np.random.rand()函数
语法:
np.random.rand(d0,d1,d2……dn)
注:使用方法与np.random.randn()函数相同
作用:
通过本函数可以返回一个或一组服从“0~1”均匀分布的随机样本值。随机样本取值范围是[0,1),不包括1。
应用:在深度学习的Dropout正则化方法中,可以用于生成dropout随机向量(dl),例如(keep_prob表示保留神经元的比例):dl = np.random.rand(al.shape[0],al.shape[1]) < keep_prob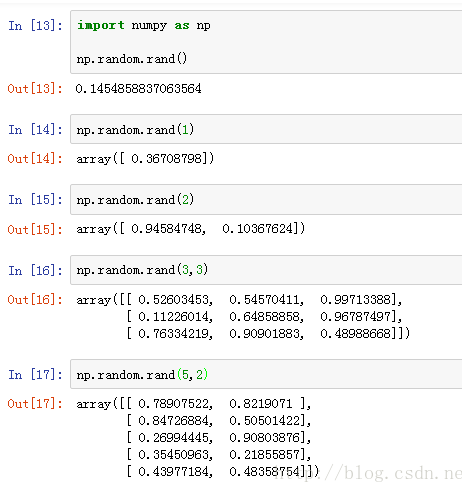
np.random.randn()函数
语法:
np.random.randn(d0,d1,d2……dn)
1) 当函数括号内没有参数时,则返回一个浮点数;
2)当函数括号内有一个参数时,则返回秩为1的数组,不能表示向量和矩阵;
3)当函数括号内有两个及以上参数时,则返回对应维度的数组,能表示向量或矩阵;
4)np.random.standard_normal()函数与np.random.randn()类似,但是np.random.standard_normal()
的输入参数为元组(tuple).
5)np.random.randn()的输入通常为整数,但是如果为浮点数,则会自动直接截断转换为整数。
作用:
通过本函数可以返回一个或一组服从标准正态分布的随机样本值。
特点:
标准正态分布是以0为均数、以1为标准差的正态分布,记为N(0,1)。对应的正态分布曲线如下所示,即
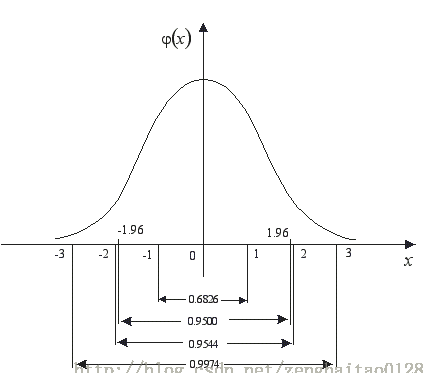
标准正态分布曲线下面积分布规律是:
在-1.96~+1.96范围内曲线下的面积等于0.9500(即取值在这个范围的概率为95%),在-2.58~+2.58范围内曲线下面积为0.9900(即取值在这个范围的概率为99%).
因此,由 np.random.randn()函数所产生的随机样本基本上取值主要在-1.96~+1.96之间,当然也不排除存在较大值的情形,只是概率较小而已。
用例:
