词的向量化
自然语言理解的问题要转化为机器学习的问题,第一步肯定是要找一种方法把这些符号数学化。词向量是自然语言处理中常见的一个操作,是搜索引擎、广告系统、推荐系统等互联网服务背后常见的基础技术。它分为One-hot Representation、基于SVD(奇异值分解)的方法、基于迭代的方法——Word2vec等三类,并基于飞浆(paddlepaddle)平台实现。在展开介绍之前,先补充一些基本概念和数学知识。
重要概念
词项-文档矩阵,TF-IDF(term frequency times inverse document frequency):
2)若词项在整个语料库中出现的次数越多,那么对于某一篇文章而言这个词就越没有意义,即越不重要。我们用逆文档频率idf来表示这个词在整个语料库中的重要程度,故,出现越多的词,idf值会越低,出现越少的词,idf值会越高 IDF = log(N/d) ,其中N为所有文档的总数;d为出现过某个单词的文档的总数。
在现实中,词项在语料中的频率往往呈指数型。一个常用词出现的次数往往是一个次常用词出现次数的几十倍,这样常用词的权重会非常低(如“的”这样的词N/D几乎可能几乎等于1),故我们对逆文档频率取对数log,如此,文档频率的差别就从乘数变成了加数级了。即,我们在计算词项在一个文档中的重要程度,要考虑以上两个因素,用TF-IDF值来共同衡量 :
数学概念:
1)马尔科夫假设是指,每个词出现的概率只跟它前面的少数几个词有关。比如,二阶马尔科夫假设只考虑前面两个词,相应的语言模型是三元模型。引入了马尔科夫假设的语言模型,也可以叫做马尔科夫模型,产生了n-gram语言模型。
2)统计语言模型(Statistical Language Model)
假定S表示某个有意义的句子,由一连串特定顺序排列的词ω1,ω2,...,ωn组成,这里n是句子的长度。现在,我们想知道S在文本中出现的可能性,即S的概率P(S),则P(S)=P(ω1,ω2,...,ωn)。利用条件概率的公式:

1、One-hot Representation
这种方法把每个词表示为一个很长的向量。这个向量的维度是词表大小,其中绝大多数元素为 0,只有一个维度的值为 1,这个维度就代表了当前的词。方法简单,然这种表示方法也存在一个重要的问题就是“词汇鸿沟”现象:任意两个词之间都是孤立的。从数学上解释,正交基的积为0。
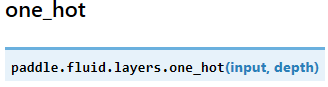
- 参数:
-
-
- input (Variable)-输入指数,最后维度必须为1
- depth (scalar)-整数,定义one-hot维度的深度
-
返回:输入的one-hot表示
返回类型:变量(Variable)
例如:有如下三个特征属性:
性别:[“male”,”female”]
地区:[“Europe”,”US”,”Asia”]
浏览器:[“Firefox”,”Chrome”,”Safari”,”Internet Explorer”]。对于这样的特征,如果采用机器学习进行学习,通常我们需要对其进行特征数字化。
import numpy
label = fluid.layers.data(name="X", shape=[1], dtype="int64")
one_hot_label = fluid.layers.one_hot(input=label, depth=10)
结果解释:可以采用One-Hot编码的方式对上述的样本“[“male”,”US”,”Internet Explorer”]”编码,“male”则对应着[1,0],同理“US”对应着[0,1,0],“Internet Explorer”对应着[0,0,0,1]。则完整的特征数字化的结果为:[1,0,0,1,0,0,0,0,1]。这样导致的一个结果就是数据会变得非常的稀疏。
2、基于SVD(奇异值分解)的方法
为了找到词嵌入(word embeddings,可以简单的理解为与词向量等价),可以首先遍历巨大的语料库,统计两个词之间某种形式的共现次数,并将统计值保存在一个矩阵XX中。然后应用奇异值分解:X=USVTX=USVT。我们使用UU中的每一行作为每个词的词嵌入。
用这种方式生成的词向量保留了足够多的语法和语义信息,但也还是存在一些问题:
-
- 矩阵维度经常变动,比如新词频繁加入。
- 由于绝大部分词并不会共现,造成矩阵过于稀疏。
- 矩阵维度一般很高,大约106×106106×106。
- 并且难以合并新词或新的文档。对于一个m×nm×n矩阵,训练时的计算复杂度是O(mn2)O(mn2)
- 由于词频的极度不平衡,需要对矩阵XX应用一些黑科技。
上述问题的一些解决方案:
-
- 忽略the、he、has等虚词。
- 应用一个斜坡窗口(ramp window,也就是说,不再对窗口内的所有词一视同仁)——比如,根据距离当前词的距离,对共现次数赋予相应的权重。
- 使用皮尔逊相关系数(Pearson correlation coefficient),取代直接计数。
3、基于迭代的方法——Word2vec
- 两个算法:continuous bag-of-words (CBOW)和skip-gram。CBOW是给定上下文环境时,预测该环境中间的那个中心词。Skip-gram正好相反,预测一个中心词上下文环境的分布,其图示如下。
- 两个训练方法:负采样(negative sampling)和分层softmax。
3.1 n-gram model
n-gram模型也是统计语言模型中的一种重要方法,用n-gram训练语言模型时,一般用每个n-gram的历史n-1个词语组成的内容来预测第n个词。
3.2 Neural Network Language Model,NNLM
通过一个线性映射和一个非线性隐层连接,同时学习了语言模型和词向量,即通过学习大量语料得到词语的向量表达,通过这些向量得到整个句子的概率。因所有的词语都用一个低维向量来表示,用这种方法学习语言模型可以克服维度灾难(curse of dimensionality)。
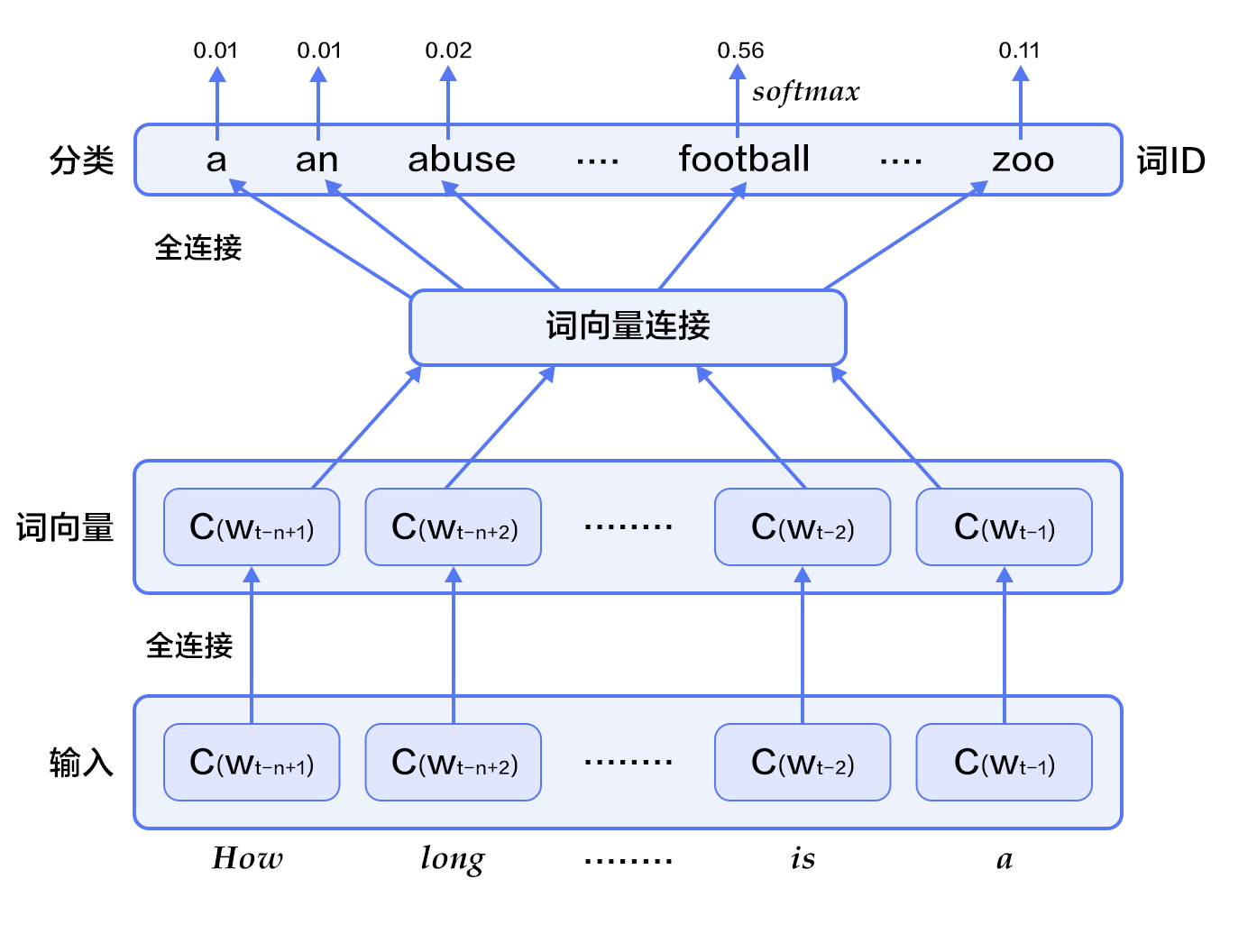
3.3 Continuous Bag of Words Model,CBOW
CBOW模型通过一个词的上下文(各N个词)预测当前词。当N=2时,模型如下图所示:
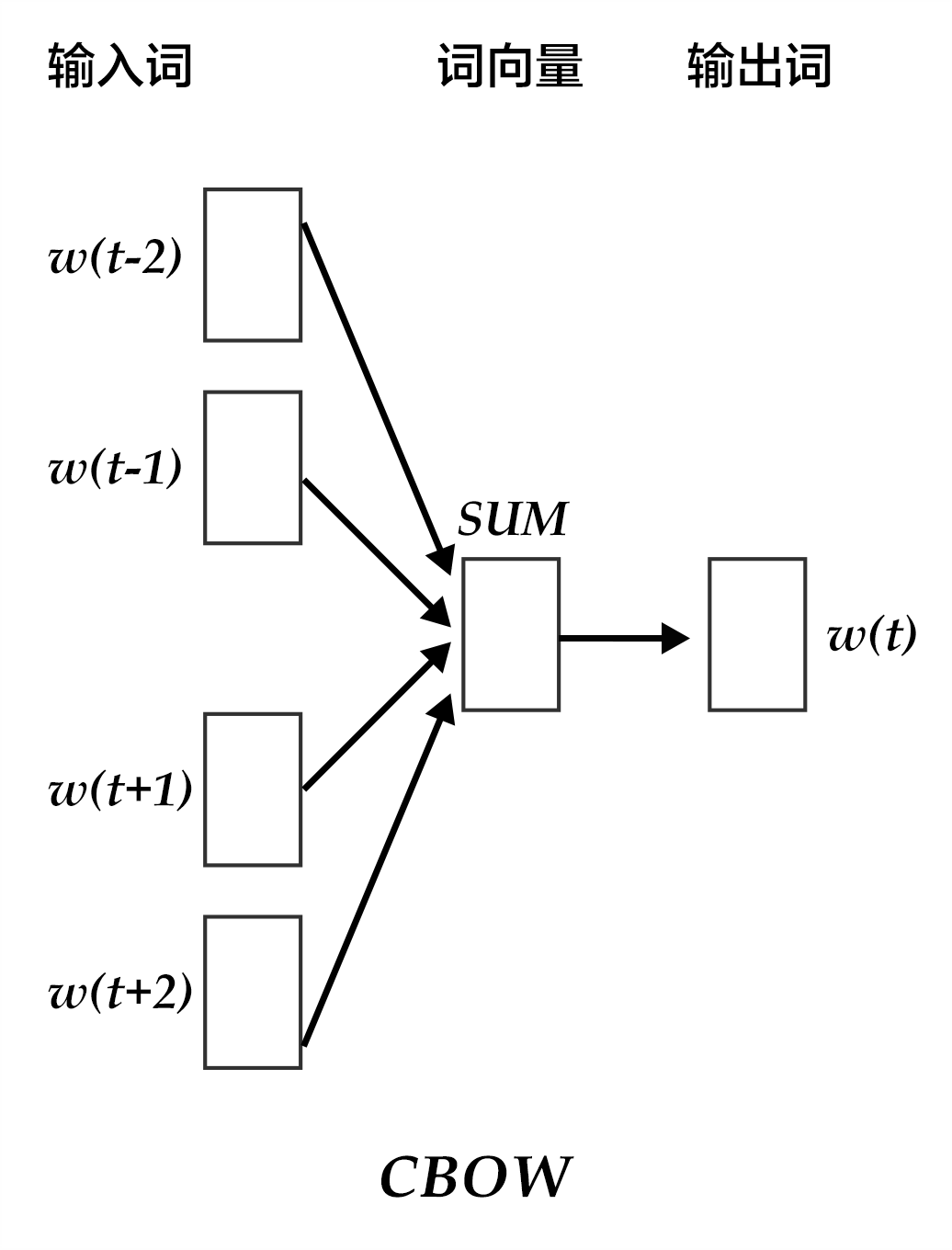
CBOW的好处是对上下文词语的分布在词向量上进行了平滑,去掉了噪声,因此在小数据集上很有效。假设cc是目标值one-hot向量为1的位置的索引,损失函数:

3.4 Skip-gram model
而Skip-gram的方法中,用一个词预测其上下文,得到了当前词上下文的很多样本,因此可用于更大的数据集。

在条件概率相互独立下,定义损失函数:
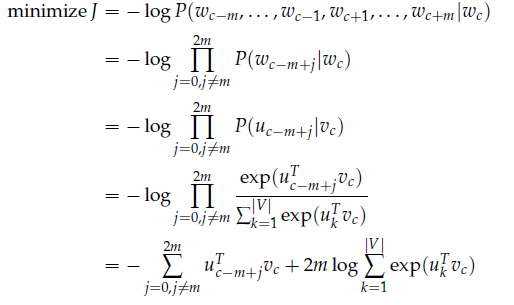
4、案例分析及实现:
本配置的N-gram 神经网络模型结构如下图所示:

PaddlePaddle提供了一个内置的方法fluid.layers.embedding,我们就可以直接用它来构造 N-gram 神经网络。

嵌入层(Embedding Layer)
该层用于查找由输入提供的id在查找表中的嵌入矩阵。查找的结果是input里每个ID对应的嵌入矩阵。 所有的输入变量都作为局部变量传入LayerHelper构造器
- 参数:
-
-
- input (Variable)-包含IDs的张量
- size (tuple|list)-查找表参数的维度。应当有两个参数,一个代表嵌入矩阵字典的大小,一个代表每个嵌入向量的大小。
- is_sparse (bool)-代表是否用稀疏更新的标志
- is_distributed (bool)-是否从远程参数服务端运行查找表
- padding_idx (int|long|None)-如果为
None,对查找结果无影响。如果padding_idx不为空,表示一旦查找表中找到input中对应的padding_idz,则用0填充输出结果。如果 padding_idx<0padding_idx<0 ,在查找表中使用的padding_idx值为 size[0]+dimsize[0]+dim 。 - param_attr (ParamAttr)-该层参数
- dtype (np.dtype|core.VarDesc.VarType|str)-数据类型:float32,float_16,int等。
-
返回:张量,存储已有输入的嵌入矩阵。
返回类型:变量(Variable)
1.训练代码,包括数据预处理
import paddle as paddle import paddle.fluid as fluid import six import numpy import math EMBED_SIZE = 32 # embedding维度 HIDDEN_SIZE = 256 # 隐层大小 N = 5 # ngram大小,这里固定取5 BATCH_SIZE = 100 # batch大小 PASS_NUM = 100 # 训练轮数 use_cuda = False # 如果用GPU训练,则设置为True word_dict = paddle.dataset.imikolov.build_dict() dict_size = len(word_dict) def inference_program(words, is_sparse): embed_first = fluid.layers.embedding( input=words[0], size=[dict_size, EMBED_SIZE], dtype='float32', is_sparse=is_sparse, param_attr='shared_w') embed_second = fluid.layers.embedding( input=words[1], size=[dict_size, EMBED_SIZE], dtype='float32', is_sparse=is_sparse, param_attr='shared_w') embed_third = fluid.layers.embedding( input=words[2], size=[dict_size, EMBED_SIZE], dtype='float32', is_sparse=is_sparse, param_attr='shared_w') embed_fourth = fluid.layers.embedding( input=words[3], size=[dict_size, EMBED_SIZE], dtype='float32', is_sparse=is_sparse, param_attr='shared_w') concat_embed = fluid.layers.concat( input=[embed_first, embed_second, embed_third, embed_fourth], axis=1) hidden1 = fluid.layers.fc(input=concat_embed, size=HIDDEN_SIZE, act='sigmoid') predict_word = fluid.layers.fc(input=hidden1, size=dict_size, act='softmax') return predict_word def train_program(predict_word): # 'next_word'的定义必须要在inference_program的声明之后, # 否则train program输入数据的顺序就变成了[next_word, firstw, secondw, # thirdw, fourthw], 这是不正确的. next_word = fluid.layers.data(name='nextw', shape=[1], dtype='int64') cost = fluid.layers.cross_entropy(input=predict_word, label=next_word) avg_cost = fluid.layers.mean(cost) return avg_cost def optimizer_func(): return fluid.optimizer.AdagradOptimizer( learning_rate=3e-3, regularization=fluid.regularizer.L2DecayRegularizer(8e-4)) def train(if_use_cuda, params_dirname, is_sparse=True): place = fluid.CUDAPlace(0) if if_use_cuda else fluid.CPUPlace() train_reader = paddle.batch( paddle.dataset.imikolov.train(word_dict, N), BATCH_SIZE) test_reader = paddle.batch( paddle.dataset.imikolov.test(word_dict, N), BATCH_SIZE) first_word = fluid.layers.data(name='firstw', shape=[1], dtype='int64') second_word = fluid.layers.data(name='secondw', shape=[1], dtype='int64') third_word = fluid.layers.data(name='thirdw', shape=[1], dtype='int64') forth_word = fluid.layers.data(name='fourthw', shape=[1], dtype='int64') next_word = fluid.layers.data(name='nextw', shape=[1], dtype='int64') word_list = [first_word, second_word, third_word, forth_word, next_word] feed_order = ['firstw', 'secondw', 'thirdw', 'fourthw', 'nextw'] main_program = fluid.default_main_program() star_program = fluid.default_startup_program() predict_word = inference_program(word_list, is_sparse) avg_cost = train_program(predict_word) test_program = main_program.clone(for_test=True) sgd_optimizer = optimizer_func() sgd_optimizer.minimize(avg_cost) exe = fluid.Executor(place) def train_test(program, reader): count = 0 feed_var_list = [ program.global_block().var(var_name) for var_name in feed_order ] feeder_test = fluid.DataFeeder(feed_list=feed_var_list, place=place) test_exe = fluid.Executor(place) accumulated = len([avg_cost]) * [0] for test_data in reader(): avg_cost_np = test_exe.run( program=program, feed=feeder_test.feed(test_data), fetch_list=[avg_cost]) accumulated = [ x[0] + x[1][0] for x in zip(accumulated, avg_cost_np) ] count += 1 return [x / count for x in accumulated] def train_loop(): step = 0 feed_var_list_loop = [ main_program.global_block().var(var_name) for var_name in feed_order ] feeder = fluid.DataFeeder(feed_list=feed_var_list_loop, place=place) exe.run(star_program) for pass_id in range(PASS_NUM): for data in train_reader(): avg_cost_np = exe.run( main_program, feed=feeder.feed(data), fetch_list=[avg_cost]) if step % 10 == 0: outs = train_test(test_program, test_reader) print("Step %d: Average Cost %f" % (step, outs[0])) # 整个训练过程要花费几个小时,如果平均损失低于5.8, # 我们就认为模型已经达到很好的效果可以停止训练了。 # 注意5.8是一个相对较高的值,为了获取更好的模型,可以将 # 这里的阈值设为3.5,但训练时间也会更长。 if outs[0] < 5.8: if params_dirname is not None: fluid.io.save_inference_model(params_dirname, [ 'firstw', 'secondw', 'thirdw', 'fourthw' ], [predict_word], exe) return step += 1 if math.isnan(float(avg_cost_np[0])): sys.exit("got NaN loss, training failed.") raise AssertionError("Cost is too large {0:2.2}".format(avg_cost_np[0])) train_loop()
预测代码:
def infer(use_cuda, params_dirname=None):
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
exe = fluid.Executor(place)
inference_scope = fluid.core.Scope()
with fluid.scope_guard(inference_scope):
# 使用fluid.io.load_inference_model获取inference program,
# feed变量的名称feed_target_names和从scope中fetch的对象fetch_targets
[inferencer, feed_target_names,
fetch_targets] = fluid.io.load_inference_model(params_dirname, exe)
# 设置输入,用四个LoDTensor来表示4个词语。这里每个词都是一个id,
# 用来查询embedding表获取对应的词向量,因此其形状大小是[1]。
# recursive_sequence_lengths设置的是基于长度的LoD,因此都应该设为[[1]]
# 注意recursive_sequence_lengths是列表的列表
data1 = numpy.asarray([[211]], dtype=numpy.int64) # 'among'
data2 = numpy.asarray([[6]], dtype=numpy.int64) # 'a'
data3 = numpy.asarray([[96]], dtype=numpy.int64) # 'group'
data4 = numpy.asarray([[4]], dtype=numpy.int64) # 'of'
lod = numpy.asarray([[1]], dtype=numpy.int64)
first_word = fluid.create_lod_tensor(data1, lod, place)
second_word = fluid.create_lod_tensor(data2, lod, place)
third_word = fluid.create_lod_tensor(data3, lod, place)
fourth_word = fluid.create_lod_tensor(data4, lod, place)
assert feed_target_names[0] == 'firstw'
assert feed_target_names[1] == 'secondw'
assert feed_target_names[2] == 'thirdw'
assert feed_target_names[3] == 'fourthw'
# 构造feed词典 {feed_target_name: feed_target_data}
# 预测结果包含在results之中
results = exe.run(
inferencer,
feed={
feed_target_names[0]: first_word,
feed_target_names[1]: second_word,
feed_target_names[2]: third_word,
feed_target_names[3]: fourth_word
},
fetch_list=fetch_targets,
return_numpy=False)
print(numpy.array(results[0]))
most_possible_word_index = numpy.argmax(results[0])
print(most_possible_word_index)
print([
key for key, value in six.iteritems(word_dict)
if value == most_possible_word_index
][0])
5.存在问题及改进工作
存在问题:现在主要理解别人的实现,处于归纳、总结,还没有个人的创新。
后续工作还有基于循环神经网络的语言模型的实现、与tensorflow的对比实验。
从目前我个人的使用情况,觉得tensorflow暂时要比paddlepaddle好用,主要是paddlepaddle真正的参考书籍少,还有功能方面前者要灵活一些。至于性能对比,后续工作将进行对比实验。