一 堆的定义:
堆是一种逻辑上的数据结构,英文名heap,常常用于一段连续的空间,如数组中。这是堆的存储结构。
而堆的逻辑结构,本质上是有排序的二叉树。
按堆的排序方式,分为大堆,和小堆。

堆的存储结构,与逻辑结构的关系如下:
- 存储结构:
设有数组为Array[N] , 这里假定N = 9

这个数组就是堆的存储结构
2. 逻辑结构,即数组中元素与元素的关系:
数组中的元素,谁是根节点,谁是子节点?这个关系是用以下的方式确定的。
上列数组中,名称为Ai 元素(i = 1 ~ N)满足:
1> 父节点的序号为parent = i /2 。若parent = 0 ,则无父节点,Ai为根节点(显然,A1是最顶层的根节点) 。
2>最多具有两个子节点,分别为 left = i * 2 ,right = i * 2 +1 。若无子节点,则该节点为叶子节点(树的叶子上不会再长叶子,所以代表最末端)。
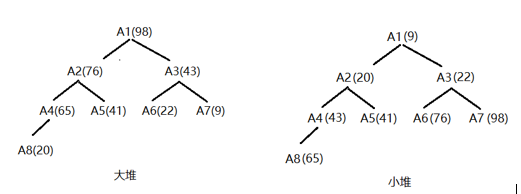
3> 大堆(小堆)中,父节点的值,一定大于(小于)所有子节点。如下图。
通俗的讲解下堆的关系:
堆就像是一个族谱,或者家庭关系图
大堆,就是从长辈到子女的关系图,节点值代表年龄: 母亲 总是比子女的年龄大。 但孙辈的年龄,却没有固定顺序,孙子孙女年龄,可以大于舅舅,舅妈。 注意,由于堆是二叉树,所以这个族谱最多只能二胎。
小堆,就是子女到长辈的关系图,节点值代表年龄。 根节点的年龄,一定小于左右节点的年龄。但是爷爷节点与父母之间却没有固定顺序(外公外婆可以比父亲年龄小)
二 堆的初始化
数组要变为堆,首先必须经过初始化排序,使得无序数组变为有序堆。
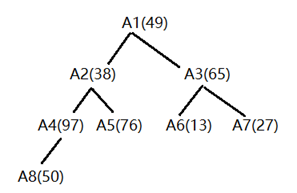
我们假设一个数组如下,并将其转换为大堆:
| 序号 |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
| 名称 |
A1 |
A2 |
A3 |
A4 |
A5 |
A6 |
A7 |
A8 |
| 值 |
49 |
38 |
65 |
97 |
76 |
13 |
27 |
50 |
- 先把无序数组变为无序二叉树。
设i = 1 to 8,子节点为 i*2 ,i*2+1,依次添加子节点。结果如下图:
(无序二叉树)
- 从叶子节点,向根节点,整理二叉树的排序。
a> 找到最外层(远离根)的非叶子节点。 由于N= 8 ,则最远端节点是 i = INT(N/2) = 4.
b> 从A4开始,依次整理A3, A2, A1 为根的子树 (这是大循环)

c>当前节点为Ai, 若无子节点,回到大循环b> .
若有子节点,找出子节点中的大者。并与Ai 比较。
若Ai大,则本次整理完成,回到大循环b>
若Ai小,则交换 Ai 与该大值子节点。 然后i = 交换序号,重复执行c >。
(举例,对A2的子树做整理:)

初始化的总结:
可以看到,无序化树的整理,有两个循环。
内循环是,对已经有序的子树,加入新根,然后自根向叶,做排序。
外循环是,当一个子树的内循环完成,就继续遍历完所有子树(N=4,3,2,1)
这个方针就是,先整理好基层(子树);然后逐渐将中层,高层纳入整理范围(更大的子树),直到整个系统整理完成。
三 在堆中添加数据并刷新
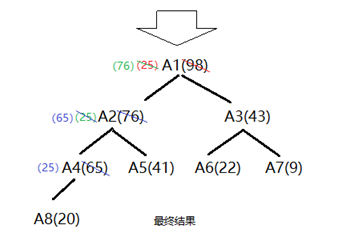
若一个数据A_new,要加进一个已经序列化,并且节点数固定的堆,那么就需要按照如下方法添加(这里以大堆举例说明,需要注意的是,大堆总是弹出最大值,保存小值,所以大堆往往用于保存N个数中最小的k个数):
- 对比A_new与根A1:
若A_new 大于 A1,则A_new不加入堆,本次更新完成。
若A_new小于A1, 则A1= A_new,i = 1. 然后进入2.。
2. 当前节点为Ai, 若无子节点,完成整理 .
若有子节点,找出子节点中的大者。并与Ai 比较。
若Ai大,则本次整理完成。
若Ai小,则交换 Ai 与该大值子节点。 然后i = 交换序号,重复执行2.。
可以看出,其实就是执行的堆的初始化中的“2.c>” 步。
如下图是一个例子,经过三次交换后,堆更新完成。

四 堆的其他运算:
包括堆的减小,堆的增加,堆头的删除等。
暂时待加入。
五 堆的优点
当我们在堆中,增加新的值时,需要重新排序. 若堆有N个元素,那么这个排序的时间复杂度为 Log2N
这是由于,一个具有N个元素的堆,它最多具有Log2N 层 。 而最坏的情况下,每层需要执行一次交换。
不过,对于时间复杂度,我们一般计为:
LogN
这是由于,不论底数是多少,例如(ln N)和( lg N ) ,它们的比例是常数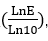 ,说明不论底是多少,他们都是一个数量级的。所以直接用logN来表示时间常数。
,说明不论底是多少,他们都是一个数量级的。所以直接用logN来表示时间常数。
而如果采用数组标准的排序法,则最坏要执行N次交换。
显然,堆的执行效率高很多。
例如:
一个长度为1024的堆,要更新一个新元素,执行次数最多为:10次。
一个长度为1024的数组,则跟新一个元素,执行次数最多为:1024次。
数据越大,则这个差距也越大。