引言:
做前端到目前为止,一个心得体会是实现功能不难,但是想要有很优质的体验,快速的响应,则需要很多的讲究。缓存系列将从前端的角度,着重记录一下浏览器缓存和应用缓存两大缓存方向。此篇记录浏览器缓存。
资源缓存的原则:
基本思想是简历一个资源的缓存池,当webkit需要请求资源的时候,先从资源池中查找这个资源是不是已经存在了,如果有,直接拿来用。否则再发送真正的请求到服务器,webkit在收到该资源之后,会将其设置到该资源类的对象中,以便下次缓存的时候再使用。
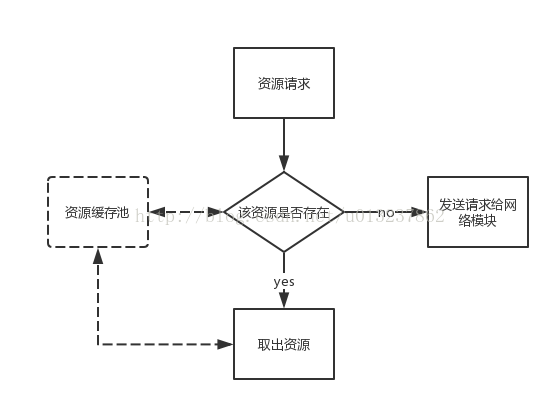
资源池保存资源的key是url,所以说这个过程是对重复请求一个url而言的。如果有一个资源内容一样,但是url不一样,浏览器也会认为这两个是不同的资源,都会进行缓存。
那么先来看一下一个资源从发起请求到最终收到内容,中间发生了哪些事。
一个资源的请求过程:
浏览器从收到请求一个资源的指令,到最终把这个资源呈现在页面上,中间会有很多很多缓存的地方。首先需要分析一下,一个资源从发起请求,到加载,中间经历了哪些过程。
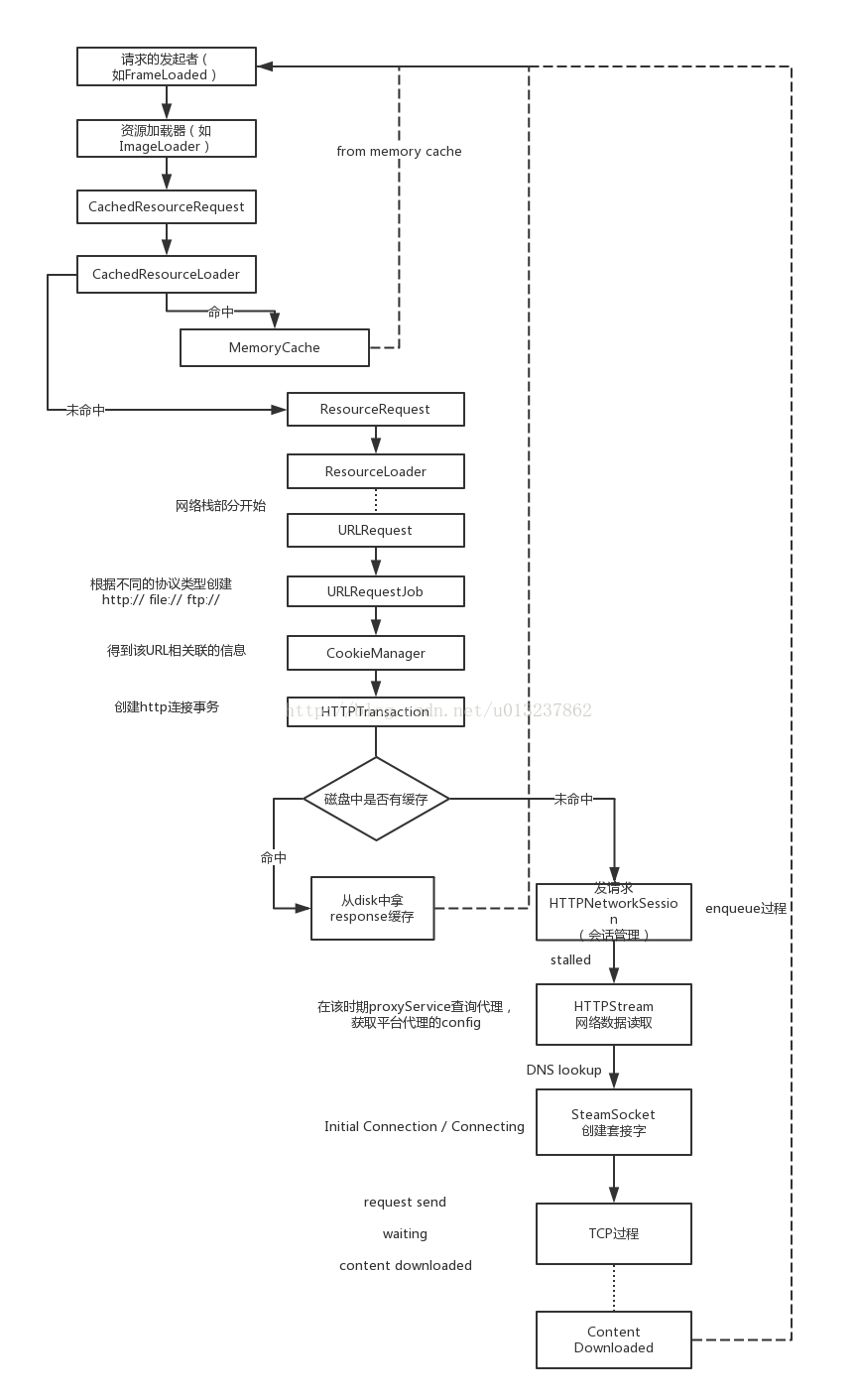
这张图是从webkit技术内幕这本书总结出来了。从webkit的角度来看,从收到发起资源请求,到这个请求最终收到中间发生了哪些过程。总的来说,这一系列的过程分为两大部分,一部分是ResourceLoader部分,一部分是网络栈的部分。
资源的加载有三类加载器:
- 每种资源类的特定加载器:例如image有ImageLoader,css自定义字体有FontLoader类,当html解析到该类资源的标签(或者任何方式,表示要加载该资源时,比如background-image:url等)。就会调用响应的资源加载器进行加载。
- 资源缓存机制的资源加载器:所有的特定加载器都共享它来查找并插入缓存资源,CachedResourceLoader类。所有的特定加载器先从这里看看有没有缓存,如果有的话直接把缓存里的内容拿来用。这里缓存的位置是在内存中(加载速度很快,但是很容易被置换出去)。
- ResourceLoader类:是需要调用网络栈来获取资源时,会调用该加载器。被所有的加载器共享。
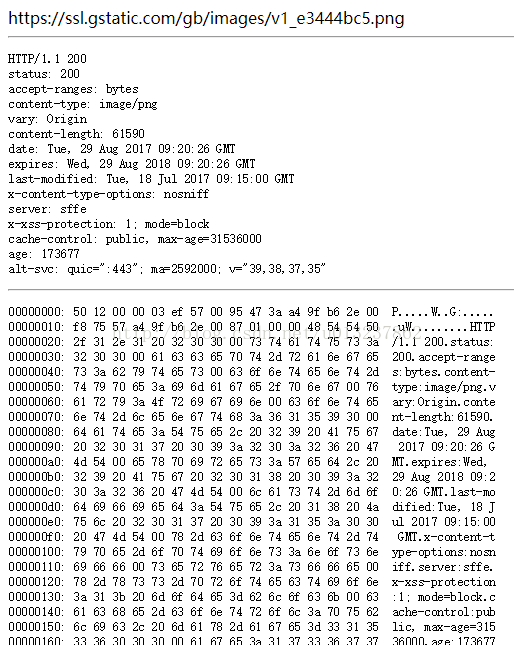
*可以打开chrome://view-http-cache/来查看磁盘缓存了哪些东西

我的chrome缓存这这些东西,可以看到key是资源的URL。chrome至少需要一个索引文件和4个数据文件。索引文件用于存放索引项,用来索引表项。数据文件成为快文件,里面包含很多特定大小的块,用于快速检索,这些数据块的内容是表项,包括http文件头,请求数据和资源数据等。可以看一下缓存的内容是什么:
7. 如果没有命中,则会创建HttpTransaction来发起连接。首先会使用HttpNetworkSession来管理会话。该类会通过HttpStreamFactory建立TCP Socket连接。由于一个域一个TCP上只能建立6个连接,所以多的请求会排队。所以请求在这个阶段会有一个enqueue的时间。然后到了installed的阶段。
8. 接着网络之间的数据处理由HttpStream对象来处理。
9. 开始创建套接字。在创建之前,首先会利用proxyService来查看查询代理,获取平台代理的Config.并且会有DNS lookup的时间,进行DNS 解析。之后才创建套接字。
10. 然后就进行TCP三次握手以及SSL的阶段,这个时间可以在initial connecting中看到。
11.然后就可以等着收结果了。
以上就是一个请求发送的整体过程。从这个过程中可以看到浏览器主要做两次缓存。1,是从memory cache中缓存,2是在disk中缓存。第一个缓存看url,第二个缓存通过url和expires,cache的时间来确定有效期。所以对于希望缓存的资源,首先url不要变,其次就是设置合适的缓存时间。这样在用户允许cache的时候,浏览器能有比较好的缓存效果。
下一篇文章分析从用户的角度来看,如何有效利用浏览器的缓存策略