用实例接管并处理客户端的请求,客户端与故障实例之间的当前会话可能会出现中断,可能需要重新建立会话。
在主动—主动冗余模式下,所有实例副本均处于有效状态,通过负载均衡器来处理客户端请求,向服务实例分发流量并跟踪每个服务的同一个会话。
3. 单服务器安装模式
如前所述,OpenStack可以采用AIO(All-In-One,一体化)部署模式,所有模块均位于同一台服务器上。这种单服务器安装模式可以在同一台物理服务器上使用多个AIO实例,因而具有软件冗余性。
不过从硬件角度来看,由于所有服务均运行在单台物理服务器上,因而不具备硬件冗余性。因此,AIO部署模式仅适用于演示或实验室环境,生产级部署方案则要求同时保护系统的核心模块(即控制器节点)和其他模块。
4. 集群与仲裁
为了实现大规模生产级部署方案的冗余性,可以采用集群技术。该冗余性方案的实现方式是将多个控制器节点组合在一起形成一个集群,部署多个集群并形成集群级冗余,从而获得额外的冗余性能力。
对于拥有偶数个控制器节点的集群来说,有效控制器节点可能并未出现故障,只是与备用控制器节点之间的连接出现了故障,主用与备用控制器节点之间的连接故障可能会导致备用节点错误地检测到主用节点故障并将自己设置为有效状态,此时就会出现多个有效控制器节点,从而导致服务出现中断。
为了解决这个问题,可以部署奇数个控制器节点或奇数个集群。在这种情况下,如果有效服务器出现了故障,那么切换到冗余节点的故障切换决策就将基于多数准则,从而保证数据和进程不受任何影响。我们将这种多数准则称为仲裁,如果仲裁范围内的多个节点出现故障,而且已定义策略强制要求的有效服务器数量不满足阈值要求,那么就会关闭整个集群,从而由另一个集群接管所有负载。
在OpenStack中使用集群技术时,通常采用标准的Linux集群管理软件,如Pacemaker或Veritas集群服务器。
基于Pacemaker的集群部署方案支持以下3种可能的部署选项:
- Collapsed(折叠)模式—AIO服务:该模式下的所有服务都托管在单个控制器节点上,并且将整个节点都复制到多台服务器上以实现冗余性。该部署方式要求服务器的处理能力必须足够强大,从而能够一次性托管所有服务。
- Collapsed(折叠)模式—分布式服务:该模式下的服务分布在多台服务器上,每台服务器都托管多种服务,实现冗余性的方式是复制这些服务器。该模式对服务器的计算能力需求较低,因为与AIO服务相比,该部署方式下的主机仅托管部分服务。由于只在每台服务器上分发一组服务,因而该部署方式需要更多的服务器。
- 基于Segregated(隔离)模式的部署方式:每种服务都在服务器上作为单一服务运运行,从而可以根据需要对每种服务提供灵活的扩展能力,而不会影响其他服务。该部署方式的冗余性能力是通过复制每台服务器实现的,缺点是需要更多的服务器。
下图给出了这3种服务部署选项的示意图:
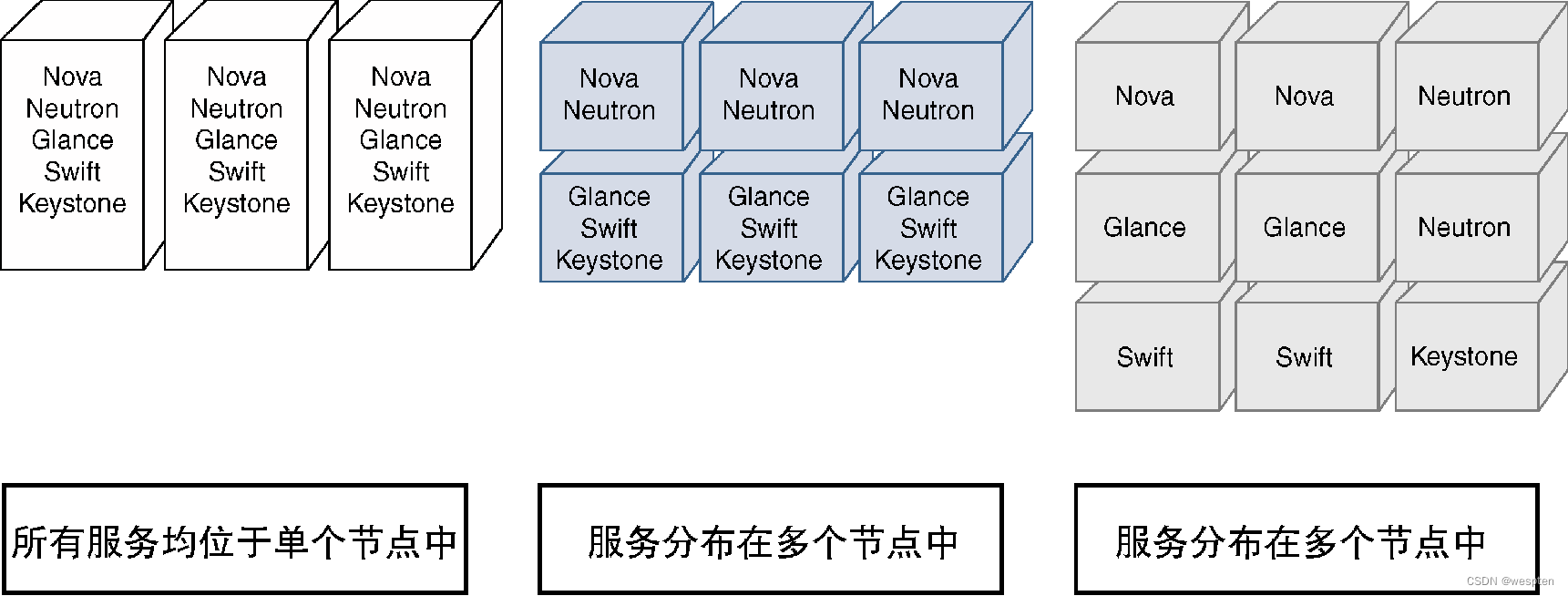
集群部署选项:
- Pacemaker是一种部署高可用性服务器的资源管理器开源软件,起源于Linux的高可用性项目,后来逐渐发展成为一款独立软件。
- VCS(Veritas Cluster Server,Veritas集群服务器)是由Symantec开发的一款商业软件,该高可用性集群软件支持UNIX、Linux和Windows操作系统,可以为系统软件、应用程序、数据库以及网络文件共享提供集群能力。Keepalived
- Keepalived是一款可提供负载均衡和高可用Linux基础设施的开源软件,用于管理去往OpenStack服务的数据包流量(基于四层负载来均衡去往有效服务的流量)。Keepalived的高可用性基于VRRP协议。与基于集群的场景相比,Keepalived的高可用性架构中没有额外的管理软件部署该功能。VRRP
- VRRP(Virtual Router Redundancy Protocol,虚拟路由器冗余协议)是一种解决网络单点故障的动态协议。VRRP将一台主用设备指派为虚拟网关以处理所有入站流量,如果主用设备出现了故障,那么备用设备就会接管主用设备的功能,从而保证网络的连续性,实现高可用性网络。VRRP起源于专有协议HSRP(Hot standby Router Protocol,热备份路由器协议)。
2、OpenStack云的冗余性
OpenStack云冗余机制是为了实现OpenStack云的高可用性,确切而言,这些冗余机制的目的是保证OpenStack控制器节点的可用性。虽然这些方法为OpenStack云用户提供了更可靠的基础设施,但是对于用户来说却是不可见的,并没有减轻用户设计方案的冗余性需求,用户仍然需要在设计方案中部署额外的冗余措施,从而在VNF上实现应用级的冗余性(如路由协议、VRRP等),同时还要在虚拟机与容器之间为VNF设计冗余措施。
OpenStack提供了一些有用的特性来简化和帮助用户实现VNF级别的冗余性设计。
例如,用户可以创建虚拟机的多个副本来实现虚拟机级别的冗余性。这些虚拟机可能处于主用/备用配置状态(即一组虚拟机被动地作为另一组虚拟机的备份),也可能处于主用/主用配置状态(即运行在两组虚拟机上的进程相互备份,同时还实现负载分担),无论处于哪种状态,都应该采取一定的虚拟机(或虚拟机组)部署策略,以免共享基础设施(或者具体地说是计算节点)出现故障,从而最大限度地减少同时发生故障的可能性。如果没有实现故障域的隔离,那么整个冗余性机制都会因单个控制器节点的故障而全部失效。
为了实现虚拟机的策略部署,OpenStack提供了Affinity(亲和性)以及可用区(Availability Zone)机制。
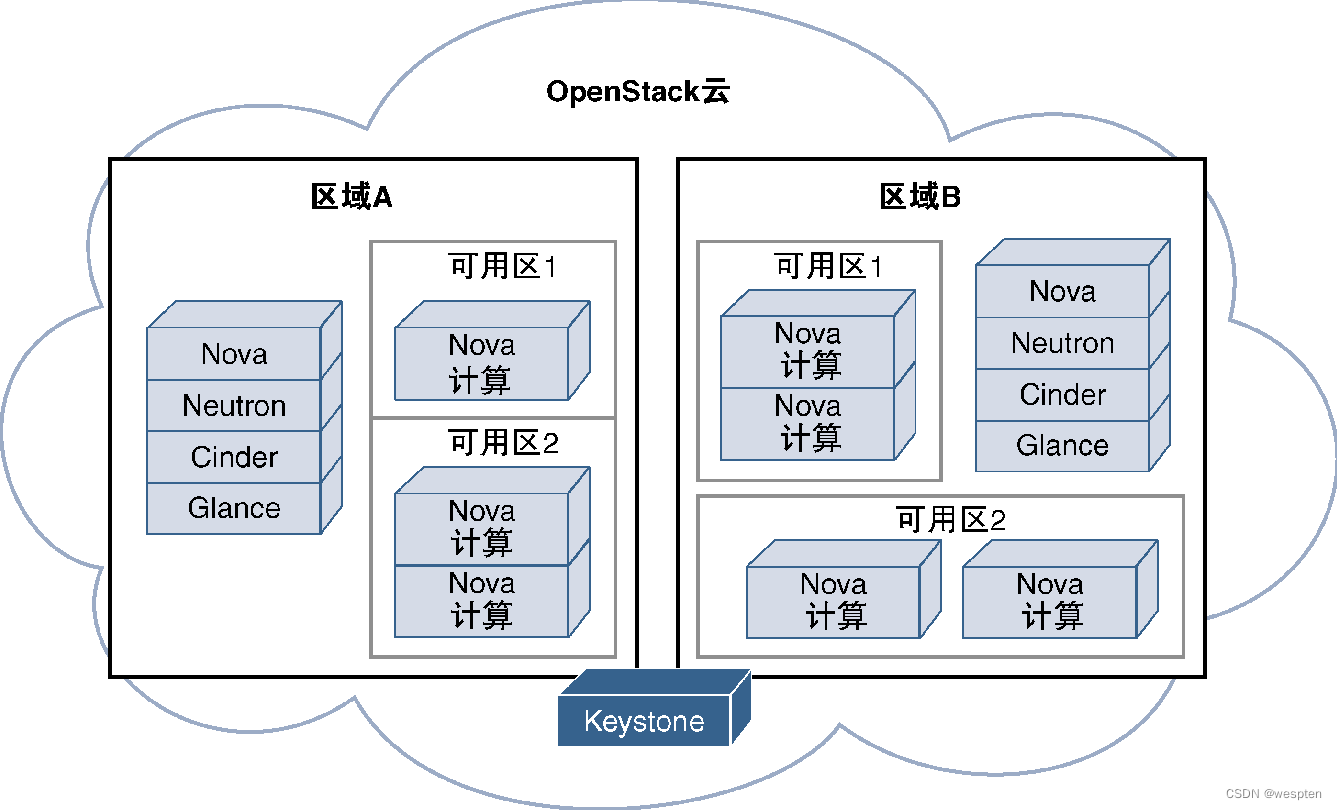
在介绍这两个概念之前,有必要先解释一下OpenStack的区域(Region)概念。如果OpenStack站点采用了分布式部署模式且属于单个云,那么就可以将它们划分成多个区域,每个区域都有一套完整的OpenStack模块,仅在各个区域之间共享Keystone模块,这样就可以在分布式OpenStack部署方案中实现分组并基于地理距离进行隔离。每个区域都会提供一个独立的API端点,可以看到区域内的所有模块。
例如,Glance只能查看本区域内的镜像,而不能查看其他区域内的镜像。因此,区域内的模块使用的都是本地资源,创建虚拟机时,由Nova提供计算资源,然后请求本区域内的Cinder和Neutron提供相应的网络和存储资源。从本质上来说,可以将OpenStack区域视为独立部署的OpenStack模块子组,这些子组通过一个共同的OpenStack云连接在一起。
OpenStack可以在每个区域内定义可用区,每个可用区都代表一个故障域。连接在相同电源上的服务器都共享同一个可用区,因为一旦该电源出现中断,那么所有的服务器都将同时受到影响。同样,连接在相同上行交换机上的服务器也都位于同一个可用区内,因为它们共享相同的数据路径。为了最大限度地实现虚拟机的高可用性,必须将冗余虚拟机放置在不同的可用区中。用户创建虚拟机时,可以在自己的区域内指定可用区,并将其作为参数之一传递给Nova模块。
Affinity组为OpenStack提供了另一种控制虚拟机部署位置的方法。可以由提供商为每个Nova实例指派Affinity组,OpenStack用户可以请求将他们的虚拟机运行在同一个Affinity组中,也可以请求将部分虚拟机运行在其他Affinity组中,这样就可以在一定程度上允许用户将自己的虚拟环境分发到提供商预先创建的多个主机组上。
下图给出了OpenStack的区域及可用区概念:
3、支持VNF移动性的实时迁移
对于任何云部署方案来说,考虑到业务及维护等原因(如定期维护时段、服务器或数据中心的整合或迁移、将VNF迁移到低电价数据中心以提高能效、将VNF从高利用率的服务器迁移到低利用率的服务器等),都需要用到VNF的移动性。
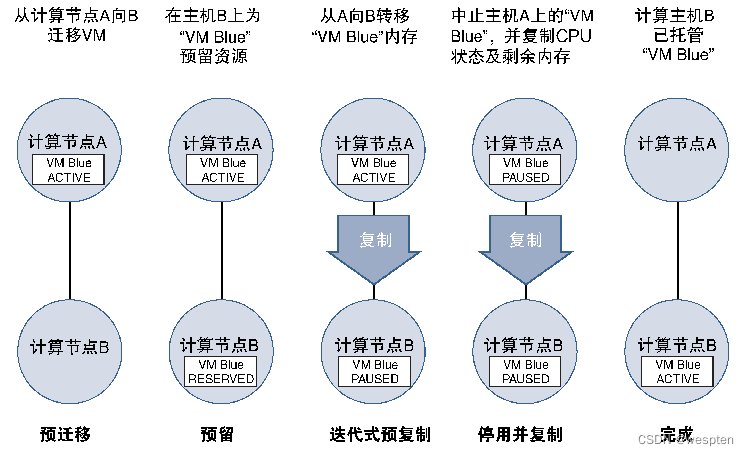
在OpenStack部署的云中,使用OpenStack提供的实时迁移功能,可以在不影响客户的情况下实现VNF的移动性。
为了实现无缝实时迁移,需要在云的初始部署阶段考虑如下设计要求。
- VNF应使用共享存储;
- 应在有效节点和迁移节点上使用相同类型的Hypervisor软件;
- 应在实时迁移期间考虑网络带宽及时延;
下图给出了实时迁移的进程信息:
五、OpenStack 部署管理
OpenStack部署节点都需要OpenStack的部分相关模块。
下图从全局角度展示了这些模块信息,可以看出这些模块都具有客户端—服务器模型。

控制器节点是中心控制模块,客户端仅在提供相关虚拟化资源的节点上运行。
例如,虽然存储节点只需要运行Cinder客户端模块(Cinder-Agent),但是作为Cinder中心节点的Cinder API需要运行在OpenStack控制器节点上。
某些组件(如Keystone、Horizon或Heat)仅属于控制器节点,如果出于某种原因,控制器节点与其他节点之间的管理网络的连接出现故障,那么该节点就无法提供功能,因为该节点需要其模块的服务器端部分以及通过管理网络连接的其他基本服务(如Keystone)。
1、部署OpenStack
如前所述,使用OpenStack、vCenter以及其他COS(Cloud Operating System,云操作系统)等软件工具的目的是简化和自动化云应用程序的部署与管理操作,但是必须部署和安装COS。
OpenStack因其开放性、模块化以及快速迭代等特性,使得其部署过程显得尤为复杂,由于OpenStack由社区提供技术支持(免费版本),因而其部署过程较为困难。
绝大多数常见的Linux系统(如CentOS、Ubuntu、Red Hat、SUSE以及Debian)都支持OpenStack,可以提供多种定制版本和付费版本的OpenStack,提供的服务主要集中在为公有云或私有云的定制化OpenStack基础设施提供部署、支持以及管理服务,常见的有Red Hat的Red Hat OpenStack、SUSE的SUSE Cloud、Cisco的Meta-Pod以及Ubuntu的Ubuntu OpenStack。
为了让大家对常见工具有一个基本了解,这里做简单的介绍。
1. Devstack
Devstack适用于非生产或开发目的的OpenStack安装,主要采用脚本方式安装OpenStack,经过优化之后可以快速创建用于开发、测试以及演示的OpenStack环境。
可以在支持Devstack的操作系统上安装Devstack,然后从代码存储库中提取稳定的OpenStack存储库。还有一些预置映射可以使用,这些镜像中内置了Devstack,安装之后可以将OpenStack安装在其上。Devstack的启动非常简单,只要下载Devstack并运行Shell脚本即可。
DevStack安装过程:
[root@localhost ~]# git clone
https://git.openstack.org/openstack-dev/devstack
[root@localhost ~]# cd devstack;./stack.sh
<snip>
2. Packstack
Packstack是一款可以实现OpenStack自动部署的实用工具,它利用Puppet(一种配置管理工具)来编排OpenStack的部署操作。Puppet是一款专用于配置管理操作的开源软件,它通过自己的描述语言来编写逻辑,相应的语言文件称为Puppet-Manifest,这些文件决定了其正在管理的服务器(或虚拟机)的配置要求。
安装Packstack的时候,必须先将其作为软件包添加到Linux环境中,然后再启动以确定所需的OpenStack安装类型以及需要安装哪些组件。Packstack可以根据交互式问答(或基于命令行参数)创建一个问答文件,安装脚本则利用该文件来完成OpenStack的安装过程,也可以使用all-in-one选项来安装Packstack。
[root@localhost ~]# packstack --all-in-one
Welcome to the Packstack setup utility
The installation log file is available at
/var/tmp/packstack/20160407-183305-c2bBs5/openstack-setup.log
Installing
Clean Up [ DONE]
Setting up ssh keys [ DONE]
<snip>
**** Installation completed successfully ******
Additional information:
<snip>
3. Ubuntu OpenStack安装程序
Canonical(提供Ubuntu开源Linux的公司)和Ubuntu为OpenStack云环境提供安装程序,Canonical Autopilot支持构建私有云,其他Ubuntu安装程序则支持单节点和多节点安装,这些安装程序可以使用Juju和MAAS(Metal as a Service,裸机即服务)等Ubuntu工具来执行OpenStack的部署操作。
Juju是一款由Canonical(Ubuntu)开发的用于编排及自动化安装的实用工具,Juju并非专用于OpenStack,它可以为云环境部署任意服务。Juju的编排逻辑由Juju-Charm定义,可以利用为OpenStack定义的Juju-Charm来编排OpenStack的部署操作。
MAAS是Metal as a Service(裸机即服务)的缩写,由Canonical/Ubuntu提供的MAAS是一款配置和部署裸机服务器(云的一部分)的工具。MAAS识别出服务器或虚拟机之后,就可以启动它们、验证其硬件并在这些服务器或虚拟机上部署软件。MAAS利用Juju在系统上执行软件配置操作。对对于Juju来说,该服务器可能是一台虚拟机(MAAS已经处理了物理设备),因而Juju完全可以根据指示执行部署操作。
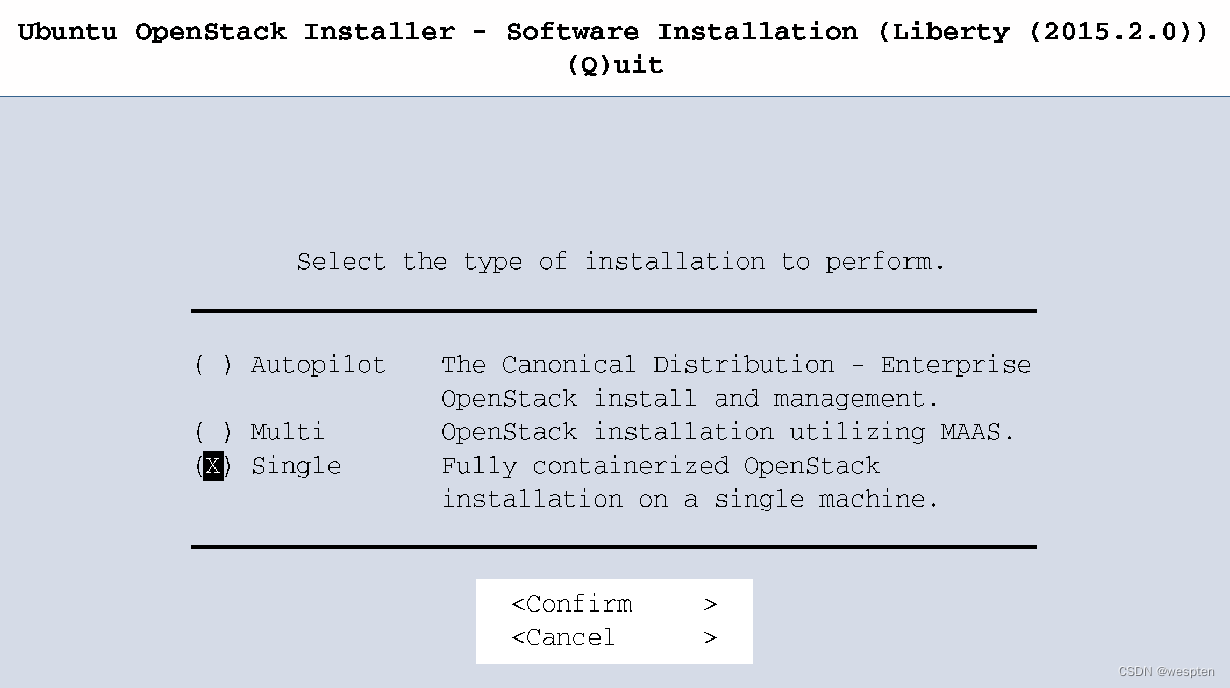
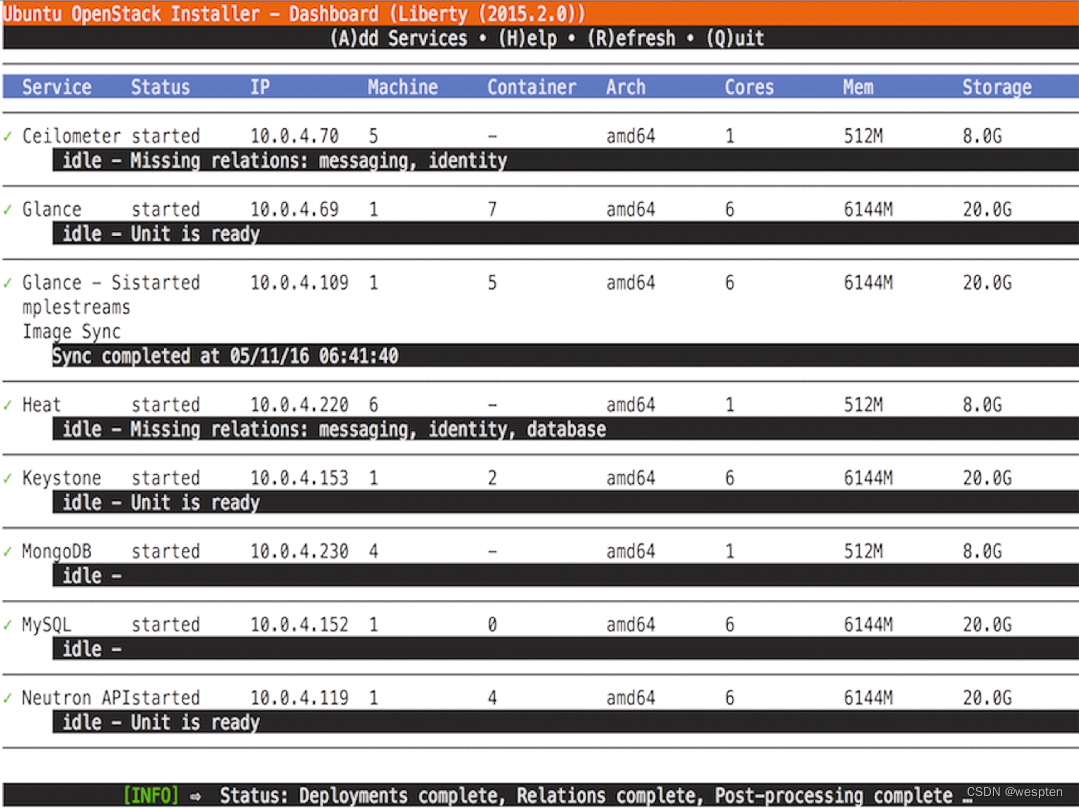
简单而言,Ubuntu的OpenStack安装程序可以在单台计算机上安装OpenStack,拥有简单易行的CLI部署步骤以及可用于更新和管理OpenStack环境的图形用户界面。
下图显示了可以选择安装类型的简单GUI:
安装完成之后,就可以利用下图所示的GUI来轻松管理OpenStack。
4. Fuel
Fuel由Mirantis提供,是一款可以部署OpenStack的开源工具。Fuel提供了交互式GUI,可以确定应该安装哪些组件和模块以及将这些组件和模块安装在什么位置。
2、将OpenStack用作VIM
前面讲到了利用OpenStack Horizon仪表盘GUI为虚拟环境配置网络时所需的配置步骤,为了更好地了解使用OpenStack部署VNF的整体情况,这里解释OpenStack作为VIM时所提供的基本监控功能,同时还将详细介绍利用之前部署的网段构建VNF所需的步骤。
需要强调的是,如果使用了脚本和自动化工具,或者其他功能模块正在实例化VNF,那么就会通过直接调用API打开源端模块,或者通过CLI执行以下操作。
第1步:登录Horizon之后,用户可以看到计算节点的利用率信息,如下图所示。

这是因为OpenStack计算节点正在管理NFVI所使用的硬件(控制器节点资源并不用于VNF的资源分配)。
第2步:对于要实例化的VNF来说,需要将其呈现为镜像。具体的文件格式可以是QCOW2、VMDK等(用于打包虚拟机)或Docker镜像(用于容器),也可以是作为虚拟机镜像(用于启动虚拟机)的只读ISO文件,如下图所示。

第3步(可选):作为可选项,用户还可以在同一个界面上定义需要给虚拟机分配的最小磁盘容量以及内存大小(如果要使用该镜像),从而确保实例化该VNF时不会出现分配的资源量不足,进而导致性能下降或者不稳定。
下图给出了设置这些资源下限的菜单选项信息,同时还给出了加载镜像文件时的两个选项,镜像文件可以位于任何可达的URL地址,也可以位于本地机器中。
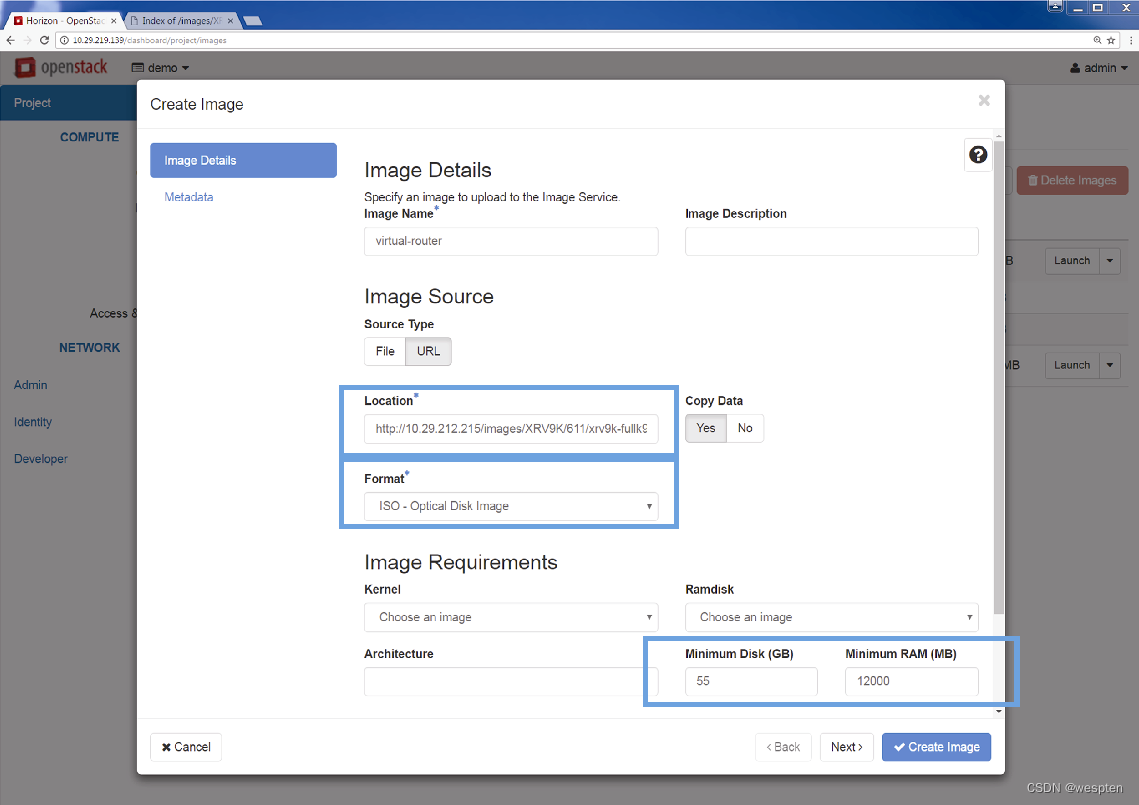
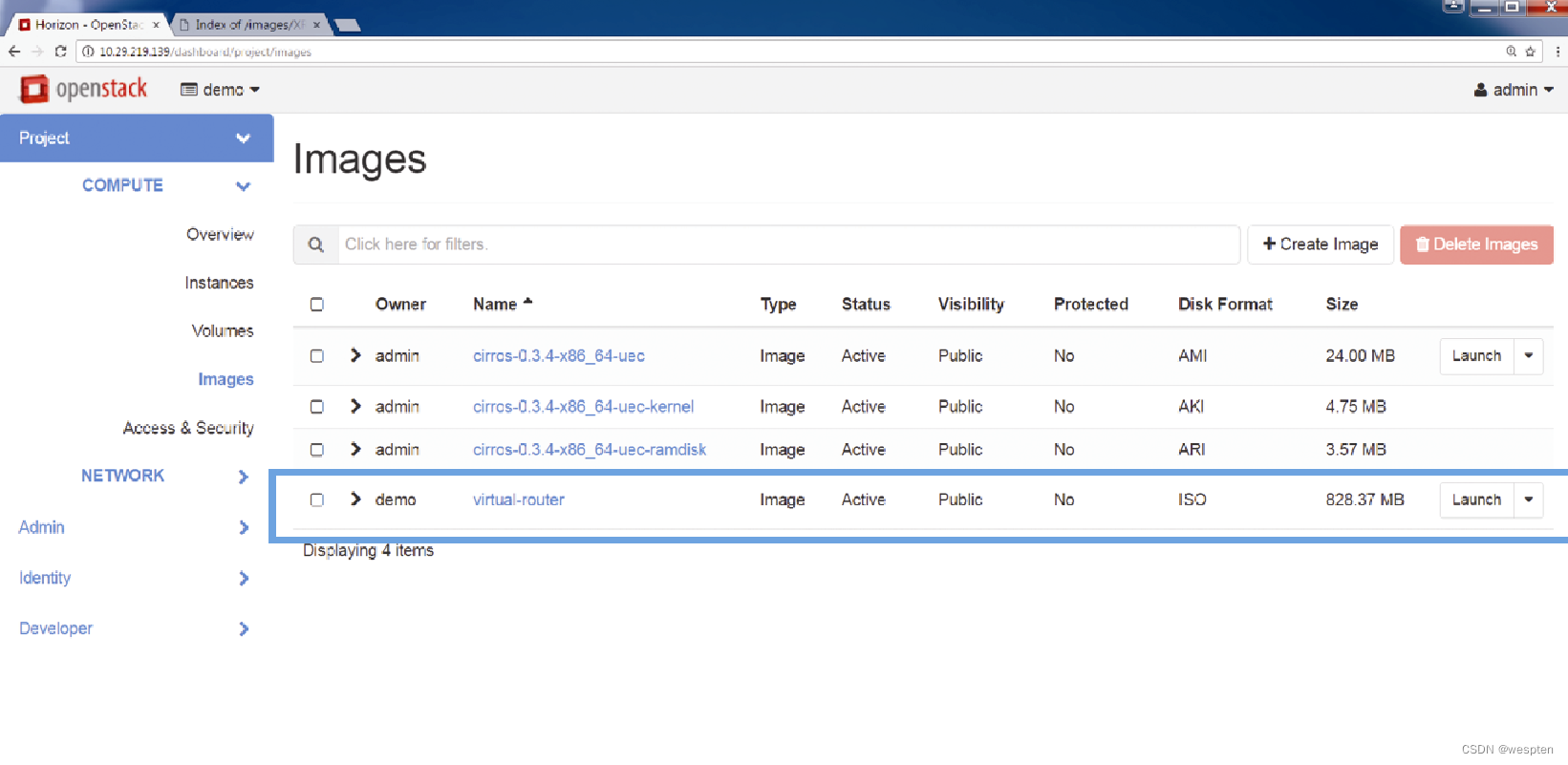
提供了该文件信息之后,OpenStack就可以将这些信息录入Glance数据库并将镜像存储在OpenStack的存储库中。
此后就可以利用Image(镜像)选项卡查看Glance数据库,如下图所示。
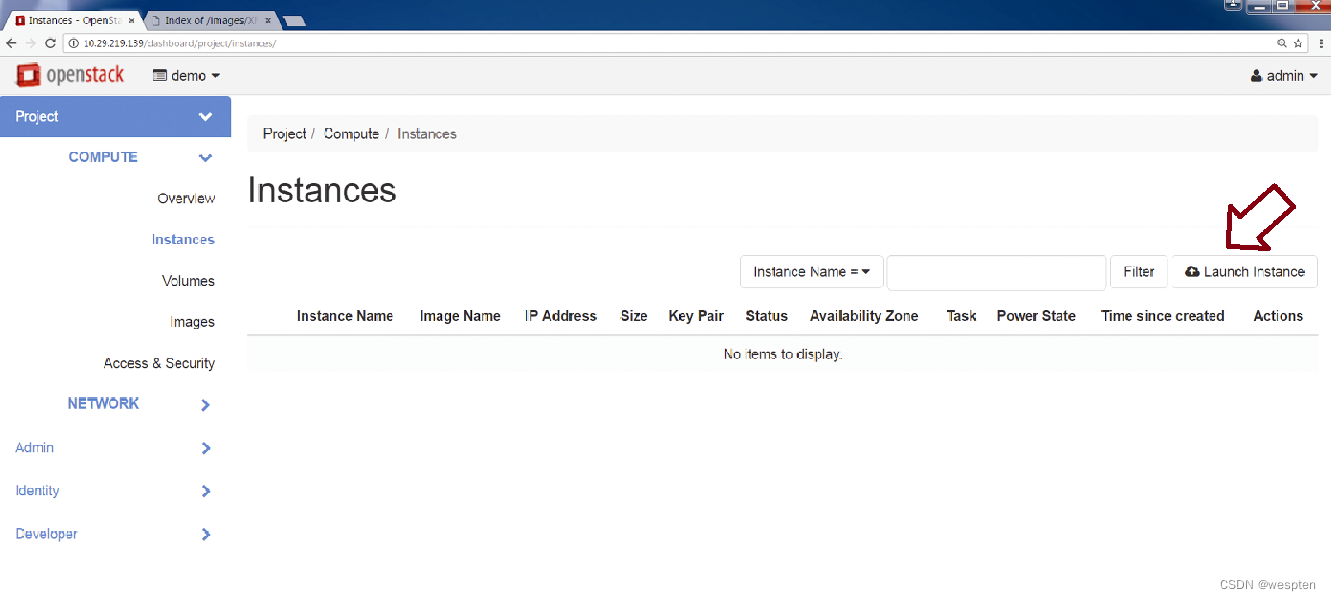
第4步(可选):可以利用Instance(实例)选项卡启动实例,如下图所示。
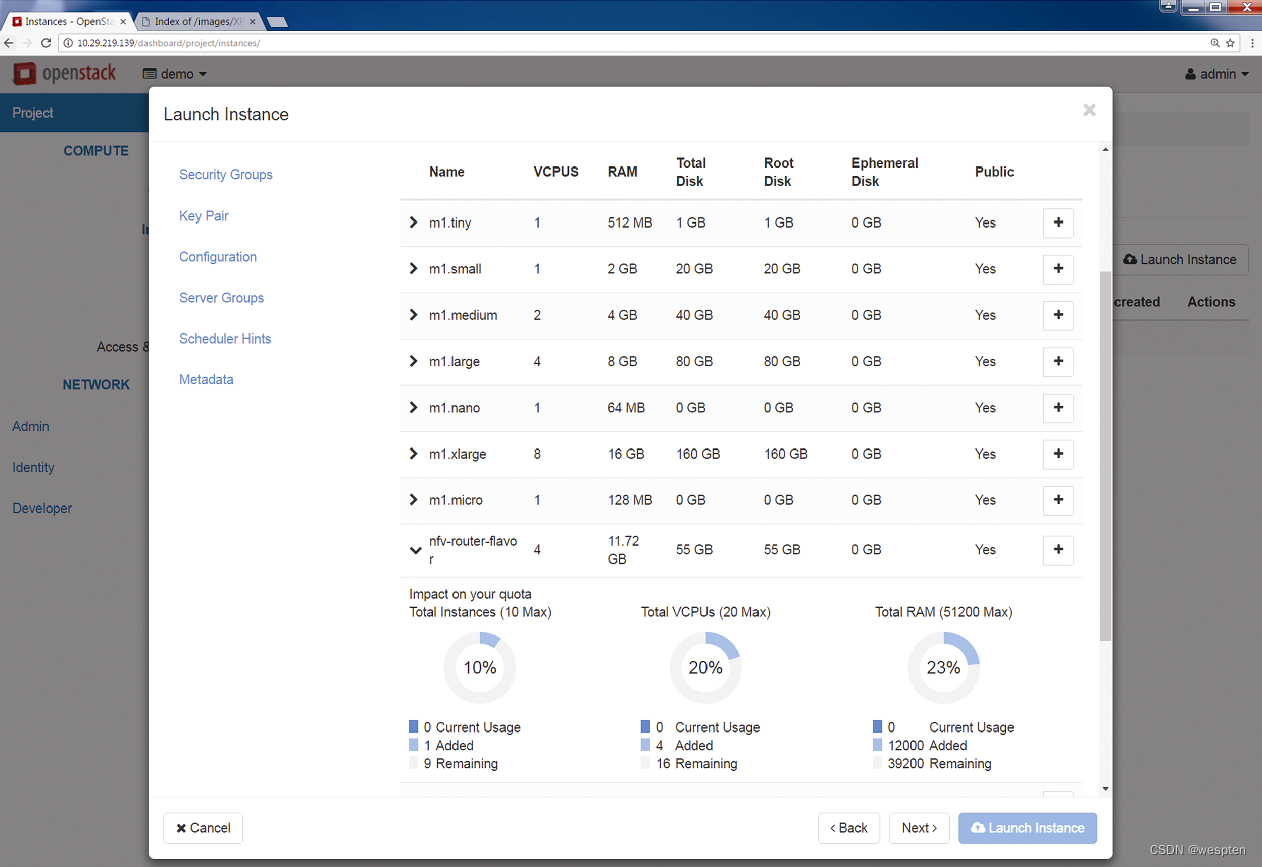
第5步:VNF可以使用预定义模板,这些预定义模板由OpenStack管理员定义,提供了计算、内存以及存储空间资源的容量选项。如果管理员已经为镜像文件配置了最低的磁盘和内存要求,那么选定的模板就必须满足这些最低要求。
下图显示了实例化VNF时所选择的模板以及最终分配的VCPU(Virtual CPU,虚拟CPU)、Root Disk(根磁盘)以及Ephemeral Disk(临时磁盘)等信息。
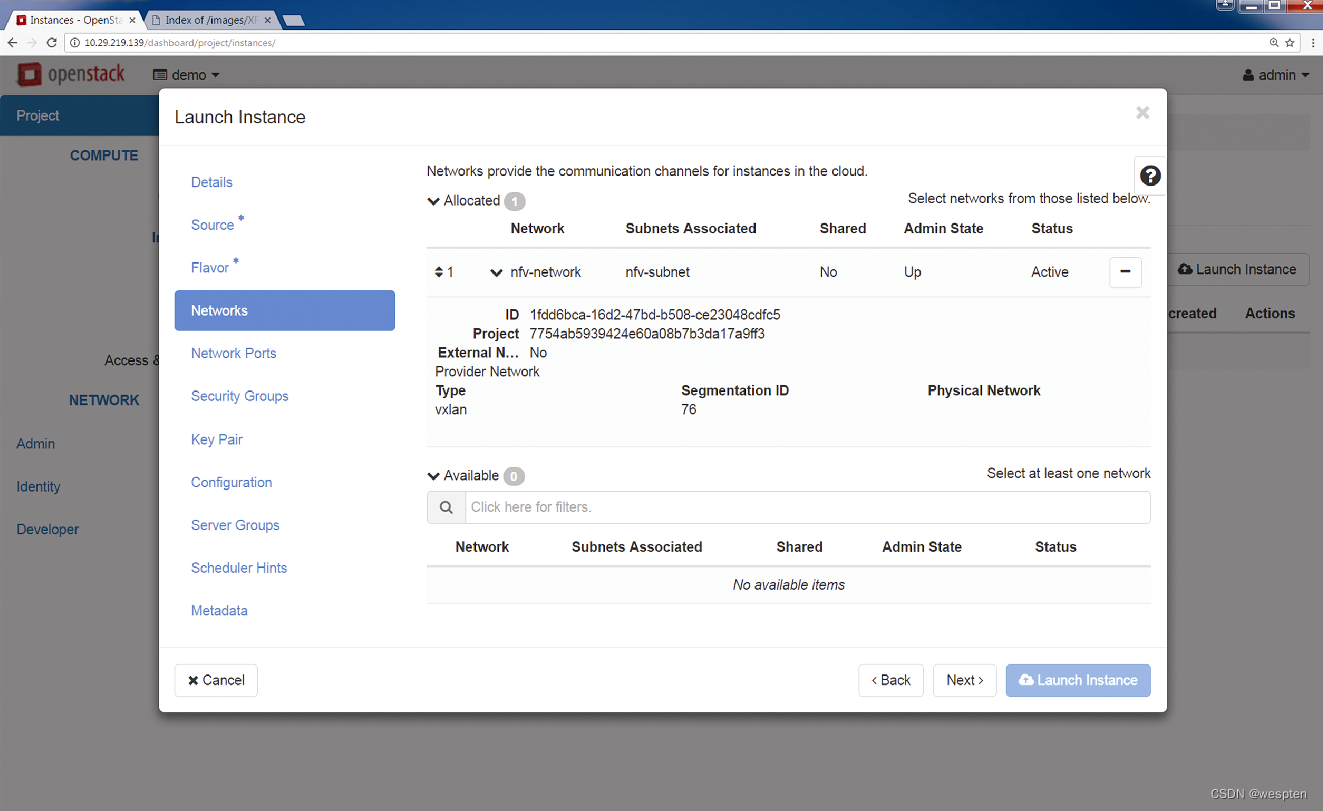
第6步:所有已创建的VNF都应该有去往其他VNF或外部网络的连接,因而与网段建立关联是VNF实例化进程的一部分,用户可以将VNF与已有网段(属于该用户的网段或者该用户共享的网段)相关联。
从下图可以看出,前面创建的网络“nfv-network”可用,VNF与该网络建立了关联关系。
第7步:最后需要定义的就是VNF的启动镜像,该镜像就是之前上传的镜像,如下图所示。
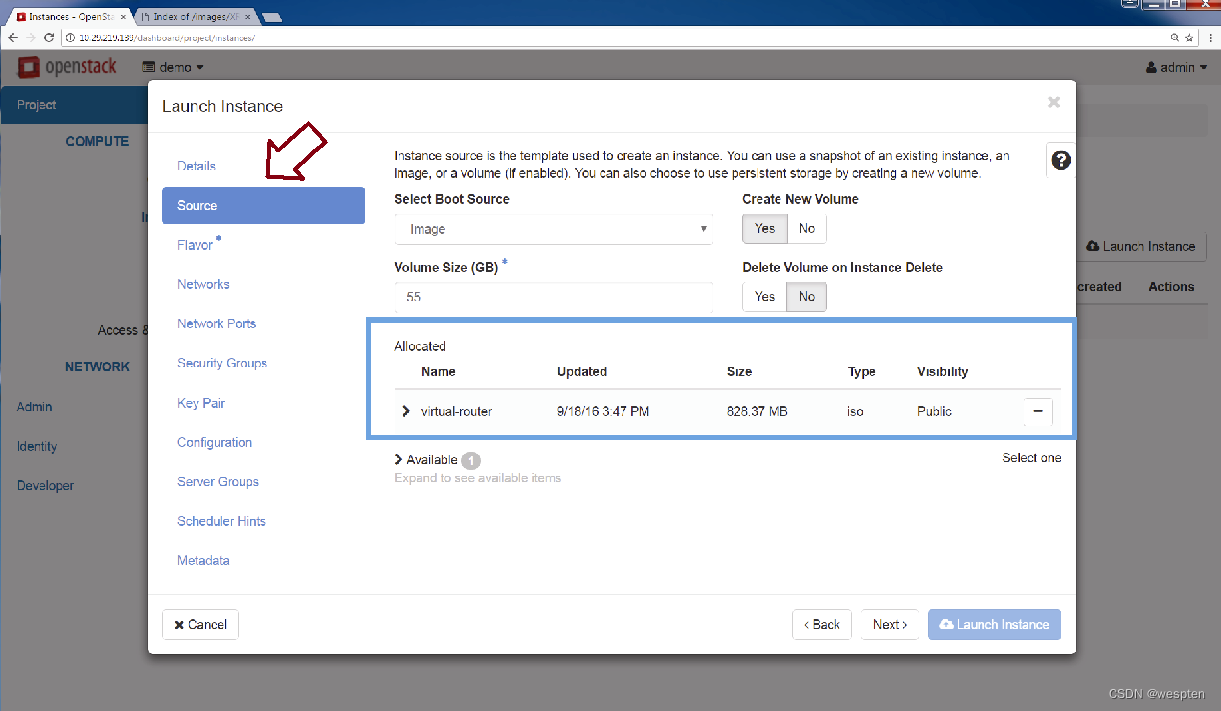
作为可选方式,VNF也可以从已保存的快照中启动,此时可以验证所有的资源参数,然后再启动镜像。
此时可以从Instance(实例)选项卡查看刚刚启动的VNF的状态,如下图所示。

可以看出该镜像已经成功启动并处于运行状态。
新创建的VNF实例与网络“nfv-network”相关联之后,Neutron就可以创建端口并在其GUI中显示该关联关系,如下图所示。

新启动的实例已经连接到网络上了。