机器学习入门介绍(非常易懂)
//2019.07.31早上
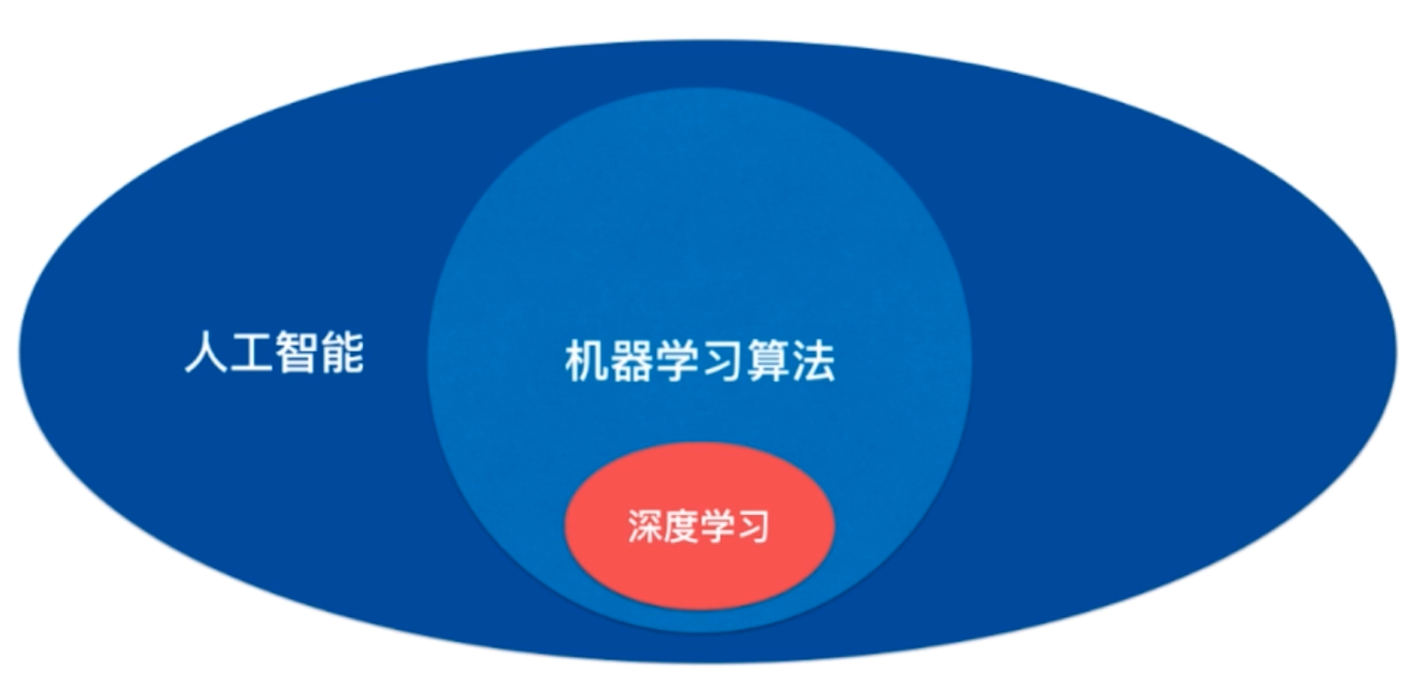
机器学习基本概念介绍
1、机器学习的含义在于让机器去学习,其核心在于学习。
2、最早的机器学习应用是在垃圾邮件的分辨,它开启了机器学习的领域和时代
3、机器学习的典型应用主要体现在以下几个方面:
(1)图像识别
(2)语音识别
(3)数字识别
(4)......
4、机器学习算法的学习必须建立在以下四个方面上面:
(1)深入学习机器学习算法的基本原理;
(2)实际使用算法解决实际场景问题;
(3)对于不同算法进行对比试验;
(4)对于同一算法的不同参数进行对比试验。
5、对于不同的算法的具体使用,主要关键的几个方面在于:
(1)如何评价算法的好坏;
(2)如何避免解决算法的过拟合和欠拟合;
(3)如何调节不同机器学习算法的参数;
(4)如何验证算法的正确性;
(5)对底层算法进行编写。
6、机器学习的搭建环境:
(1)语言:python3
(2)框架:scikitlearn
(3)其他:numpy、matplotlib等
(4)IDE:Jupyter-Notebook或者Pycharm
7、手写数字数据集:MNIST数据集
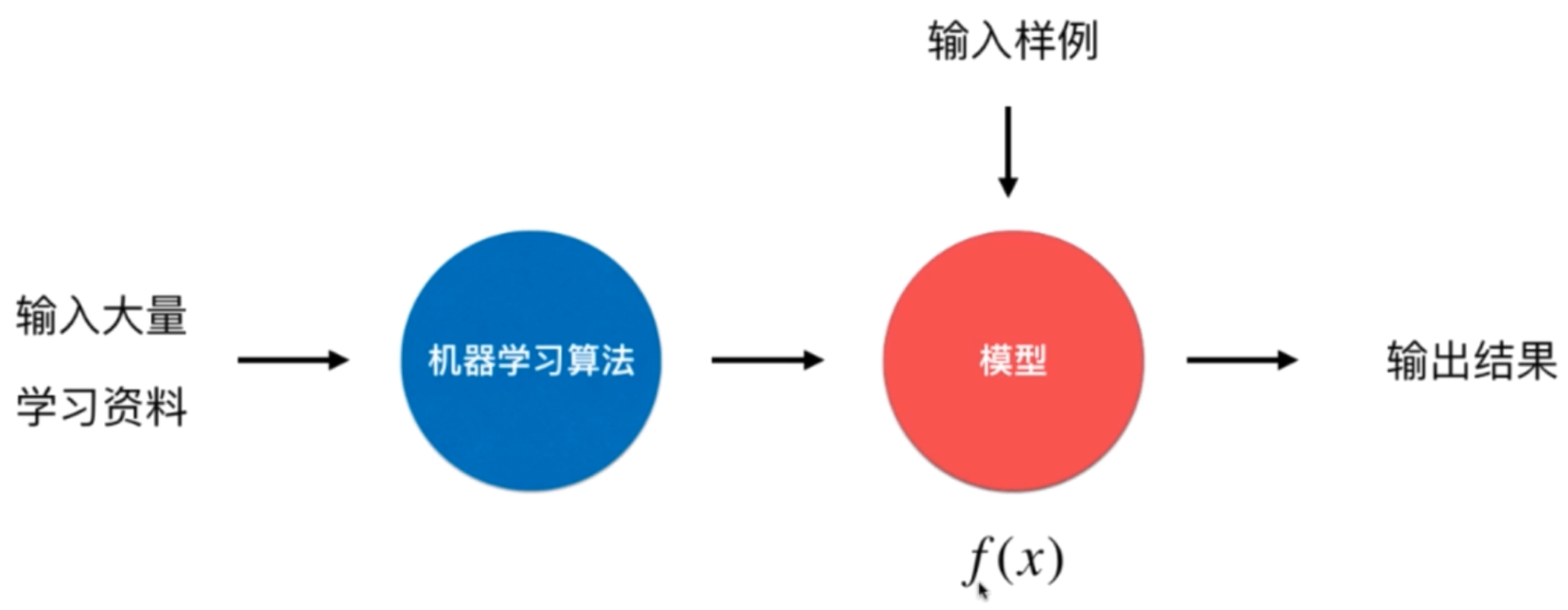
8、对于机器学习算法的学习与使用原则:
不仅仅是调库,而是要深入到算法的内部,更好的理解算法的好坏,在理解的接触上争取创造新的算法。

//2019.07.31下午
机器学习基础入门
1、机器学习的典型数据集iris数据集(根据花的四种特征来区分三种不同的花)
iris数据集总共150行,5列数据,其中前4列为花的四种特征数据(萼片长度、萼片宽度、花瓣长度及其花瓣宽度)最后一列为花的种类数据集(0、1、2)
2、对于机器学习的数据,其数据整体称之为数据集,每一行数据为一个样本,除最后一列数据,其余各列数据都是样本的一个特征,最后一列数据称之为label,即函数值y,而前面的列数据为X向量
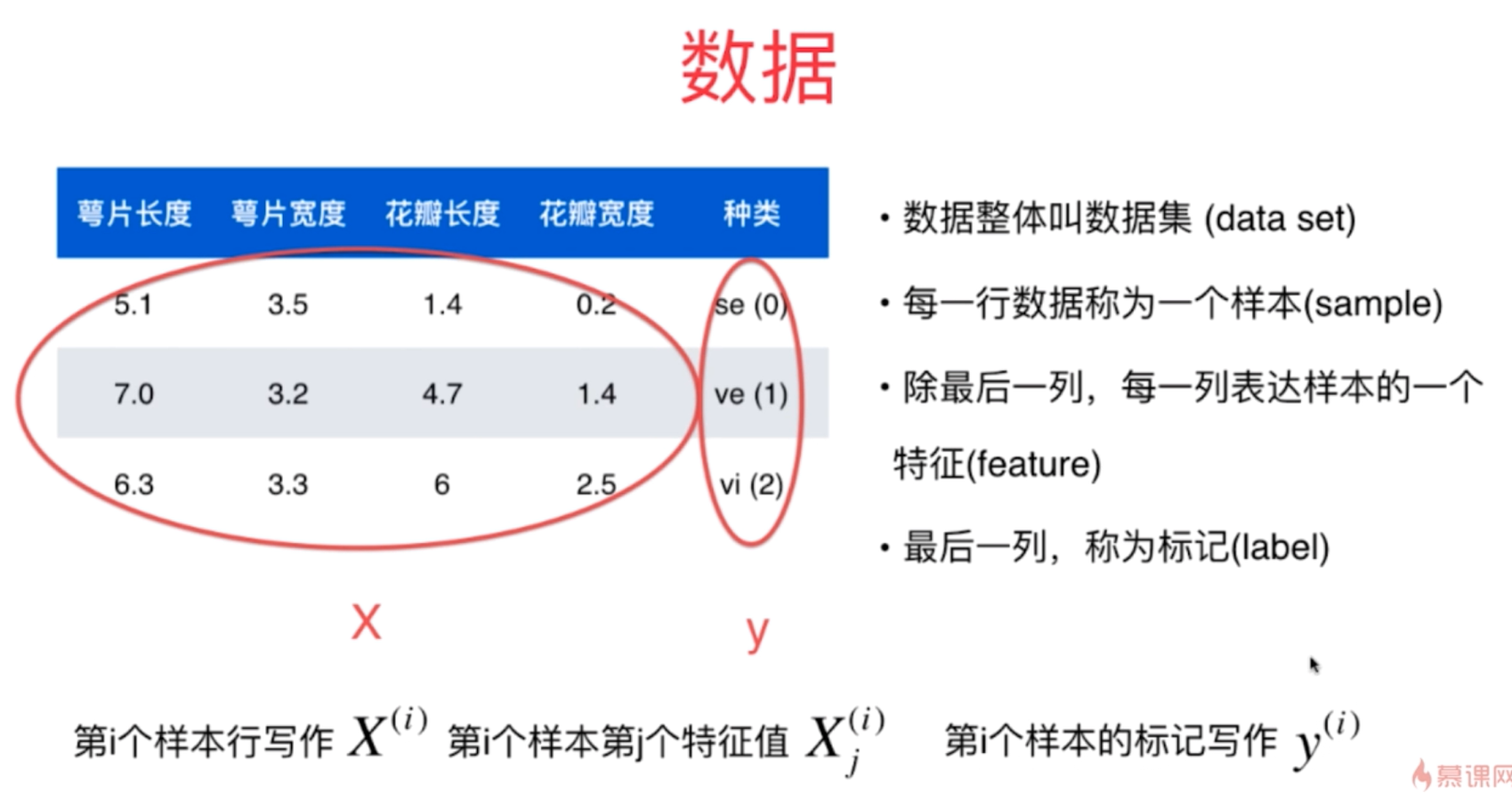
3、对于数据集的每一行疏浚转置以后变为一个列向量,它可以称之为样本数据的特征向量。
4、对于机器学习算法,其数据集的不同特征向量会组成一个特征空间,而分类任务的实质是对于其样本数据组成的特征空间进行切分(低维和高维空间都是同理的)。
5、对于图像处理的每一个图像,其每个像素点都是一个特征,一般的手写数字集MNIST数据集的每个图像都是有28*28=784个特征点,而特征点会因为图像的不同有很多的特征,这些都将是用来识别图像所表达内容的基础。
6、机器学习算法的不同任务:根据结果的离散与连续分为分类算法(结果离散,不连续)与回归算法(结果连续,是一个具体的数值,而非一个类别)
(1)分类任务:
1)二分类任务:邮件是否为垃圾邮件、股票的跌与涨等;
2)多分类任务:手写数字数据集的识别,多种图像处理与识别、判断信用卡的风险等级等;
3)对于一些算法只支持二分类任务,但是有很多的多分类任务可以转化为二分类任务,从而使用相应的二分类算法,也有一些算法可以天然解决多分类任务。
4)多标签任务:多标签任务主要是对一张图像或者一个数据集进行多个属性和特征的识别和归类,然后结合多个归类信息对其进行整体含义的推测与识别,属于高层次机器学习算法的研究内容。
(2)回归任务:回归任务的结果是连续的数值,而不是离散的一些类别,比如股票价格的预测,房价的预测,市场分析,学生成绩等
(3)有些算法只可以解决分类问题,有些算法只可以解决回归问题,而有的算法既可以解决分类问题,又可以解决回归问题。
(4)一些情况下,一些回归任务可以根据实际情况将其转换为分类任务。
7、机器学习主要分为非监督学习、监督学习、半监督学习以及增强学习四种大类算法,其中监督学习主要分为分类问题和回归问题。
8、对于监督学习算法,其机器学习进行数据训练的数据集都拥有以下特点:都拥有标记或者答案(最后一列y数据)也就是说其数据集一般都拥有标定信息,比如:
(1)图像都已经拥有了其标定信息;
(2)医院都已经积累了一定的病人信息以及最终是否患病的情况;
(3)银行已经积累一定的客户信息和他们的信用卡使用情况等
(4)房屋市场以及积累了房屋的基本信息和成交金额。
9、对于大部分机器学习算法,大多属于监督学习算法,比如:k近邻、线性回归和多项式回归、逻辑回归、SVM以及决策树和随机森林等。
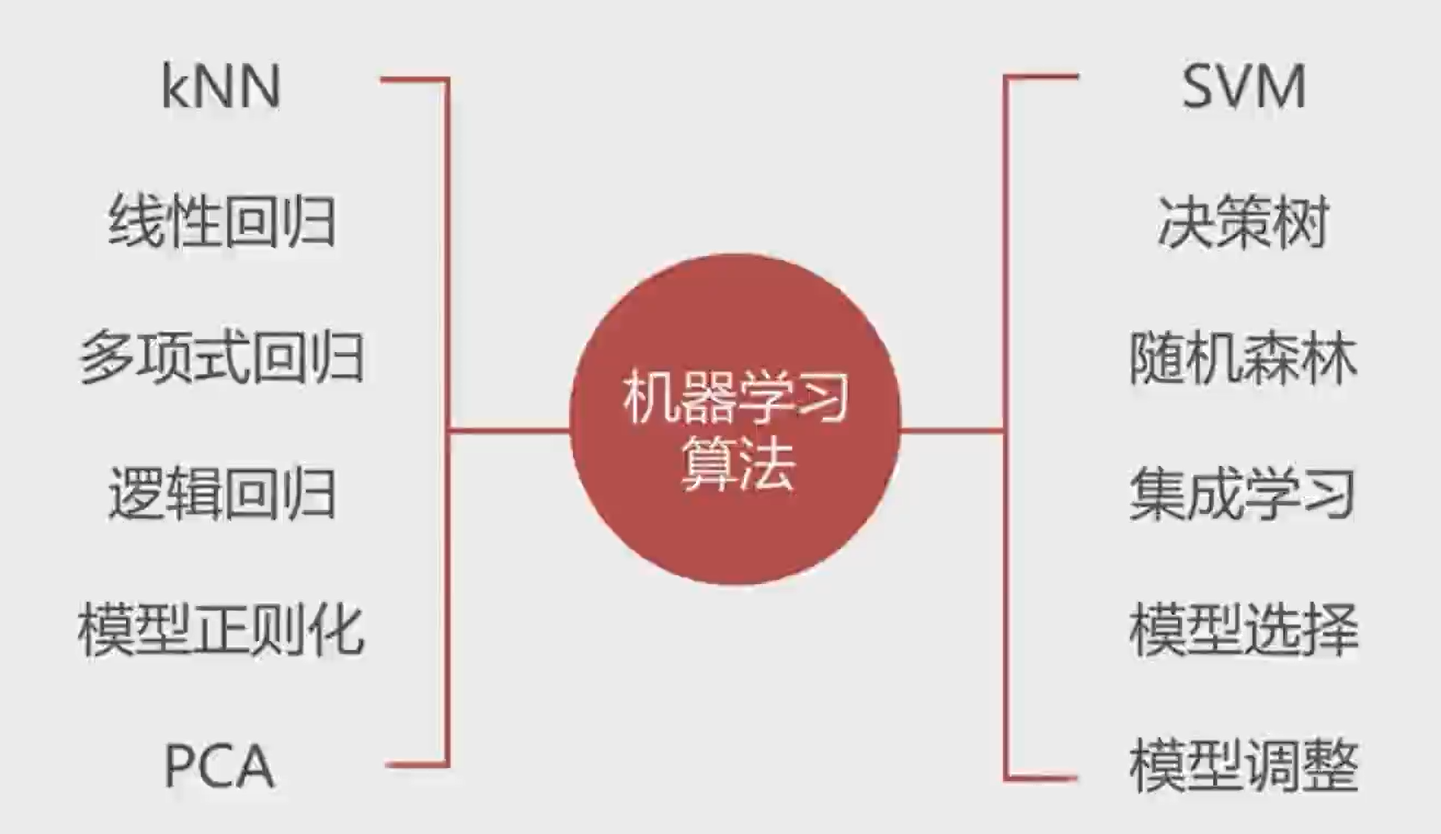
10、对于非监督学习算法,主要的意义在于:
(1)数据集的聚类分析
(2)对于数据进行降维处理,其具体包括对于数据的特征提取和特征压缩(PCA)
