目录
top K 排行问题:— 以处理较多数据为例,最大的前K个数

堆的概念:
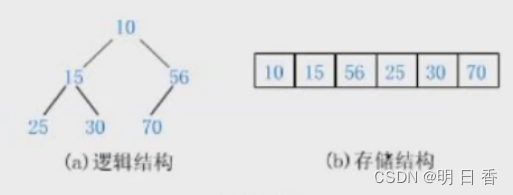
一般是把数组的数据在逻辑结构上看成一颗完全二叉树,如下图所示。
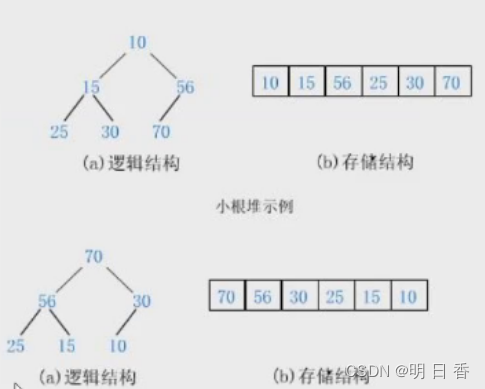
注意:别将C语言中的堆和数据结构的堆混为一谈,本文所讲的数据结构的堆是一种完全二叉树,而C语言中的堆其实是一种内存区域的划分
堆的分类:
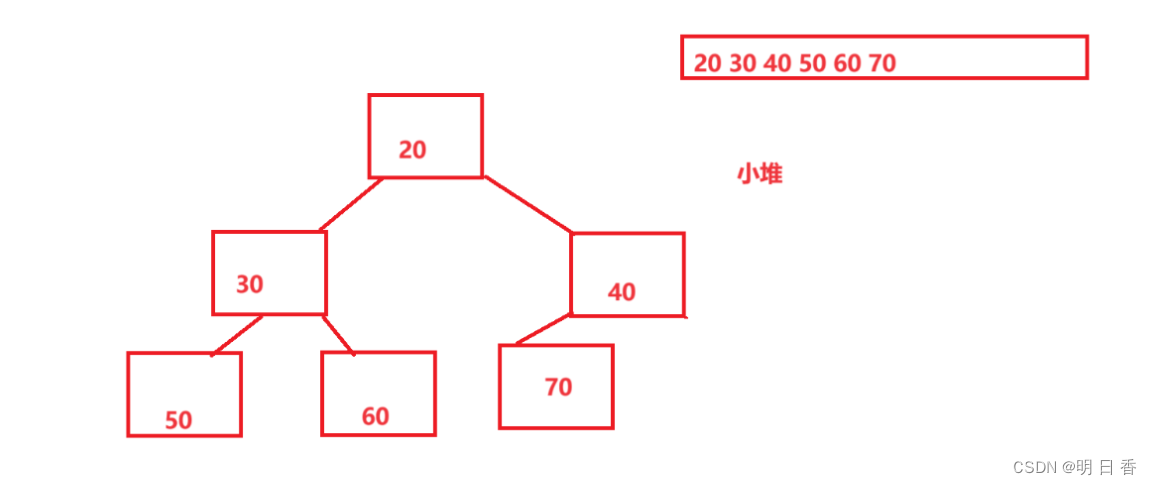
小堆:小堆的数组转化为完全二叉树则就是父亲节点要比孩子节点小。
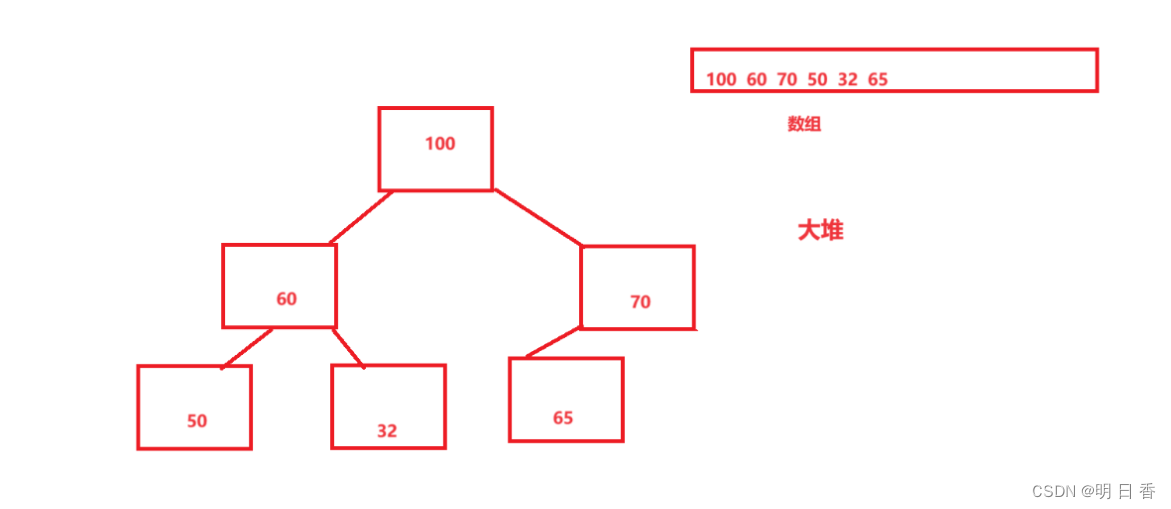
大堆:大堆的数组转化为完全二叉树则就是父亲节点要比孩子节点大。
- 根据大小堆的特点,可以得知有序数组一定是堆,但堆不一定是有序数组
大堆:
小堆:
堆的实现:——以小堆为例

堆的定义:

因为堆的底层是数组所以定义一个数组的结构体,且看似一个顺序表,但本质上并不是顺序表,因为逻辑结构是一个完全二叉树,所以插入的要求要完全按照完全二叉树的要求来看,这里就需要用到之前完全二叉树存储到数组中后,父节点和子节点再数组中的下标关系。
堆的初始化和销毁:
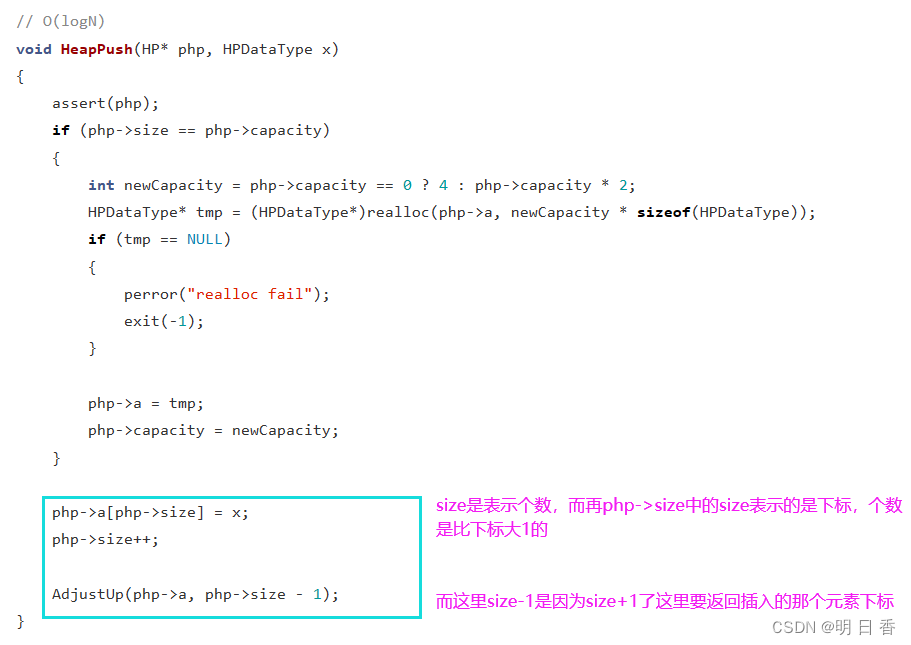
注意:size是表示结点的个数,而不是数组的下标,结点的个数始终是比数组的下标大1 ,所以之后的插入操作中 size 是表示需要插入的位置下标。

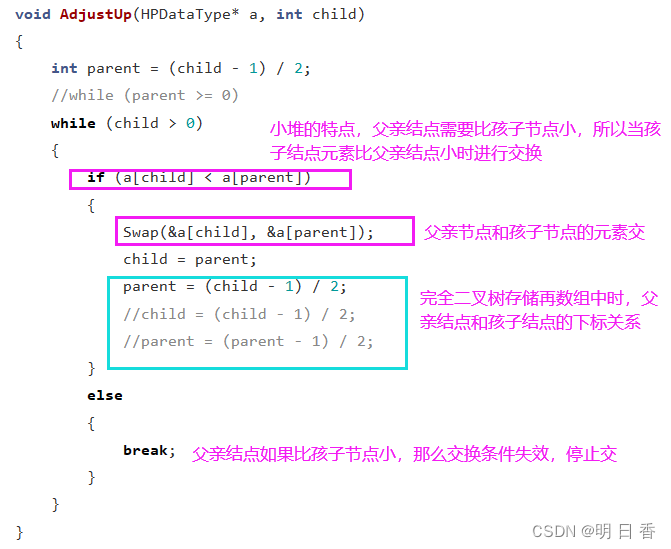
堆的插入:
- 堆的插入和删除本质上是需要对堆的状态进行一种保持,例如,再插入前是小堆类型,那么插入后就必须是小堆类型,删除也是一样
- 所以怎么样使得堆保持再小堆状态或者是大堆状态是插入和删除需要考虑的问题。
- 而之前说过,堆的底层是一种数组,而数组的另一种令人熟知的结构是顺序表,那么是否能够模仿顺序表的尾插进行堆的插入操作呢?
- 答案是可以!
- 但,需要对这种操作进行一种改造
- 因为尾插的数据不确定,而根据小堆的特点,父节点始终需要比子节点要小,所以需要进行比较,比较后进行子节点和父节点之间的交换
- 但仅仅一次的交换是不够的!
- 因为父节点之上,还有父节点的父节点,所以为了保持堆的结构,需要自下而上的进行一次判断交换操作!

自下而上的交换操作:
尾插操作: ——与顺序表的尾插一样
交换函数:

堆的删除:
- 删除数据,分为两种,一种是删除根结点,一种是删除最后的结点。
- 但是删除最后的结点其实没有任何的意义,对于堆的结构并不会发生改变,所以通常而言删除堆其实就是删除堆的根节点后,堆依旧保持大堆状态或者小堆状态。
其次,删除堆的根节点有一个误区,就是会沿用顺序表的头删操作,这样做虽然删除了根本节点,但是对于堆的结构却发生了不可逆转的变化,那就是父亲不是父亲,孩子不是孩子,兄弟不是兄弟。
要知道顺序表是一种连续的线性表结构,而堆是一个完全二叉树结构,二者的结构本质上是不一样的!

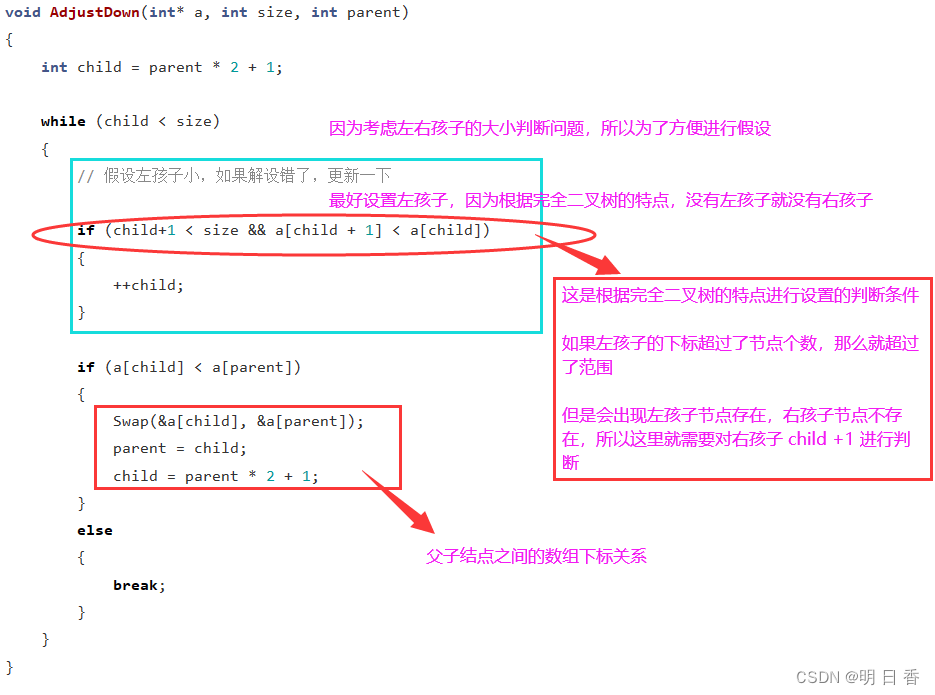
- 而正确的做法,是将尾的结点的元素和根结点元素进行交换,交换后再进行尾删,这样既不会使得堆的父子节点关系错乱,保证了左右子树的各个节点关系正常。
- 而在交换后进行尾删,达到删除的目的,之后在进行自下而上的交换,和自己的子节点自上而下的进行数值的交换,从而保证堆还是原来的小堆或者大堆。
进行交换要符合条件,也就是小堆或者大堆的父子关系特点
例如父节点要不子节点小——例子以小堆为例,因为要换小的,所以要换最小的那个孩子,所以需要左右孩子进行比较,交换的条件是判断孩子的结点下标是不是超出了数组长度的范围,超了就是叶节点表示交换停止了。
- 注意:如果不是交换左右孩子中最小的那个,那么就不是堆
自上而下的交换操作:
尾删操作:——和顺序表的尾删一样

获取堆顶元素:——获取根结点元素

判断堆是否存在:——判断堆的结点个数是否是零

获取堆的结点个数:

主函数部分:
创建操作

获取堆中前K个最小元素

打印堆

完整代码:
头文件部分:

源文件部分:
主函数部分:
堆的意义:
第一是堆的排序,第二是堆的top k 排行问题
堆的 top k 排行问题:
- 堆的top k 排行问题主要是利用了 大堆或者小堆的堆顶一定是最大或者最小值的特点,再利用了堆的删除操作,从而进行堆的一种大小排序,从而形成一种升序或者逆序的top榜单排满。
面对大量数据的top k 问题:
再面对大量的数据时,如果要进行排列前k个最小的数值时,可以先创建一个拥有K个结点大小的小堆,随后再进行插入,将插入的数据和栈顶元素进行比较,如果比栈顶元素小,那么替换栈顶元素,随后再和栈顶下的各个结点进行比较和交换。
这种做法到最后,形成了一种栈顶是最小的元素的结果,这种方法也相当于是一种末位淘汰制。
堆排序的实现:——以升序为例
- 关于升序,一般大多数人会想到使用小堆,因为小堆的特点是父节点比子节点小,而堆的底层结构又是数组,所以大多数人最初想到的是使用小堆来实现堆排序问题。
- 但这是错误的,因为堆其实是一种选择排序。
如果排升序建立小堆,我们可以一开始获取最小的数字,但是我们下一步呢,如果找第二小的数字?
如果要找第二个最小的数字,如果在当前这个堆的基础上找,那么关系全乱了,因为要在兄弟之间,要在父亲的兄弟之间,父亲的兄弟的孩子之间找
这时候只能重新建一个堆,但是建堆的代价是时间复杂度的重复性。
所以,使用大堆来解决堆排序的升序问题!
方法一 交换首尾:
根据,堆删除的一种思想,交换!
根结点元素和尾结点元素的交换,以大堆的父结点元素比子结点元素大的特点,最后一个结点的元素是堆的最小值,而根结点的元素是堆的最大值,当二者进行交换后,最小值跑到了根结点位置,最大值跑到了最尾部结点。
而此时,使用循环的方法再结合屏蔽尾部结点的方法,在轮流交换的过程下,很快就会形成一个以大堆的基础构建的小堆,而小堆在数组中的排序便是升序的!
建立大堆:
使用之前构建堆的方法过于繁琐,所以可以利用现成数组和自下而上的交换方法进行大堆的建立

根结点尾结点的交换配合自上而下的操作:
- -end是用来屏蔽每一会的最尾结点,end 是下标的意思,n是数组大小的意思。

自上而下的函数 :

自下而上的函数:

源文件:

主函数部分:

方法二 反复横跳:
反复横跳的核心是找到最后一个结点的父节点,进行自上而下的交换,利用升序和大堆的特点——父结点比子结点大,将父结点的元素和子结点的元素进行交换。
- 且每一次交换后都会形成一颗子树,这时候在将这颗子树的下标跳到隔壁子树上,再度进行刚才的操作,这样一来,左右子树的父子结构均不会被破坏,且还会变成一个升序的小堆。
实现:
i 表示为父结点的下标,n一开始是最尾部结点的下标。

top K 排行问题:— 以处理较多数据为例,最大的前K个数
在之前上文堆的意义中,详细讲过了堆的top k问题,而这里以处理较多数据的top k 为例
创建数据并存储到文件中:
这一步主要是怕数据过多导致终端卡顿
- 代码解读:
- srand 函数进行选取随机,然后在使用time传输随机值,然后以写("w")的方式打开文件
- 然后因为要产生一千万个数值,而rand只能产生三万多个数字所以需要+i并%上10000000
- 之后将这些数据写入文件中(fprintf),最后关闭文件,fin是文件的指针变量
file 是指向文件的指针,fin是文件内部进行内容操作的指针

创建K个数的小堆:
- 根据小堆的特点,根部是堆中最小的数字,如果需要寻找最大的数,则可以通过堆顶的根结点元素进行第一道排查
- 而比堆顶大的数则替换堆顶元素,随后根据小堆的特点,父结点比子结点小,从而进行自上而下的交换,把较大的元素丢到堆的尾部进行二次的排查。
- 这样到最后,最后一个结点是最大的数,而堆顶的根结点元素则是这一千万个数种第K个最大的数。

- 注意,这里还是使用了数组构建堆的方法,而进入数组中的元素由fscanf函数从之前创建好的文件中拿取。
- 使用了malloc建立了一个能够存放K个元素的字节 的 空间大小,作为数组。
- fscanf是从指定标准流中获取内容,scanf是从键盘标准流中获取内容
- fascnf 的三个参数分别是,一个文件类型的指针负责读取数据,一个读取后展示的格式,第三个是读数后读取的数据存放的空间
- fscanf读完数据后会返回EOF
进行交换:
因为fscanf读完数据后会返回EOF,所以 以此作为判定条件,x用来寄存从文件中读取的元素,当x比堆顶根结点元素大时,替换堆顶根结点元素,随后进行自上而下的交换进行调整堆的元素,以此维持小堆结构。

打印堆:
- 最后将堆打印

完整代码:

自上而下调整的时间复杂度:

自下而上调整的时间复杂读:

