基本语法
static、final、java内部类、transient、volatile关键字的作用,foreach循环的原理
①static表示“全局”或者“静态”的意思,用来修饰成员变量和成员方法,也可以形成静态static代码块,甚至静态导包(静态导包就是java包的静态导入,用import static代替import静态导入包是JDK1.5中的新特性)。 被static修饰的成员变量和成员方法独立于该类的任何对象。也就是说,它不依赖类特定的实例,被类的所有实例共享。只要这个类被加载,Java虚拟机就能根据类名在运行时数据区的方法区内定找到他们。因此,static对象可以在它的任何对象创建之前访问,无需引用任何对象。
②final关键字可以用来修饰类、方法和变量(包括成员变量和局部变量)。注意final类中的所有成员方法都会被隐式地指定为final方法。类的private方法会隐式地被指定为final方法。对于一个final变量,如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;如果是引用类型的变量,则在对其初始化之后便不能再让其指向另一个对象。
关于final的一个例子:
public class Test {
public static void main(String[] args) {
String a = "hello2";
final String b = "hello";
String d = "hello";
String c = b + 2;
String e = d + 2;
System.out.println((a == c));
System.out.println((a == e));
}
}
True
false解释:当final变量是基本数据类型以及String类型时,如果在编译期间能知道它的确切值,则编译器会把它当做编译期常量使用。也就是说在用到该final变量的地方,相当于直接访问的这个常量,不需要在运行时确定。因此在上面的一段代码中,由于变量b被final修饰,因此会被当做编译器常量,所以在使用到b的地方会直接将变量b 替换为它的值。而对于变量d的访问却需要在运行时通过链接来进行。
final和static的区别:static作用于成员变量用来表示只保存一份副本,而final的作用是用来保证变量不可变。
局部内部类和匿名内部类只能访问局部final变量:局部变量的值在编译期间就可以确定,则直接在匿名内部里面创建一个拷贝。如果局部变量的值无法在编译期间确定,则通过构造器传参的方式来对拷贝进行初始化赋值。java编译器就限定必须将变量限制为final变量,不允许对变量进行更改(对于引用类型的变量,是不允许指向新的对象),这样数据不一致性的问题就得以解决了。
③Java内部类:内部类的存在使得Java的多继承机制变得更加完善
- 成员内部类:成员内部类拥有和外部类同名的成员变量或者方法时,会发生隐藏现象,即默认情况下访问的是成员内部类的成员。内部类可以拥有private访问权限、protected访问权限、public访问权限及包访问权限。这一点和外部类有一点不一样,外部类只能被public和包访问两种权限修饰。要创建成员内部类的对象,前提是必须存在一个外部类的对象。创建成员内部类对象的一般方式如下:
//第一种方式:
Outter outter = new Outter();
Outter.Inner inner = outter.new Inner(); //必须通过Outter对象来创建
//第二种方式:
Outter.Inner inner1 = outter.getInnerInstance();
-
局部内部类:局部内部类就像是方法里面的一个局部变量一样,是不能有public、protected、private以及static修饰符的。
-
匿名内部类:使用匿名内部类能够在实现父类或者接口中的方法情况下同时产生一个相应的对象,但是前提是这个父类或者接口必须先存在才能这样使用。
扫描二维码关注公众号,回复: 4726479 查看本文章
-
静态内部类:静态内部类是不需要依赖于外部类的
④transient
java中对象的序列化指的是将对象转换成以字节序列的形式来表示,这些字节序列包含了对象的数据和信息,一个序列化后的对象可以被写到数据库或文件中,也可用于网络传输。transient关键字的作用,简单地说,就是让某些被修饰的成员属性变量不被序列化,例如:HashMap源码有个字段modCount是用transient修饰的,modCount主要用于判断HashMap是否被修改(像put、remove操作的时候,modCount都会自增),对于这种变量,一开始可以为任何值,0当然也是可以,没必要持久化其值。
⑤volatile
可见性是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。Java提供了volatile关键字来保证可见性。当一个共享变量被volatile修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值。volatile关键字无法保证操作的原子性。volatile关键字和没有加入volatile关键字时所生成的汇编代码发现,加入volatile关键字时,会多出一个lock前缀指令。
⑥foreach
对Collection集合类的foreach遍历,foreach之所以能工作,是因为这些集合类都实现了Iterable接口,该接口中定义了Iterator迭代器的产生方法,并且foreach就是通过Iterable接口在序列中进行移动。
集合
List、Map、Set各种实现类的底层实现原理,实现类的优缺点
①ArrayList
ArrayList继承AbstractList 并且实现了List和RandomAccess,Cloneable, Serializable接口,默认情况下使用ArrayList会生成一个大小为10的Object类型的数组。
添加元素比较复杂,涉及到扩充数组容量的问题。如果加入元素后数组大小不够会先进行扩容,每次扩容都将数组大小增大一半比如数组大小为10一次扩容后的大小为10+5=15;ArrayList的最大长度为 2^32
public boolean add(E e) {
ensureCapacityInternal(size + 1); // 加入元素前检查数组的容量是否足够
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
modCount++;
// 如果添加元素后大于当前数组的长度,则进行扩容
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}//3-----------------------
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
//将数组的长度增加原来数组的一半。
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
//如果扩充一半后仍然不够,则 newCapacity = minCapacity;minCapacity实际元素的个数。
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
//数组最大位2^32
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
} ②LinkedList(基于jdk 1.8实现了List接口和Deque接口的双端链表)
Node节点的定义,Node类LinkedList的静态内部类
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}添加操作
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;//指向链表尾部
final Node<E> newNode = new Node<>(l, e, null);//以尾部为前驱节点创建一个新节点
last = newNode;//将链表尾部指向新节点
if (l == null)//如果链表为空,那么该节点既是头节点也是尾节点
first = newNode;
else//链表不为空,那么将该结点作为原链表尾部的后继节点
l.next = newNode;
size++;//增加尺寸
modCount++;
}获得头节点数据
- getFirst()和element()方法在链表为空时会抛出NoSuchElementException
- peek()和peekFirst()方法在链表为空时会返回null
- 获得尾节点数据
- getLast()在链表为空时会抛出NoSuchElementException
- peekLast()在链表为空时会返回null
③queue
-
ConcurrentLinkedQueue:是一个适用于高并发场景下的队列,通过无锁的方式,实现了高并发状态下的高性能,通常ConcurrentLinkedQueue性能好于BlockingQueueo它是一个基于链接节点的无界线程安全队列。该队列的元素遵循先讲先出的原则。头是最先加入的,尾是最近加入的,该队列不允许null元素。
-
ArrayBlockingQueue:基于数组的阻塞队列实现,在ArrayBlockingQueue内部,维护了一个定长数组,以便缓存队列中的数据对象,其内部没实现读写分离,也就意味着生产和消费不能完全并行,长度是需要定义的,可以指定先讲先出或者先讲后出,也叫有界队列,在很多场合非常适合使用。
-
LinkedBlockingQueue:基于链表的阻塞队列,同ArrayBlockingQueue类似,其内部也维持着一个数据缓冲队列〈该队列由一个链表构成),LinkedBlockingQueue之所以能够高效的处理并发数据,是因为其内部实现采用分离锁(读写分离两个锁),从而实现生产者和消费者操作的完全并行运行,他是一个无界队列。
-
SynchronousQueue:一种没有缓冲的队列,生产者产生的数据直接会被消费者获取并消费。
-
PriorityBlockingQueue:基于优先级的阻塞队列(优先级的判断通过构造函数传入的Compator对象来决定,也就是说传入队列的对象必须实现Comparable接口),在实现PriorityBlockingQueue时,内部控制线程同步的锁采用的是公平锁,他也是一个无界的队列。
-
DelayQueue:带有延迟时间的Queue,其中的元素只有当其指定的延迟时间到了,才能够从队列中获取到该元素。DelayQueue中的元素必须实现Delayed接口,DelayQueue是一个没有大小限制的队列,应用场景很多,比如对缓存超时的数据进行移除、任务超时处理、空闲连接的关闭。
④TreeMap
TreeMap 是一个有序的key-value集合,它是通过红黑树实现的。
TreeMap 继承于AbstractMap,所以它是一个Map,即一个key-value集合。
TreeMap 实现了NavigableMap接口,意味着它支持一系列的导航方法。比如返回有序的key集合。
TreeMap 实现了Cloneable接口,意味着它能被克隆。
TreeMap 实现了java.io.Serializable接口,意味着它支持序列化。
TreeMap基于红黑树(Red-Black tree)实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。
TreeMap的基本操作 containsKey、get、put 和 remove 的时间复杂度是 log(n) 。
另外,TreeMap是非同步的。 它的iterator 方法返回的迭代器是fail-fast的。
红黑树的特性:
(1)每个节点或者是黑色,或者是红色。
(2)根节点是黑色。
(3)每个叶子节点(NIL)是黑色。 [注意:这里叶子节点,是指为空(NIL或NULL)的叶子节点!]
(4)如果一个节点是红色的,则它的子节点必须是黑色的。
(5)从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。
常见问题
为什么wait()和notify()属于Object类
wait()暂停的是持有锁的对象,所以想调用wait()必须为:对象.wait();
notify()唤醒的是等待锁的对象,调用:对象.notify();注意:wait(),notify(),notifyAll()都必须使用在同步中,因为要对持有监视器(锁)的线程操作。所以要使用在同步中,因为只有同步才具有锁。
多线程下HashMap的死循环问题
在put操作的时候,如果size>initialCapacity*loadFactor,那么这时候HashMap就会进行rehash操作,随之HashMap的结构就会发生翻天覆地的变化。很有可能就是在两个线程在这个时候同时触发了rehash操作,产生了闭合的回路。
参考链接:https://www.cnblogs.com/dongguacai/p/5599100.html
ConcurrentHashMap 的工作原理及代码实现,如何统计所有的元素个数
数据结构
jdk1.7中采用Segment + HashEntry的方式进行实现
先采用不加锁的方式,连续计算元素的个数,最多计算3次:
1、如果前后两次计算结果相同,则说明计算出来的元素个数是准确的;
2、如果前后两次计算结果都不同,则给每个Segment进行加锁,再计算一次元素的个数
jdk1.8中放弃了Segment臃肿的设计,取而代之的是采用Node + CAS + Synchronized来保证并发安全进行实现
元素个数保存baseCount中,部分元素的变化个数保存在CounterCell数组中,累加即可
Spring AOP的实现原理
Spring AOP中的动态代理主要有两种方式,JDK动态代理和CGLIB动态代理。JDK动态代理通过反射来接收被代理的类,并且要求被代理的类必须实现一个接口。JDK动态代理的核心是InvocationHandler接口和Proxy类。
如果目标类没有实现接口,那么Spring AOP会选择使用CGLIB来动态代理目标类。CGLIB(Code Generation Library),是一个代码生成的类库,可以在运行时动态的生成某个类的子类,注意,CGLIB是通过继承的方式做的动态代理,因此如果某个类被标记为final,那么它是无法使用CGLIB做动态代理的。
Spring之BeanFactory和bean的生命周期
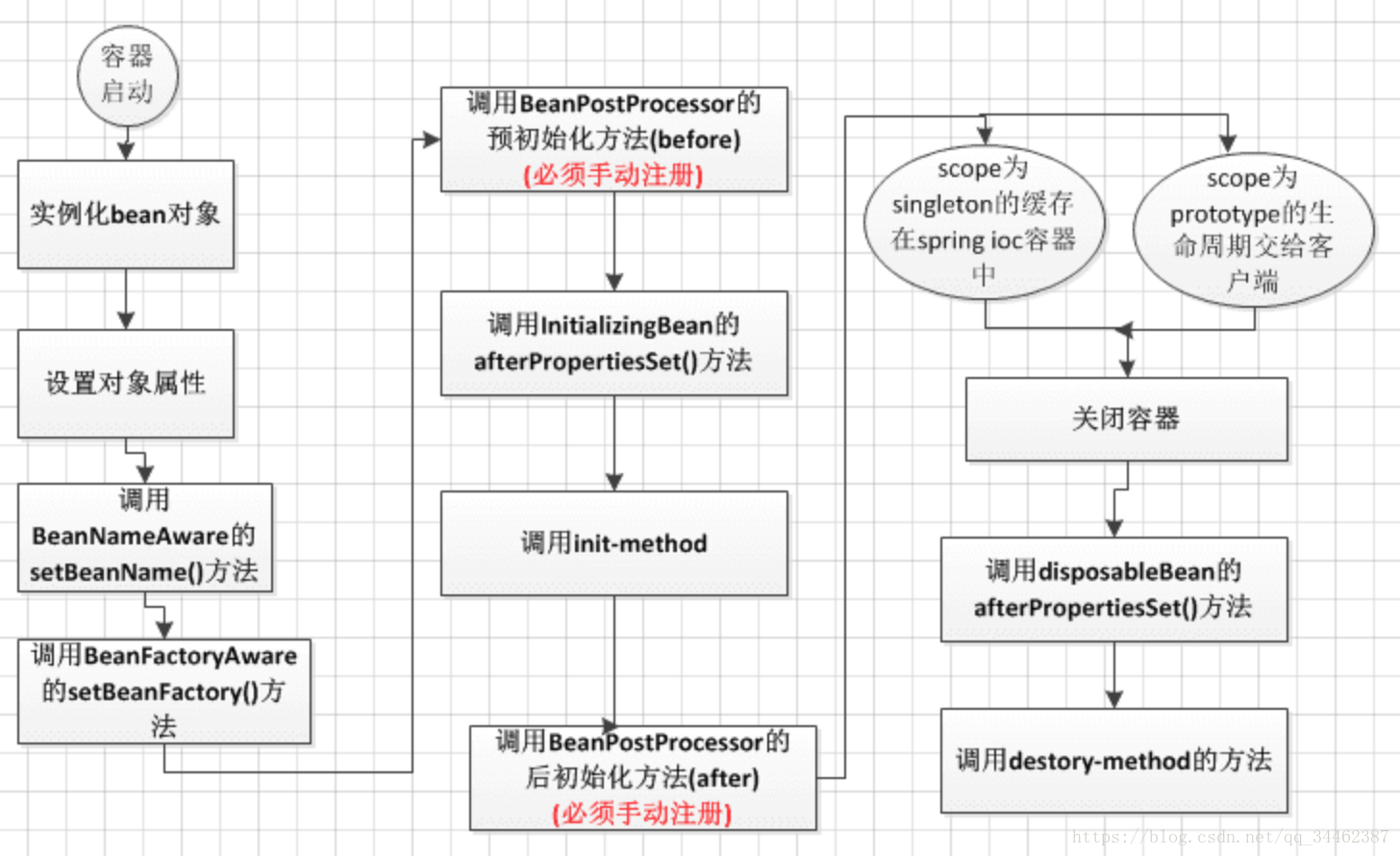
容器在内部实现的时候,采用“策略模式”来决定采用何种方式初始化bean实例。通常,可以通过反射或者CGLIB动态字节码生成来初始化相应的bean实例或者动态生成其子类。默认情况下,容器内部采用CglibSubclassingInstantiationStartegy。
BeanFactoty容器中, Bean的生命周期如上图所示,与ApplicationContext相比,有如下几点不同:
1. BeanFactory容器中,不会调用ApplicationContextAware接口的setApplicationContext()方法
2. BeanPostProcessor接口的postProcessBeforeInitialization方法和postProcessAfterInitialization方法不会自动调用,必须自己通过代码手动注册
3. BeanFactory容器启动的时候,不会去实例化所有bean,包括所有scope为singleton且非延迟加载的bean也是一样,而是在调用的时候去实例化。
线程是一个动态执行的过程,它也有一个从产生到死亡的过程。
(1)生命周期的五种状态
- 新建(new Thread)
当创建Thread类的一个实例(对象)时,此线程进入新建状态(未被启动)。
例如:Thread t1=new Thread();
- 就绪(runnable)
线程已经被启动,正在等待被分配给CPU时间片,也就是说此时线程正在就绪队列中排队等候得到CPU资源。例如:t1.start();
- 运行(running)
线程获得CPU资源正在执行任务(run()方法),此时除非此线程自动放弃CPU资源或者有优先级更高的线程进入,线程将一直运行到结束。
- 死亡(dead)
当线程执行完毕或被其它线程杀死,线程就进入死亡状态,这时线程不可能再进入就绪状态等待执行。
自然终止:正常运行run()方法后终止
异常终止:调用stop()方法让一个线程终止运行
- 堵塞(blocked)
由于某种原因导致正在运行的线程让出CPU并暂停自己的执行,即进入堵塞状态。
正在睡眠:用sleep(long t) 方法可使线程进入睡眠方式。一个睡眠着的线程在指定的时间过去可进入就绪状态。
正在等待:调用wait()方法。(调用notify()方法回到就绪状态)
被另一个线程所阻塞:调用suspend()方法。(调用resume()方法恢复)
Java中线程池的实现原理
线程池中的核心线程数,当提交一个任务时,线程池创建一个新线程执行任务,直到当前线程数等于corePoolSize;如果当前线程数为corePoolSize,继续提交的任务被保存到阻塞队列中,等待被执行;如果阻塞队列满了,那就创建新的线程执行当前任务;直到线程池中的线程数达到maxPoolSize,这时再有任务来,只能执行reject()处理该任务;
Java线程池的工厂类:Executors类,
初始化4种类型的线程池:
- newFixedThreadPool()
说明:初始化一个指定线程数的线程池,其中corePoolSize == maxPoolSize,使用LinkedBlockingQuene作为阻塞队列
特点:即使当线程池没有可执行任务时,也不会释放线程。
- newCachedThreadPool()
说明:初始化一个可以缓存线程的线程池,默认缓存60s,线程池的线程数可达到Integer.MAX_VALUE,即2147483647,内部使用SynchronousQueue作为阻塞队列;
特点:在没有任务执行时,当线程的空闲时间超过keepAliveTime,会自动释放线程资源;当提交新任务时,如果没有空闲线程,则创建新线程执行任务,会导致一定的系统开销;
因此,使用时要注意控制并发的任务数,防止因创建大量的线程导致而降低性能。
- newSingleThreadExecutor()
说明:初始化只有一个线程的线程池,内部使用LinkedBlockingQueue作为阻塞队列。
特点:如果该线程异常结束,会重新创建一个新的线程继续执行任务,唯一的线程可以保证所提交任务的顺序执行
- newScheduledThreadPool()
特定:初始化的线程池可以在指定的时间内周期性的执行所提交的任务,在实际的业务场景中可以使用该线程池定期的同步数据。
所谓重入锁,指的是以线程为单位,当一个线程获取对象锁之后,这个线程可以再次获取本对象上的锁,而其他的线程是不可以的
synchronized 和 ReentrantLock 都是可重入锁
可重入锁的意义在于防止死锁
实现原理实现是通过为每个锁关联一个请求计数和一个占有它的线程。
当计数为0时,认为锁是未被占有的。线程请求一个未被占有的锁时,jvm讲记录锁的占有者,并且讲请求计数器置为1 。
如果同一个线程再次请求这个锁,计数将递增;
每次占用线程退出同步块,计数器值将递减。直到计数器为0,锁被释放。