原文:http://tecdat.cn/?p=3772
创建测试数据
作为第一步,我们创建一些测试数据,用于拟合我们的模型。让我们假设预测变量和响应变量之间存在线性关系,因此我们采用线性模型并添加一些噪声。
我将x值平衡在零附近以“去相关”斜率和截距。结果应该看起来像右边的
trueA <- 5
trueB <- 0
trueSd <- 10
sampleSize <- 31
# create independent x-values
x <- (-(sampleSize-1)/2):((sampleSize-1)/2)
# create dependent values according to ax + b + N(0,sd)
y <- trueA * x + trueB + rnorm(n=sampleSize,mean=0,sd=trueSd)
plot(x,y, main="Test Data")图
![]()

定义统计模型
下一步是指定统计模型。我们已经知道数据是用x和y之间的线性关系y = a * x + b和带有标准差sd的正常误差模型N(0,sd)创建的,所以让我们使用相同的模型进行拟合,看看如果我们可以检索我们的原始参数值。
从模型中导出似然函数
为了估计贝叶斯分析中的参数,我们需要导出我们想要拟合的模型的似然函数。可能性是我们期望观察到的数据以我们所看到的模型的参数为条件发生的概率(密度)。因此,假设我们的线性模型y = b + a * x + N(0,sd)将参数(a,b,sd)作为输入,我们必须返回在此模型下获得上述测试数据的概率(这听起来更复杂,正如你在代码中看到的那样,我们只是计算预测y = b + a * x和观察到的y之间的差异,然后我们必须查找概率密度(使用dnorm)发生这种偏差。
likelihood <- function(param){
a = param[1]
b = param[2]
sd = param[3]
pred = a*x + b
sumll = sum(singlelikelihoods)
(sumll)
}
slopevalues <- function(x){return(likelihood(c(x, trueB, trueSd)))}![]()

斜率参数的对数似然曲线
作为说明,代码的最后几行绘制了斜率参数a的一系列参数值的似然性。结果应该看起来像右边的情节。
为什么我们使用对数
您可能已经注意到我返回似然函数中概率的对数,这也是我对所有数据点的概率求和的原因(乘积的对数等于对数之和)。我们为什么要做这个?你不必这样做,但这是强烈建议的,因为很多小概率乘以的可能性很快就会变得非常小(比如10 ^ -34)。在某些阶段,计算机程序正在进入数字舍入或下溢问题。所以,底线:当你用可能性编程时,总是使用对数!
定义先验
作为第二步,与贝叶斯统计中一样,我们必须为每个参数指定先验分布。为了方便起见,我对所有三个参数使用了均匀分布和正态分布。 无信息先验通常是1 / sigma的比例(如果你想了解原因,请看这里)。当你认真地深入了解贝叶斯统计数据时,这个东西很重要,但我不想让代码在这里更加混乱。
# Prior distribution
prior <- function(param){
a = param[1]
b = param[2]
sd = param[3]
aprior = (a, min=0, max=10, log = T)
bprior = dnorm(b, sd = 5, log = T)
}后验
先验和可能性的乘积是MCMC将要处理的实际数量。这个函数被称为后验(或者确切地说,它在被归一化之后称为后验,MCMC将为我们做,但让我们暂时不挑剔)。同样,在这里我们使用总和,因为我们使用对数。
posterior <- function(param){
return ( (param) + prior(param))
}![]()
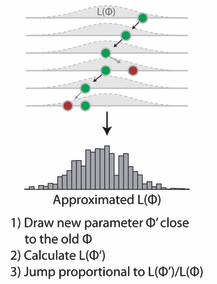
MCMC
现在,实际上是Metropolis-Hastings算法。该算法最常见的应用之一(如本例所示)是从贝叶斯统计中的后验密度中提取样本。然而,原则上,该算法可用于从任何可积函数中进行采样。因此,该算法的目的是在参数空间中跳转,但是以某种方式使得在某一点上的概率与我们采样的函数成比例(这通常称为目标函数)。在我们的例子中,这是上面定义的后验。
这是通过
- 从随机参数值开始
- 根据称为提议函数的某个概率密度,选择接近旧值的新参数值
- 以概率p(新)/ p(旧)跳到这个新点,其中p是目标函数,p> 1表示跳跃
考虑为什么会起作用很有趣,但目前我可以向你保证 - 当我们运行这个算法时,它访问的参数的分布会收敛到目标分布p。那么,让我们在R中得到这个:
######## Metropolis algorithm ################
proposalfunction <- function(param){
return(rnorm(3,mean = param, sd= c(0.1,0.5,0.3)))
}
run_metropolis_MCMC <- function(startvalue, iterations){
for (i in 1:iterations){
if (runif(1) < probab){
chain[i+1,] = proposal
}else{
chain[i+1,] = chain[i,]
}
}
return(chain)
}
chain = run_metropolis_MCMC(startvalue, 10000)
burnIn = 5000
acceptance = 1-mean(duplicated(chain[-(1:burnIn),]))再次,使用后验的对数可能在开始时有点混乱,特别是当您查看计算接受概率的行时(probab = exp(后验(建议) - 后验(链[i,])) )。要理解我们为什么这样做,请注意p1 / p2 = exp [log(p1)-log(p2)]。
算法的第一步可能受初始值的偏差,因此通常被丢弃用于进一步分析 。要看的一个有趣的输出是接受率: 接受标准拒绝提案的频率是多少?接受率可以受提议函数的影响:通常,提案越接近,接受率越大。然而,非常高的接受率通常是无益的:这意味着算法“停留”在同一点 。可以证明,20%到30%的接受率对于典型应用来说是最佳的 。
### Summary: #######################
par(mfrow = c(2,3))
hist( [-(1:burnIn),1],nclass=30, , main="Posterior of a", xlab="True value = red line" )
abline(v = mean(chain[-(1:burnIn),1]))
# for comparison:
summary(lm(y~x))生成的图应该类似于下图。您可以看到我们或多或少地检索了用于创建数据的原始参数,并且您还看到我们获得了一个围绕最高后验值的特定区域,这些区域也有一些数据支持,这是贝叶斯相当于置信度的间隔。
![]()

图:上排显示斜率(a)的后验估计,截距(b)和误差的标准偏差(sd)。下一行显示马尔可夫链参数值。
还有问题吗?请在下面留言!
大数据部落 -中国专业的第三方数据服务提供商,提供定制化的一站式数据挖掘和统计分析咨询服务
统计分析和数据挖掘咨询服务:y0.cn/teradat(咨询服务请联系官网客服)
![]()
QQ:3025393450
![]()
【服务场景】
科研项目; 公司项目外包;线上线下一对一培训;数据采集;学术研究;报告撰写;市场调查。
【大数据部落】提供定制化的一站式数据挖掘和统计分析咨询
