Table of Contents
概述
文本表示是自然语言处理中的基础工作,文本表示的好坏直接影响到整个自然语言处理系统的性能。文本向量化就是将文本表示成一系列能够表达文本语义的向量,是文本表示的一种重要方式。目前对文本向量化大部分的研究都是通过词向量化实现的,也有一部分研究者将句子作为文本处理的基本单元,于是产生了doc2vec和str2vec技术。
word2vec
词袋(Bag Of Word)模型是最早的以词语为基础处理单元的文本项量化方法。该模型产生的向量与原来文本中单词出现的顺序没有关系,而是词典中每个单词在文本中出现的频率。该方法虽然简单易行,但是存在如下三个方面的问题:维度灾难,无法保留词序信息,存在语义鸿沟。
随着互联网技术的发展,大量无标注数据的产生,研究重心转移到利用无标注数据挖掘有价值的信息上来。词向量(word2vec)技术就是为了利用神经网络,从大量无标注的文本中提取有用的信息而产生的。
词袋模型只是将词语符号化,所以词袋模型是不包含任何语义信息的。如何使“词表示”包含语义信息是该领域研究者面临的问题。分布假设(distributional hypothesis)的提出为解决上述问题提供了理论基础。该假设的核心思想是:上下文相似的词,其语义也相似。随后有学者整理了利用上下文表示词义的方法,这类方法就是有名的词空间模型(word space model)。通过语言模型构建上下文与目标词之间的关系,是一种常见的方法,神经网络词向量模型就是根据上下文与目标词之间的关系进行建模。
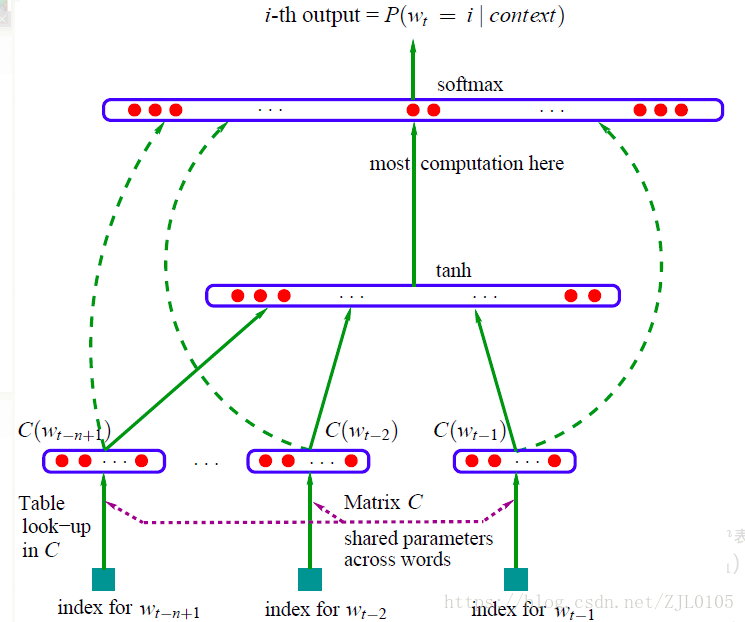
NNLM
神经网络语言模型(Neural Network Language Model,NNLM)与传统方法估算的不同在于直接通过一个神经网络结构对n元条件概率进行估计。由于NNLM模型使用低维紧凑的词向量对上下文进行表示,解决了词袋模型带来的数据稀疏、语义鸿沟等问题。另一方面,在相似的上下文语境中,NNLM模型可以预测出相似的目标词,而传统模型无法做到这一点。例如,如果在预料中A=“小狗在院子里趴着”出现1000次,B=“小猫在院子里趴着”出现1次。A和B的唯一区别就是狗和猫,两个词无论在语义还是语法上都相似。根据频率来估算概率P(A)>>P(B),这显然不合理。如果采用NNLM计算P(A)~P(B),因为NNLM模型采用低维的向量表示词语,假定相似的词其词向量也相似。
C&W
C&W(context&word,上下文和目标词)主要目的并不在于生成一份好的词向量,甚至不想训练语言模型,而是要用这份词向量去完成 NLP 里面的各种任务,比如词性标注、命名实体识别、短语识别、语义角色标注等等。NNLM模型的目标是构建一个语言概率模型,而C&W则是以生成词向量为目标的模型。C&W模型并没有采用语言模型去求解词语上下文的条件概率,而是直接对n元短语打分,这就省去了NNLM模型中从隐藏层到输出层的权重计算,大大降低了运算量。其核心机理是:如果n元短语在语料库中出现过,那么模型会给该短语打高分;如果是未出现在语料库中的短语则会得到较低的评分。
CBOW and Skip-gram
为了更高效地获取词向量,研究者在NNLM和C&W模型的基础上保留其核心部分,得到了CBOW(Continuous Bag of Words)模型和Skip-gram模型。

CBOW模型使用一段文本的中间词作为目标词,去掉了隐藏层,大幅度提升了计算速率。此外,COBW模型还使用上下文各词的词向量的平均值替代NNLM模型各个拼接的词向量。即根据上下文来预测当前词语的概率,且上下文所有词对当前词出现概率的影响权重是一样的。Skip-gram模型同样没有隐藏层,与CBOW模型输入上下文词的平均词向量不同,它时从目标词w的上下文中选择一个词,将其词向量组成上下文的表示。即根据当前词语来预测上下文概率。
doc2vec/str2vec
利用world2vec计算词语间的相似度有非常好的效果,word2vec技术也可以用于计算句子或者其他长文本间的相似度,其一般做法是对文本分词后,提取其关键词,用词向量表示这些关键词,接着对关键词向量求平均或者将其拼接,最后利用词向量计算文本间的相似度。这种方法丢失了文本中的语序信息,而文本的语序包含重要信息。为此,有研究者在word2vec的基础上提出了文本向量化(doc2vec),又称str2vec和para2vec。
doc2vec技术存在两种模型--Distributed Memory(DM)和Distributed Bag of Words(DBOW),分别对应word2vec技术里的CBOW和Skip-gram模型。Doc2vec 相对于 word2vec 不同之处在于,在输入层,增添了一个新句子向量Paragraph vector,Paragraph vector 可以被看作是另一个词向量,它扮演了一个记忆,词袋模型中,因为每次训练只会截取句子中一小部分词训练,而忽略了除了本次训练词以外该句子中的其他词,这样仅仅训练出来每个词的向量表达,句子只是每个词的向量累加在一起表达的。正如上文所说的词袋模型的缺点,忽略了文本的词序问题。而 Doc2vec 中的 Paragraph vector 则弥补了这方面的不足,它每次训练也是滑动截取句子中一小部分词来训练,Paragraph Vector 在同一个句子的若干次训练中是共享的,所以同一句话会有多次训练,每次训练中输入都包含 Paragraph vector。它可以被看作是句子的主旨,有了它,该句子的主旨每次都会被放入作为输入的一部分来训练。这样每次训练过程中,不光是训练了词,得到了词向量。同时随着一句话每次滑动取若干词训练的过程中,作为每次训练的输入层一部分的共享 Paragraph vector,该向量表达的主旨会越来越准确。

DM模型示意图
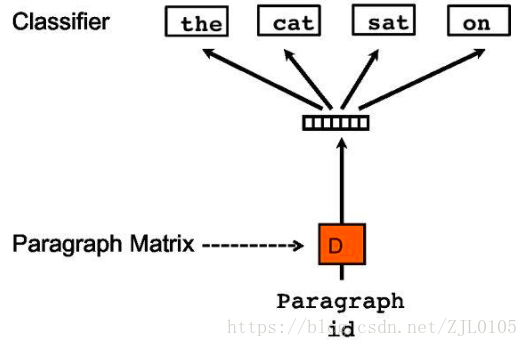
DBOW模型示意图
那么 Doc2vec 是怎么预测新的句子 Paragraph vector 呢?其实在预测新的句子的时候,还是会将该 Paragraph vector 随机初始化,放入模型中再重新根据随机梯度下降不断迭代求得最终稳定下来的句子向量。不过在预测过程中,模型里的词向量还有投影层到输出层的 softmax weights 参数是不会变的,这样在不断迭代中只会更新 Paragraph vector,其他参数均已固定,只需很少的时间就能计算出带预测的 Paragraph vector。