目录
4.使用Object.prototype.toString.call(value)
一.浏览器工作原理
具体流程:
1.浏览器首先使用HTTP协议或者HTTPS协议,向服务器请求页面
2.把请求回来的HTML代码经过解析,构建成DOM树
3.计算DOM树上的CSS属性
4.根据CSS属性对元素逐个进行渲染,得到内存中的位图
5.一个可选的步骤是对位图进行合成,这会极大增加后续绘制的速度;
6.合成之后,再绘制到界面上;
要更好的理解工作原理要理解以下几个问题:
1.什么是进程/线程?
进程是程序的一次执行,它占有一片独有的内存空间,各个进程的内存空间相互独立,彼此无法相互访问,是CPU的最小分配单元;
线程是进程内的独立的执行单元,一个进程内可以有多个线程,一个进程内的数据可以供其中的多个线程直接共享,在一个进程中,可能同时处理多个任务,每一个任务都是基于线程处理的,线程是程序执行的一个完整流程,是CPU的最小调度单元;
2.何为多进程/多线程?
多进程运行指一个应用程序可以同时启动多个实例运行;
多线程指一个进程内,同时有多个线程运行。
3.一个浏览器有哪些进程
浏览器包含:浏览器进程,网络进程,渲染进程,GPU进程,插件进程等;
几个进程之间用IPC协议进行通信,进程之间是相互隔离的,进程之间通信需要缓存区;
注意:浏览器也可以说是多线程的,但是渲染解析代码的只分配一个线程,所以前端代码渲染是单线程的。
4.渲染进程组成
即内核,一个tab页面对应一个渲染进程,js引擎工作在该进程上;
该进程包括:GUI渲染线程,JS引擎线程,事件触发线程,定时触发器线程,异步http请求线程。
第一步 URL地址解析
区别URL,URN,URI
URL:统一资源定位符,根据这个地址找到对应的资源;
URN:统一资源的名称,一般指国际上通用的一些名字(例如:国际统一发版的编号);
URI:统一资源标识符,URL和URN是URI的子集
一个完整的URL包含的内容
例如:https://www.bilibili.com:443/video/BV1rV411n2v?p=294&spm_id_from=333.1007#asaxf
- 协议:https:// 传输协议就是能把客户端和服务器端通信的信息,进行传输的工具
http - 超文本传输协议,除了超文本还可以传输媒体资源文件及XML格式数据
https - 更安全的http,一般涉及支付的网站都要采用https协议(s:ssl加密传输)
ftp - 文件传输协议(一般应用于将本地资源上传或下载到服务器端)
- 域名:www.bilibili.com
顶级域名 qq.com
一级域名 www.qq.com
二级域名 sports.qq.com
三级域名 kbs.sports.qq.com
- 端口号::443 端口号的取值范围(0-65535) ,用端口号来区分同一服务器上的不同项目
http默认端口号 80
https默认端口号443
ftp默认端口号 21
如果采用默认端口号,我们在书写的时候,不用加端口号,浏览器在发送请求的时候会帮我们默认加上
- 请求资源路径名称:/video/BV1rV411n2v 限定需要请求的资源文件的路径名称
默认的路径或名称,不指定资源名,服务器会找默认的资源,一般默认的资源名是index.html / default.html
注意伪url的处理,url的重写技术是为了增加SEO搜索引擎优化,动态网址一般不能被搜索引擎收录,所以我们要把动态的网址静态化,此时需要重写url,例如:
https://item.jd.hk/2688449.html => https://item/jd.hk/index.php?id=2688449
- 问号参数:?p=294&spm_id_from=333.1007
客户端想把信息传递给服务器
URL地址问号传参
请求报文传参(请求头和请求主体)
也可以实现多页面之间信息的交互
- hash值:#asaxf
充当信息传输方式(不是最常用)
描点定位
基于HASH实现路由管控,不同的hash值,展示不同的组件和模块
url特殊字符的编码
请求的地址栏中如果出现非有效的UNICODE编码(汉字,斜杠等),现代版浏览器会默认进行编码(encodeURI)
1.基于encodeURI编码,这样整个url中的有特殊字符会自动编译,我们可以基于decodeURI解码
2.使用encodeURIComponent/decodeURIComponent它相对于encodeURI来说,不用于整个URL进行编码,而是给URL部分信息进行编码,一般都是问号传参的值进行编码;
3.这两种方法是可用户端和服务端通用的方法,可以统一编解码;客户端还存在一种方式,针对中文编码escape、unescape,这种方式一般只是针对于客户端页面之间自己的处理
第二步 域名解析
DNS服务器:域名解析服务器,在服务器上存储着 域名 <=> 服务器的外网ip相关记录。
DNS解析:而我们发送请求时候所谓的DNS解析,其实就是根据域名,在DNS服务器上查找到对应服务器的外网IP
用户输入域名, 浏览器进程会开始导航,将URL请求发送给网络进程,开始真正的URL请求。域名解析方式有两种,递归查询和迭代查询,本地的dns解析是递归查询,dns服务器解析是迭代查询。
如果之前有解析过这个域名,就会在本地有缓存,合理利用这个缓存,也是网站优化的一个要点;本地dns解析的过程如下图,其中只要有一个环节获取到了域名的ip,域名解析就停止了
DNS缓存:一般浏览器会在第一次解析后,默认建立缓存,时间很短,只有一分钟左右

若没有本地的DNS服务器会向根DNS服务器请求 ,根DNS会告知顶级域名服务器的IP地址(顶级管理一级域名),顶级域又告知权威域名服务器的IP地址(管理二级域名),权威域名服务器告知请求的域名的IP地址。
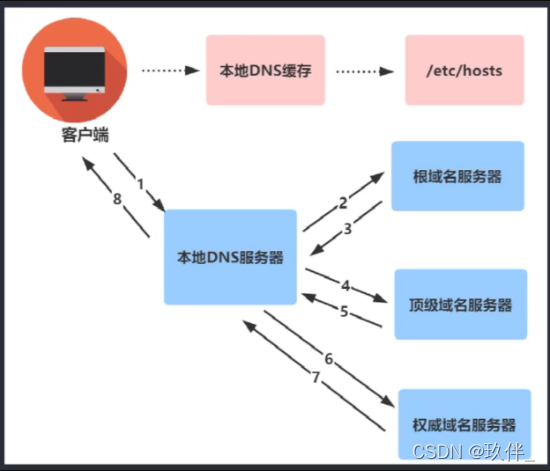
如果本地没有dns缓存,一次域名解析需要20-120ms;
性能优化:
1.减少dns请求,一个页面中尽量减少不同域名,资源都放在同一个服务器上;但是这种方式在项目中不推荐,往往会将资源分布到不同的服务器上,会对多个服务器的域名进行dns解析,但是这种方式能实现高可用,提高http的并发性,比如同一个源可以并发四个,如果有5个服务器集群,那么最多可以并发20个http请求。
2.dns预获取
接上,一个项目需要从不同服务器获取资源,从而需要解析那么多的域名
dns预获取就是在head标签中添加如下的link标签,href属性对应的就是项目需要解析的域名,这样在页面还没有加载dom结构的时候就将这些link请求发送,获取到的解析结果存放在本地,与此同时进行页面渲染,当渲染到图片等资源需要解析指定获取资源的服务器ip地址时,可以直接从本地获取就行了。

第三步 建立TCP链接
客户端和服务端的数据发送和返回依靠的就是TCP协议,建立了TCP连接后,浏览器就可以 构建请求行,请求头信息,向服务器发送请求数据;
2.1 TCP的三次握手
几个标志位
SYN:请求建立连接; 我们把携带SYN标识的称为同步报文段;
ACK:对数据进行确认.确认由目的端发出,用它来告诉发送端这个序列号之前的数据段都收到了;
RST:重置连接;
FIN:释放一个链接;
seq:序列号码,用来标识从TCP源端向目标端发送的字节流,发起方发送数据时对此进行标记;
ack:确认号码,只有ACK为1时,确认序号字段才有效,ack = seq + 1.
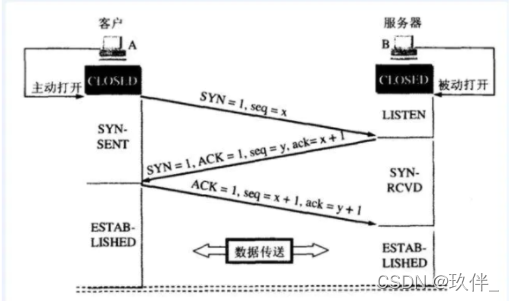
1.Client发送Syn 消息给Server端,SYN标志位在此场景下被设置为1,同时会带上Client这端分配好的Seq号,这个序列号是一个U32的整型数,该数值的分配是根据时间产生的一个随机值,通常情况下每间隔4ms会加1。除此之外还会带一个MSS,也就是最大报文段长度,表示Tcp传往另一端的最大数据块的长度。
2.Server端在收到Syn消息之后,返回Ack消息给Client,用来通知Client,Server端已经收到SYN消息并通过了确认。这一步Server端包含两部分内容,一部分是回复Client的Syn消息,其中ACK=1,Seq号设置为Client的Syn消息的Seq数值+1;另一部分是主动发送Sever端的Syn消息给Client,Seq号码是Server端上面对应的序列号,当然Syn标志位也会设置成1,MSS表示的是Server这一端的最大数据块长度。
3.Client在收到第二步消息之后,Client发消息给Server端,这个方向的通道已经建立成功,Client可以发送消息给Server端了,Server端也可以成功收到这些消息。其次,Client端需要回复ACK消息给Server端,消息包含ACK状态被设置为1,Seq号码被设置成Server端的序列号+1。(备注:这一步往往会与Client主动发起的数据消息,合并到一起发送给Server端。)
2.2.TCP的四次挥手
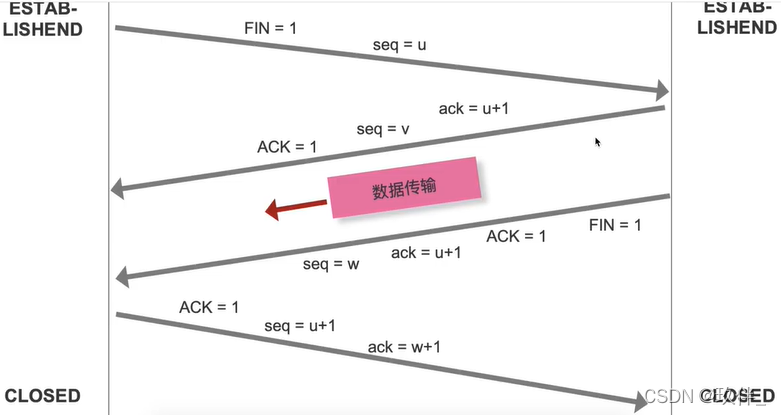
1.客户端向服务器发送释放连接的标识FIN = 1,和一个序列号seq;
2.服务器返回信息回馈,其中ACK=1,确认号ack是客户端的序列号+1,序列号seq来自服务端;
3.此时不会关闭传输通达,因为服务端可能还有需要发送的数据,服务端发送完数据后,发送FIN + ACK 进行结束确认,此时序号和确认号不需要改变;
4.客户端收到服务端的结束确认信息后,发送ACK进行确认,自己的序号seq使用服务端的确认号,自己的确认号使用对方的序列号+1;
为什么要挥手四次?
服务器收到客户端的FIN报文,可能不会立刻关闭连接,需要及时反馈先回复一个ACK报文代表FIN报文已经收到,但还有数据需要传递,要等服务器所有的数据全部发送完毕后再发送给FIN报文给客户端。
请求头 Connection:keep-alive可以保证tcp通道建立后可以不关闭,一般在页面关闭时才会关闭
在http1.0中使用 Connection:keep-alive 需要手动进行配置,但在http1.1中成为了默认规范;
服务器接收到后就会准备发送响应数据,响应数据包含响应行响应头等信息,将其发送给浏览器的网络进程,浏览器会解析响应头中的内容;
网络进程会根据响应头的Content-Type判断响应体的数据类型,若值为text/html,则响应体内容为html类型,为octet-stream返回字节流类型;
若Content-Type值为text/html则浏览器需要准备渲染进程进行渲染;
第四步 渲染进程
浏览器准备好了渲染进程,将网络进程中的数据提交渲染进程,两者建立数据传输的管道IPC;
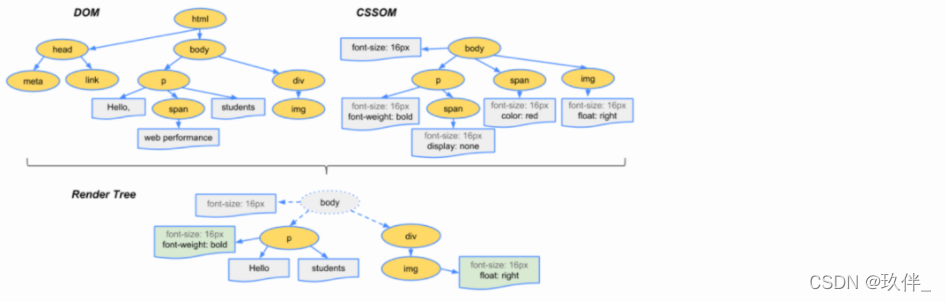
1.html解析
传输过程中,渲染进程就会不断读取网络进程的传递的HTML内容,将其交给HTML解析器,动态的将这些字节流解析为DOM。
在这些HTML格式的字节流中,存在两类组成这类字节流的最小单元,分别是标签和文本,需要一个分词器解析出来,生成一段段的token,HTML解析器会维护一个Token栈,计算节点之间的父子关系,生成DOM树(对象结构)。
html代码中会引入一些额外的资源,图片和css资源会从网络中下载,不会影响html的解析,script标签即js代码,此时会停止html解析的流程,去加载执行js,加载完成后再继续解析html
- DOM树的绘制规则:
将HTML元素依次入栈,栈中相邻的元素就是呈父子关系的元素;
当出现文本节点时,它不会入栈,根据谁是栈顶元素判断其父元素;
当出现结束标签时,会将栈顶元素出栈;
知道整个Token栈清空了,代表HTML字符流解析完毕了;
在浏览器渲染过程中,默认情况下遇到script标签或是@import是同步加载,浏览器会让主线程去加载资源信息,完成后再继续向下渲染页面;遇到link/img/audio/video标签是异步加载,即浏览器会分配一个新的线程去加载,主线程会继续向下渲染页面(但css@import这种导入方式是同步加载)
3.css解析
与html解析类似,他解析最终形成CSSOM树,过程为Bytes -> Characters -> Tokens -> Nodes -> CSSOM。
4.render树
layout布局,由DOM树与CSSOM树结合形成的渲染树(其中无法显示的元素,如script,head元素或diplay:none的元素,不会在渲染树中,也就最终不会被渲染出来),渲染树记录着节点的坐标和占用的区域,页面的布局,绘制都是以render树为依据。
5.确定节点绘制的层级关系
最常见的就是设置了z-index属性的元素,为了确保正确的层级,主线程遍历渲染树,创建一个绘制记录表,记录绘制的顺序。 随后遍历layout tree 生成 layer tree。
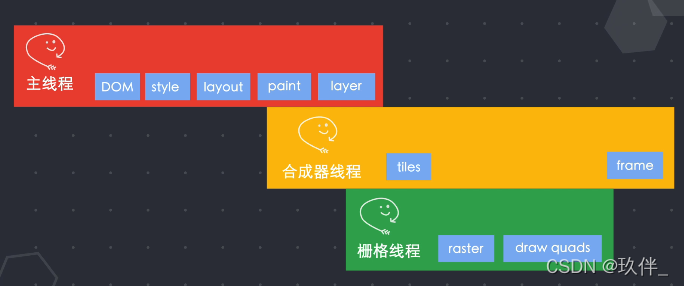
6.页面展示
将render树提供的信息转换成像素点显示在屏幕上,这样的过程成为栅格化。chrome使用合成的方式进行栅格化,就是将页面上所有的元素按照某种规则进行分图层,并把图层栅格化,将可视区域的内容转换成一帧展示给用户。
主线程将上述的渲染树传递给合成器线程, 合成器线程将分完的图层的每一层切分为许多图块,合成器线程将每个图块发送给栅格化线程栅格化图块,将它们存储在GPU内存中。
当栅格化线程栅格化完成后,将处理完毕的draw quads 的图块信息(记录了图块在内存中的位置以及在页面中的哪个位置绘制图块信息)给合成器线程,它生成一个合成器帧,通过IPC传送给浏览器进程,再传送给GPU渲染展示到页面上。
页面发生滚动,就生成一个新的合成器帧,再次给GPU,再次渲染。
7.重排和重绘
可能基于js或其他方式会进一步修改页面的dom结构和样式,此时的渲染树会和之前不一样,需要重新去处理;
若在布局的过程中发生了元素尺寸、位置、隐藏的变化或增加、删除元素时,则进行重排(回流),此时浏览器会重新计算dom树,和CSSOM树,将两者结合重新生成render树,重新绘制页面。
若在布局的过程中元素的外观(字体,颜色)发生变化,则进行重绘。
回流一定会出发重绘,重绘不一定触发回流;回流是非常消耗性能的,尽量要减少dom的回流。
以上步骤就是html文件解析全过程,完成之后,如若当页面有元素的尺寸、大小、隐藏有变化时,重新布局计算回流,并修改页面中所有受影响的部分,如若当页面有元素的外观发生变化时,重绘;
性能优化:如何减少回流的次数?
1.放弃传统的dom操作的时代,基于vue/react开始数据影响视图的模式,使用 virtal-dom dom-diff 进行dom差异化对比,最终将有变化的那一部分重新处理;
2.dom操作的读写分离
现代版本的浏览器都有渲染队列的机制,即发现某一行要修改元素的样式,不立即渲染,而是看看下一行,如果下一行也改变样式,则会把修改样式的操作放到渲染队列中,一直到不再修改样式后整体渲染一次,引发一次回流。
像offsetTop,clientWidth,scrollWidth,getComputedStyle等都会刷新渲染队列;
所以尽量不要将设置样式和读取样式的代码混在一起写,这样读取样式的代码会将渲染队列中断,
需要将读写分离。
3.集中改变样
使用 xxx.className = 'yyy',直接修改类名, 或 xxx.style.cssText = 'xxx:ooo;ppp:qqq',以字符串的方式批量设置样式。
4.缓存布局信息,其本质还是读写分离
test.style.left = test.offsetLeft + 1 + 'px';
test.style.top = test.offsetTop + 1 + 'px';以上代码可以优化为
// 缓存布局信息
let curLeft = test.offsetLeft,
curTop = test.offsetTop;
div.style.left = curLeft + 'px';
div.style.top = curTop + 'px';5.创建文档碎片
文档碎片就是存储文档的容器,使用document.createDocumentFragment()创建
6.使用css硬件加速(GPU加速)
如transform,opacity,filters...这些属性会触发硬件加速,不会引发回流和重绘。

二.HTTP协议
2.HTTP请求信息
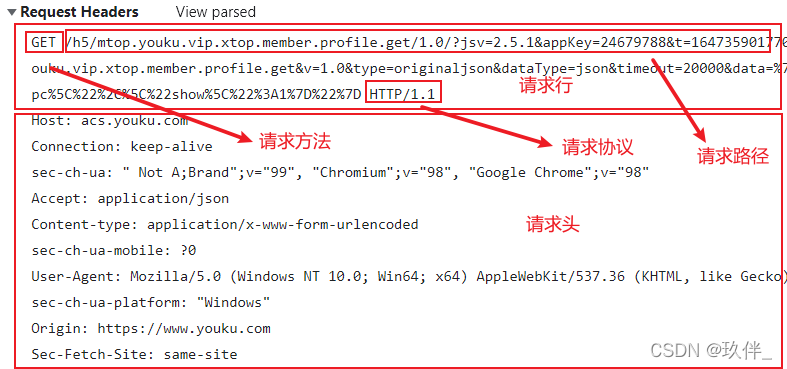
1)请求信息
- 请求行 又分为 请求方法 请求路径 所用的协议及版本
- 请求头 post请求需要加上content-length 和 content-type 指明请求体长度和类型
- 请求空行 头信息和主体信息之间需要这个空行做区分
- 请求主体信息 get 请求体为空,post的请求体不为空
下面是一个请求报文:
2)请求方法
GET:主要用于从服务器获取数据,可以刷新,可以在书签中收藏,可以被浏览器缓存(两次请求的地址一样),请求提交的内容是在url中的,所以数据长度是有限制的,一般为2KB(IE),其他浏览器一般在4-8KB左右,从而安全性较差(url劫持),请求提交的中文字符会通过urlencode进行编码;
解决浏览器对于两次相同的get请求缓存的办法:在query中添加随机数
xhr.open('get',`/list?a=90&_=${
Math.random()}`)DELETE:一般应用于告诉服务器,从服务器上删除点东西;
HEAD:可以确认一个资源是否存在,用head请求某个资源时,只想获取响应头内容,不会在响应体中返回内容。
OPTIONS:试探性请求,发送请求给服务器看看服务器能不能接受,能不能返回。
POST:主要用于将数据发送到服务器,刷新后请求会重新提交,请求提交的数据在请求体中,一般没有长度限制,较于get比较安全。
PUT:往服务器上的某个资源传输内容,一般用于文件获取大型数据传输(使用post也一样)
TRACE:会返回服务器最终收到的请求,一般用于代理上网,查看代理是否修改了你发送的请求
不遵循这些规范也可以,但这些都是约定俗成的规范。
3)所用的协议
一般是HTTP1.1
3.HTTP响应信息
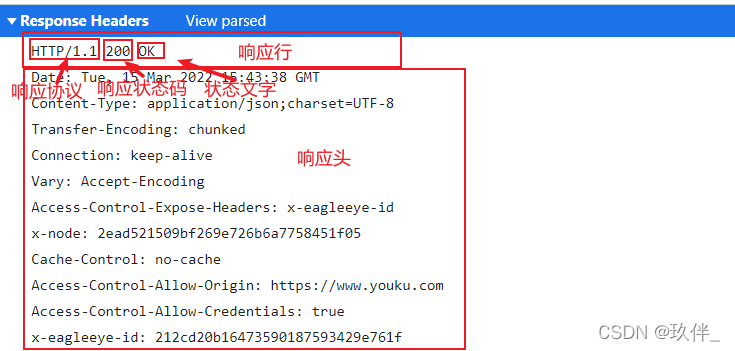
1)响应信息
- 响应行 又分为 协议版本 状态码 状态文字
- 响应头
- 响应空行
- 响应体
下面是一个响应报文:
4.常见响应头/请求头
1)请求头
1.Accept:浏览器端接受的格式;
2.Accept-Encoding:浏览器端接受的编码方式;
3.Accept-Language:浏览器端接收的语言用于服务器判断多语言;
4.Catch-control:控制缓存的失效性;
5.Connection:连接方式,如果是keep-alive,且服务端支持,会复用链接;
6.Host:HTTP访问使用的域名;
7.If-Modified-Since:上次访问的更改时间,如果服务端认为此时间后自己没有更新,则会返回304
8.If-None-Match:此访问时使用E-Tag,通常是页面的信息摘要,这个比更改时间更准确一些;
9.User-Agent:客户端标识;
10.Cookie:客户端存储的cookie字符串;
2)响应头
1.Cache-Control:缓存控制,用于通知各级缓存保存的时间,例如max-age=0,表示不要缓存
2.Connection:连接类型,Keep-Alive表示复用连接;
3.Content-Encoding:连接编码方式,通常是gzip;
4.Content-length:内容的长度,有利于浏览器判断内容是否已经结束;
5.Content-Type:内容类型
application/json --- json格式
application/x-www-form-unlencoded --- 用于表单提交
multipart/form-data --- 用于文件上传
text/html --- html格式
6.Date:当前服务器时间;
7.ETag:页面的信息摘要,用于判断是否需要重新到服务器获取数据;
8.Expires:过期时间,用于判断下次请求是否要到服务器重新取回页面;
9.Keep-Alive:保持连接不断时的一些信息,如timeout=5,max=100;
10.Last-Modified页面上次修改的时间;
11.Server:服务器软件的类型;
12.Set-Cookie:设置cookie,可以存在多个;
13.Via:服务器的请求链路,对一些调试场景至关重要的一个头;
5.响应状态码
1xx:临时响应
2xx:成功处理请求
200:成功
201:请求成功并且服务器创建了新的资源
204:服务器成功处理了请求,但没有返回任何内容
3xx: 重定向
301:永久重定向
302:临时重定向
303:查看其他位置
304:是对客户端有缓存情况下服务端的一种响应。服务器返回此响应时,不会返回网页内容
4xx:请求错误
401: 用户没有访问权限,需要进行身份认证
403:禁止,运行脚本没有开放指定用户权限
404:url地址未找到
405:请求方式不对
409:会导致一个或多个资源处于不一致的状态
410:请求的地址过期了
422:请求参数错误
429:发送请求过于频繁,请求被干掉
5xx:服务器错误
500:服务器内部错误,服务端代码出了问题
502:内网代理层如nginx向后端服务器通信出现问题时
504:服务器网关超时
6.HTTP内容压缩
为了提高网页在网络上的传输速度,服务器对主体信息进行压缩;使用content-Encoding:gzip这个响应头指定当前响应的文本内容为压缩的内容;
常见的压缩方式有:gzip压缩,compress压缩,google chrome 压缩等;
压缩的过程:服务器返回压缩的内容,客户端接收压缩内容,进行解压缩
一般压缩文本格式的的文件,而图片视频等资源压缩需要消耗CPU资源,以下为bilibili网站为例:
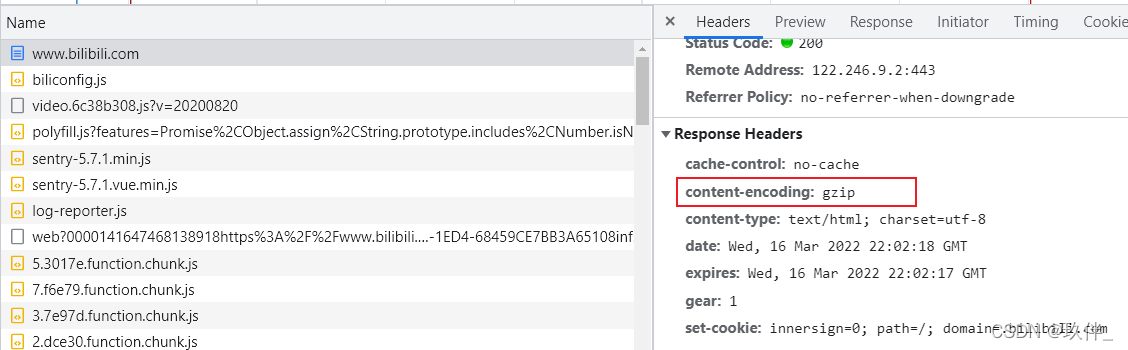
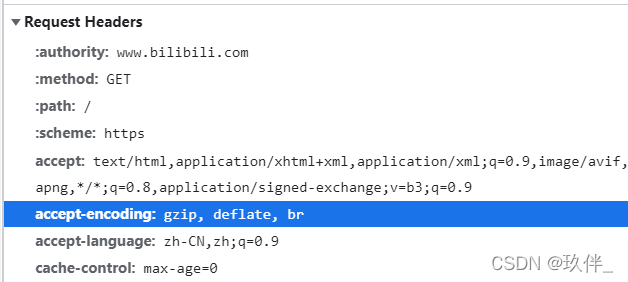
服务器通过请求头 accept-encoding:gzip, deflate, br 知道浏览器能够支持的压缩类型,如果浏览器不支持压缩,则响应压缩的文本。
7.防盗链技术
使用防盗链技术可以防止网站的图片等静态资源被外部网站使用;
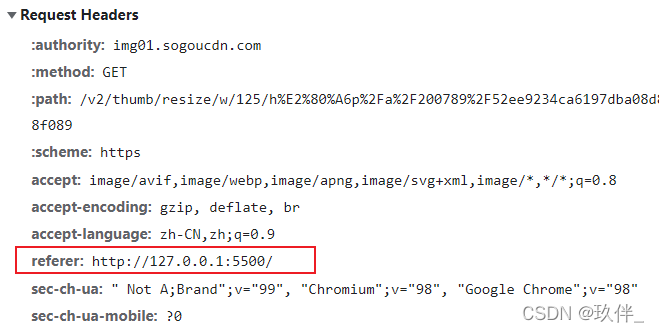
在HTTP协议中,请求头信息中有一个重要的选项Referer,它代表网页的来源,即上一页的地址;
如果在浏览器中直接输入地址访问资源,则不会有referer请求头;
服务器可以通过这个请求头判断图片是从哪里引用的,也可以知道客户端是从哪个连接跳转过来的,从而使用过滤器判断非本网站的静态资源请求;
比如,在本地创建一个html文件,引入其它网站的一张图片地址,发现图片无法显示,说明该网站对静态资源做了防盗链处理
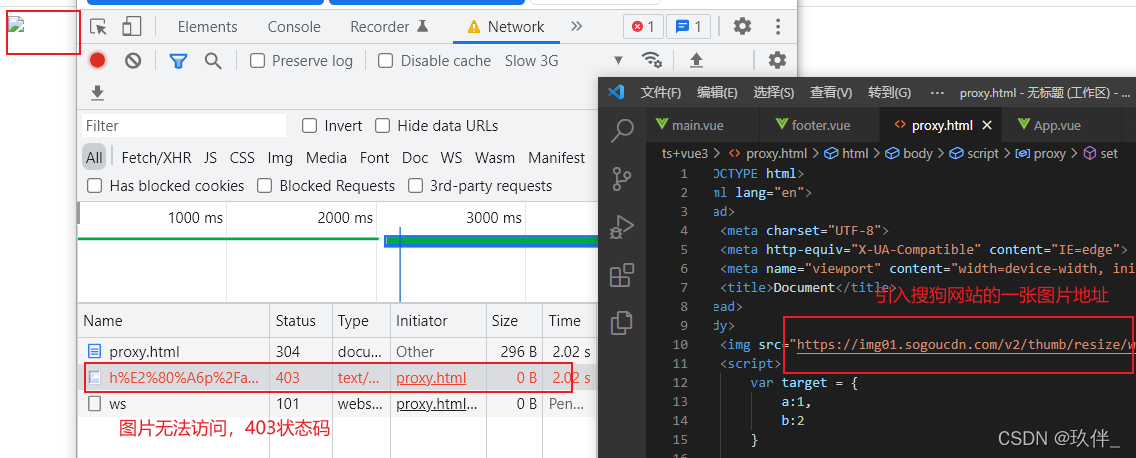
该请求的请求头存在referer字段,值为本地ip
8.多路复用
在http1.1中默认设置了Connection;keep-alive保证tcp连接不断开,从而可以使得tcp连接通道的多用性,但每一次只能发送一次请求,即第一次请求成功后才能发送第二次请求,但如果前面一个请求没有回来,下面一个请求就永远无法发送;
在http2.0中可以在当前的tcp通道中可以同时发送多个http请求,这就是多路复用。
9.http1.0/1.1/2.0的一些区别

三.async/defer属性
当浏览器碰到 `script` 脚本时,没有 `defer` 或 `async`,浏览器会立即加载并执行指定的脚本,“立即”指的是在渲染该 `script` 标签之下的文档元素之前,也就是说不等待后续载入的文档元素读到就加载并执行(默认遇到script同步加载);
1.async模式 下载后立刻执行
<script type="text/javascript" src="x.min.js" async="async"></script>当浏览器遇到 script 标签时,文档的解析不会停止,其他线程将下载脚本,脚本下载完成后开始执行脚本,脚本执行的过程中文档将停止解析,直到脚本执行完毕。
如果你的脚本并不关心页面中的DOM元素(文档是否解析完毕),并且也不会产生其他脚本需要的数据。
2.defer模式 下载后不立刻执行
<script type="text/javascript" src="x.min.js" defer="defer"></script>当浏览器遇到 script 标签时,文档的解析不会停止,其他线程将下载脚本,待到文档解析完成,脚本才会执行;
如果你的脚本代码依赖于页面中的DOM元素(文档是否解析完毕)
四.浏览器缓存
浏览器缓存分为强缓存和协商缓存,这两者置针对于不经常更新的静态资源文件,整个浏览器缓存的执行流程如下:
1.浏览器根据这个资源的http头信息来判断是否命中强缓存,如果命中则直接加载缓存中的资源,并不会将请求发送到服务器;
2.没有强缓存或强缓存失效,则检查是否有协商缓存,有就执行协商缓存,浏览器会将资源加载请求发送到服务器,服务器来判断浏览器本地缓存是否失效,若可以使用,则服务器并不会返回资源信息,浏览器继续从缓存加载资源;
3.如果未命中协商缓存,则服务器会将完整的资源返回给浏览器,浏览器加载新的资源,并更新缓存;
缓存位置:内存缓存,硬盘缓存;
打开网页会先看硬盘缓存;普通刷新会优先使用内存缓存,再看硬盘缓存;强制刷新(ctrl + F5)不走任何缓存,请求头部将带有Cache-control:no-cache,服务器直接返回200和最新内容。
1.强缓存
通过响应头指定一个时间,在这个时间内浏览器不请求服务器,走浏览器缓存;
标志:开发者工具看到状态码200 + size列表显示fro m cache;
响应头字段:Expires + Cache-Control,后者优先级高
1.Expires:返回一个时间,代表资源失效的时间,在此之前命中强缓存。如:
Expires:Thu 31 Dec 2037 23:59:59 GMT是一个绝对时间,浏览器时间和服务器不一致,可能资源会提前失效
2.Cache-control:这是一个相对时间 ,如:
Cache-Control:3600可以由多个字段组成:
- max-age:在这个时间长度内缓存是有效的(s)
Cache-Control:max-age=31536000nginx服务器配置强缓存:
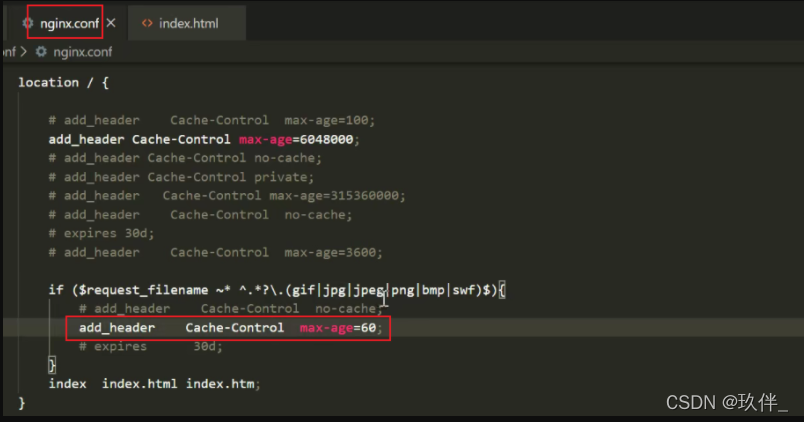
注意一:服务器资源更新但浏览器本地有强缓存怎么办?
1.一般html页面不走强缓存,只会对引入的图片css文件等做缓存,服务器一旦更新,让更新的资源名称和之前不一样,html导入的也将是一个全新的资源文件,这样就会重新获取文件,而对文件名命名的技术一般使用webpack的hash name进行。
2.当文件更新后,我们在html导入的时候,设置一个后缀时间戳 <script src="index.js?32421212">
3.不用强缓存,使用协商缓存。
2.协商缓存
协商的是浏览器的缓存文件是否更新,若未更新走缓存返回304,更新的话服务器发新的文件返回200;
响应/请求头字段:Last-Modified/If-Modify-Since 或 Etag/If-None-Match
命中返回304,浏览器从缓存中加载资源;
- 服务器在响应头中添加字段Last-Modify,它是一个时间标识,资源最后修改的时间
Last-Modified:Sat,27 Jun 2020 16:46:38 GMT浏览器再次请求资源时,请求头中包含If-Modify-Since ,该值缓存Last-Modify,服务器收到后,根据资源的最后修改时间判断是否命中缓存
If-Modify-Since:Sat,27 Jun 2020 16:46:38 GMT命中返回304,且不返回资源内容,不会返回Last-Modified;
- Etag响应头返回的是一个校验码,保证每一个资源是唯一的,资源变化导致Etag变化,服务器根据If-None-Match 来判断是否命中缓存。
Etag:W/"1a3b3222322123nnd11:0"If-None-Match:W/"1a3b3222322123nnd11:0"- 为什么要Etag:Last-Modify标注的最后修改时间精度在秒级,若一秒之内多次修改资源,不能标注文件的修改时间。
对于数据的缓存可以使用vuex,redux,localStorage。
三.前端安全
1.XSS 跨站脚本攻击
黑客攻击浏览器,注入恶意客户端代码,窃取用户信息,如cookie发送给攻击者。

防御措施:
输入过滤,如:用户输入内容长度限制,采用预期阿字符提交;
输出转义,如str.replace(/ /g," ");
给cookie标记http-only,使得无法通过document.cookie读取,如:
response.addHeader("Set-Cookie", "uid=112; Path=/; HttpOnly")2.CSRF跨站请求伪造

防范CSRF:
1. 服务器中验证请求头Referer
Referer记录了请求的来源地址,从而判断请求来源是否合法;
但Referer可以伪造;
2. 使用token
最主流的方式;
3. 加验证码
成本较大;
四.前端性能优化
1.首页加载慢的优化
问题:首页加载图片过多 --- 图片懒加载
1.图片懒加载
监听滚动条事件,如果滚动条距离浏览器顶部的高度等于图片距离顶部的高度,那么就将data-src的值赋值到src上
<img data-src="lazy.jpg">
<img src="lazy.jpg" data-src="lazy.jpg">2.小图标或图片
纯色的小图标使用iconfont解决,设置font-family的css属性;
对于彩色小图片使用雪碧图,使用background-position的css属性来修改图片坐标;
3.通过工具分析哪些资源请求过多
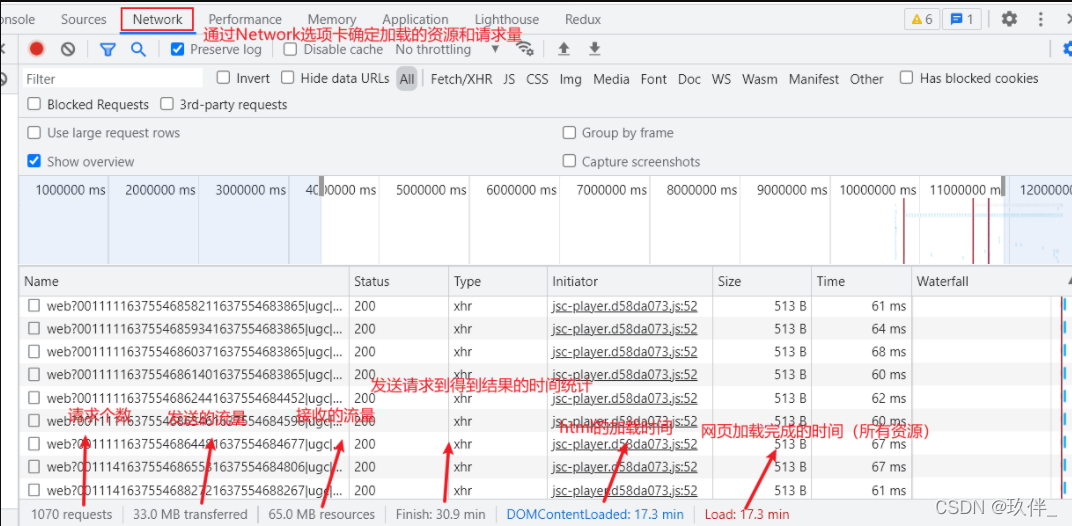
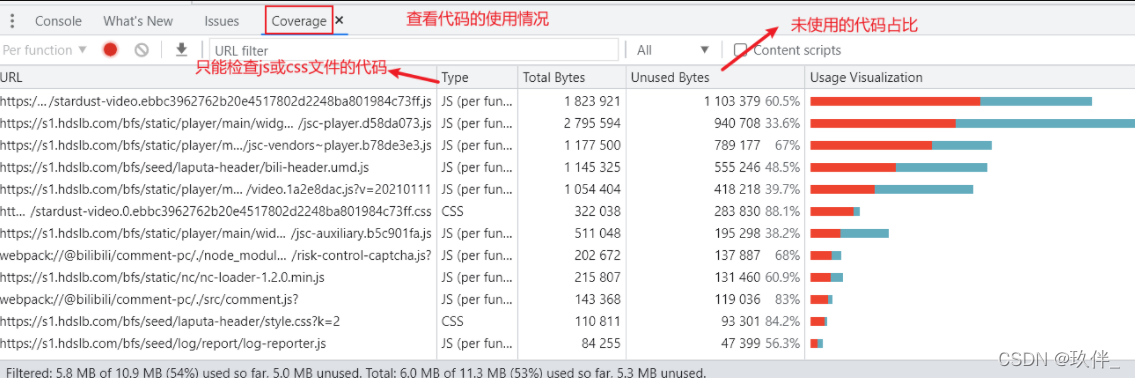 综上,可以对于未使用的代码进行懒加载;
综上,可以对于未使用的代码进行懒加载;
4.减少资源的请求量
通过nginx服务器(来做CDN,用来处理静态资源),来做资源文件合并combo(下载concat插件做相应配置)
5.将多个js/css文件合并为一个
实际上是拼接资源路径的链接,访问一个连接可以访问一个文件,但将多个连接在地址栏中拼接在一起访问可以访问拼接后的文件;
在日常的企业项目中服务器分类:
应用服务器:服务端语言运行的服务器如Java
数据库服务器:放数据库的服务器;
存储服务器:放大型文件的服务器;
CDN服务器:放静态资源的服务器(JS,CSS,图片)
6.使用webpack来做资源文件的物理打包
- 引入的较大的第三方库,比如组件库,函数库,设定按需加载,一般通过Babel插件来实现;
- 使用前端路由懒加载,仅使用于SPA应用
以React为例,使用React Lazy进行动态路由的加载(16.6以上);
lazy(() => import("./组件路径名"));webpack只要遇到import("xxx"),就会把括号内引入的内容单独打成一个包;
import返回的是一个Promise,用其状态进行渲染流程的控制,Promise是Pending状态,那么就渲染Loading组件,resolve就渲染动态导入的组件。
7.静态资源量过大的解决方式
- CSS和JS可以通过Webpack来进行混淆和压缩;
混淆:将HS代码进行字符串加密(最大程度减少代码)
压缩:去注释空行以及console.log()等调试代码
- 图片也可以进行压缩
- 可以通过自动化工具来压缩图片;
如熊猫站 -- 通过减少颜色的数量和不必要的数据来实现文件压缩;
在项目中 npm install --save tinify 下载,实现图片的批量压缩
- 对图片进行转码 -> base64格式
使用Webpack的url-loader进行图片策略的配置,将小图片转化为base64格式,因base64格式的图片作用是减少资源的数量,但是base64格式的图片会增大原有代码的体积。
- 使用Webp格式
- 通过开启gzip进行全部资源压缩
gzip是一种压缩格式,可以对任何文件进行压缩;
通过nginx服务器配置项进行开启
8.webpack打包策略
将打包策略结合网络缓存来优化;
第三方包改动频率小,公共代码包中等,非公共代码包改动频率高,所以可以将三者分开打包;
再对于第三方的不常变动的资源,使用Cache-control:max-age=315000并配合协商缓存Etag使用;
对于需要变动的资源,可以使用Cache-control:no-cache配合Etag使用,表示该资源已被缓存,但每次需要发送请求询问该资源是否更新;
9.CDN
CDN是一种解决方案,常用nginx服务器实现;
CDN服务器就是距离用户最近的一台服务器,把所有静态资源都同步到这台服务器上,以后只要访问网站,就直接从这台服务器上下载资源,随着用户位置的改变,会切换访问的服务器(切换节点);
对于同一个域名协议端口,最多可以打开6个TCP连接(最多同时发送6个);
CDN服务器的地址和主服务器的地址不同,解决了浏览器对同一个域名并发请求上限的限制;
对于HTTP2.0S使用多路复用机制,破除浏览器对并发请求的限制;
2.运行阶段
1.渲染十万条数据如何造成不卡顿
浏览器卡顿的原因是操纵dom的次数太频繁;
const total = 100000;
let ul = document.querySelector('ul');
// 一次渲染一屏的量
const once = 20;
// 渲染次数
const loopCount = total / once;
// 已经渲染的次数
let countHasRender = 0;
function add(){
const fragment = document.createDocumentFragment();
for (let i = 0; i < once; i++) {
const li = document.createElement("li");
li.innerText = Math.floor(Math.random() * total);
fragment.appendChild(li);
}
ul.appendChild(fragment);
countHasRender += 1;
loop();
}
function loop(){
if(countHasRender < loopCount){
// 使用这个API逐帧渲染
window.requestAnimationFrame(add);
// 帧:1秒播放多少图片,一般浏览器渲染速度是60帧/秒
//1000/60 = 16 16毫秒渲染一帧,一帧20条数据
//setTimeout(add,16);
}
}
add();1.使用document.createDocumentFragment 创建虚拟节点,避免没有必要的渲染;
2.当所有的li渲染完毕后,一次性把所有节点的li标签全部渲染出来;
3.使用分段渲染的方式,一次渲染一屏的数据;
4.最后使用window.requestAnimationFrame来逐帧渲染,一帧就是一张图片,浏览器需要每秒渲染60帧才能保证用户看到的页面不会卡顿,由此计算可知渲染一帧需要16毫秒,requestAnimationFrame可以由系统决定回调函数的执行时机,保证回调函数在屏幕每一次刷新间隔中被执行一次,即16ms执行一次,从而每一帧渲染20条li。
优点:
1.使用setTimeout实现动画,当前页卡被切换走(切换到别的页面或最小化),此时定时器依旧在后台执行,这样浪费CPU资源,而requestAnimationFrame会暂停执行,待到切换回来时继续从上次暂停的地方继续执行;
补充:今有一个需要触发重排或重绘的动画,此外还需执行其它js任务,如何避免大量的重绘重排
方法1:
页面的重排和重绘都会影响主线程,而js也是运行在主线程上,浏览器采用的是逐帧渲染,在一帧时间内(通常是16ms)当重排和重绘的任务结束后的多于时间,js拥有主线程的使用权,若js执行时间过长,会导致在下一帧时间开始时,js没有归还主线程使用权(阻塞),导致下一帧动画没有按时渲染,从而出现页面动画的卡顿。
 可以使用requestAnimationFrame(),它会在每一帧被调用,将js任务分为一段段小的任务块,在每一帧时间用完前暂停js执行,归还主线程,从而主线程可以按时执行绘制。
可以使用requestAnimationFrame(),它会在每一帧被调用,将js任务分为一段段小的任务块,在每一帧时间用完前暂停js执行,归还主线程,从而主线程可以按时执行绘制。
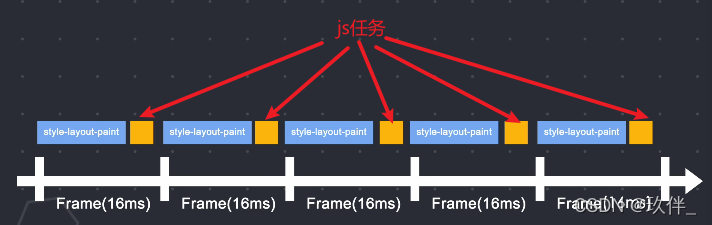
方法2:
栅格化是不占用主线程的,只在合成器线程和栅格线程中进行,而css中transform属性实现的动画不会经过布局和绘制,直接运行在合成器线程和栅格化线程中。
常见的属性如位置变化transform:translate(x,y),大小变化transform:scale(x,y),旋转变化transform:rotate(xxdeg)
五.Rest风格请求
在rest中,认为互联网中所有的东西都是资源,既然是资源就会有一个唯一的uri标识它;
没有rest,原有的url设计
https://localhost:8080/user/queryUserById?id=3
使用resr风格,代表id为3的那个用户记录(资源)
https://localhost:8080/user/3
锁定资源后就可以操作它,常规的操作有增删改查,根据请求方式的不同,代表要做不同的操作:
get 查询,获取资源
post 增加,新建资源
put 更新资源
delete 删除资源
带来的直观体现:传递参数方式的变化,参数可以在uri中
只要能唯一标识资源的就是URI,在URI的基础上给出其资源的访问方式的就是URL,URM
六.浏览器发送options请求
在项目中,前端发送请求时,出现如下报错

原因时浏览器发送了options请求,但服务端没有处理导致;
1.什么时候会发送options请求?
当一个请求跨域且不是简单请求时就会发送 OPTIONS 请求
2.什么是简单请求?
- 使用下列方法之一:
`GET`
`HEAD`
`POST`
- Content-Type 的值仅限于下列三者之一:
`text/plain`
`multipart/form-data`
`application/x-www-form-urlencoded`
- 上面的条件,只要有一点不满足就不是简单请求,例如常见的 `application/json`
当请求跨域且不是简单请求时,浏览器首先使用 OPTIONS 方法发起一个预检请求到服务器,以获知服务器是否允许该实际请求。"预检请求“的使用,可以避免跨域请求对服务器的用户数据产生未预期的影响。
3.服务器如何处理options请求?(以node为例,第六行)
app.all('*', function(req, res, next) {
res.header("Access-Control-Allow-Origin", "*");
res.header("Access-Control-Allow-Headers", "Content-Type,Content-Length, Authorization, Accept,X-Requested-With");
res.header("Access-Control-Allow-Methods","PUT,POST,GET,DELETE,OPTIONS");
res.header("X-Powered-By",' 3.2.1')
if(req.method=="OPTIONS") res.send(200); /*让options请求快速返回*/
else next();
});七.BFC
Formatting Context
Formatting context 是它是页面中的一块渲染区域,并且有一套渲染规则,它决定了其子元素将如何定位,以及和其他元素的关系和相互作用。最常见的 Formatting context 有 Block fomatting context (简称BFC)和 Inline formatting context (简称IFC)。
BFC是什么?
BFC是块级元素格式化上下文,上下文就是一个区域,是一片隔离的区域,在这片区域中的子元素不会和外界的元素产生影响。
1、属于同一个BFC的两个相邻容器的上下margin会重叠(重点)
2、计算BFC高度时浮动元素也参于计算(重点)
3、BFC的区域不会与浮动容器发生重叠(重点)
4、BFC内的容器在垂直方向依次排列
5、元素的margin-left与其包含块的border-left相接触
6、BFC是独立容器,容器内部元素不会影响容器外部元素7、一个BFC区域只包含其子元素,不包括其子元素的子元素
如何开启BFC?
body元素:默认就是BFC元素
float: left | right
overflow: hidden | scroll | auto (只要不是默认值visibl e)
display:inline-block | table-cell | table-caption | flex | grid (只要不是块级元素或none)
position:absolute | fixed (非relative)
BFC能解决的问题?
1. 外边距重合(兄弟元素) 给每个兄弟元素外面包裹一个div,给这两个div开启BFC;
2. 外边距重合(父子元素) 给父元素开启BFC ;
3. 高度塌陷 子元素开启浮动后父元素高度为0产生,给父元素开启BFC.
八.flex属性的含义
flex属性包含三个属性,分别是:
1.flex-grow:当子元素大小小于父元素大小时,是否需要填满父元素
2.flex-shrink:当子元素空间在一行内不够时,是否需要压缩在指定宽度内
3.flex-basis:有值(除auto以外都是有值)宽度以此计算;无值默认auto,会以样式width的值计算,无width则以内容撑开的宽度计算
flex:1 <=> 1 1 0%
flex:auto <=> 1 1 auto
flex:0 <=> 0 1 0%
flex:none <=> 0 0 auto
flex:1 更适合在等比例列表时使用;
lex:auto适用于元素充分利用剩余空间,比如头部导航文字多少不一致时使用
九.js数据类型检测
1.使用typeof
1)检测原理:直接在计算机底层基于数据类型的值(二进制)进行检测;
2)注意点:其中对象的二进制值是000开头的,而null的二进制值也为000开头,所以typeof null 也为 ‘object’;
也可以检测bigint :typeof 111n 'bigint'
3)缺点:对于数组对象/日期对象/正则对象/普通对象 检测的结果都是 ‘object’,对于基本数据类型检测上除了null之外都可以检测,但对于检测对象上,除了function之外都无法进行检测
2.使用instanceof
检测当前实例是否属于这个类,例如:
let arr = [];
console.log(arr instanceof Array); // true
console.log(arr instanceof RegExp); // false
console.log([] instanceof Object); // true1)检测原理:只要当前类出现在实例的原型链上,结果都为true;
2)缺点:由于可以肆意的修改原型的指向,检测出来的结果是不准的
function Fn () {}
Fn.prototype = Object.create(Array.prototype);
let f = new Fn;
console.log(f instanceof Array); // true
不能检测基本数据类型
console.log(1 instanceof Number); // false3)手写instanceof
遵循原则:参数classFun的显示原型在example的原型链上,即实例 example.__proto__ = 类.prototype,循环查找example的原型链上的原型,看看是否有classFun,查找的尽头是Object.prototype.__proto__ = null
function myInstanceof (example,classFun) {
let classFunPrototype = classFun.prototype,
// 等价于example.__proto__,example.__proto__不兼容ie
proto = Object.getPrototypeOf(example);
while (true) {
if(proto === null) {
return false;
}
if(classFunPrototype === proto) {
return true;
}
proto = Object.getPrototypeOf(proto);
}
}
console.log(myInstanceof([],Array)); // true
console.log(myInstanceof([],RegExp)); // false
console.log(myInstanceof([],Object)); // true3.使用constructor
constructor是每一个构造函数原型中的属性,它指向函数对象本身
console.log([].constructor === Array); // true
console.log([].constructor === RegExp); // false
console.log([].constructor === Object); // false
console.log(1.constructor === Number); // true它支持基本数据类型的判断,但它依旧可以被修改,如下:
Number.prototype.constructor = 'AAA';
console.log(1.constructor === Number); // false4.使用Object.prototype.toString.call(value)
这是标准检测数据类型的方法,它不是转换为字符串,是返回当前实例所属类的信息;
返回值:
[object Number/String/Boolean/Null/Undefined/Symbol/Object/Array/RegExp/Date/Function]
在实际项目中,检测数据类型一般将typeof和Object.prototype.toString.call结合使用,如下:
// 数据类型检测
;(function () {
var class2type = {};
var toString = class2type.toString; // Object.prototype.toString
// 设置数据类型检测的映射表
['Boolean','Number','String','Function','Array','Date','RegExp','Object','Error','Symbol'].forEach(name => {
class2type[`[object ${name}]`] = name.toLowerCase();
});
console.log(class2type);
function toType (obj) {
if(obj == null) {
// undefined 和 null
return obj + '';
}
// 引用数据类型 使用 Object.prototype.toString 检测,基本数据类型使用 typeof检测
return typeof obj === 'object' || typeof obj === 'function' ? class2type[toString.call(obj)] || 'object' : typeof obj;
}
window.toType = toType;
})()
console.log(toType(1)); // number
console.log(toType(/^[a-z]$/)); // regexp
console.log(toType(undefined)); // undefined
console.log(toType(new Date)); // date在这个闭包中先要创建一个数据类型的映射表class2type,用于输出检测的数据类型结果,toType方法用于检测数据类型,class2type内容输出如下:

十.三类循环的对比和性能分析
1.for和while循环
我们使用如下代码进行验证for和while循环的执行速度,创建一个长度为9999999的数组,随后风别使用for和while进行遍历,在浏览器控制台查看输出结果
// 循环性能比较
let arr = new Array(9999999).fill(0);
console.time('FOR');
for (let index = 0; index < arr.length; index++) {}
console.timeEnd('FOR');
console.time('WHILE');
let i = 0;
while (i < arr.length) { i++; }
console.timeEnd('WHILE');
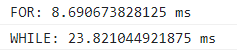
使用let定义变量时,输出结果如下:
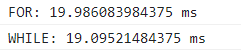
使用var定义变量时,输出结果如下:
结论:
1.基于var声明的时候,for和while性能差不多,一般在不确定循环次数的使用使用while;
2.基于let声明的时候,for循环的性能更好,那是由于在var模式下是不存在块级上下文的,那么变量i就是全局的,那么i就会占据一定的内存空间;而let声明的i不是全局下的i,i属于当前循环轮次生成的块级上下文,每一轮循环结束,对应的块将会被释放,并不会在全局上下文中占据内存;而while循环的变量声明不能写在while后面的括号里,就意味着及时使用let定义循环变量,那么这个循环变量也存在于全局上下文中,占据一定的内存。
3.当然如果for循环中,使用let定义i,但每一轮存缓中存在许多无法被释放的闭包,那么此时for循环的性能会比使用var更高。
4.从本质上来对比,for和while两者的性能是差不多的。
2.forEach循环
forEach较for循环消耗性能更加多一些
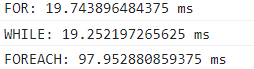
forEach方法内部除了执行循环,还进行了许多别的操作,所以消耗大;
在项目中,如果循环的量级较大或者想要精准的管控循环的每一次的过程,推荐使用for循环这种命令式编程;如果性能消耗可以忽略不记的情况下,推荐使用forEach函数式编程,这样使用上方便且维护性较强。
重写forEach方法:
Array.prototype.forEach = function forEach (callback,context) {
let self = this,
i = 0,
len = self.length;
context = context == null ? window : context;
for(; i < len; i++) {
typeof callback === 'function' ? callback.call(context,self[i],i) : null;
}
};3.for...in...循环
for in 性能很差,迭代当前对象中所有可枚举的属性,私有属性大部分都是可枚举的,共有属性(出现在所属类的原型上的)也有部分是可枚举的。查找机制一定会搞到原型链上去。

缺点:遍历顺序是以数字优先;symbol属性无法遍历;可以遍历到公有中可枚举的(即原型上的属性);
解决方法:
1.使用Object.keys(obj)拿到当前对象上所有非symbol的私有属性;
2.使用Object.getOwnPropertySymbols(obj)拿到当前对象上是symbol的私有属性
3.将1,2得到的两个数组拼接在一起
let obj1 = {
name:'zs',
age:12,
[Symbol('asdf')]:'plm',
0:888
};
let keys = Object.keys(obj1);
if(typeof Symbol !== 'undefined') keys = keys.concat(Object.getOwnPropertySymbols(obj1));
console.log(keys); // ['0', 'name', 'age', Symbol(asdf)]4.for...of...循环
for...of循环速度比for...in快的多但慢于forEach
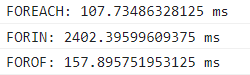
for of循环的原理是按照迭代器规范遍历的,只有拥有Symbol.iterator这套规范的数据结构才可以使用for...of循环,包括 数组,部分类数组,set,map......,但对象没有实现。
for...of的内部机制:
let arrIterator = [10,20,30];
arr[Symbol.iterator] = function () {
let self = this,
index = 0;
return {
// 必须具备next方法,执行一次next方法,拿到数据结构中的某一项的值
next () {
if(index > self.length - 1) { // 迭代结束判断
return {
done:true,
value:undefined
}
}
return {
done:false, // 是否已经完成迭代
value:self[index++] // 每一次获取的值
}
}
}
};
for(let key of arrIterator) {}让类数组对象具有迭代规范,从而进行for of遍历
let obj2 = {
0:888,
1:'sasa',
2:32,
length:3
};
obj2[Symbol.iterator] = Array.prototype[Symbol.iterator];
for(let val of obj2) {
console.log('obj2',val);
}十一. 当前前端开发的项目模式
1.PC端产品
一般用于大型项目,大型项目都是PC和移动端都各做一套产品
一般不需要做响应式开发,都是固定宽高的布局,百分百还原设计稿
有时全屏的项目,需要我们把最外层的容器的宽度设置为百分百布局
2.移动端产品
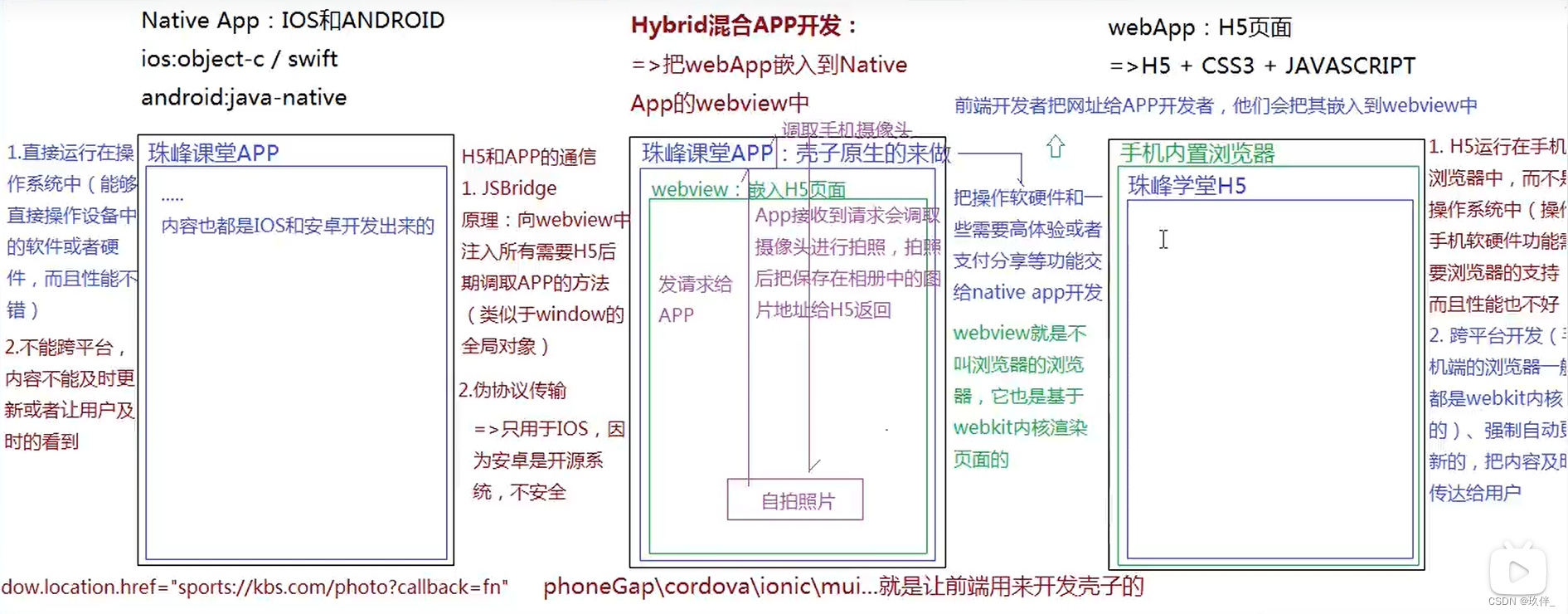
1)webApp:把开发的H5页面放到手机端浏览器,微信自己公司的APP中运行"Hybird混合开发"
2)小程序
3)APP:ios,android,前端(react native,flutter,uni-app,ionic,phoneGap,cordova......)
需要做响应式布局开发,但是只需要适配移动端设备即可,常见的手机尺寸px:320,375,414,360,480,540......,PAD尺寸:768 * 1024
3.PC端和移动端同一套项目
需要响应式布局处理,这种产品一般都是简单的企业展示站