1、为什么要学习机器学习?
一个东西火都是有原因的,机器学习也是人工智能很重要的一个分支,未来趋势。可以应用在
(1)推荐系统:淘宝,衣服穿搭,智能出行线路,大数据精准营销用户画像
(2)识别:垃圾短信识别,国家电网客户用电分析,自动驾驶中的交通标志检测,监控中突发事件识别
2、机器学习是什么?
2.1 定义:
依据学习策略,读取海量的数据,发现其中的规律、联系从而获得归纳推理和决策能力
三要素:海量数据,超强计算、优秀算法
2.2 工作方式
(1)选择数据,将原始数据分成三组 训练数据、验证数据、测试数据
(2)数据建模 、用训练数据和相关特征构建模型
(3)验证模型 用验证数据来验证模型效果如何,接着可以继续调整,类似模拟考试
(4)测试模型 用测试数据测验证模型性能
(5)使用模型 用新的数据做预测
(6)调优模型 使用更多的数据,特征,参数来优化模型
2.3 相关算法
2.4 机器学习过程
(1)数据抽象
(2)设置性能度量指标:避免出现过拟合和欠拟合
(3)数据预处理
(4)选定模型
(5)训练及优化
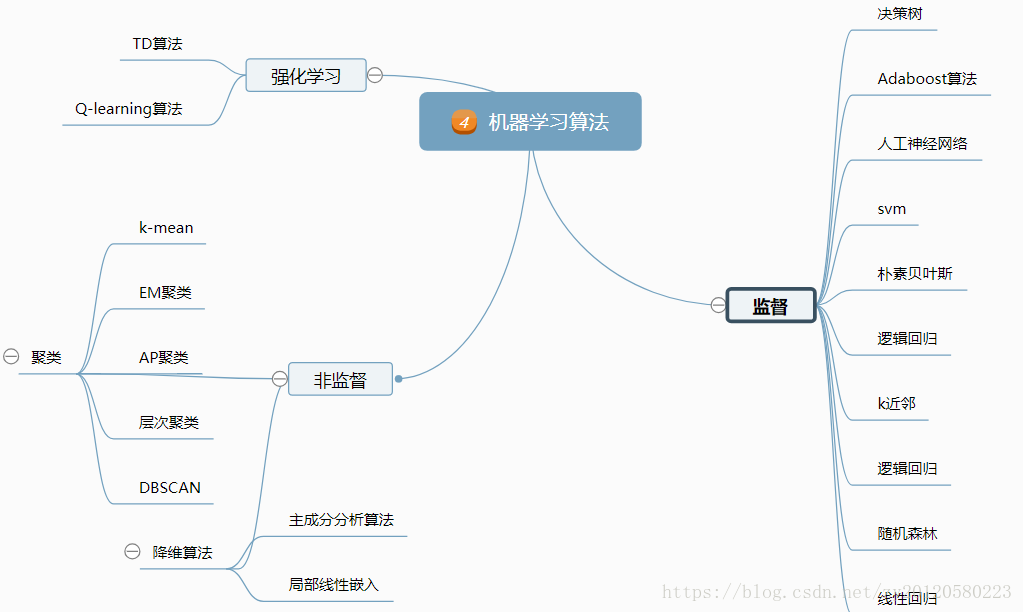
2.1.1监督式学习
监督式学习的常见应用场景如分类问题和回归问题。常见监督式学习算法有决策树学习(ID3,C4.5等),朴素贝叶斯分类,最小二乘回归,逻辑回归(Logistic Regression),支撑矢量机,集成方法以及反向传递神经网络(Back Propagation Neural Network)等等
2.1.1非监督式
在非监督式学习中,数据并不被特别标识,学习模型是为了推断出数据的一些内在结构。非监督学习的常见应用场景包括关联规则的学习以及聚类等。常见非监督学习算法包括奇异值分解、主成分分析,独立成分分析,Apriori算法以及k-Means算法等等。
2.1.2半监督式学习
半监督式学习的应用场景包括分类和回归,半监督学习的算法包括一些对常用监督式学习算法的延伸,这些算法首先试图对未标识数据进行建模,在此基础上再对标识的数据进行预测。如图论推理算法(Graph Inference)或者拉普拉斯支持向量机(Laplacian SVM)等。
2.1.3强化学习
在这种学习模式下,输入数据作为对模型的反馈,不像监督模型那样,输入数据仅仅是作为一个检查模型对错的方式,在强化学习下,输入数据直接反馈到模型,模型必须对此立刻作出调整。强化学习的常见应用场景包括动态系统以及机器人控制等。强化学习的常见算法包括Q-Learning以及时间差学习(Temporal difference learning)
2.2 机器学习过程
(1)数据抽象
(2)设置性能度量指标:避免出现过拟合和欠拟合
(3)数据预处理
(4)选定模型
(5)训练及优化
3 常用的算法
3.1回归算法
试图用函数或者是对误差的衡量来反映变量之间的映射关系
最小二乘法(Ordinary Least Square),逻辑回归(Logistic Regression),逐步式回归(Stepwise Regression),多元自适应回归样条(Multivariate Adaptive Regression Splines)以及本地散点平滑估计(Locally Estimated Scatterplot Smoothing)。
通常,回归可以被用于在现实世界的应用,用来预测未来某一个点的状况
度量营销活动的成功率
预测某一产品的收入
在一个特定的日子里会发生地震吗?
3.2基于实例的算法
通常先选取一批样本,利用后来的数据与样本数据的相似性来进行预测,从而找到最佳匹配不,所以又叫基于记忆的学习。常见的算法包括 k-Nearest Neighbor(KNN), 学习矢量量化(Learning Vector Quantization, LVQ),以及自组织映射算法(Self-Organizing Map , SOM)。
3.3正则化算法
正则化通常是回归算法的延伸,加入了惩罚因子,简单模型予以奖励而对复杂算法予以惩罚。