-
29 二进制转换
-
30 二进制转换(二)
-
31 二进制转换小练习讲解
-
32 ASCII码与二进制
-
33 字符串编码的烟花
-
34 Python里使用的编码
-
35 浮点数和科学计数法
-
36 浮点数的精确度问题
-
37 列表类型
-
38 列表类型-修改及插入
-
39 列表类型-其他方法
-
40 列表练习题讲解
-
41 列表练习题讲解2
-
42 深浅copy
-
43 字符串类型讲解
-
44 字符串类型讲解2
-
45 元组类型
-
46 hash函数
-
47 字典类型及特性
-
48 字典类型的详细方法
-
49 集合类型
-
50 集合类型的关系测试
-
51 16进制运算
-
52 为何使用16进制
-
53 16进制与2进制的换算
-
54 字符编码回顾
-
55 字符怎么存到硬盘上的
-
56 字符编码的转换
-
57 Python3代码执行流程
-
58 Python3的代码转换语法
-
59 Python3通过查看编码映射表确定编码类型
-
60 Python bytes类型介绍
-
61 Python3与2字符串的区别
-
62 Python3与2编码总结
-
63 作业需求
29 二进制转换;
1、引言-古时候人类如何通信?!
- 飞鸽传书;
- 八百里加急;
- 信号弹(貌似没有耶);
- 烽火戏诸侯(这个真有)据说狼烟燃烧后烟比较直,不会散开;


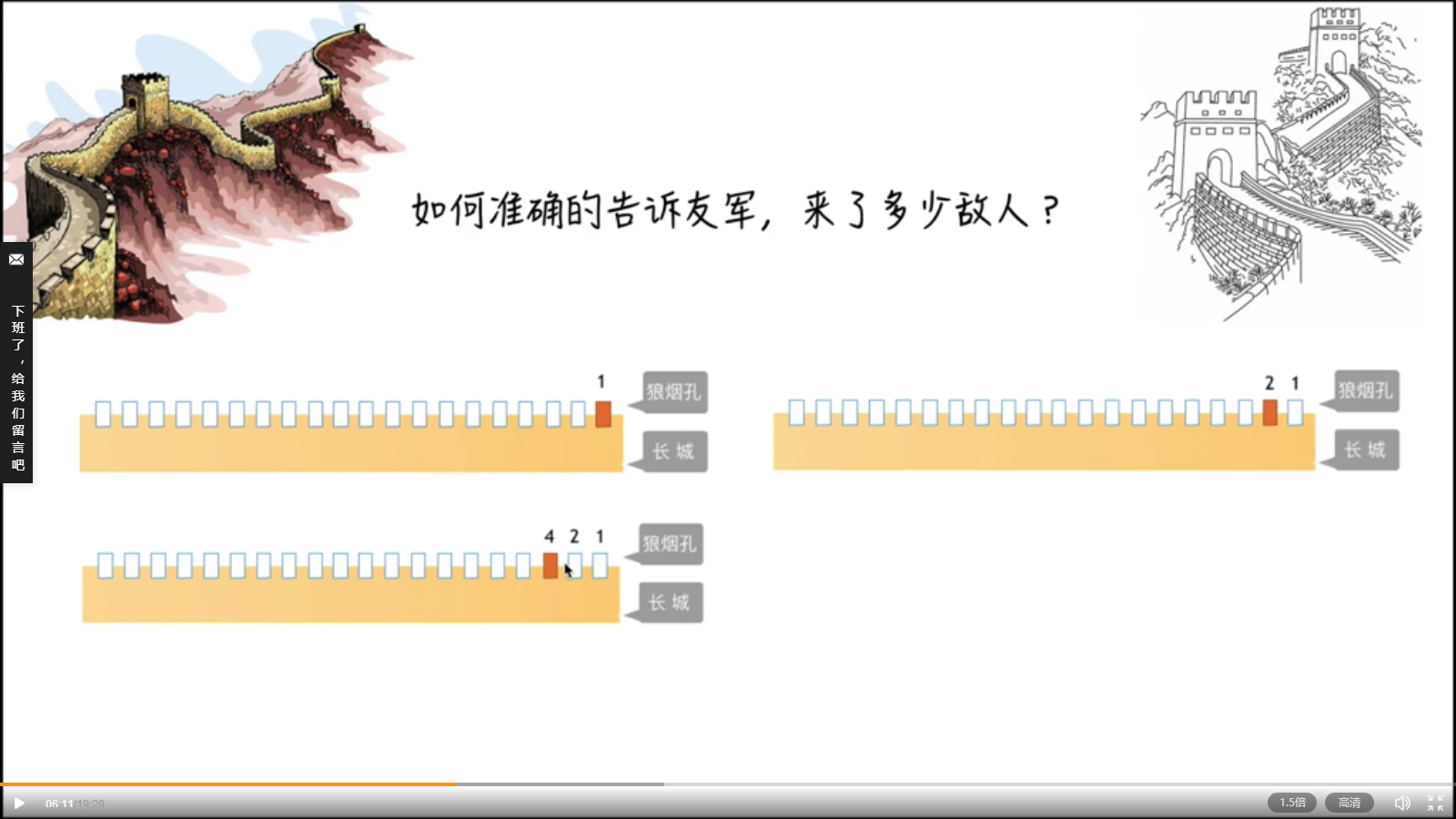
2、需求:如何准确地告诉“友军”,来了多少敌人?!
- 点狼烟告知-来了敌人来,赶紧来支援;
- 1根烟代表一个敌人,来了五百个敌人,点了500根狼烟,自己把自己烧死啦!
- 优化思路:点1根烟,代表1~10敌人;点2根烟,代表100~500;点3根烟,代表1000~5000人;点4根烟,代表5000~10000人;但问题是无法“精确地”表示来了多少敌人。

30 二进制转换(二)
1、1,2,4,8,16,32,64...按照2**n次方,来“准确地”表示敌人的数量;
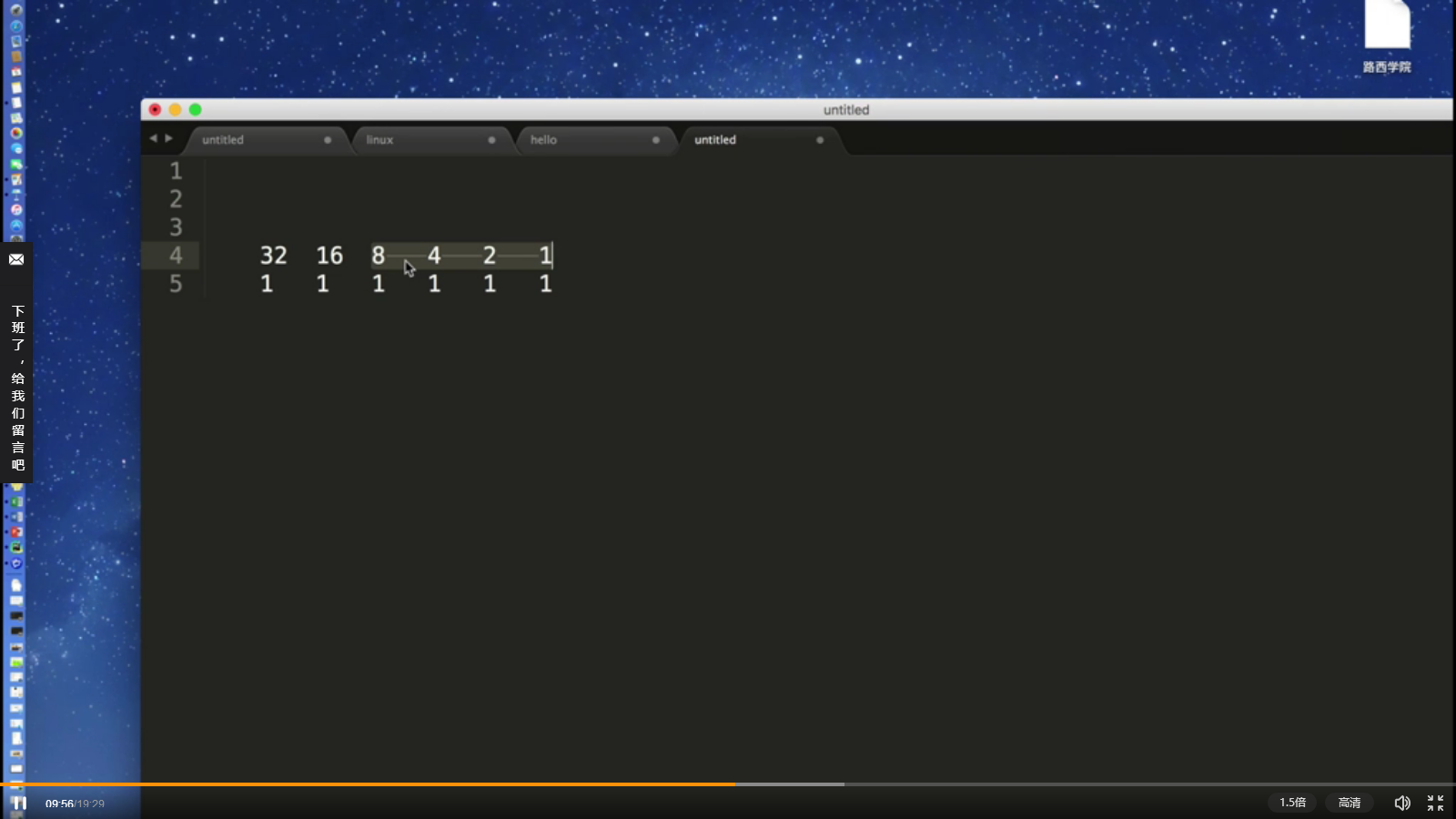
2、“二进制”与“十进制”之间的相互转换;

31 二进制转换小练习讲解
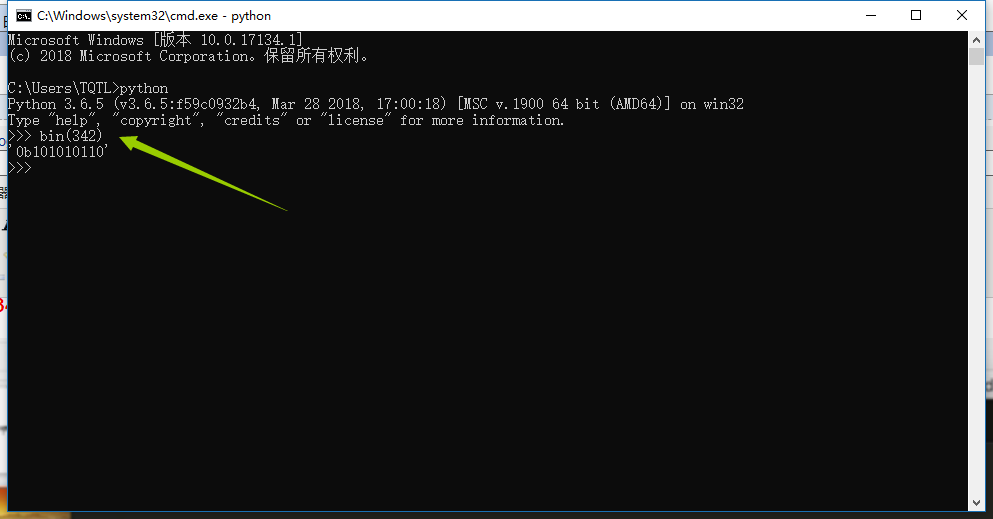
1、如何计算342的“二进制”数;
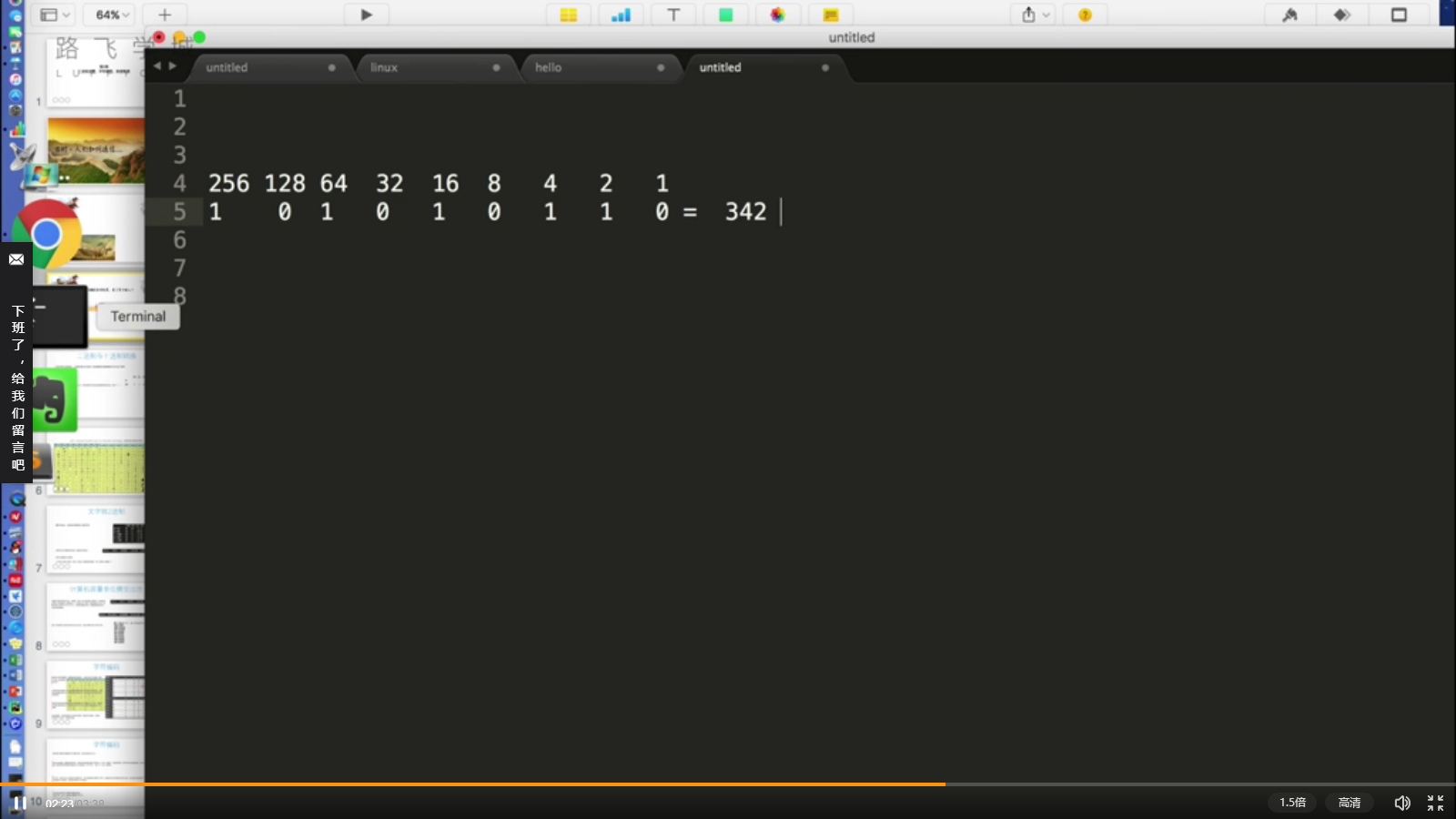
2、使用Python内置方法-bin(n)计算;
32 ASCII码与二进制
1、如何让计算机表示-文字、符号、字母等字符?!(搞一张对应关系表-ASCII码表)

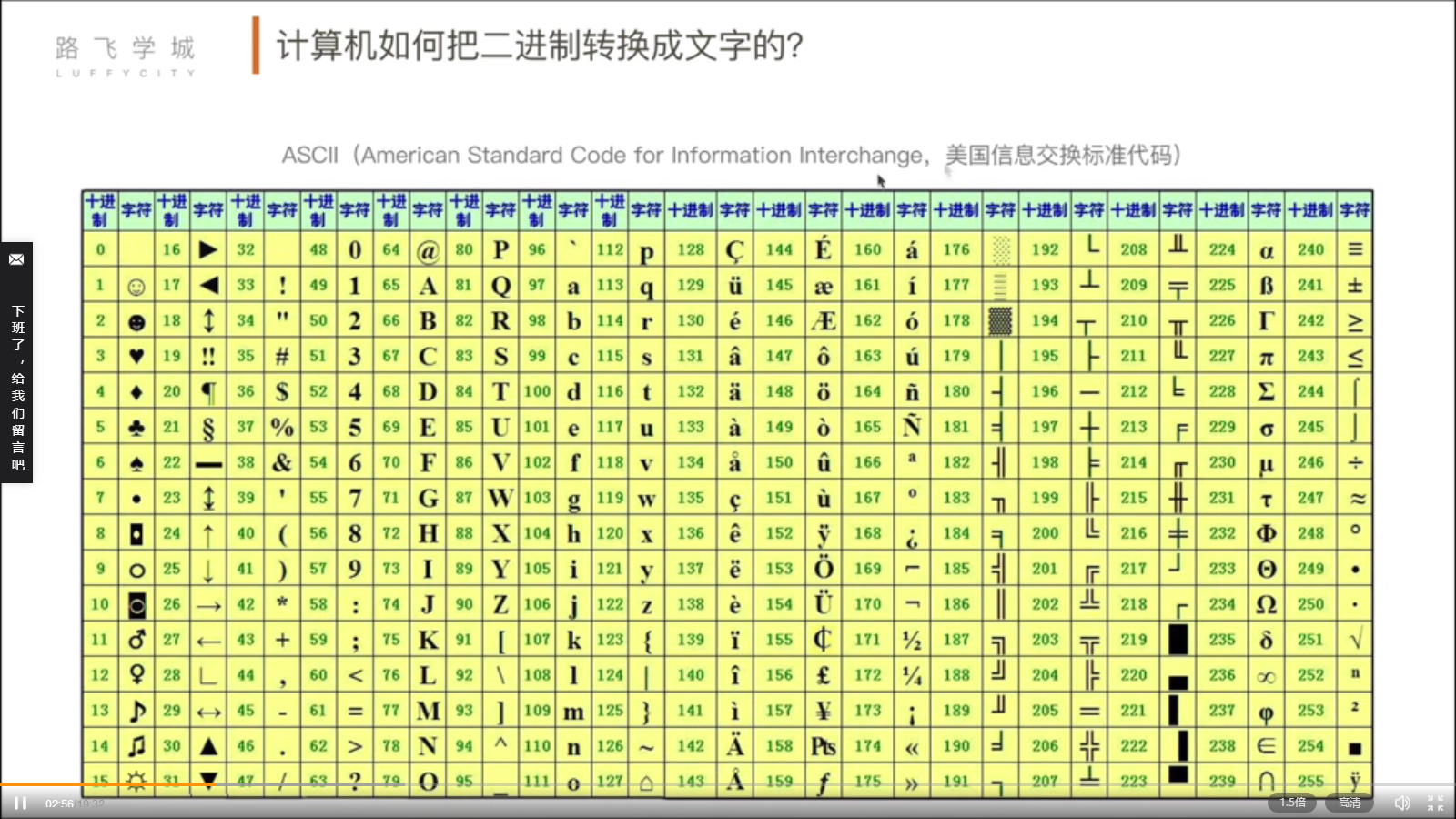
2、文字转二进制;
- 论断句的重要性与必要性;
- 写作文,需要使用“标点符号”来断句;
- 使用空格来断句,空格也是二进制;
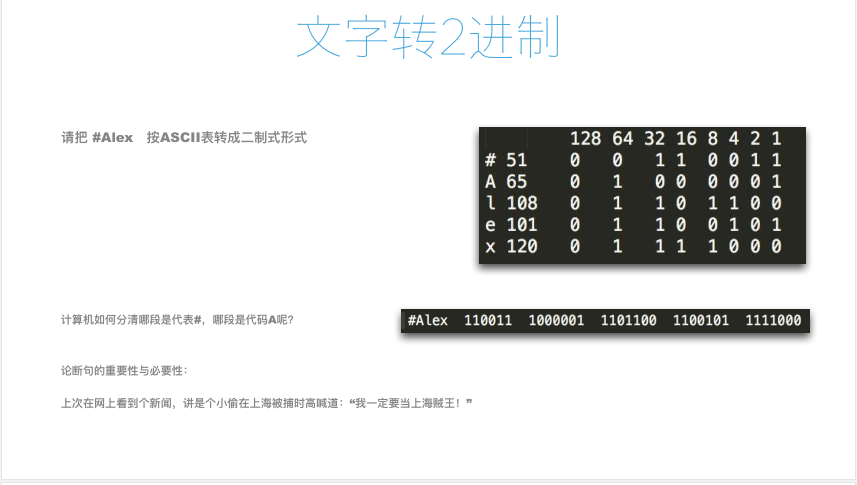
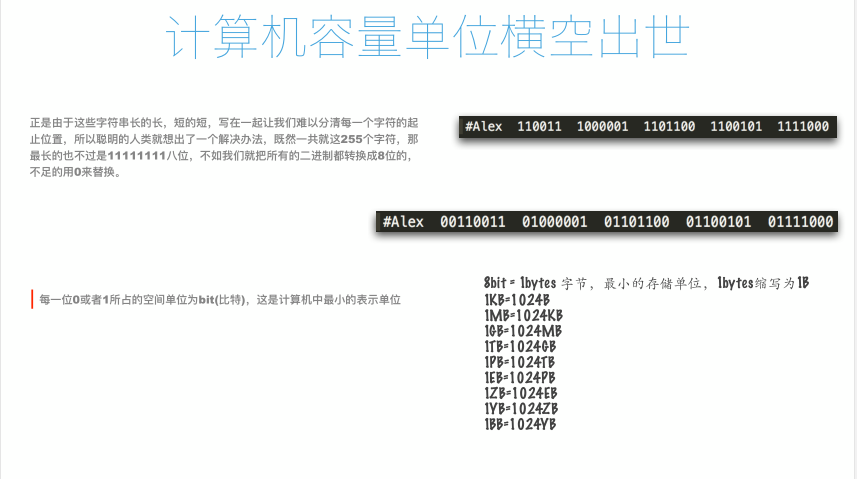
3、ASCII码表里,最多的字符是255位,使用8位来表示1个字符;
- 每一位0或者1的空间单位为bit(比特),这是计算机中“最小的表示单位”;
- 8bit = 1bytes,是计算机中“最小的存储单位”,1bytes缩写为1B;
33 字符串编码的烟花
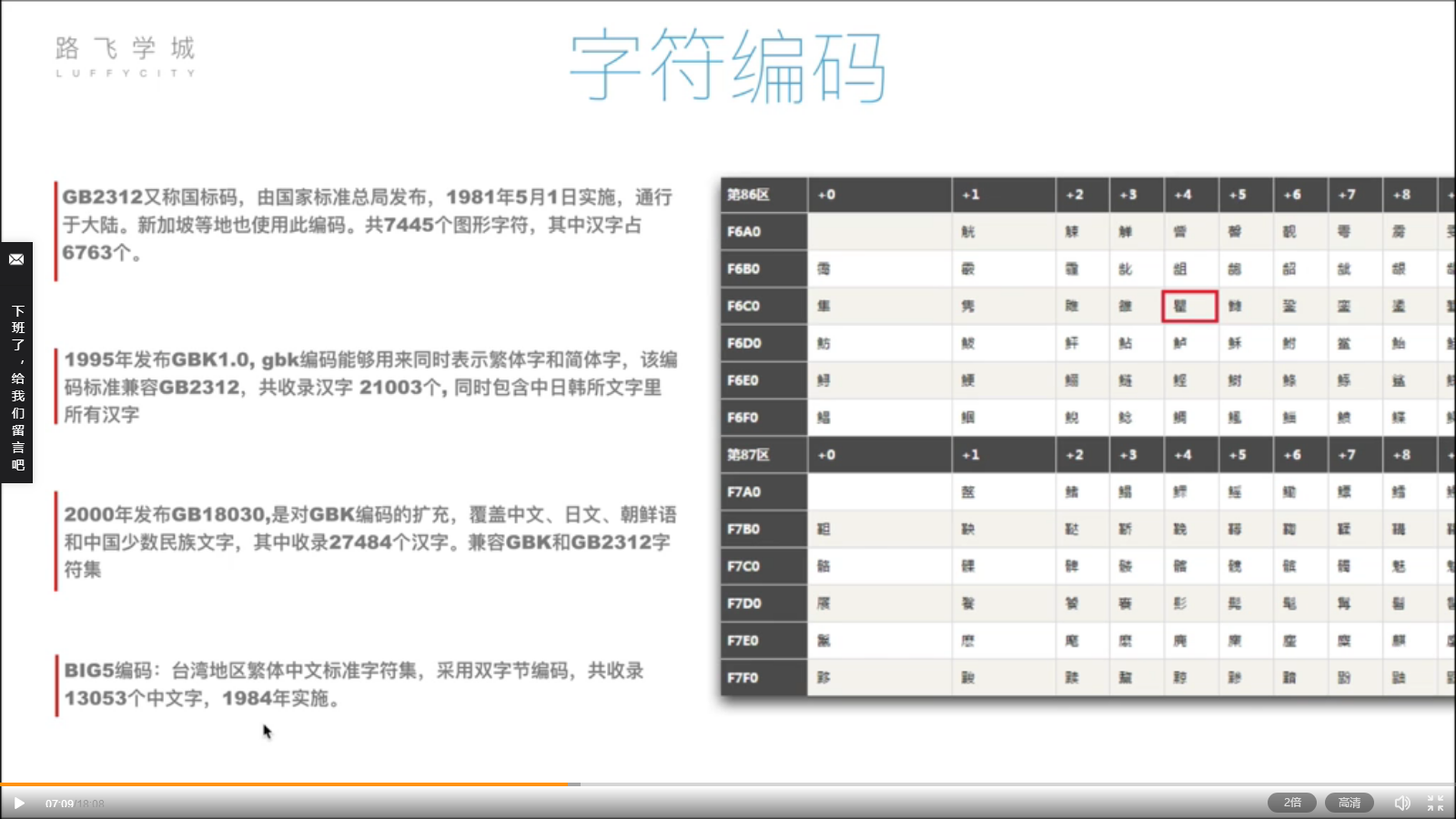
1、ASCII码表里只有英文,没有我们中文呀!作为中国人表示不服,我们自己搞一张“类ASCII码表”。
- 中文字符编码:GB2312横空出世,但是仅表示部分中文,仅支持简体中文;
- GBK1.0,兼容GB2312,Windows系统默认编码是GBK;
- GB18030,向上兼容;
- 台湾BIG5;
2、世界上有200多个国家和地区,我们每个国家搞一套“类ASCII”码表,这就乱套了;相互出口软件使用很麻烦;

3、那么问题又来了,我美国人表示不服呀,使用Unicode使我的存储容量变成了2倍呢,so,UTF-8(可变长字符编码)横空出世;
- UTF-8是对Unicode的压缩和优化;
- 我党规定,出口到我国的字符编码必须支持GBK;
34 Python里使用的编码
1、字符编码对“编程”的影响;
- Python2.x默认不支持中文,但是不代表不支持中文;
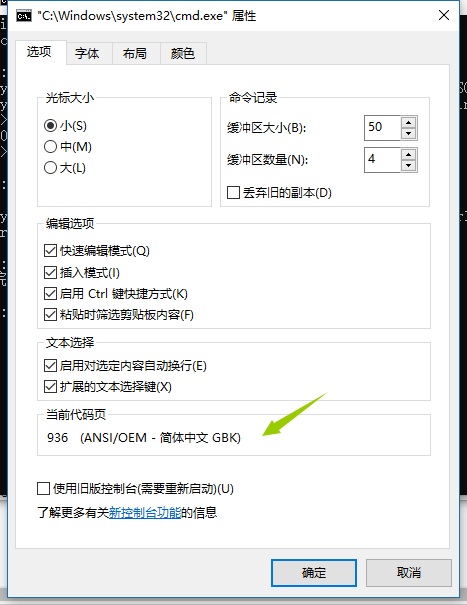
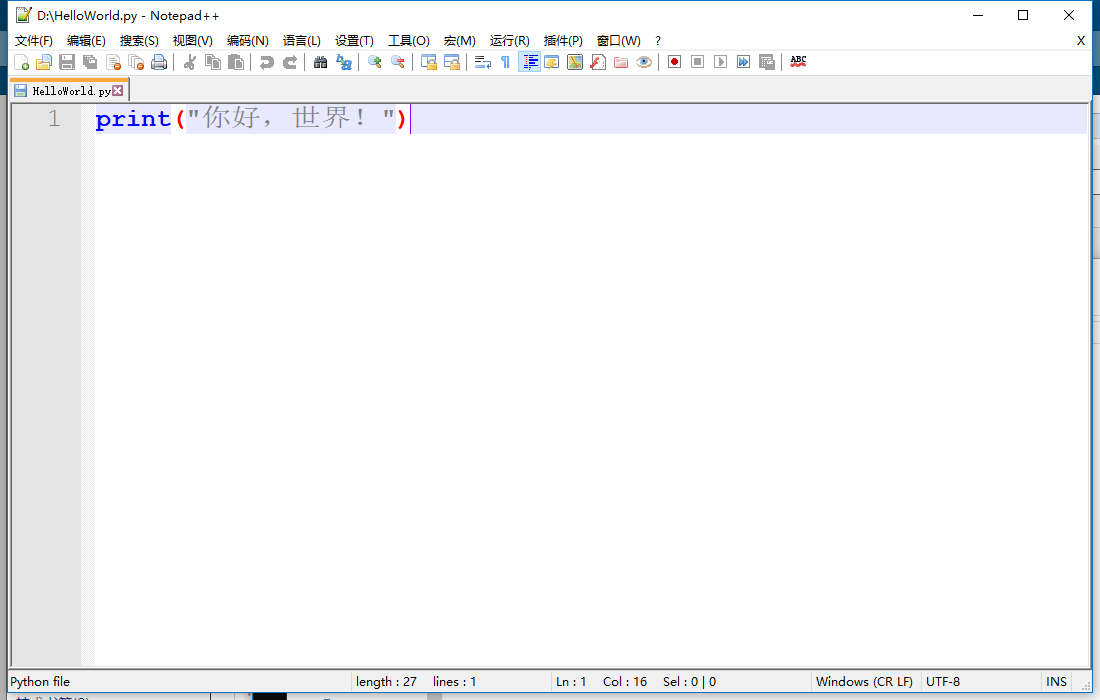
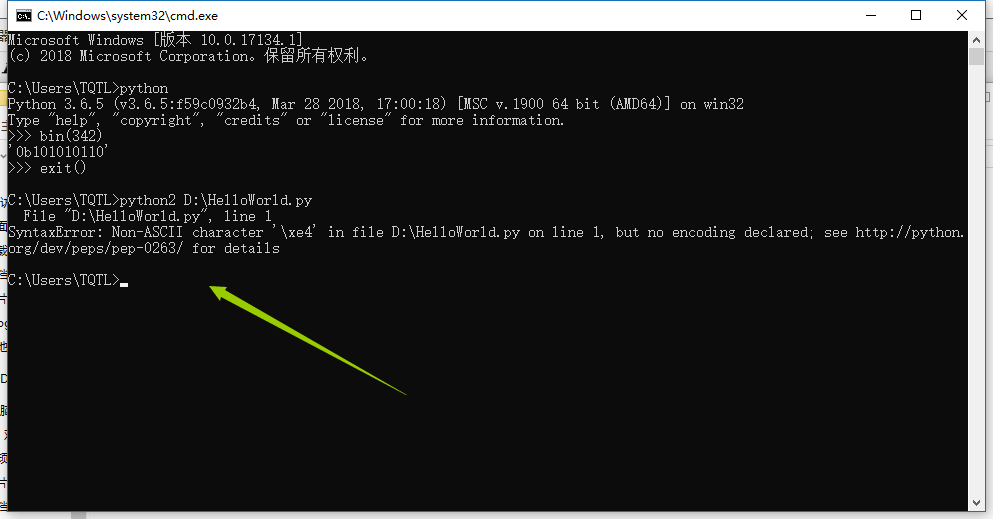
- Python2.x写中文,需要在文件头部特别指定(声明)编码格式;
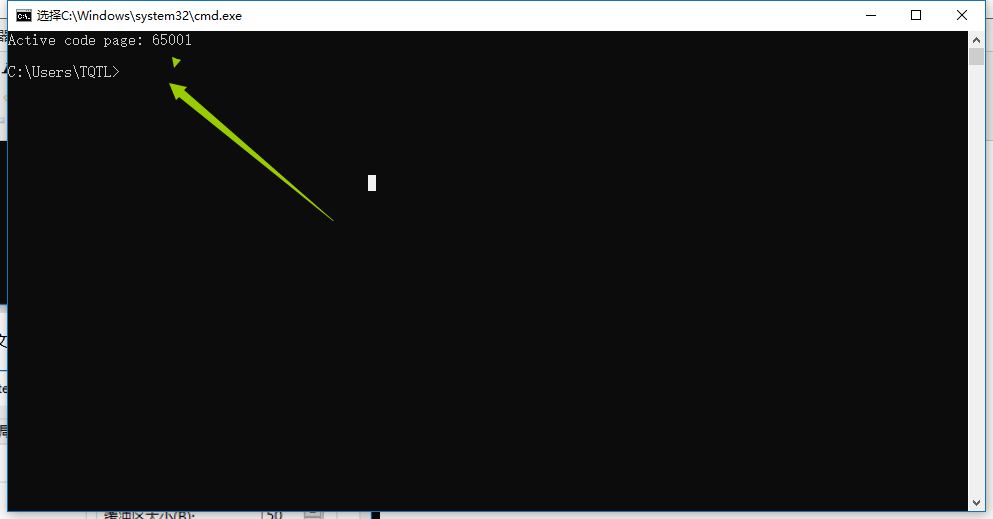
命令窗口修改编码,CMD编码修改方法:https://jingyan.baidu.com/article/e75aca85440f01142edac636.html


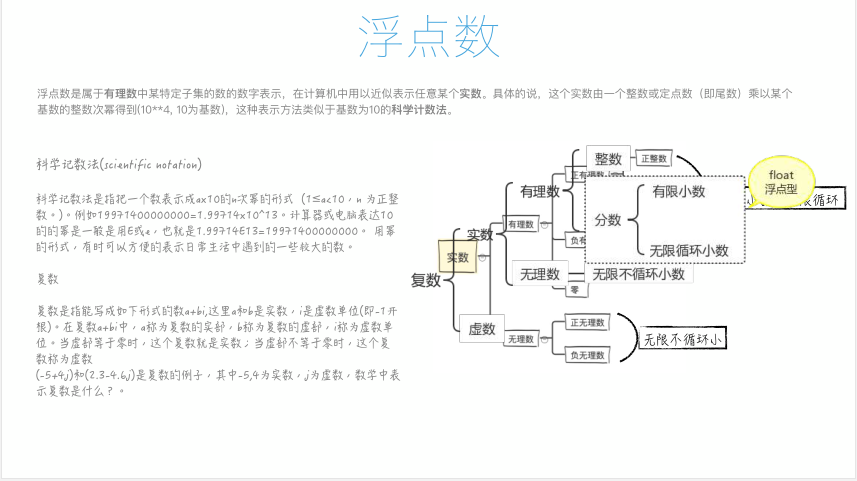
35 浮点数和科学计数法
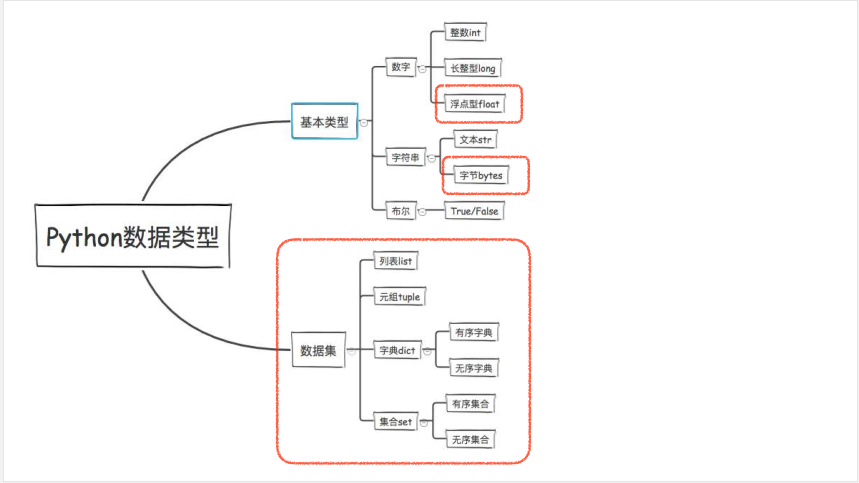
1、Python中的数据类型;
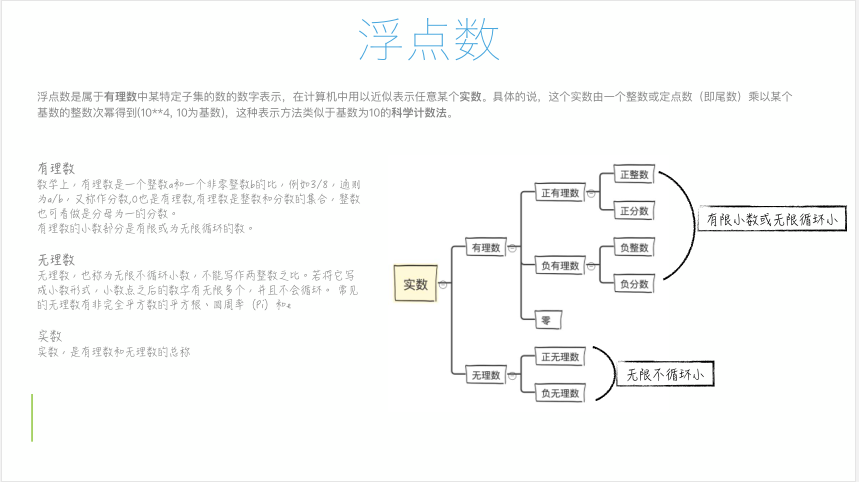
2、实数的引入;
- 有理数(有限或无限循环小数);
- 无理数(无限不循环小数);
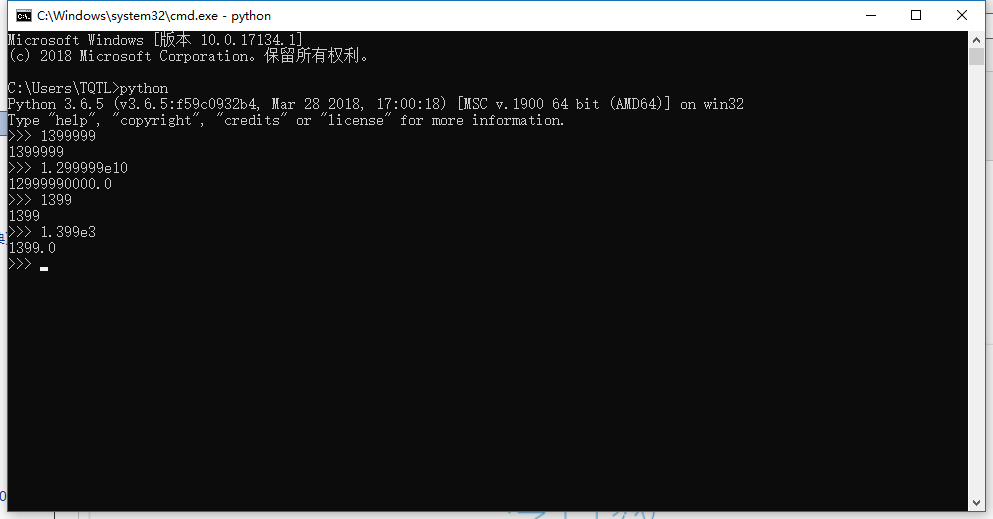
3、浮点数的定义以及科学计数法;
- 科学计数法;
- 复数(数学中的概念z=a+bi),Python中表示(5+4j);
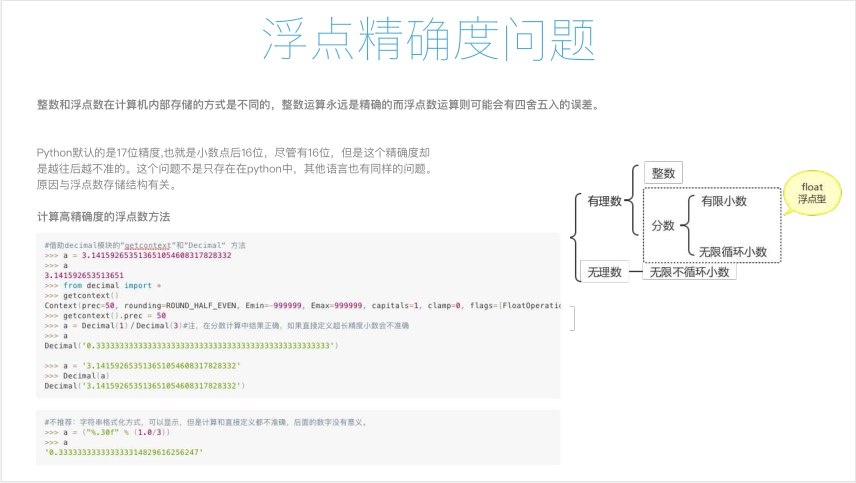
36 浮点数的精确度问题
- 在Python中,浮点数只能精确的存储16位;
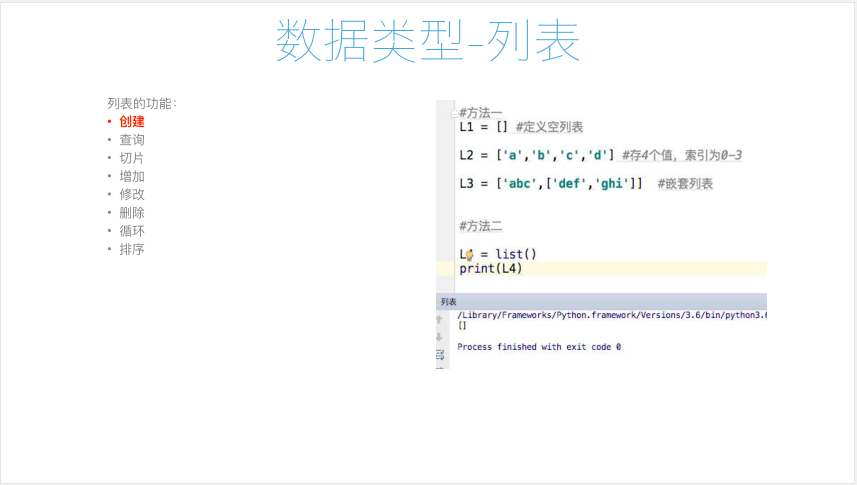
37 列表类型
1、如何通过一个变量存储公司所有员工的名字?!
- names = “shanshan longling alex”,但是无法查询和修改name的值;

2、列表的创建方法;

1 #! /usr/bin/env python 2 # -*- coding:utf-8 -*- 3 #__author__ = "tqtl" 4 # Date:2018/5/7 5 6 #列表的功能之创建 7 #方法1-变量赋值; 8 L1 = [] #定义一个空列表 9 L2 = ['','b','c','d']#存储4个值,索引为0~3 10 L3 = ['abc',['def','ghi']]#嵌套列表 11 #方法2,使用python内置方法进行创建; 12 L2 = list() 13 print(L2)
3、列表的查询;
1 #! /usr/bin/env python
2 # -*- coding:utf-8 -*-
3 #__author__ = "tqtl"
4 # Date:2018/5/7
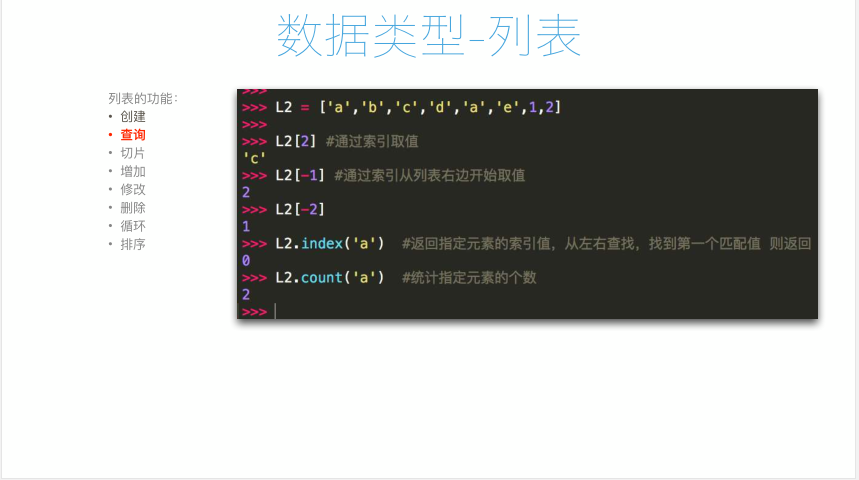
5 L2 = ['a','b','c','d','a','e',1,2]#定义一个列表L2;
6 print(L2[2])#通过索引取值;
7 print(L2[-1])#通过索引从列表右边开始取值;
8 print(L2.index('a'))#返回指定元素的”索引值“,从左向右查找,找到第一个匹配字符;
9 print(L2.count('a'))#统计指定元素的个数;
4、列表的切片;
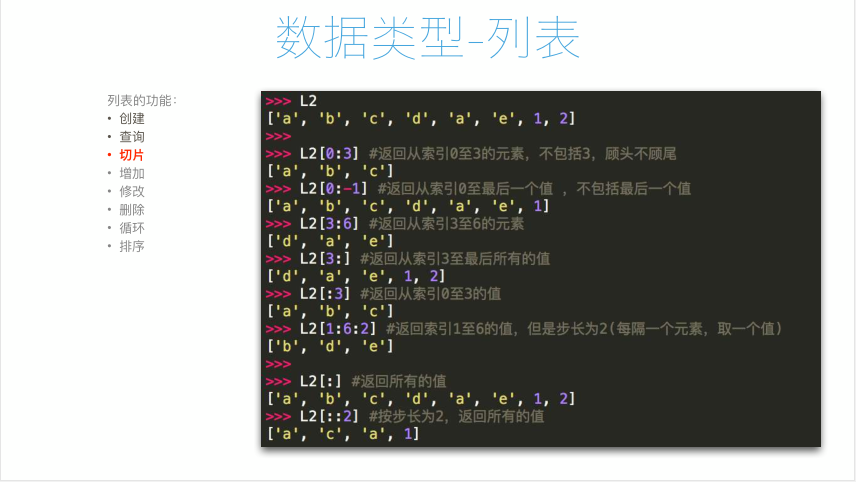
1 #! /usr/bin/env python 2 # -*- coding:utf-8 -*- 3 #__author__ = "tqtl" 4 # Date:2018/5/7 5 #把列表当做一个面包,进行切分查找; 6 L3 = ['Shanshan','Longting','Alex',1,3,4,4,5,6,7,8,8,9,9,0,0,2,3,4,4] 7 print(L3[0-2])#注意,0-2为-2,等价于print[L3[-2]] 8 print(L3[0-3])#注意,0-3为-3,等价于print[L3[-3]] 9 print(L3[0:3])#结果为:['Shanshan', 'Longting', 'Alex'],顾头不顾尾; 10 print(L3[3:7])#结果为:[1, 3, 4, 4], 11 print(L3[-1:-5])#结果为空列表,切片的原则是,只能从左到右进行切分; 12 print(L3[-5:-1])#结果为:[0, 2, 3, 4],仍旧顾头不顾尾; 13 print(L3[-5:0])#结果为:[]空列表 14 print(L3[-5:])#结果为:[0, 2, 3, 4, 4] 15 print(L3[0:3])#结果为:['Shanshan', 'Longting', 'Alex'] 16 print(L3[:3])#结果为:['Shanshan', 'Longting', 'Alex'] 17 print(L3[:])#结果为:['Shanshan', 'Longting', 'Alex', 1, 3, 4,4, 5, 6, 7, 8, 8, 9, 9, 0, 0, 2, 3, 4, 4] 18 print(L3[:7])#结果为:['Shanshan', 'Longting', 'Alex', 1, 3, 4, 4] 19 print(L3[0:7:2])#结果为:['Shanshan', 'Alex', 3, 4],引入步长的概念 20 print(L3[:7:1])#结果为:['Shanshan', 'Longting', 'Alex', 1, 3, 4, 4] 21 print(L3[:-1:3])#结果为:['Shanshan', 1, 4, 7, 9, 0, 4] 22 print(L3[:-1:4])#结果为:['Shanshan', 3, 6, 9, 2] 23 print(L3[:])#结果为:['Shanshan', 'Longting', 'Alex', 1, 3, 4, 4, 5, 6, 7, 8, 8, 9, 9, 0, 0, 2, 3, 4, 4] 24 print(L3[::2])#结果为:['Shanshan', 'Alex', 3, 4, 6, 8, 9, 0, 2, 4]
5、列表的增加及修改;
1 #! /usr/bin/env python
2 # -*- coding:utf-8 -*-
3 #__author__ = "tqtl"
4 # Date:2018/5/7
5 #列表的插入与追加
6 L4 = ['Shanshan', 'Longting', 'Alex', 1, 3, 4, 4, 5, 6, 7, 8, 8, 9, 9, 0, 0, 2, 3, 4, 4]
7 L4.append('Peiqi')#append方法是“追加”的意思,只能插入到结尾;
8 print(L4)#结果为:['Shanshan', 'Longting', 'Alex', 1, 3, 4, 4, 5, 6, 7, 8, 8, 9, 9, 0, 0, 2, 3, 4, 4, 'Peiqi']
9 L4.insert(0,'abc')#insert方法是根据索引值,进行插入数据;
10 print(L4)
11 L4.insert(2,'Alex')
12 print(L4)
13 #列表的修改-根据索引值修改;
14 print(L4[3])
15 L4[3] = "龙婷"#列表值的修改,使用重新赋值的方法;
16 print(L4)#结果为:['abc', 'Shanshan', 'Alex', '龙婷', 'Alex', 1, 3, 4, 4, 5, 6, 7, 8, 8, 9, 9, 0, 0, 2, 3, 4, 4, 'Peiqi']
17 #列表的修改-根据索引值的范围修改;
18 print(L4[4:6])#通过索引范围,进行批量修改;
19 L4[4:6] = "JACK LIU"# "JACK LIU"分别表示'J', 'A', 'C', 'K', ' ', 'L', 'I', 'U'注意中间有空格,总结8个元素;
20 print(L4)#结果为:['abc', 'Shanshan', 'Alex', '龙婷', 'J', 'A', 'C', 'K', ' ', 'L', 'I', 'U', 3, 4, 4, 5, 6, 7, 8, 8, 9, 9, 0, 0, 2, 3, 4, 4, 'Peiqi']

38 列表类型-修改及插入
1、append、insert等方法;
1 #! /usr/bin/env python
2 # -*- coding:utf-8 -*-
3 #__author__ = "tqtl"
4 # Date:2018/5/7
5 #列表的插入与追加
6 L4 = ['Shanshan', 'Longting', 'Alex', 1, 3, 4, 4, 5, 6, 7, 8, 8, 9, 9, 0, 0, 2, 3, 4, 4]
7 L4.append('Peiqi')#append方法是“追加”的意思,只能插入到结尾;
8 print(L4)#结果为:['Shanshan', 'Longting', 'Alex', 1, 3, 4, 4, 5, 6, 7, 8, 8, 9, 9, 0, 0, 2, 3, 4, 4, 'Peiqi']
9 L4.insert(0,'abc')#insert方法是根据索引值,进行插入数据;
10 print(L4)
11 L4.insert(2,'Alex')
12 print(L4)
13 #列表的修改-根据索引值进行重新赋值修改;
14 print(L4[3])
15 L4[3] = "龙婷"#列表值的修改,使用重新赋值的方法;
16 print(L4)#结果为:['abc', 'Shanshan', 'Alex', '龙婷', 'Alex', 1, 3, 4, 4, 5, 6, 7, 8, 8, 9, 9, 0, 0, 2, 3, 4, 4, 'Peiqi']
17 #列表的修改-根据索引值的范围修改
18 print(L4[4:6])#通过索引范围,进行批量修改;
19 L4[4:6] = "JACK LIU"# "JACK LIU"分别表示'J', 'A', 'C', 'K', ' ', 'L', 'I', 'U'注意中间有空格,总结8个元素;
20 print(L4)#结果为:['abc', 'Shanshan', 'Alex', '龙婷', 'J', 'A', 'C', 'K', ' ', 'L', 'I', 'U', 3, 4, 4, 5, 6, 7, 8, 8, 9, 9, 0, 0, 2, 3, 4, 4, 'Peiqi']

39 列表类型-其他方法
1、列表的循环(for及while的区别);
1 #! /usr/bin/env python
2 # -*- coding:utf-8 -*-
3 #__author__ = "tqtl"
4 # Date:2018/5/7
5 #列表的循环和排序
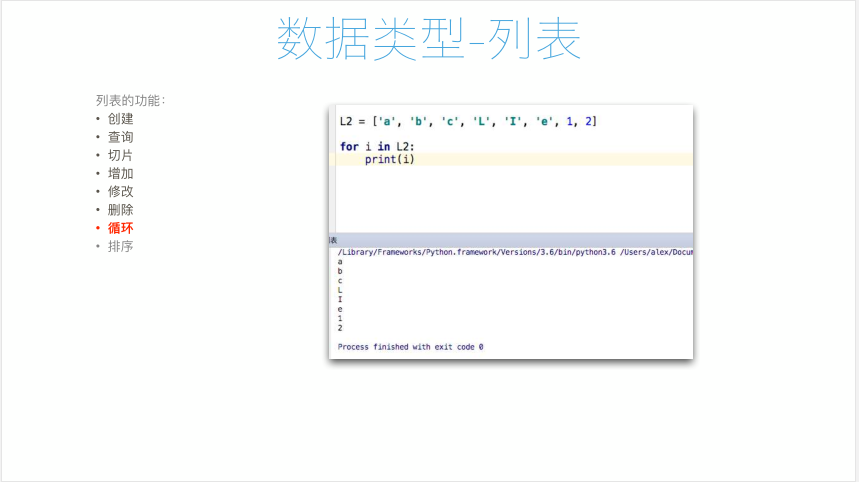
6 L6 = ['Shanshan', 'Peiqi', ' ', 'L', 'I', 'U', 3,4, 5, 6, 7,7, 8, 8, 9, 9, 0, 0, 2, 3, 4, 4]
7 for i in L6:#i是临时变量;for循环;
8 print('loop',i)
9 #range(10),与Python2.x不同,
10 for i in range(10):
11 print(i)
12 #for循环与while循环的区别;while循环可以是死循环,但for循环有边界,不会出现死循环,区别在于有无循环边界;
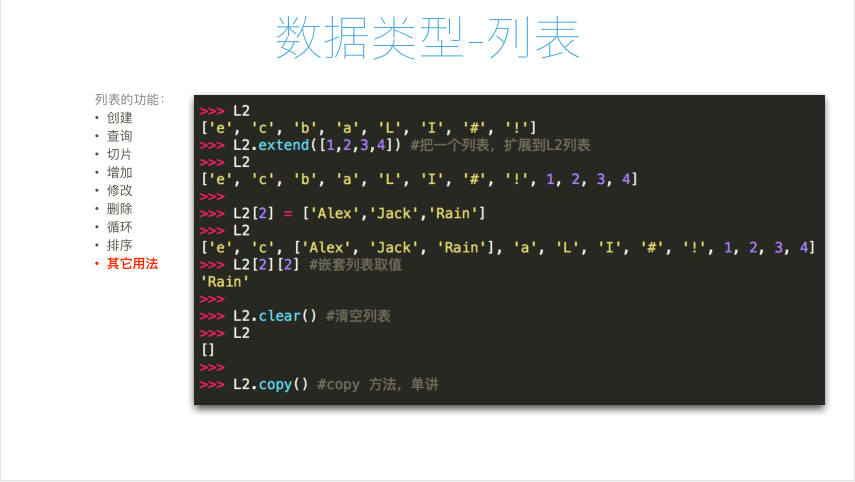
2、列表的排序、反转、清空、拓展及复制;
1 #! /usr/bin/env python
2 # -*- coding:utf-8 -*-
3 #__author__ = "tqtl"
4 # Date:2018/5/7
5 L7 = ['a','e','b',1,34,2,'c']
6 #L7.sort()#使用sort方法来排序;
7 #print(L7)#TypeError: '<' not supported between instances of 'int' and 'str',int和str没有关系,所以无法排序;
8 L7.remove(1)#使用remove方法,删除指定元素值;
9 L7.remove(34)
10 L7.remove(2)
11 print(L7)
12 L7.append('z')#列表的追加;
13 L7.insert(1,'y')#根据索引值进行增加;
14 L7.insert(3,'A')
15 print(L7)
16 L7.sort()#列表的排序sort方法;
17 print(L7)
18 L7.insert(3,'#')
19 L7.insert(3,'*')
20 L7.insert(3,'!')
21 print(L7)#其实,排序规则是按照列表中元素的位于ASCII码表中的位置进行排列显示的;
22 L7.reverse()#列表的反转reverse方法与sort互逆;
23 print(L7)
24 L8 = [1,2,4]#新建一个列表;
25 L7.extend(L8)#列表的拓展方法;
26 print(L7)
27 L9 = L7.copy()#列表的copy方法;
28 print(L9)
29 L7.clear()#列表的清空,注意与删除操作不相同,前者是对内容级别进行操作;后者是列表级别操作;
30 print(L7)#

40 列表练习题讲解
1、练习题;

41 列表练习题讲解2
1、 练习题;
#!/usr/bin/env python # -*- coding:utf-8 -*- # Project: DevelopBasic # Software: PyCharm # DateTime: 2018-10-10 22:19 # File: 12-列表练习题讲解.py # __author__: 天晴天朗 # Email: [email protected] # 1、创建一个空列表,命名为names,往里面天添加old_driver,rain,jack,shanshan,peiqi,black,black_girl元素; names = [] names.append("old_driver") names.append("rain") names.append("jack") names.append("shanshan") names.append("peiqi") names.append("black") names.append("black_girl") print("No.01:", names) # No.01 ['old_driver', 'rain', 'jack', 'shanshan', 'peiqi', 'black', 'black_girl'] # 2、往names列表里black_girl前面插入一个alex; names.insert(names.index("black_girl"), "alex") print("No.02:", names) # No.02: ['old_driver', 'rain', 'jack', 'shanshan', 'peiqi', 'black', 'alex', 'black_girl'] # 3、把shanshan的名字改成中文"姗姗"; names[names.index("shanshan")] = "姗姗" print("No.03:", names) # No.03: ['old_driver', 'rain', 'jack', '姗姗', 'peiqi', 'black', 'alex', 'black_girl'] # 4、往names列表里rain的后面插入一个子列表["oldboy", "oldgirl"] names.insert(names.index("rain") + 1, ["oldboy", "oldgirl"]) print("No.04:", names) # No.04: ['old_driver', 'rain', ['oldboy', 'oldgirl'], 'jack', '姗姗', 'peiqi', 'black', 'alex', 'black_girl'] # 5、返回peiqi的索引; print("No.05:", names.index("peiqi")) # No.05: 5 # 6、创建新列表[1,2,3,4,2,5,6,2],合并入names列表; nums = list(range(1, 5)) nums.append(2) nums.append(5) nums.append(6) nums.append(2) combine = names + nums print("No.06:", combine) # # No.06: ['old_driver', 'rain', ['oldboy', 'oldgirl'], 'jack', '姗姗', 'peiqi', 'black', 'alex', 'black_girl', 1, 2, 3, 4, 2, 5, 6, 2] # 7、取出names列表中索引4-7的元素 print("No.07:", names[4:8]) # No.07: ['姗姗', 'peiqi', 'black', 'alex'] # # 8、取出names列表中索引2-10的元素,步长为2 print("No.08:", names[2:11:2]) # No.08: [['oldboy', 'oldgirl'], '姗姗', 'black', 'black_girl'] # 9、取出names列表中最后3个元素; print("No.09:", names[-3:]) # No.09: ['black', 'alex', 'black_girl'] print("此处为分隔符0".center(120, '-')) # 10、循环names列表,打印每个元素的索引值和元素; # 方法01: count = 0 for name in names: print("No.10-1", count, name) count += 1 """ 0 old_driver 1 rain 2 ['oldboy', 'oldgirl'] 3 jack 4 姗姗 5 peiqi 6 black 7 alex 8 black_girl """ print("此处为分隔符1".center(120, '-')) # 方法02:enumerate(names) 枚举; print(enumerate(names)) # 直接取索引,<enumerate object at 0x107a17a68> for name in enumerate(names): print("No.10-2", name) # 打印的值是一个小列表 print("此处为分隔符2".center(120, '-')) """ (0, 'old_driver') (1, 'rain') (2, ['oldboy', 'oldgirl']) (3, 'jack') (4, '姗姗') (5, 'peiqi') (6, 'black') (7, 'alex') (8, 'black_girl') """ for index, name in enumerate(names): print("No.10-3", index, name) # 打印的值不是列表了 print("此处为分隔符3".center(120, '-')) """ 0 old_driver 1 rain 2 ['oldboy', 'oldgirl'] 3 jack 4 姗姗 5 peiqi 6 black 7 alex 8 black_girl """ # 11、循环names列表,打印每个元素的索引值和元素,当索引值为偶数,把对应的元素改成-1 for index, name in enumerate(names): if index % 2 == 0: # 代表偶数 names[index] = -1 print("No.11", index, name) # 打印的值不是列表了; print("No.11", names) print("此处为分隔符".center(120, '-')) # # 12、names里有3个2,请返回第2个2的索引值,不要人肉数,要动态找(提示,找到第一个2的位置,在此基础上再找第2个) # 方法一: names = ['cuixiaozhao', 2, 'cuixiaoshan', 'cuixiaosi', 2, 'cuixiaolei', 1, 3, 4, 2] count = 0 for i in names[names.index(2) + 1:]: if i == 2: print("第二个2的index:", names.index(2) + 1 + count) break count += 1 # 方法二: first_index = names.index(2) # 第一个2的索引值 new_list = names[first_index + 1:] # 从第一个2的位置+1 开始切片,重新赋值给新的列表 second_index = new_list.index(2) # 查询2 在新的列表中的索引值 last_index = first_index + second_index + 1 # 第一个的索引值+ '第二个的索引值+切片时候的+1' print("第二个2 的index:", last_index) # 13、现有商品列表如下: products = [['Iphone8', 6888], ['MacPro', 14800], ['小米6', 2499], ['Coffee', 31], ['Book', 80], ['Nike Shoes', 799]] """ 需打印出这样的格式 ---------商品列表---------- 0. Iphone8 6888 1. MacPro 14800 2. 小米6 2499 3. Coffee 31 4. Book 80 5. Nike Shoes 799 """ print("商品列表".center(60, '-')) for index, product in enumerate(products): # print("%s %s %s" % (str(index) + ".", product[0], product[1])) print("%s. %s %s" % (index, product[0], product[1])) # 14、写一个循环,不断的问用户想买什么,用户选择一个商品编号,就把对应的商品添加到购物车里,最终用户输入q退出时,打印购物车里边的商品列表 shopping_cart = [] while True: for index, product in enumerate(products): print("%s. %s %s" % (index, product[0], product[1])) want = input("您想要买什么,请输入对象商品编号: 例<2>,输入<q>退出 >>") if want.isdigit(): want = int(want) if want > len(products) - 1 and want < 0: print("输入商品编号错误,没有该编号!!") else: shopping_cart.append(products[want]) print("已经将%s加入购物车" % products[want]) elif want == "q": if len(shopping_cart) > 0: print("您已购买以下商品:") for index, i in enumerate(shopping_cart): print("%s. %s %s" % (index, i[0], i[1])) break else: print("输入不正确!") continue # 知识补充: # 判断字符串是否是一个数字; "33".isdigit() # 查看列表的长度; len(names) # break 退出也可以用标志位来设置True False 进行循环判断退出; # 标志位; flag = True while flag: if 100: pass else: flag = False # 标志位 设置False 结束循环;
42 深浅copy
1、深copy,完全克隆一份,不推荐使用,借助Python工具箱:import copy;
2、浅copy(浅层次的克隆一份);
#!/usr/bin/env python # -*- coding:utf-8 -*- # Project: DevelopBasic # Software: PyCharm # DateTime: 2018-10-11 12:17 # File: 14-深浅拷贝.py # __author__: 天晴天朗 # Email: [email protected] "" """ Python3中存在的深浅拷贝; """ # 变量举例: a = 1 b = a print("a:", a) print("b:", b) print("id(a):", id(a)) print("id(b):", id(b)) print("这里是分隔符".center(100, '-')) a = 2 print("b:", b) print("a:", a) print("id(b):", id(b)) print("id(a):", id(a)) print("这里是分隔符".center(100, '-')) # 列表举例: names = ['cuixiaozhao', 'cuixiaoshan', 'cuixiaosi', 'cuixiaolei', 'cuixiaoyan'] names2 = names print("names:", names) # names: ['cuixiaozhao', 'cuixiaoshan', 'cuixiaosi', 'cuixiaolei', 'cuixiaoyan'] print("names2:", names2) # names2: ['cuixiaozhao', 'cuixiaoshan', 'cuixiaosi', 'cuixiaolei', 'cuixiaoyan'] print("names的id值:", id(names), "names2的id值:", id(names2)) # names的id值: 4422633096 names2的id值: 4422633096 print(id(names[1]), id(names2[1])) # 4560274288 4560274288 names[0] = "崔晓昭" print(names) print(names2) print("这里是分隔符".center(100, '-')) print("此时的names:", names) # 此时的names: ['崔晓昭', 'cuixiaoshan', 'cuixiaosi', 'cuixiaolei', 'cuixiaoyan'] names_copy2 = names.copy() print("names的浅拷贝之names_copy2:", names_copy2) print("names的id值:", id(names), "names_copy2的id值:", id(names_copy2)) print(id(names[1]), id(names_copy2[1])) # 4480082800 4480082800 print("这里是分隔符3".center(100, '-')) names.append(['崔天晴', '崔天朗']) names_copy2.append(['cxz', 'cxs']) names_copy3 = names.copy() print(names) print(names2) print(names_copy2) print(names_copy3) """ ['崔晓昭', 'cuixiaoshan', 'cuixiaosi', 'cuixiaolei', 'cuixiaoyan', ['崔天晴', '崔天朗']] ['崔晓昭', 'cuixiaoshan', 'cuixiaosi', 'cuixiaolei', 'cuixiaoyan', ['崔天晴', '崔天朗']] ['崔晓昭', 'cuixiaoshan', 'cuixiaosi', 'cuixiaolei', 'cuixiaoyan', ['cxz', 'cxs']] ['崔晓昭', 'cuixiaoshan', 'cuixiaosi', 'cuixiaolei', 'cuixiaoyan', ['崔天晴', '崔天朗']] """ print(id(names)) print(id(names2)) print(id(names_copy2)) print(id(names_copy3)) """ 4410074760 4410074760 4410074824 4409935048 """ names[-1][0] = "2020" print(names) print(names2) print('-----------------***********--------------------------') print(names_copy2) print(names_copy3) print('-----------------***********--------------------------') print(id(names[-1][0])) print(id(names2[-1][0])) print(id(names_copy2[-1][0])) print(id(names_copy3[-1][0])) """ 4537801168 4537801168 4537800552 4537801168 """ # 不建议使用deepcopy; import copy n4 = copy.deepcopy(names) print(n4) print(names) print('----------------------') names[-1][0] = 19930911 print(names) print(n4) print(id(names[-1][0])) print(id(n4[-1][0]))
43 字符串类型讲解
1、字符串的创建;
s = ‘Hello,beauty!How are you?’
- 有序;
- 不可变;
2、字符串的方法(魔法);

1 #! /usr/bin/env python
2 # -*- coding:utf-8 -*-
3 #__author__ = "tqtl"
4 # Date:2018/5/8
5 s = "Hello World!"
6 print(s.capitalize())#Hello world!首字母大写;
7 print(s.center(50,'*'))#*******************Hello World!*******************
8 print(s.center(50,'-'))#-------------------Hello World!-------------------
9 print(s.count('o'))#全局统计字符o的数量;2;
10 print(s.count('o',0,5))#指定范围统计字符o的数量;1;
11 print(s.endswith('!'))#返回布尔值True;
12 print(s.endswith('!jfdskl'))#返回布尔值False;
13 s2 = 'a\tb'
14 print(s2)#a、b;默认字符长度;
15 print(s2.expandtabs(20))#a、b中间指定数量的字符长度;;
16 print(s.find('o'))#4
17 print(s.find('ofdjskl'))#-1
18 print(s.find('o',0,5))#4
19 print(s.find('o',0,4))#-1,顾头不顾尾;
20 print(s.find('W',0,120))#6,顾头不顾尾;
21 s3 = "my name is {0},i am {1} years old."
22 print(s3.format('TQTL',26))#my name is TQTL,i am 26 years old.
23 s3 = "my name is {name},i am {age} years old."
24 #print(s3.format('TQTL',26))#KeyError: 'name'
25 print(s3.format(name='cuixiaozhao',age=26))#my name is cuixiaozhao,i am 26 years old.
44 字符串类型讲解2
1、字符串的方法(魔法)讲解2;
1 #! /usr/bin/env python
2 # -*- coding:utf-8 -*-
3 #__author__ = "tqtl"
4 # Date:2018/5/8
5 s = "Hello World!"
6 print(s.index('o'))#返回字符的索引值,默认是全局查找:4
7 #print(s.index('o',8,10))#ValueError: substring not found;指定范围查找;
8 s1 = "1993"
9 print(s1.isalnum())#True,判断长得像不像数字;
10 s2 = "cxz19930911"
11 print(s2.isalnum())#True;
12 s3 = "cuixiaozhao"
13 print(s1.isalpha())#False;
14 print(s2.isalpha())#False;
15 print(s3.isalpha())#True;
16 s4 = '18.88'#首先它得是字符串,此处不可以为s4 = 18.88;
17 s5 ='18'#首先它得是字符串,此处不可以为s4 = 18;
18 print(s4.isdecimal())#False;
19 print(s5.isdecimal())#True;
20 print(s4.isdigit())#False;
21 print(s5.isdigit())#True;
22 s6 = "names"
23 print(s.isidentifier())#判断是否为合法的变量;
24 print(s4.isidentifier())
25 print(s6.isidentifier())
26 print('cxs19920619'.isnumeric())#判断是否仅有数字在里面;
27 print('19930911'.isnumeric())#判断是否仅有数字在里面;
28 print('19971224'.isprintable())#Linux中一切皆文件,判断是不是可以打印,文本文件;
29 print('19971224fdsf'.isprintable())#Linux中一切皆文件,判断是不是可以打印,文本文件;
30 print('A B C'.isspace())#判断是不是空格space空格的意思;
31 print('A BC'.isspace())
32 print(''.isspace())
33 print(' '.isspace())
34 s7 = "Important News"
35 s8 = "HAPPY FAMILY"
36 print(s7.istitle())#新闻标题单词首字母均为大写,判断是不是title;
37 print(s7.isupper())#判断是不是全为大写;
38 print(s8.isupper())#判断是不是全为大写;
39 names = ['alex','jack','rain']
40 print(''.join(names))#alexjackrain;
41 print('-'.join(names))#alex-jack-rain;
42 print('*'.join(names))#alex*jack*rain;
43 print('^'.join(names))#alex^jack^rain;
44 s9 = 'Hello World!'
45 s10 = 'hello world!'
46 s11 = 'HELLO WOLRD!'
47 print(s9.ljust(50,'-'))#Hello World!--------------------------------------
48 print(s9.rjust(50,'-'))#--------------------------------------Hello World!
49 print(s9.upper())#HELLO WORLD!
50 print(s9.lower())#hello world!
51 print(s11.isupper())#True
52 print(s10.islower())#True
53 s12 = '\n hello world!你好 世界 '
54 print(s12.strip())#hello world!你好 世界 ;去掉左右两侧多余字符;
55 print(s12.lstrip())#hello world!你好 世界;
56 print(s12.rstrip())#hello world!你好 世界;
57 str_in = 'abcdef'
58 str_out = '!@#$%^'
59 s13 = 'xzabcdsaef'
60 table = str.maketrans(str_in,str_out)#先生成对应关系表;
61 print(table)#{97: 33, 98: 64, 99: 35, 100: 41, 101: 94, 102: 40}
62 print(s13.translate(table))#xz!@#$s!%^;
63 s14 = 'cuixiaozhao'
64 print(s14.partition('o'))#('cuixia', 'o', 'zhao')
65 print(s14.replace('a','MM'))
66 print(s14.replace('a','MM',1))#指定更换的次数;
67 print(s14.rfind('o'))#从右侧开始查找;
68 print(s14.rfind('fdsafd'))#从右侧开始查找,找不到返回值-1;
69 print(s14.rfind('fdsafd',0,10))#从右侧开始查找,指定范围,找不到返回值-1;
70 #print(s14.rindex('fdsafd',0,10))#从左侧开始查找,指定范围,找不到会报错:ValueError: substring not found;
71 #print(s14.rindex('o',0,5))#从右侧开始查找,指定范围,找不到会报错:ValueError: substring not found;
72 print(s14.rindex('o',0,10))#从右侧开始查找,指定范围,返回索引值;
73 s15 = 'Hello World!'
74 print(s15.rpartition('o'))#('Hello W', 'o', 'rld!')
75 print(s15.split('e'))#['H', 'llo World!']
76 print(s15.split('o'))#['Hell', ' W', 'rld!']
77 print(s15.split('l'))#['He', '', 'o Wor', 'd!']
78 print(s15.rsplit('o',1))#['Hello W', 'rld!'],指定次数分割;
79 s16 = 'a\nb\nalex\ncuixiaozhao'
80 print(s16.splitlines())#['a', 'b', 'alex', 'cuixiaozhao']按照行来进行分割;
81 s17 = 'hello world'
82 print(s17.startswith('he'))#True
83 print(s17.startswith('He'))#False
84 print(s17.startswith('fdsk'))#False
85 print(s17.endswith('fdsk'))#False
86 print(s17.endswith('rld'))#True
87 print(s17.endswith('RLD'))#Flase
88 print(s17.swapcase())#HELLO WORLD,小写变成大写;
89 print(s17.title())#Hello World,将字符串编程title类型的;
90 print(s17.zfill(20))#000000000hello world,将字符串变成20位长度,不够的用0填充;
91 #isdigit,replace,find,count,strip,center,split,format,join

45 元组类型(只读列表)
1、元组类型的创建;
names = ('cuixiaozhao','cuixiaosi','cuixiaoshan')
特性:
- 不可变;
- 元组本身不可变,但是元组中如果还包含其他可变元素,如list,这些元素可以被改变;
1 names = ('cuixiaozhao',['a','b'],1,2,[1,2,3,4,5])#创建names元组;
2 names[1][0]='TQTL'#对names元组中的子列表进行修改;
3 print(names)#('cuixiaozhao', ['TQTL', 'b'], 1, 2, [1, 2, 3, 4, 5])
功能:
- index;
- count;
- 切片(相当于查询,同list操作);
使用场景:
- 显示性地告知别人,此处的数据不可被修改;
- 数据库连接配置信息等;

46 hash函数
1、Hash初识;

2、hash用途;
- 文件签名(唯一确定文件内容);
- md5加密;
- 密码验证;
47 字典类型及特性
1、使用list存储这些信息的痛点;
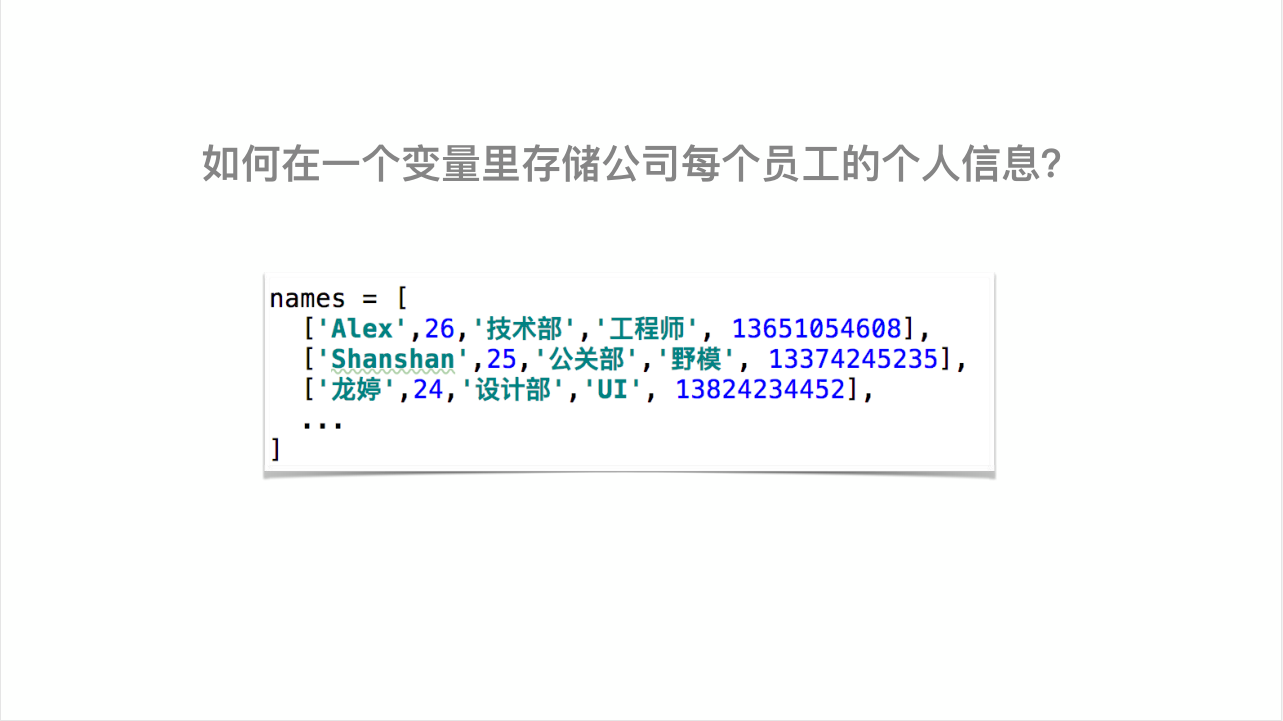
2、以《新华词典》的思想来引出“数据类型-字典”;
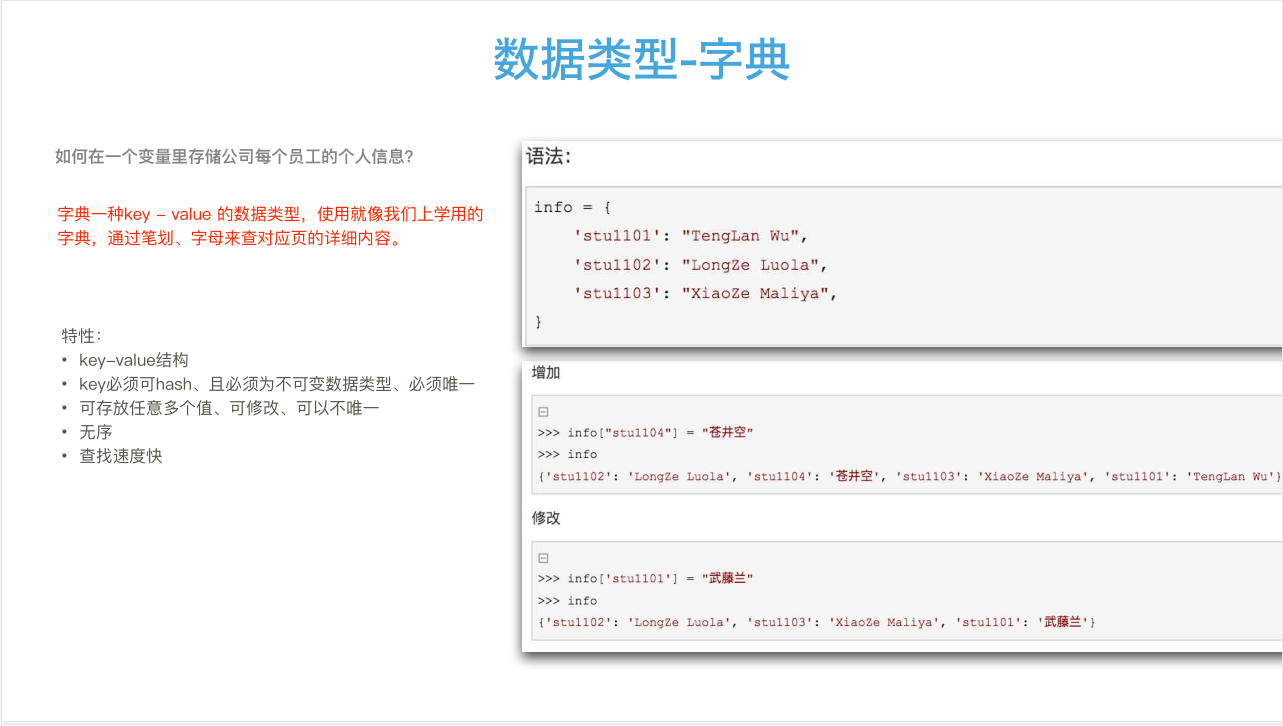
1 #! /usr/bin/env python
2 # -*- coding:utf-8 -*-
3 #__author__ = "tqtl"
4 # Date:2018/5/8 7:25
5 #需求:存储公司60~70人的姓名、年龄、性别、手机号、部门、岗位、家乡....
6 names = [
7 ['Alex',26,'技术部','工程师',13651054608],
8 ['Shanshan',25,'公关部','野模',13374245235],
9 ['龙婷',24,'设计部','UI',13824234452],
10 ]
11 #print(names.index('龙婷'))#ValueError: '龙婷' is not in list;
12 print(names.index(['龙婷',24,'设计部','UI',13824234452]))#妈的,我都知道这么多信息了,我查询它(索引2)有病呀!
13 info = {}#定义一个空字典;
14 info = {
15 '龙婷':[24,'design','UI',13811221893],
16 'shanshan':[25,'PR','wild model',13681590211]
17 }
18 print(info['龙婷'])#返回值:[24, 'design', 'UI', 13811221893]
19 #修改信息
20 mod = info['龙婷'][1]='设计部'
21 print(mod)#设计部
22 print(info)#{'龙婷': [24, '设计部', 'UI', 13811221893], 'shanshan': [25, 'PR', 'wild model', 13681590211]}
23 #字典的查找速速快的原因,因为hash查找速度快;
24 print(hash('龙婷'))#哈希值:7073574030525645556;
25 print(hash('Shanshan'))#哈希值:232415886153887154;
26 numbers = [13334,-32424,25532,2364]
27 numbers.append(3355)
28 numbers.append(123334)
29 print(numbers)#[13334, -32424, 25532, 2364, 3355, 123334]
30 numbers.sort();
31 print(numbers)#[-32424, 2364, 3355, 13334, 25532, 123334]
32 #通过折半查找,就可很快滴查找到值(二分查找);

48 字典类型的详细方法
1、字典dict的内置方法;
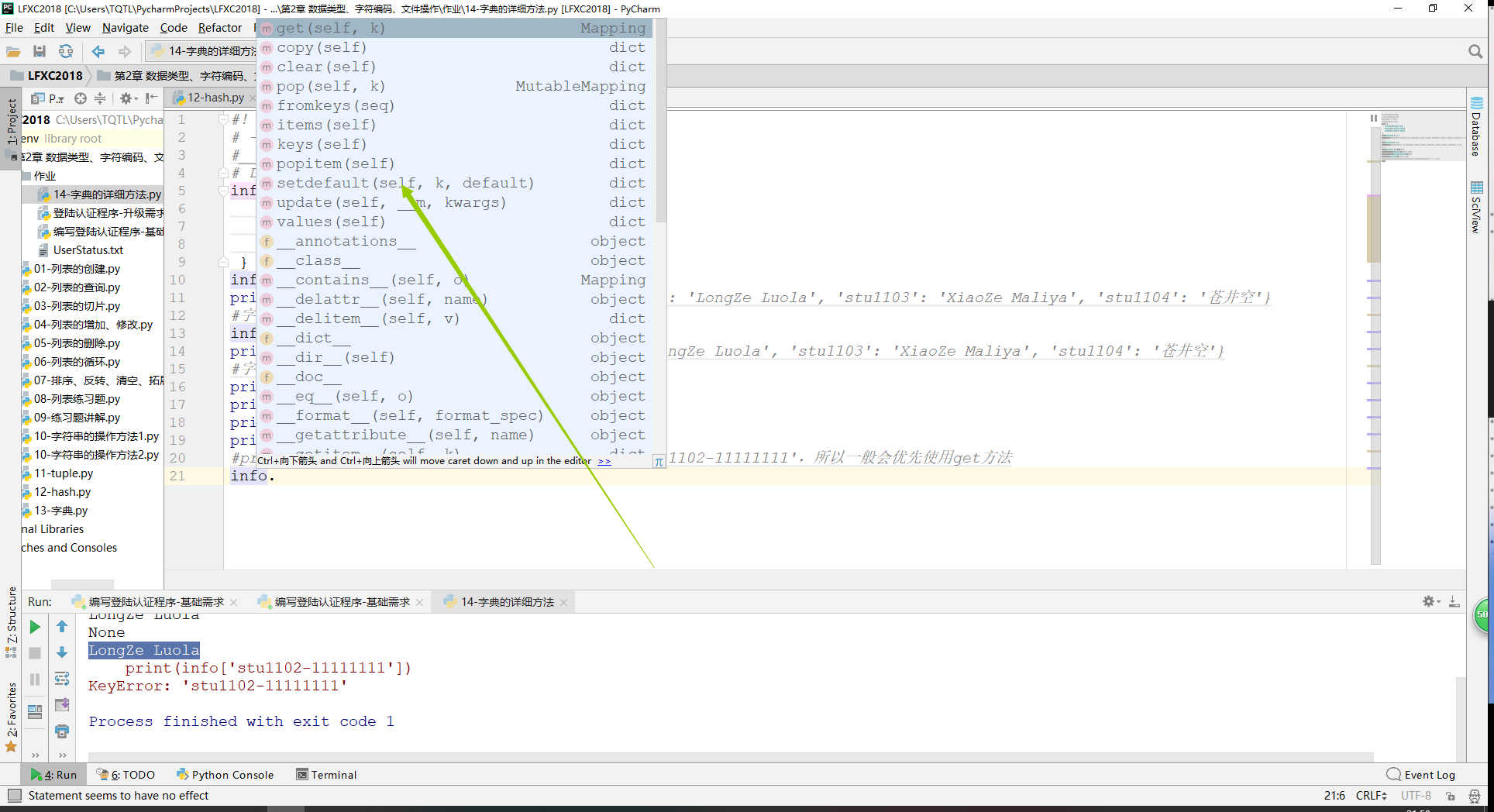
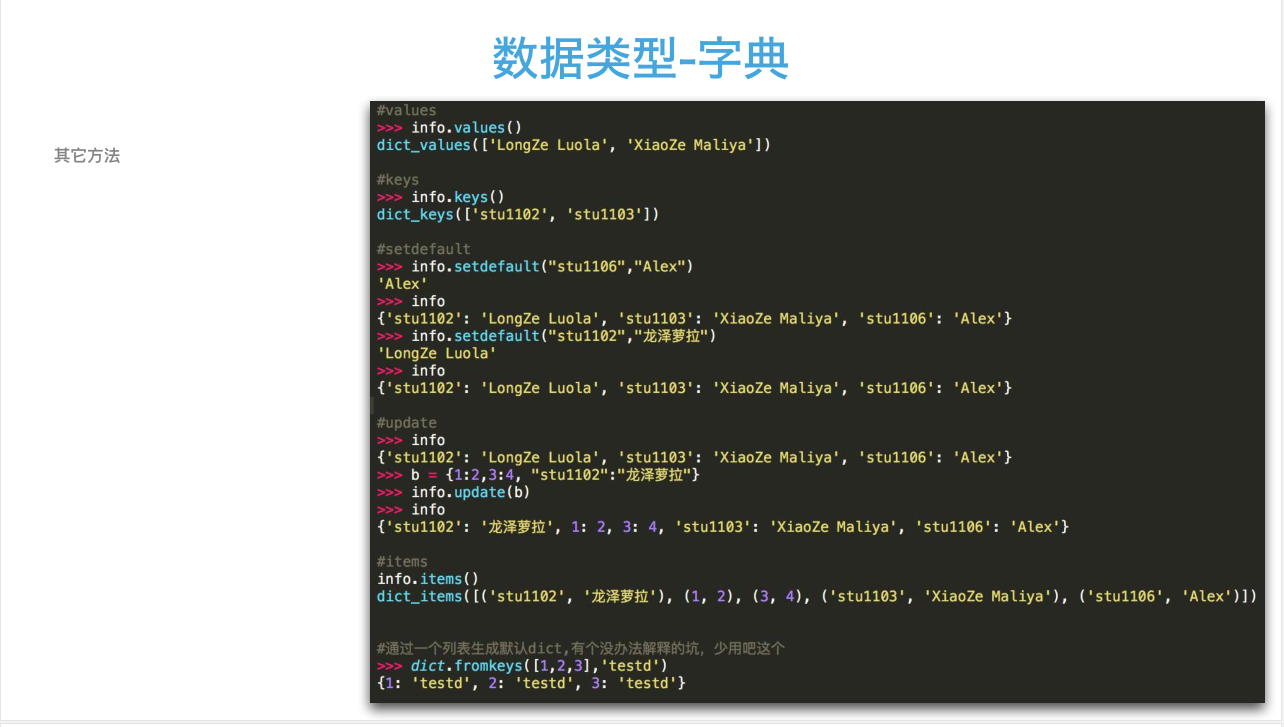

1 #! /usr/bin/env python
2 # -*- coding:utf-8 -*-
3 #__author__ = "tqtl"
4 # Date:2018/5/8 21:51
5 info = {
6 'stu1101':'TengLan Wu',
7 'stu1102': 'LongZe Luola',
8 'stu1103': 'XiaoZe Maliya'
9 }#定义了字典info,如何判断,{}、[]、()的区别;
10 info['stu1104'] = "苍井空"#字典的添加,有则重新赋值,无则新增一键值对;
11 print(info)#{'stu1101': 'TengLan Wu', 'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1104': '苍井空'}
12 #字典的修改;
13 info['stu1101'] = "武藤兰"#通过键值,进行字典的重新赋值,进行相应的修改;
14 print(info)#{'stu1101': '武藤兰', 'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1104': '苍井空'}
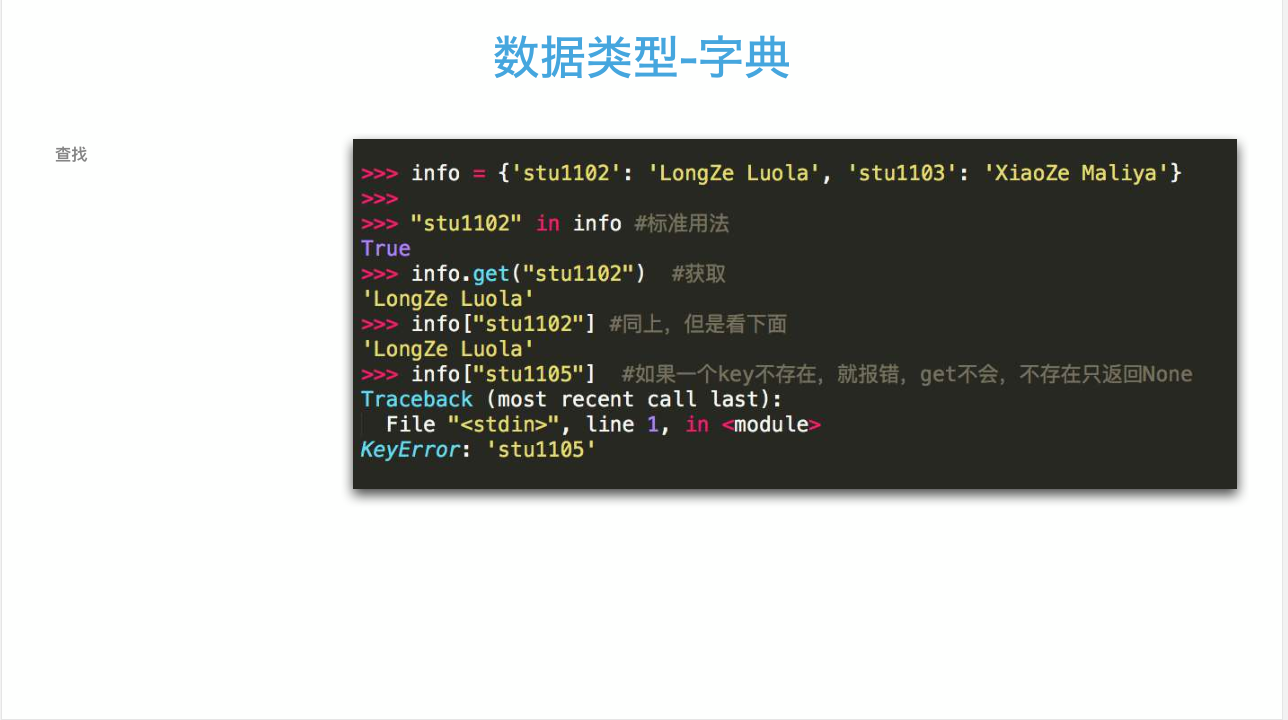
15 #字典的查询;
16 print("stu1102" in info)#True
17 print(info.get('stu1102'))#LongZe Luola;
18 print(info.get('stu110211111111'))#None;
19 print(info['stu1102'])#LongZe Luola;不推荐使用,如果不存在会报错!
20 #print(info['stu1102-11111111'])#KeyError: 'stu1102-11111111',所以一般会优先使用字典中的get方法;
21 #print(info.pop())#TypeError: pop expected at least 1 arguments, got 0
22 print(info.pop('stu1101'))#pop方法删除字典元素,有返回值:武藤兰;
23 print(info)#{'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1104': '苍井空'}
24 #字典的添加
25 info[4] = 'Number1'#增加;
26 info[3] = 'Number2'
27 info[2] = 'Number3'
28 info[1] = 'Number4'
29 print(info)#{'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1104': '苍井空', 4: 'Number1', 3: 'Number2', 2: 'Number3', 1: 'Number4'}
30 #字典的删除操作;
31 print(info.popitem())#字典是无序的,随机删除字典中的元素;(1, 'Number4');
32 print(info.popitem())#字典是无序的,随机删除字典中的元素;(2, 'Number3');
33 for i in range(100):
34 info[i]= 'Number'+(str(i))#for循环向字典中增添数据;
35 print(info.popitem())#popitem是无序随机删除;
36 print(info.popitem())
37 print(info.popitem())
38 print(info.popitem())
39 print(info.popitem())
40 print(info.popitem())
41 del info[56]#使用字典的del 方法进行删除;
42 #多级字典的嵌套——字典里面套字典;
43 av_catalog = {
44 "欧美":{
45 "www.youporn.com": ["很多免费的,世界最大的","质量一般"],
46 "www.pornhub.com": ["很多免费的,也很大","质量比yourporn高点"],
47 "letmedothistoyou.com": ["多是自拍,高质量图片很多","资源不多,更新慢"],
48 "x-art.com":["质量很高,真的很高","全部收费,屌丝请绕过"]
49 },
50 "日韩":{
51 "tokyo-hot":["质量怎样不清楚,个人已经不喜欢日韩范了","听说是收费的"]
52 },
53 "大陆":{
54 "1024":["全部免费,真好,好人一生平安","服务器在国外,慢"]
55 }
56 }
57 #字典的修改;
58 av_catalog["大陆"]["1024"][1] = "没关系,可以使用爬虫爬取下来,后续我们会讲爬虫课程的,注意认真听讲哦srapy"#多级字典的逐级查找;
59 print(av_catalog)
60 #{'欧美': {'www.youporn.com': ['很多免费的,世界最大的', '质量一般'], 'www.pornhub.com': ['很多免费的,也很大', '质量比yourporn高点'
61 # ], 'letmedothistoyou.com': ['多是自拍,高质量图片很多', '资源不多,更新慢'], 'x-art.com': ['质量很高,真的很高', '全部收费,屌比请绕过
62 # ']}, '日韩': {'tokyo-hot': ['质量怎样不清楚,个人已经不喜欢日韩范了', '听说是收费的']}, '大陆': {'1024': ['全部免费,真好,好人一生平安
63 # ', '没关系,可以使用爬虫爬取下来,后续我们会讲爬虫课程的,注意认真听讲哦srapy']}}
64 #字典的其他方法;
65 info.clear()#针对字典进行清空操作,字典级别的操作;
66 print(info)#{}空字典;
67 #info['alex':[24,'IT'],'rain':[24,'HR'],'jack':22]# info['alex':[24,'IT'],'rain':[24,'HR'],'jack':22] TypeError: unhashable type: 'slice'
68 info = {'alex':[24,'IT'],'rain':[24,'HR'],'jack':22}
69 print(info)
70 print(info.keys())#dict_keys(['alex', 'rain', 'jack'])
71 print(info.values())#dict_values([[24, 'IT'], [24, 'HR'], 22])
72 print(info.items())#dict_items([('alex', [24, 'IT']), ('rain', [24, 'HR']), ('jack', 22)])
73 dic2 = {1:2,2:3,'jack':[22,'Jack Ma','Alibaba CEO']}
74 print(info)#{'alex': [24, 'IT'], 'rain': [24, 'HR'], 'jack': 22}
75 info.update(dic2)#类似于list中的extend方法,2个字典的间的拓展操作;
76 print(info)#{'alex': [24, 'IT'], 'rain': [24, 'HR'], 'jack': [22, 'Jack Ma', 'Alibaba CEO'], 1: 2, 2: 3}#如果有对应值就覆盖,没有则创建;
77 print(info.setdefault(2,'New 2'))#返回值3,如果有键2,则返回2的值;
78 print(info.setdefault('test','New 2'))#返回值New 2,如有没有,则返回;
79 print(info)
80 print(info.fromkeys(['A','B','C']))#{'A': None, 'B': None, 'C': None}
81 print(info.fromkeys(['A','B','C'],'alex'))#{'A': 'alex', 'B': 'alex', 'C': 'alex'}实际应用先生成空字典,再批量插入值;
82 #与list相似,dict也可以循环;
83 for k in info:
84 print(k)
85 print(k,info[k])#最常用的字典循环方法;
86 #下方不高能,不建议使用,效率是生产力的第一保障!
87 for k,v in info.items():#低效率,先把字典转化成列表,再循环遍历,拒绝使用吧!
88 print(k,v)

49 集合类型
1、如何同时找出买了IPhone7和8的人?!

2、集合的主要作用;
- 去重;
- 关系测试;
3、集合的创建与内置方法梳理;
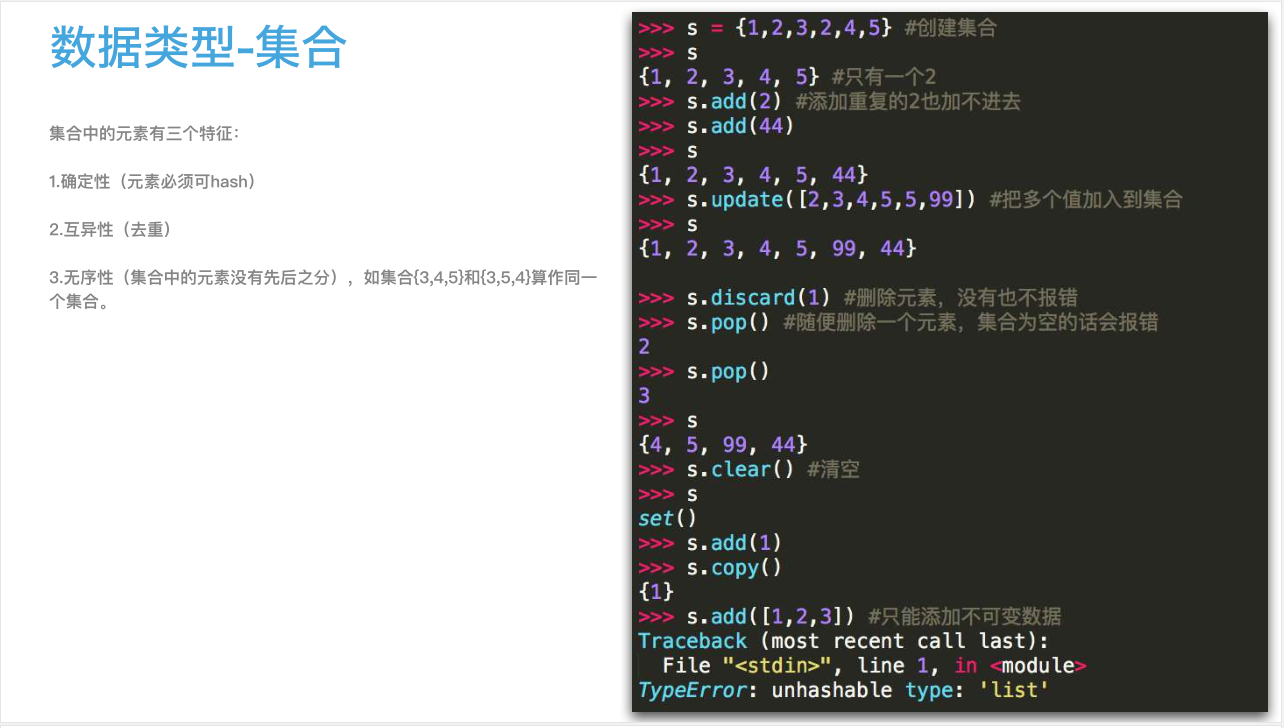
1 #! /usr/bin/env python
2 # -*- coding:utf-8 -*-
3 #__author__ = "tqtl"
4 # Date:2018/5/9 5:10
5 iphone7 = ['alex','rain','jack','old_driver']
6 iphone8 = ['alex','shanshan','jack','old_boy']
7 both_list = []
8 #如何找出同时买了IPhone7和8的人?!
9 for name in iphone7:#先循环一个列表,嵌套;
10 if name in iphone8:
11 both_list.append(name)
12 print(both_list)#['alex', 'jack']
13 #对比两个数据集合的操作-交集、差集、并集;
14 #集合的创建方式;
15 dic1 = {}#此处是字典;
16 print(type(dic1))#<class 'dict'>
17 print(type({}))#<class 'dict'>
18 dic2 = {1,2,3,4,5}#此处是集合;
19 print(type(dic2))#<class 'set'>,数据类型集合set
20 dic3 = {1,2,3,4,2,3,6}
21 print(dic3)#{1, 2, 3, 4, 6}集合自动去重;
22 lis1= [1,2,3,4,5,2,3]
23 print(lis1)#[1, 2, 3, 4, 5, 2, 3]
24 print(set(lis1))#{1, 2, 3, 4, 5}将列表转化为集合set;
25 print(type(set(lis1)))#<class 'set'>,能转化list和元组;
26 #集合的方法;
27 #增加;
28 dic4 = {1,2,3,4,5}
29 dic4.add(2)#增加一个已存在的值;
30 print(dic4)#{1, 2, 3, 4, 5}
31 dic4.add(6)#增加一个未存在的值;
32 print(dic4)#{1, 2, 3, 4, 5, 6}
33 #print(help(dic4.pop()))查看字典的帮助信息;
34 dic4.pop()#集合是无序的,随机删除一个元素,无索引的概念;
35 print(dic4)#随机删除一个元素后的结果输出{2, 3, 4, 5, 6};
36 #删除集合中指定的元素;
37 dic4.remove(6)
38 print(dic4)#{2, 3, 4, 5}
39 #discard方法;类似于字典中的get方法;
40 #dic4.remove(6)#KeyError: 6,使用remove方法,删除集合中不存在的元素,会出现报错信息;
41 dic4.discard(6)#
42 print(dic4)#{2, 3, 4, 5},使用discard方法,删除集合中不存在的元素,不会出现报错信息,一些场景推荐使用;
43 dic4.update([10,12,15,1,2,3,4,5])#往集合中拓展多个元素,add只能一次增加一个,类似于list中的extend方法和字典中的update方法;
44 print(dic4)#{1, 2, 3, 4, 5, 10, 12, 15}
45 #清空set中的内容;
46 dic4.clear()
47 print(dic4)#set()
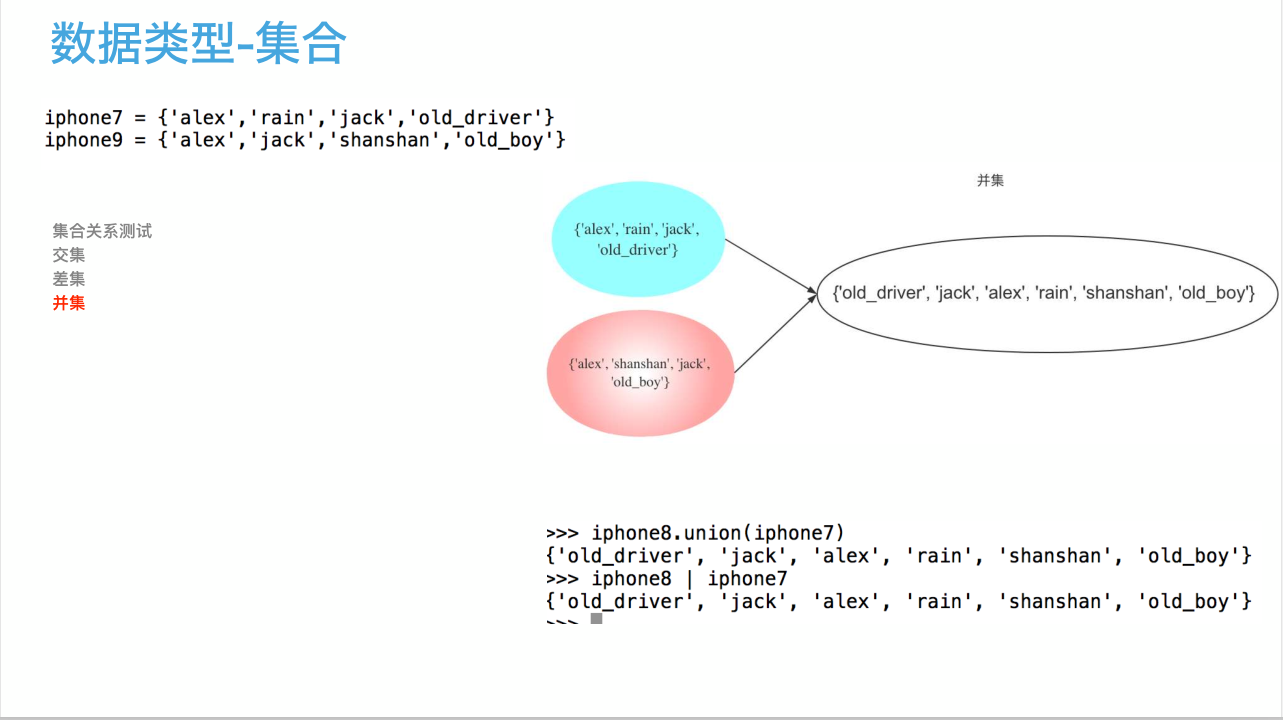
50 集合类型的关系测试
1 #! /usr/bin/env python
2 # -*- coding:utf-8 -*-
3 #__author__ = "tqtl"
4 # Date:2018/5/9 5:39
5 #取出交集;
6 iphone7 = {'alex','rain','jack','old_driver'}
7 iphone8 = {'alex','jack','shanshan','old_boy'}
8 print(iphone7.intersection(iphone8))#{'jack', 'alex'},取出两者的交集;
9 print(iphone7&iphone8)#{'jack', 'alex'},此刻,&符号等价于intersection方法;
10 #取出差集;
11 print(iphone7.difference(iphone8))#{'old_driver', 'rain'},买了iphone7却没有买iPhone8的人;
12 print(iphone7-iphone8)
13 print(iphone8.difference(iphone7))#{'shanshan', 'old_boy'},买了iphone8却没有买iPhone7的人;
14 print(iphone8-iphone7);
15 #取出并集;
16 print(iphone8.union(iphone7))
17 print(iphone7.union(iphone8))
18 print(iphone7|iphone8)
19 print(iphone8|iphone7)
20 #以上4者等价{'jack', 'old_boy', 'shanshan', 'old_driver', 'rain', 'alex'},买了iphone7或者iPhone8的人
21 #对称差集-需求:取出两者不想交的部分,只买了iPhone7或iphone8的人;
22 s = {1,2,3,4}
23 s2 = {2,3,5,6}
24 print(s.symmetric_difference(s2))#{1, 4, 5, 6}
25 print(s2.symmetric_difference(s))#{1, 4, 5, 6}
26 print(iphone8.symmetric_difference(iphone7))
27 print(iphone7.symmetric_difference(iphone8))
28 #以上4者等价{'old_driver', 'shanshan', 'old_boy', 'rain'},买了iphone7或者iPhone8的人
29 #子集和超集;
30 s2.add(1)
31 s2.add(4)
32 print(s2)#{1, 2, 3, 4, 5, 6}
33 print(s)#{1, 2, 3, 4}
34 print(s.issubset(s2))#True,判断集合是不是被其他集合包含,等同于 s <=s2;
35 print(s.issuperset(s2))#Flase判断集合是不是包含其他集合,等同于 s >=s2;
36 print(s2.issubset(s))#Flase;
37 print(s2.issuperset(s))#True;
38 #超集和子集可以使用> 或<符号;
39 #如果集合中的数据量特别大,可以使用s.isdisjoint()判断是否不相交;
40 print(s.isdisjoint(s2))#False;
41 print(s2.isdisjoint(s))#False,返回False说明二者相交;
42 s3 = {1,2,3,4,-1,-2}
43 s4 = {1,2,3,4,5,6}
44 s3.difference_update(s4)#将s3与s4差集的结果赋值给s3,{-2, -1}
45 print(s3)
46 # s4.difference_update(s3)
47 # print(s4)
48
49 s3 = {1,2,3,4,-1,-2}
50 s4 = {1,2,3,4,5,6}
51 s3.intersection_update(s4)#不常用,把交集的结果赋值给s3,{1, 2, 3, 4}
52 print(s3)
53
54
55 s3 = {1,2,3,4,-1,-2}
56 s4 = {1,2,3,4,5,6}
57 s4.intersection_update(s3)#不常用,把交集的结果赋值给s4,{1, 2, 3, 4}
58 print(s4)


51 16进制运算
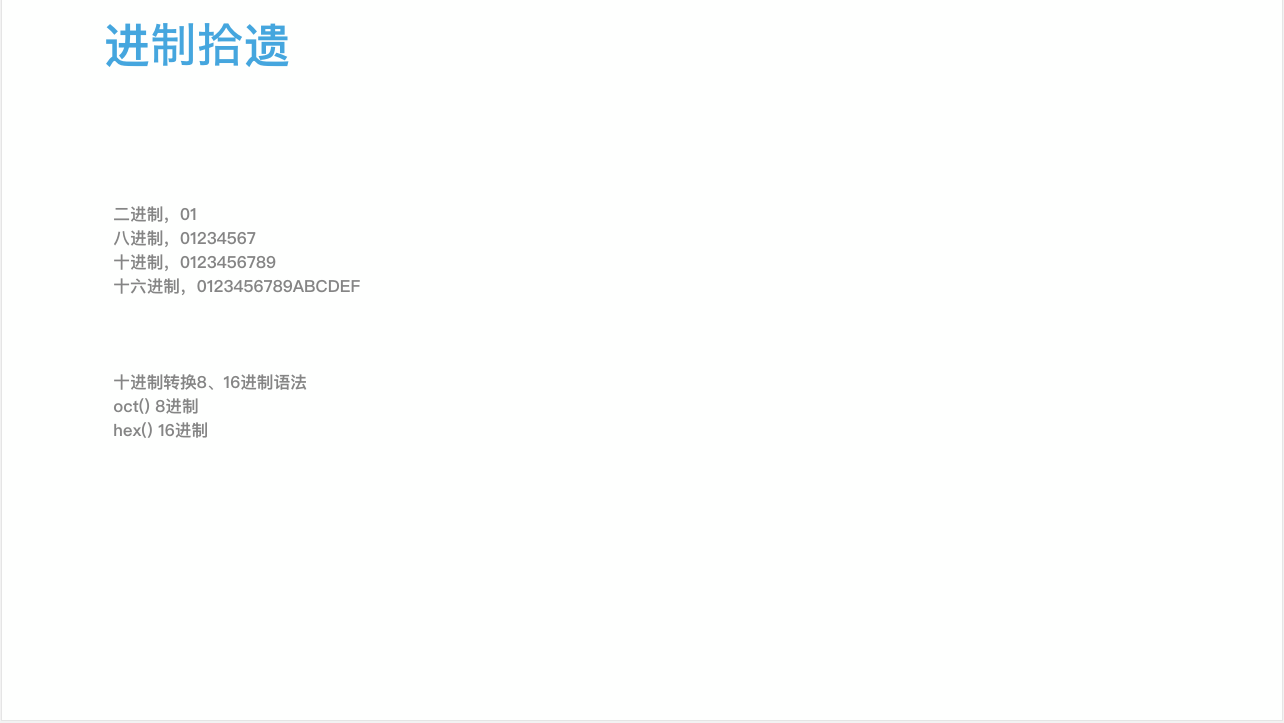
1、进制拾遗;
- 二进制:0和1;
- 八进制:0,1,2,3,4,5,6,7;
- 十进制:0,1,2,3,4,5,6,7,8,9;
- 十六进制:0,1,2,3,4,5,6,7,8,9,0 和字母ABCDEF(分别表示10,11,12,13,14,15);
2、进制之间的转换语法;
1 #! /usr/bin/env python
2 # -*- coding:utf-8 -*-
3 #__author__ = "tqtl"
4 # Date:2018/5/9 6:14
5
6 #10进制转换8、16进制的语法
7 print(oct(1))#0o1 10进制转换8进制,以0o开头,逢7进1
8 print(oct(2))#0o2
9 print(oct(3))#0o3
10 print(oct(7))#0o7
11 print(oct(8))#0o10
12 print(oct(64))#0o100
13 print('-------------------')
14 print(hex(1))#0x1 10进制转换16进制,以0x开头,逢16进1
15 print(hex(3))#0x3
16 print(hex(9))#0x9
17 print(hex(10))#0xa
18 print(hex(11))#0xb
19 print(hex(15))#0xf
20 print(hex(16))#0x10
21 print(hex(1115))#0x45b
52 为何使用16进制
1、为什么计算机广泛地使用16进制?!(8进制使用较少)

https://jingyan.baidu.com/article/47a29f24292608c0142399cb.html
53 16进制与2进制的换算
1、16进制与2进制之间的相互转换;
- 取四合一法;2转16
- 一分四法;16转2
二进制数与十六进制数之间如何互相转换https://jingyan.baidu.com/album/47a29f24292608c0142399cb.html?picindex=1
54 字符编码回顾

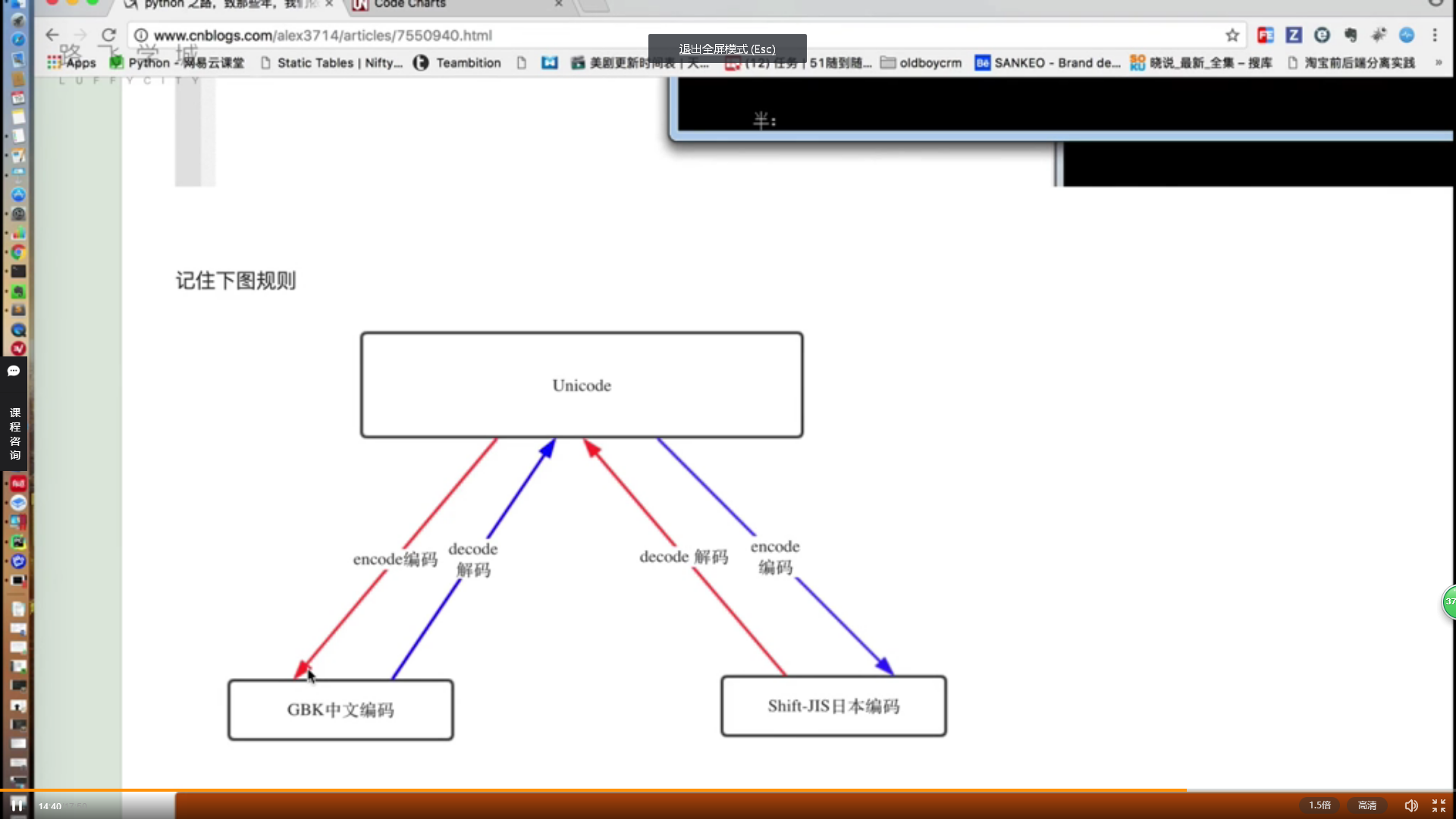
1、致那些年,我们依然没搞明白的编码;
http://www.cnblogs.com/alex3714/articles/7550940.html

2、编码回顾
- ASCII 占1个字节(BYTES),只支持英文;
- GB2312 占2个字节,支持6700+汉字;
- GBK1.0 ,GB2312的升级版,支持21000+汉字;
- Shift-JIS 日本编码;
- ks_c_5601-1987 韩国编码;
- TIS-620 泰国编码;
过渡句:由于每个国家都有自己的一套字符编码,所以其对应关系也涵盖了自己国家的字符,但是以上编码存在一定的“局限性”,即:仅涵盖本国字符,无其他国家字符的对应关系。由此,应运而生了“万国码”,他涵盖了全球所有文字和二进制的对应关系。
- Unicode 2~4个字节,已经收录了136690个字符,一直在不断扩张中...
1)Unicode的作用;
1.支持全球各个国家的语言,每个国家可以不再使用自己之前的旧编码了;
2.Unicode包含了跟全球所有国家编码的映射关系;
Unicode虽然解决了字符和二进制的对应关系,但是使用unicode表示一个字符,太浪费空间。比原来ASCII码存储多了一倍额空间;由于计算机内存比较大并且字符串在内容中表示不会特别大,所以内容可以用unicode来处理,但是“存储”和“网络传输”时,数据量就显得特别大,比如,我在“阿里云”上购买的ECS服务器的带宽是“按量付费”的,使用ASCII码,每月缴纳1w元,使用Unicode就得缴纳2w元,真是“是可忍孰不可忍”呀!
2)Unicode的缺点
1.使用unicode表示字符,多占用一倍的存储空间;
2.在存储和网络传输过程中,耗费资源;
这个世界就是在人们的智慧中不断发展壮大的。为了解决存储和网络传输的问题,再次应运而生了Unicode Transformation Format,学术名UTF,即:对unicode中的存储进行转换,以便于在存储和网络传输时节省空间;
- UTF-8,使用1~4个字节来表示所有字符,优先使用1个字节,最多使用4个字节,无法满足时,增加1,即“可变长字符编码”。英文占同ASCII码时代的1个字节,欧洲语系占2个字节,东亚占3个字节,其他及特殊字符占4个字节;
- UTF-16,使用2、4字节表示所有字符;优先使用2个字节,否则使用4个字节;
- UTF-32,使用4个字节表示所有字符;
总结:UTF 是unicode编码设计的一种在存储和传输时节省空间的编码方案。
55 字符怎么存到硬盘上的
1、致那些年,我们依然没搞明白的编码(同上);
http://www.cnblogs.com/alex3714/articles/7550940.html
要注意的是,存到硬盘上时是以何种编码存的,再从硬盘上读出来时,就必须以何种编码读,要不然就乱了。。。
56 字符编码的转换
1、字符编码的转换;
- 国际通用语言仍旧是English,但是在自己国家,我们都说自己的语言,比如中文,粤语,方言;
- 计算机届,万国码-Unicode是通用语言,但是不同的国家内部,依然使用自己的字符编码;
- 中国默认GBK,日本默认xxxxx;
2、如何解决我国软件出口至他国的字符编码问题;
- 方案1:日本人电脑上安装我国字符编码;
- 方案2:我们的软件以日本编码编写;
- 方案3:把我们的软件编码以UTF-8编码;(一劳永逸的事情);
3、如何解决: 如果我们之前开发的软件就是以gbk编码的,上百万行代码可能已经写出去了,重新编码成utf-8格式也会费很大力气的问题?!
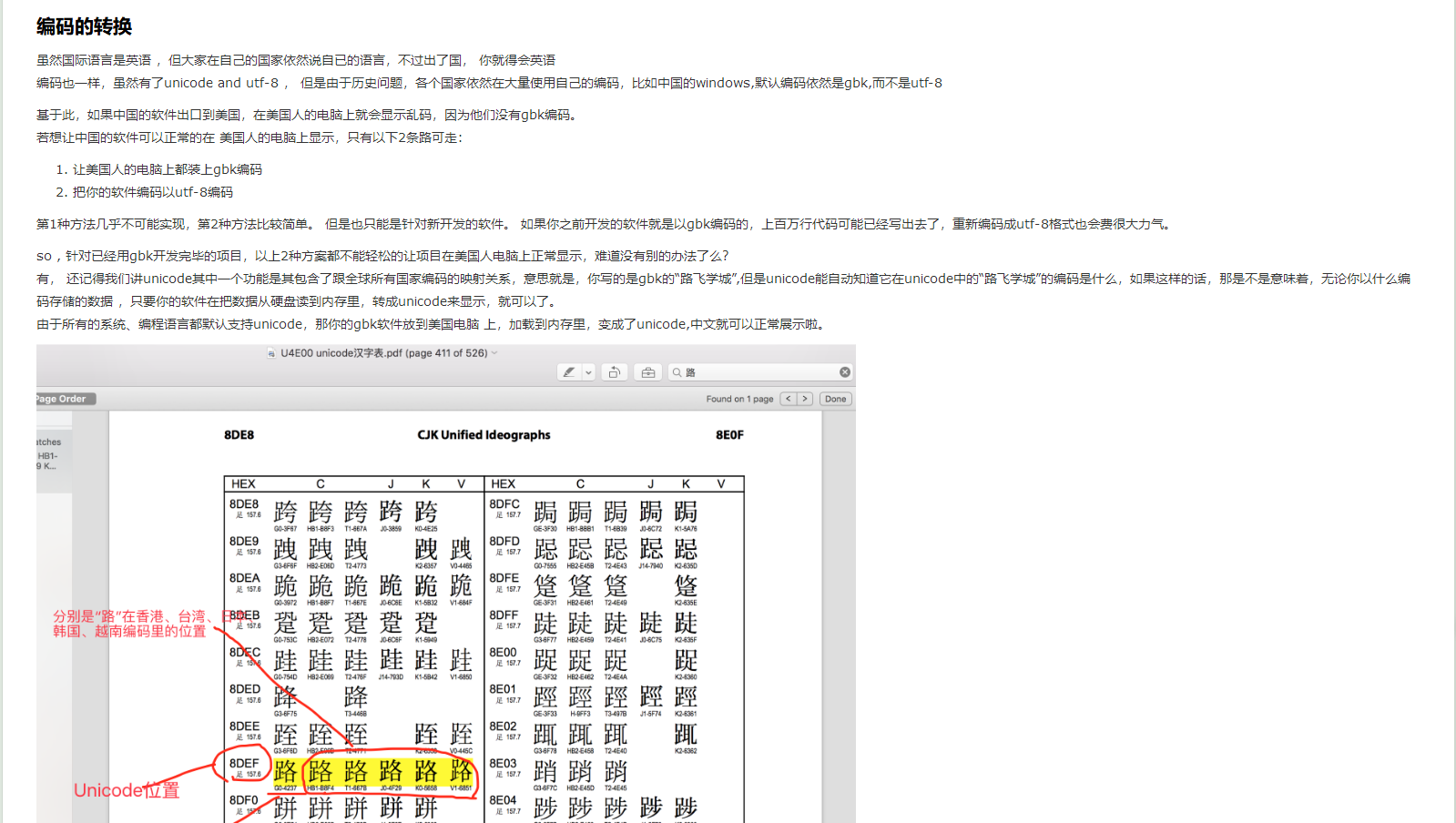
http://www.unicode.org/charts/PDF/U4E00.pdf

57 Python3代码执行流程
1、在看实际代码的例子前,我们来聊聊,python3 执行代码的过程;
- 解释器找到代码文件,把代码字符串按“文件头”定义的编码加载到内存,转成unicode;
- 把代码字符串按照语法规则进行解释(语法分析);
- 所有的变量字符都会以unicode编码声明;
2、编码转换过程;
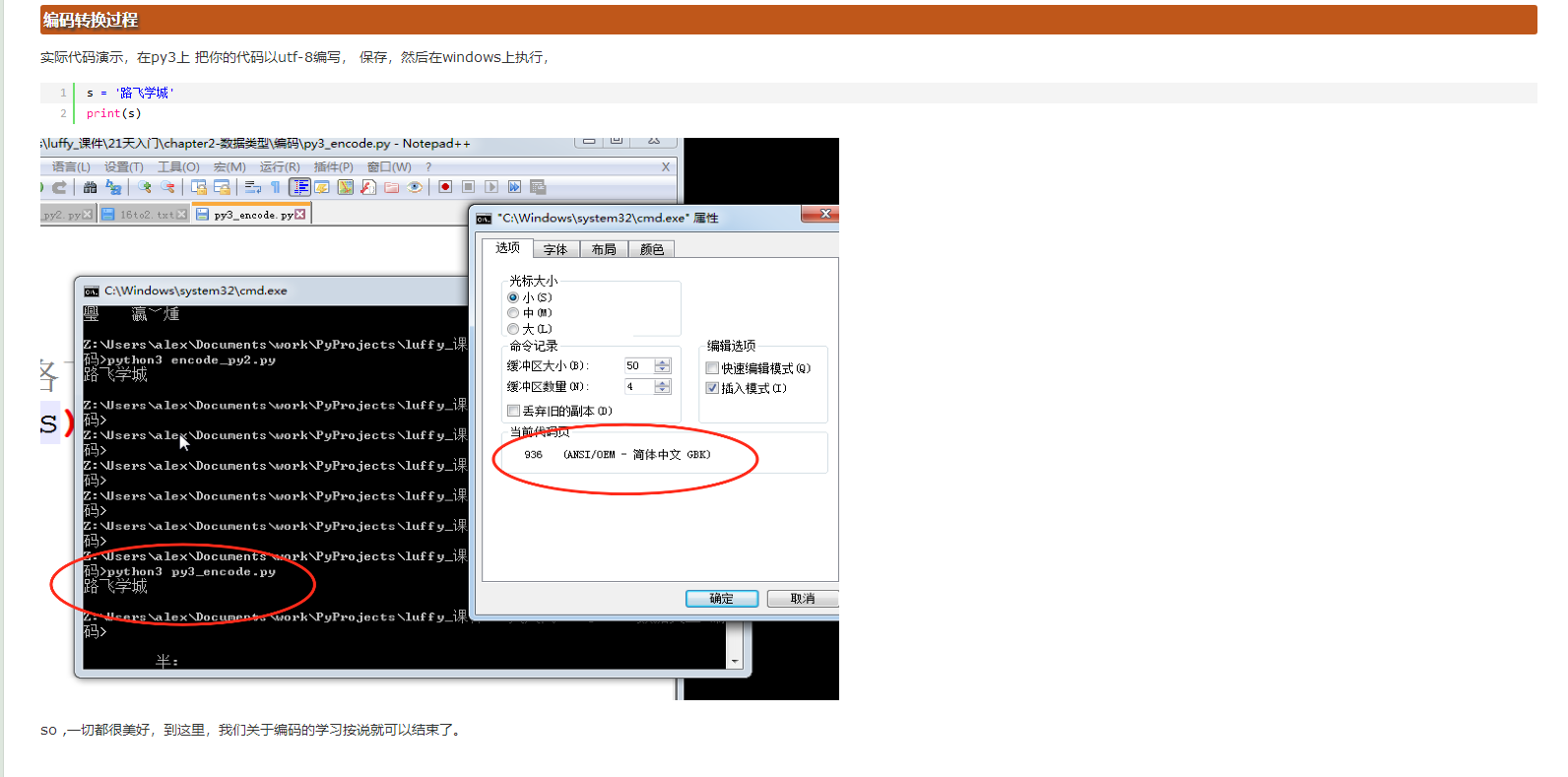
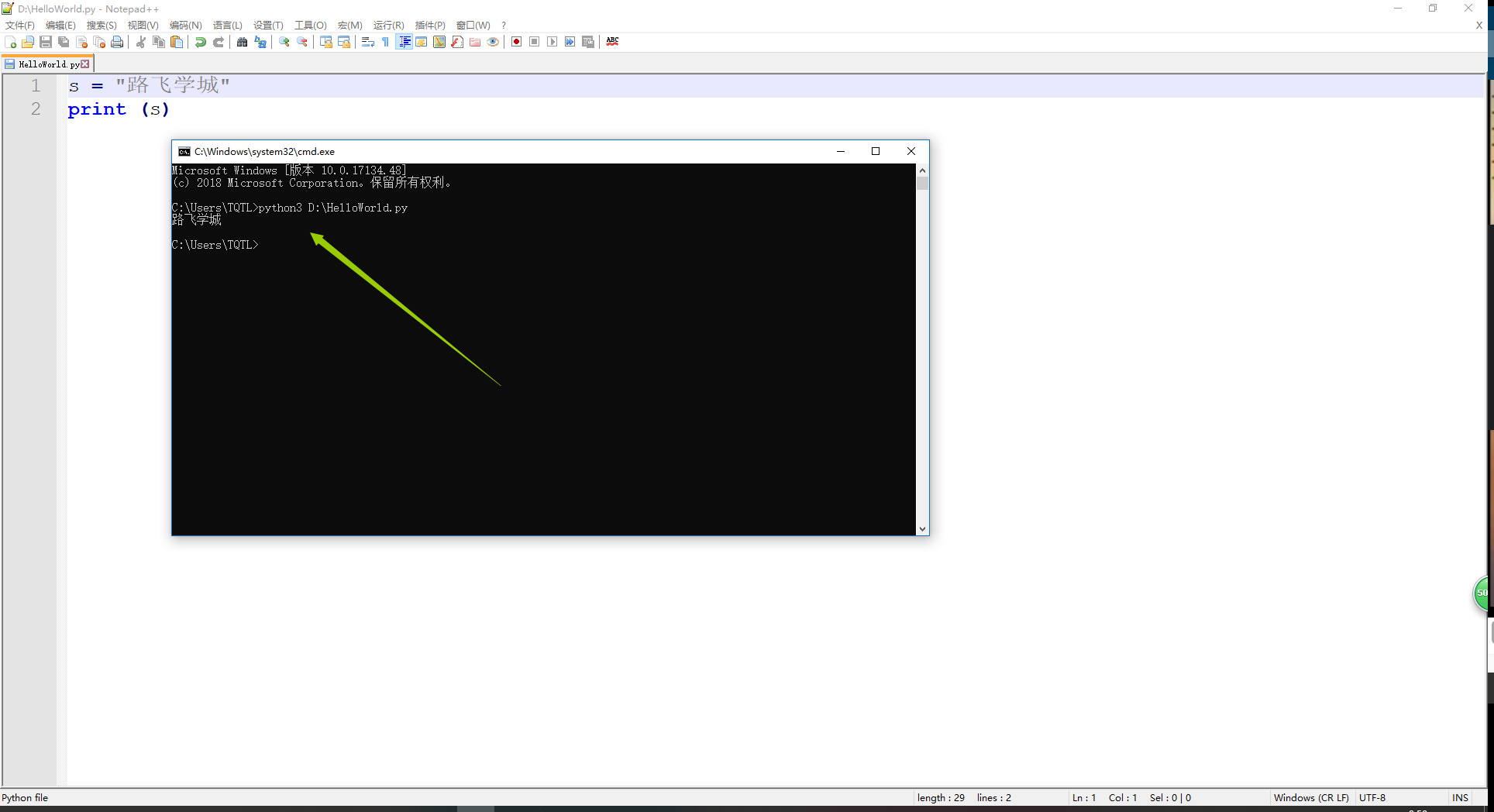
58 Python2的代码转换语法
1、Python2执行如下代码的结果显示;
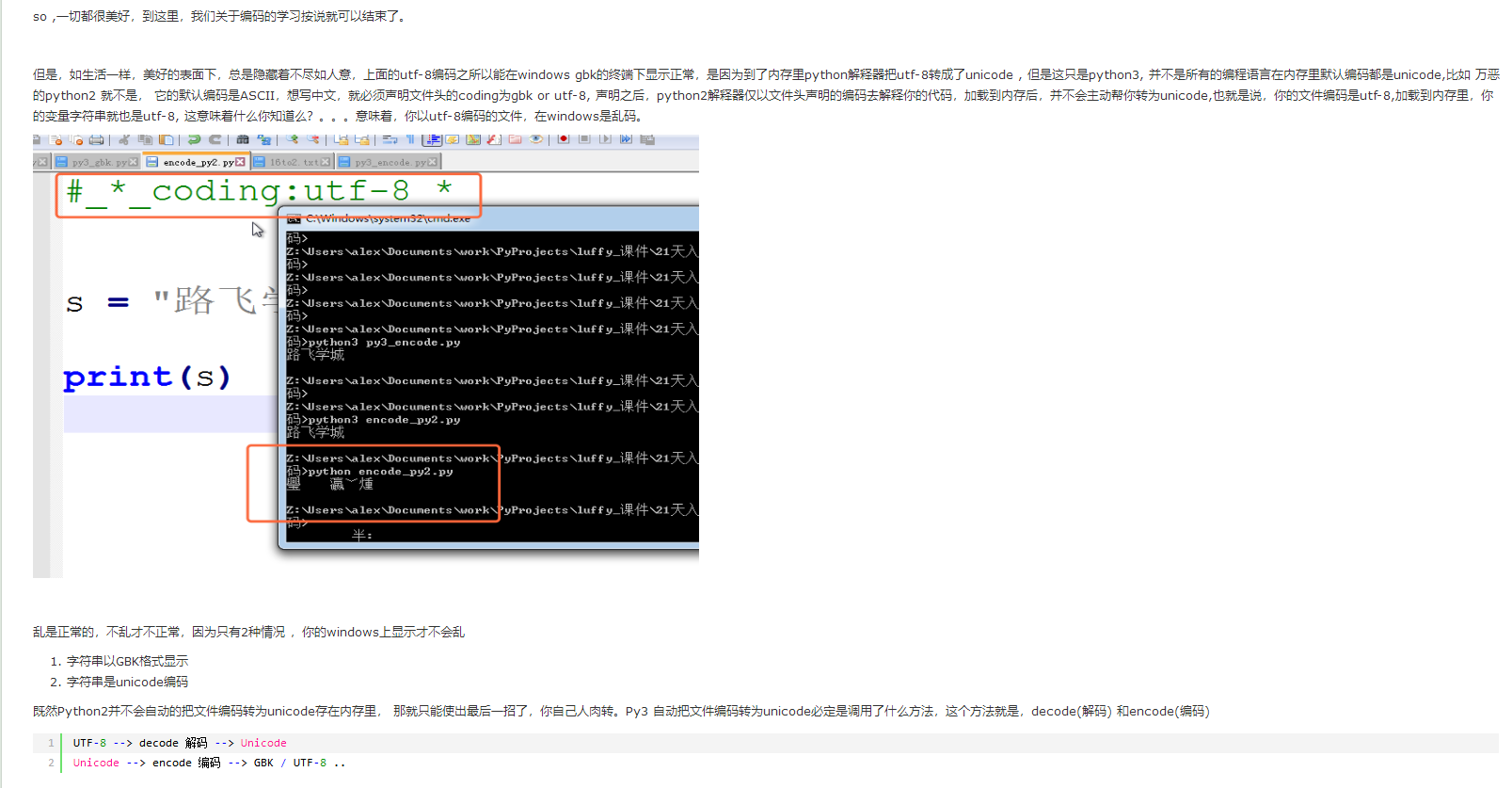
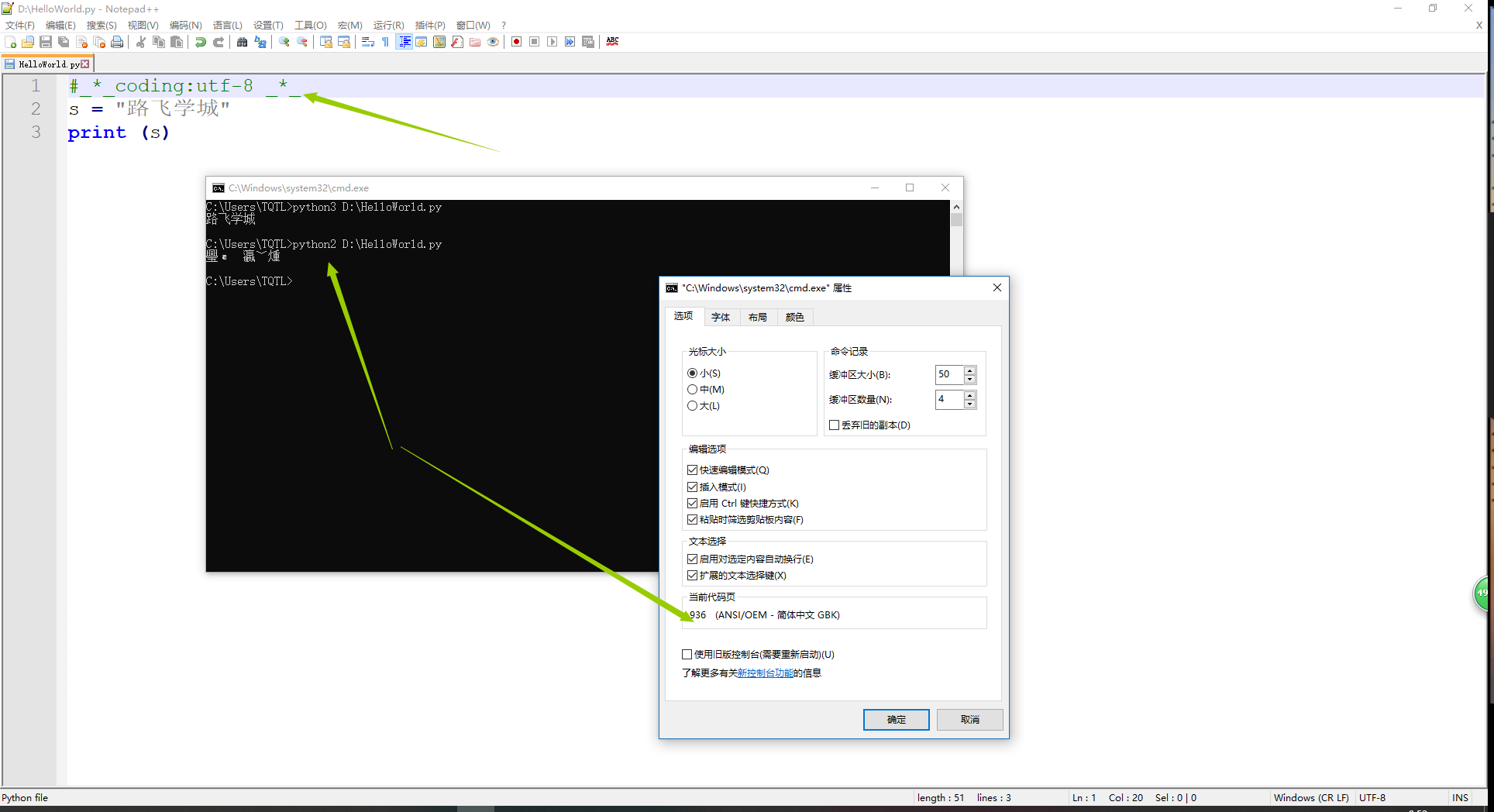
1)乱码是正常的,不乱才不正常,因为只有2种情况,windows上显示才不会乱;
- 字符串以GBK格式显示;
- 字符串是unicode编码;
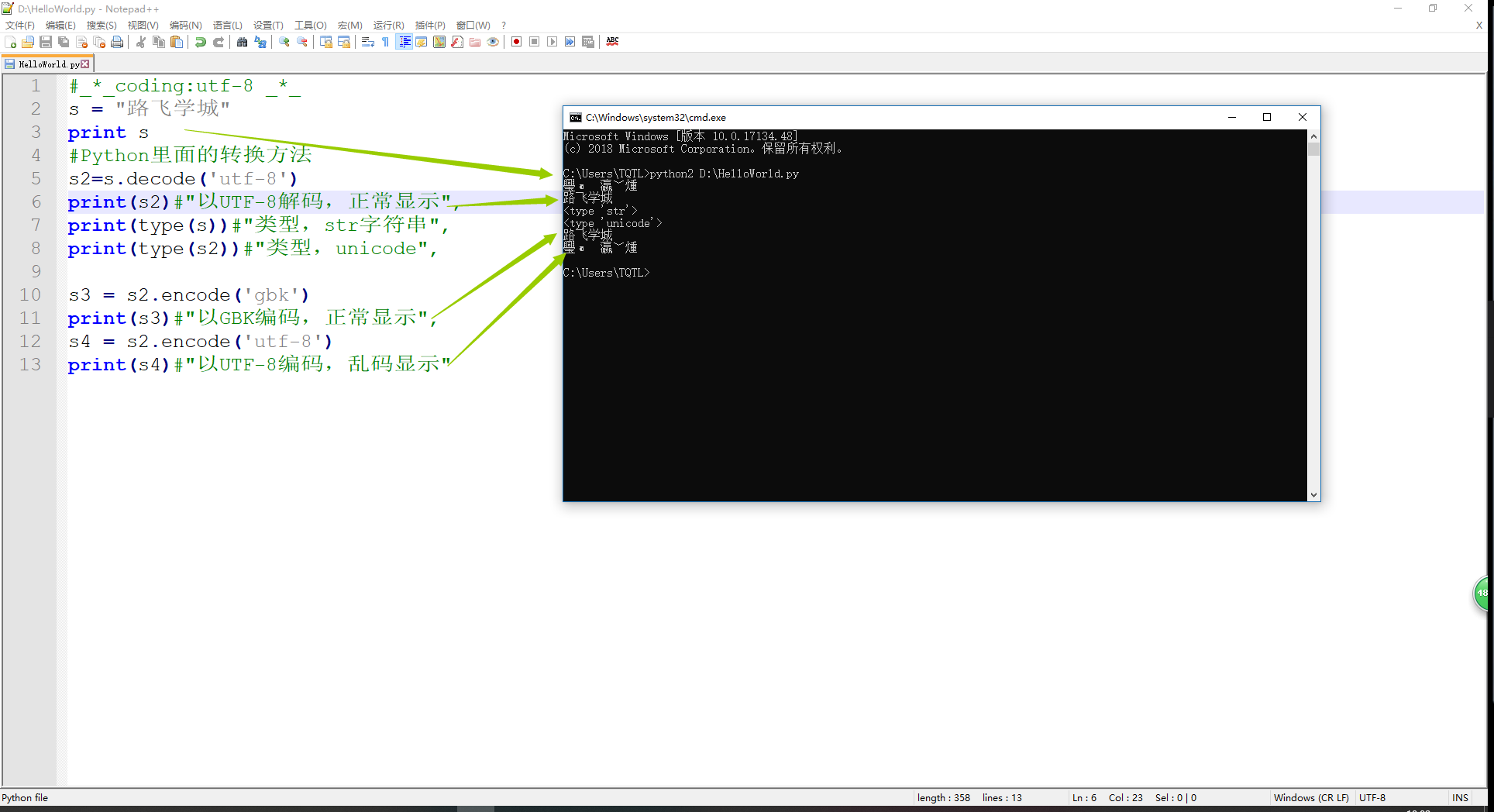

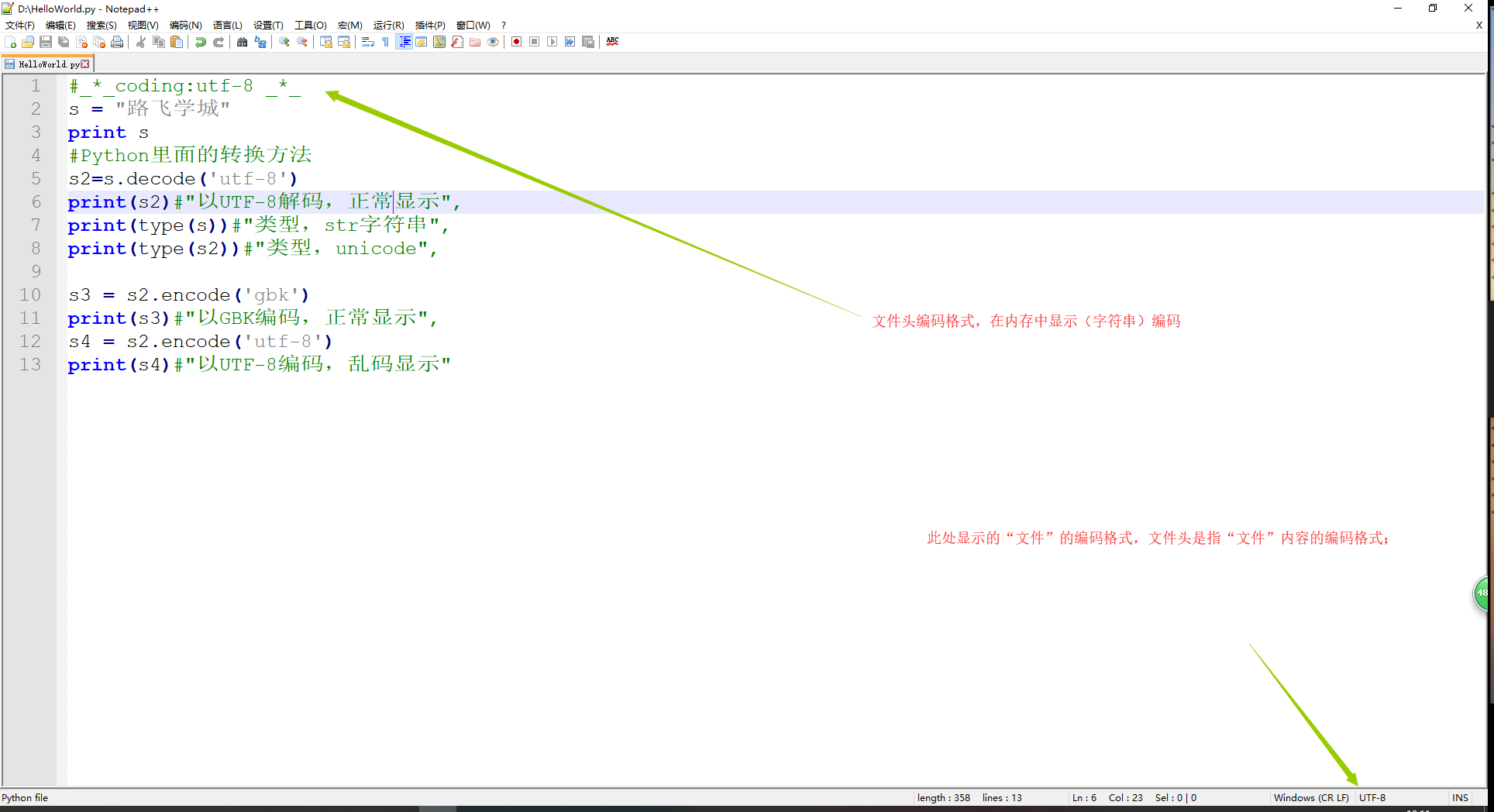
59 Python3通过查看编码映射表确定编码类型
1、如何验证编码转对了呢?!
- 查看数据类型,Python2里面有专门的unicode类型;
- 查看unicode编码映射表;
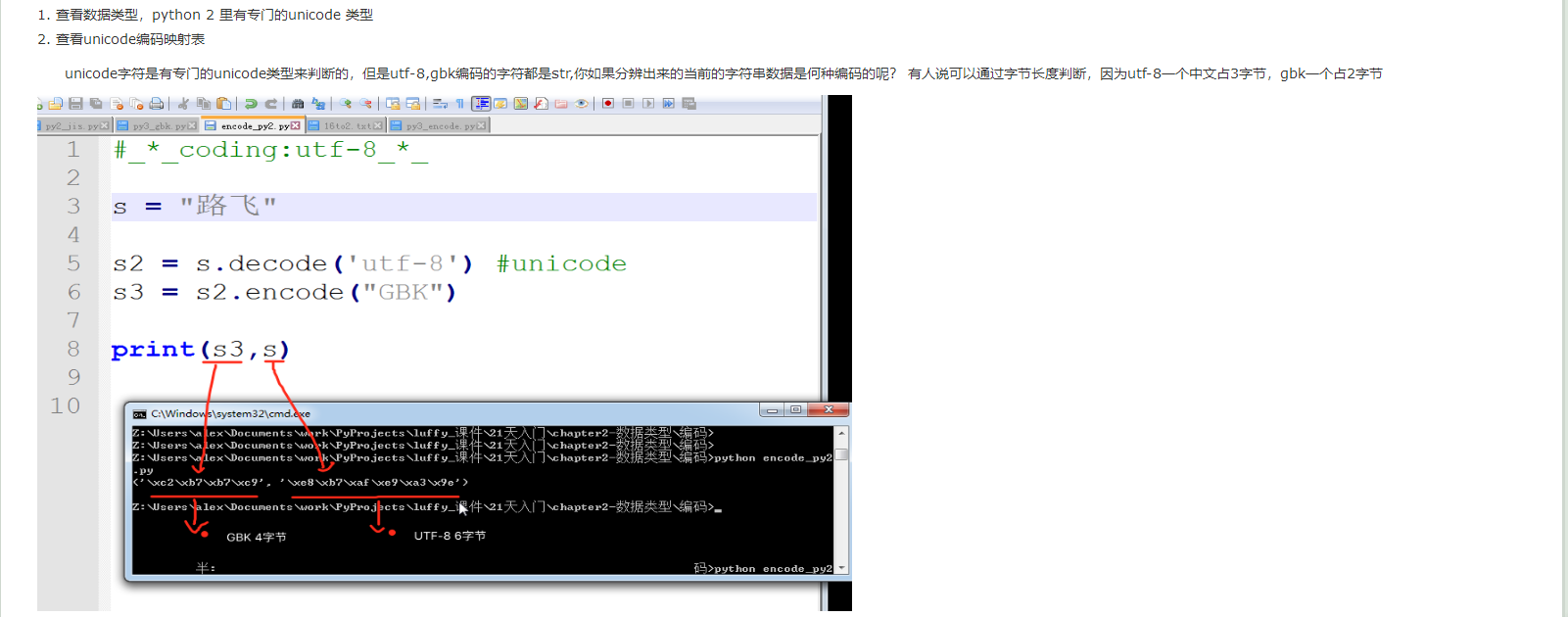
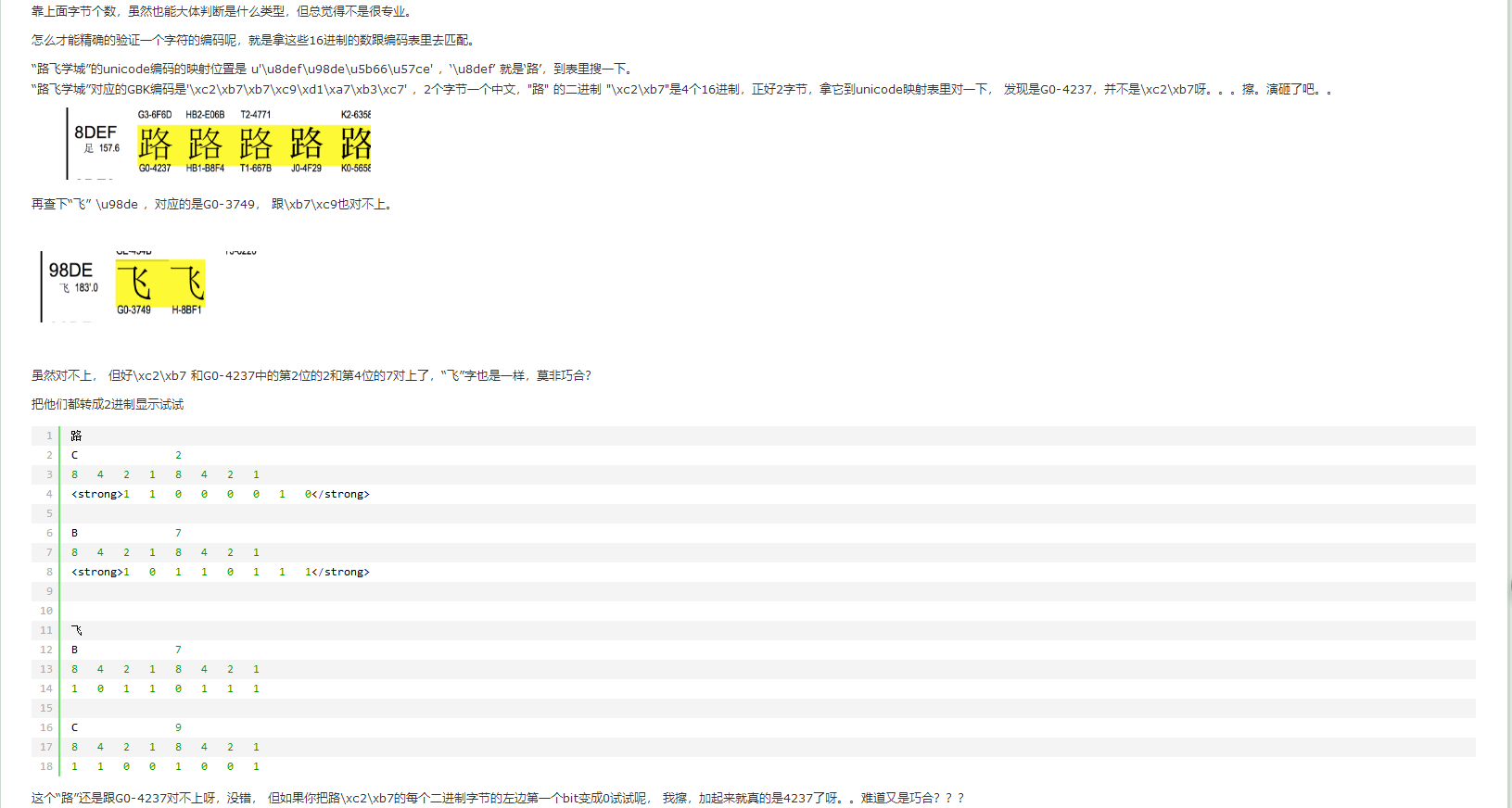

60 Python bytes类型介绍
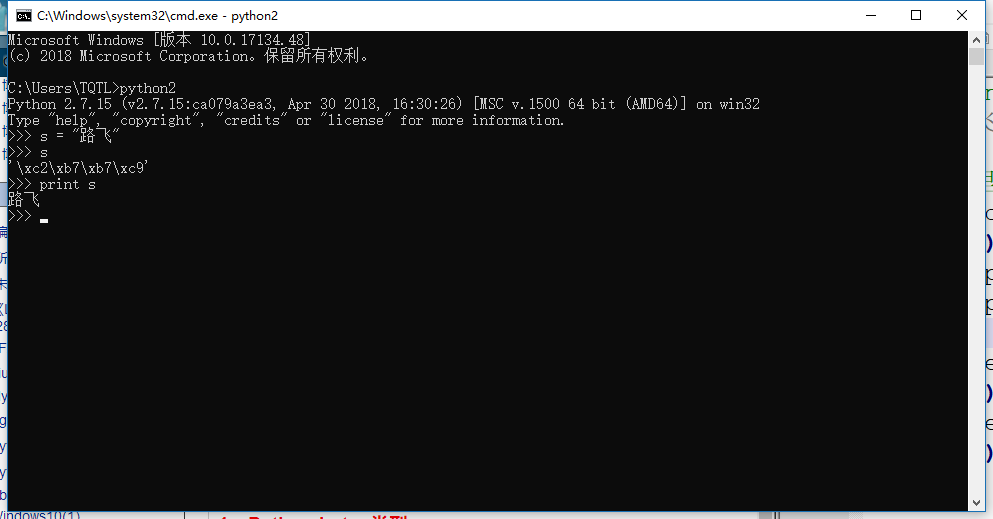
1、Python2中的 bytes类型(注意不是byte);
虽说打印的是路飞,但直接调用变量s,看到的却是一个个的16进制表示的“二进制字节”,我们如何称呼这样的数据呢?直接叫“二进制”吗?可以的,但相比与0101000111,这个“数据串”在表现形式上又把2进制转成了16进制来表示,这是为什么呢?为的就是让人们看起来更可读。我们称之为bytes类型,即字节类型。它把8个二进制一组称为byte,用16进制来表示。
Python2中的字符串更应该称为字节串,我们通过存储方式就能看出来,但Python2中还有一个类型是bytes。在Python2作用,bytes==str,就是这么回事。
2、图片没有字符编码;
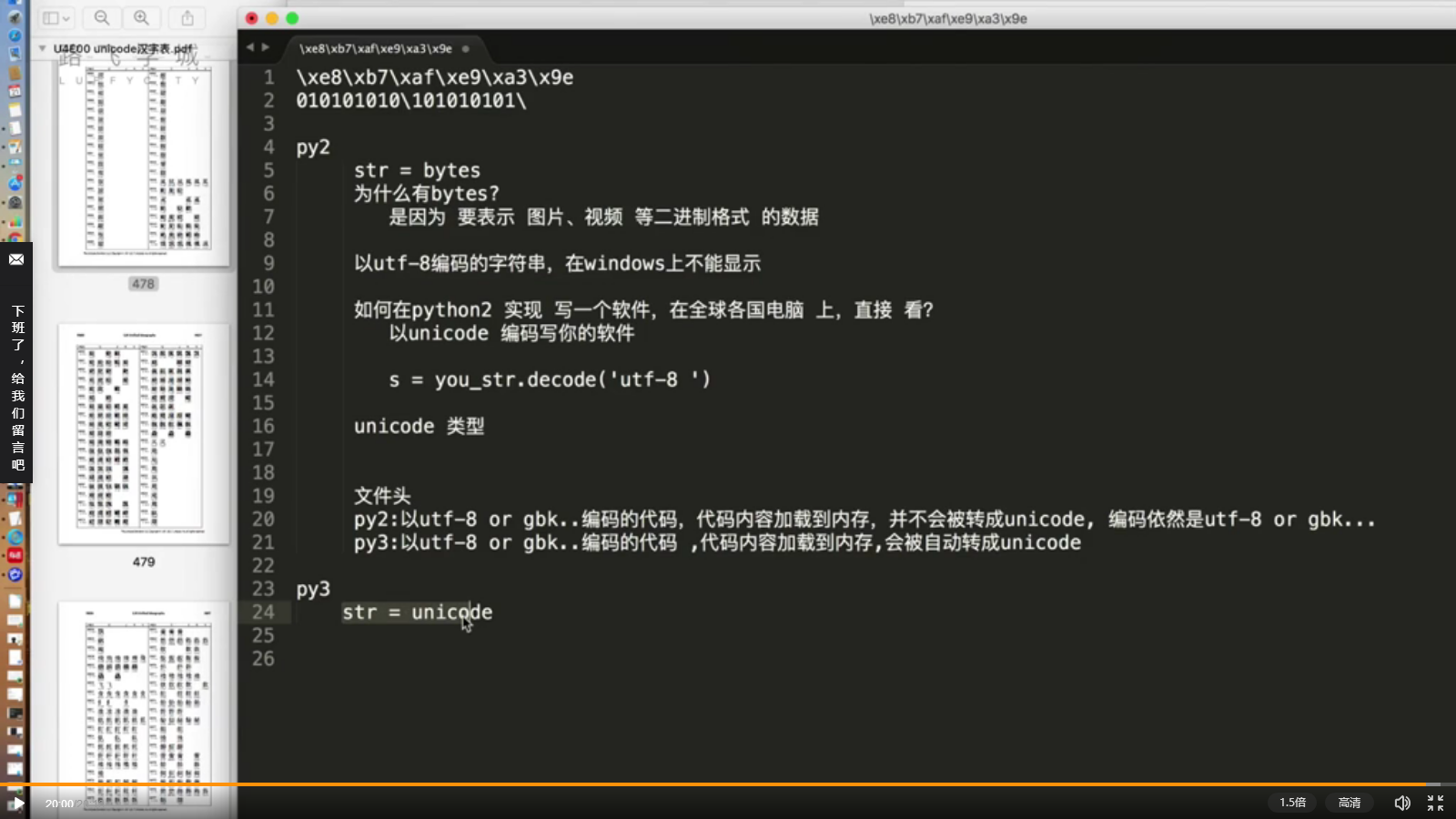
61 Python3与2字符串的区别
1、图片在内存中的显示;


2、为什么有bytes类型?!
为了表示图片、视频等二进制格式的数据类型;
3、如何在Python2实现写一款软件,在全球各国的电脑上直接使用?
以unicode编码;
62 Python3与2编码总结
1、Python2与Python3的编码总结;
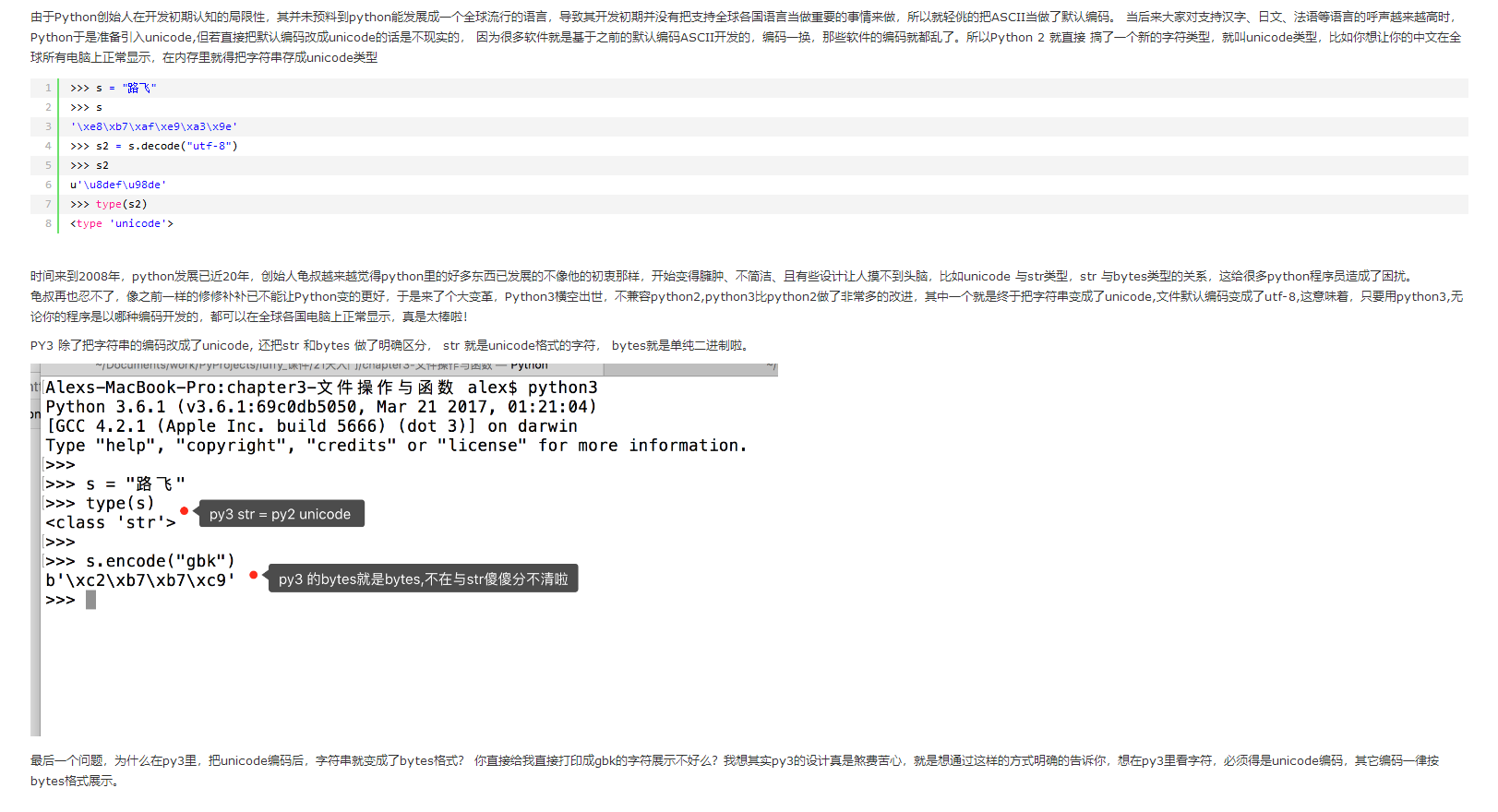
最后再提示一下,Python只要出现各种编码问题,无非是哪里的编码设置出错了。
- Python解释器的默认编码;
- Python源文件文件编码;
- Terminal使用的编码;
- 操作系统的语言设置;
掌握了编码之前的关系后,挨个排错就好了。
63作业需求
-
1、每一个合格的程序员,至少要写出10w行代码;

