一.smote相关理论
(1).
SMOTE是一种对普通过采样(oversampling)的一个改良。普通的过采样会使得训练集中有很多重复的样本。
SMOTE的全称是Synthetic Minority Over-Sampling Technique,译为“人工少数类过采样法”。
SMOTE没有直接对少数类进行重采样,而是设计了算法来人工合成一些新的少数类的样本。
为了叙述方便,就假设阳性为少数类,阴性为多数类
合成新少数类的阳性样本的算法如下:
- 选定一个阳性样本ss
- 找到ss最近的kk个样本,kk可以取5,10之类。这kk个样本可能有阳性的也有阴性的。
- 从这kk个样本中随机挑选一个样本,记为rr。
- 合成一个新的阳性样本s′s′,s′=λs+(1−λ)rs′=λs+(1−λ)r,λλ是(0,1)(0,1)之间的随机数。换句话说,新生成的点在rr与ss之间的连线上。
重复以上步骤,就可以生成很多阳性样本。
=======画了几张图,更新一下======
用图的形式说明一下SMOTE的步骤:
1.先选定一个阳性样本(假设阳性为少数类)

2.找出这个阳性样本的k近邻(假设k=5)。5个近邻已经被圈出。

3.随机从这k个近邻中选出一个样本(用绿色圈出来了)。

4.在阳性样本和被选出的这个近邻之间的连线上,随机找一点。这个点就是人工合成的新的阳性样本(绿色正号标出)。

以上来自http://sofasofa.io/forum_main_post.php?postid=1000817中的叙述
(2).
With this approach, the positive class is over-sampled by taking each minority class sample and introducing synthetic examples along the line segments joining any/all of the k minority class nearest neighbours. Depending upon the amount of over-sampling required, neighbours from the k nearest neighbours are randomly chosen. This process is illustrated in the following Figure, where xixi is the selected point, xi1xi1 to xi4xi4are some selected nearest neighbours and r1r1 to r4r4 the synthetic data points created by the randomized interpolation. The implementation of this work uses only one nearest neighbour with the euclidean distance, and balances both classes to 50% distribution.
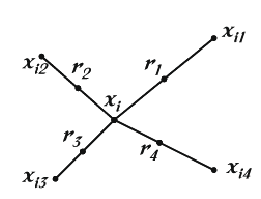
Synthetic samples are generated in the following way: Take the difference between the feature vector (sample) under consideration and its nearest neighbour. Multiply this difference by a random number between 0 and 1, and add it to the feature vector under consideration. This causes the selection of a random point along the line segment between two specific features. This approach effectively forces the decision region of the minority class to become more general. An example is detailed in the next Figure.

In short, the main idea is to form new minority class examples by interpolating between several minority class examples that lie together. In contrast with the common replication techniques (for example random oversampling), in which the decision region usually become more specific, with SMOTE the overfitting problem is somehow avoided by causing the decision boundaries for the minority class to be larger and to spread further into the majority class space, since it provides related minority class samples to learn from. Specifically, selecting a small k-value could also avoid the risk of including some noise in the data.
以上来自https://sci2s.ugr.es/multi-imbalanced中的叙述
二.spark实现smote