前言
在前端开发中,缓存有利于加快网页的加载速度,同时缓存能够被反复利用,所以可以减少流量和带宽的开销。
缓存的分类有很多种,CDN缓存、数据库缓存、代理服务器缓存和浏览器缓存。本篇将来讲解一下Web开发中的浏览器缓存。这个在实际开发环境中往往也会被问到,或者使用到。如何去准确认清楚缓存的概念,是前端必须要去学习的
浏览器的缓存问题,主要指的是http的缓存——即协议层。而h5新增的storage和数据库缓存,那是应用层缓存,并不被计入本篇的分析内容里面。下面我们正式开始来进行缓存的分析。
正文
有时当你使用chrome开发者工具的network发现了细节:

这是怎么一回事呢,当然这是上述说的缓存方式,虽然这两个看起来都是从缓存中读取,但还是有一些不一样的!
webkit资源的分类
webkit的资源分类主要分为两大类:主资源和派生资源。
http状态码
200 from memory cache //不访问服务器,直接读缓存,从内存中读取缓存。此时的数据时缓存到内存中的,当kill进程后,也就是浏览器关闭以后,数据将不存在。但是这种方式只能缓存派生资源。一般脚本、字体、图片会存在内存当中。 200 from disk cache //不访问服务器,直接读缓存,从磁盘中读取缓存,当kill进程时,数据还是存在。这种方式也只能缓存派生资源,一般是css
200 资源大小数值 //从服务器下载最新资源 304 Not Modified //访问服务器,发现数据没有更新,服务器返回此状态码(不返回资源)。然后从缓存中读取数据。
一般样式表会缓存在磁盘中,不会缓存到内存中,因为css样式加载一次即可渲染出页面。但是脚本可能会随时执行,如果把脚本存在磁盘中,在执行时会把该脚本从磁盘中提取到缓存中来,这样的IO开销比较大,有可能会导致浏览器失去响应。
几种状态的执行顺序
现加载一种资源(例如:图片):访问-> 200OK -> 退出浏览器 -> 再进来-> 200(from disk cache) -> 刷新 -> 200(from memory cache)
三级缓存原理
- 先去内存看,如果有,直接加载
- 如果内存没有,择取硬盘获取,如果有直接加载
- 如果硬盘也没有,那么就进行网络请求
- 加载到的资源缓存到硬盘和内存
首先什么是缓存吧
平时生活当中缓存一集电视剧,下载一首歌;这些资源是可以直接离线观看的,没有去请求网络,资源在本地。
浏览器中的缓存又是什么
如上所说,缓存即是离线的资源;对于浏览器开发者而言,缓存不是我们用浏览器下载了什么, 而是比如我们通过浏览器打开过一个网页,这个网页里面所包含的资源(图片、css文件、js文件等)在无感知的情况下,缓存在了本地;
浏览器缓存,有时候我们需要他,因为他可以提高网站性能和浏览器速度,提高网站性能。但是有时候我们又不得不清除缓存,因为缓存可能误事,出现一些错误的数据。像股票类网站实时更新等,这样的网站是不要缓存的,像有的网站很少更新,有缓存还是比较好的。
览器通常会将常用资源缓存在你的个人电脑的磁盘和内存中。如Chrome浏览器的缓存存放位置就在:\Users\Your_Account\AppData\Local\Google\Chrome\User Data\Default中的Cache文件夹和Media Cache文件夹中。
浏览器中缓存的步骤是什么样的
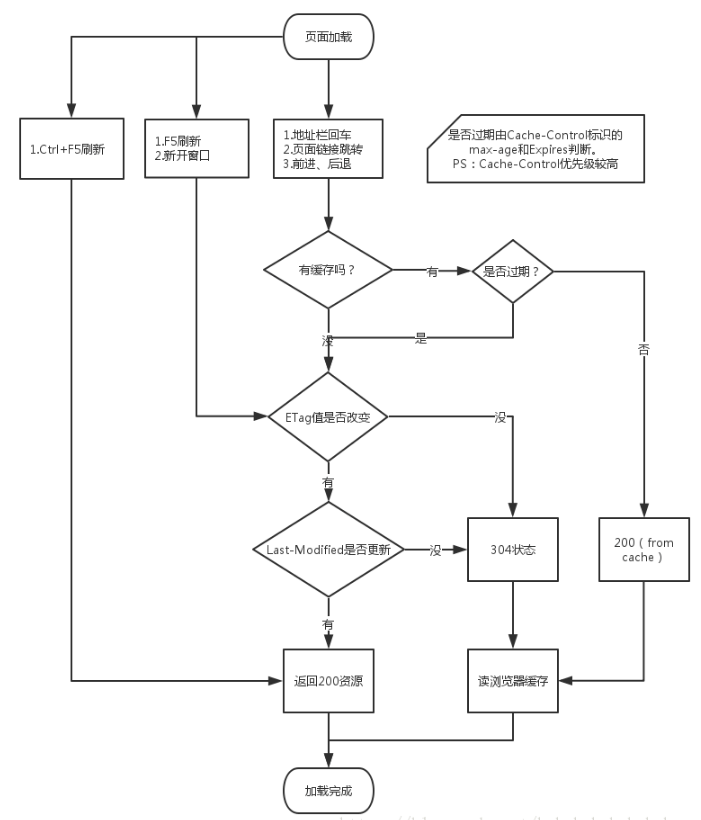
我们知道浏览器会有缓存,那么是我们每次去打开之前已经打开过的网站,都是用的缓存吗?当然不是!!!浏览器有一套协议来管理什么时候需要去请求服务器,什么时候使用本地缓存;这套协议就叫做缓存协议(缓存机制);
一起来看一下这套机制的流程是什么样的: