分类目录:《深入理解机器学习》总目录
针对随机采样技术的缺点,人们陆续开发出了一些更为高级的采样算法,这类算法均或多或少地利用了样本的局部先验分布信息,并利用这些信息,通过人工干预的方式来移除多数类样本或添加人工合成的少数类样本,从而达到了提升分类性能的目的。在此,我们将此类算法统称为“人工采样技术”。本文及后续文章将对此类技术中最具代表性的五种算法做展开介绍。
SMOTE(Synthetic Minority Oversampling Technique)算法于2002年为Chawla等人所提出,主要用于解决ROS采样法易于陷入过适应的问题。不同于ROS算法,SMOTE算法不再简单地复制少数类样本,而是通过一定策略生成大量新样本的方式来谋求训练样本集类分布的平衡。当然,为了保证样本原始分布不被严重破坏,必须确定某种规则来保证新生成样本的合理性。一般而言,抛除噪声的因素不谈,我们所常见的样本集在属性空间中往往都存在以下特性:某类样本往往趋于出现在同类样本附近,即同类样本的邻域区间当中。
SMOTE算法即以上述经验为准则,在原有少数类样本的邻域空间中填充新样本。在SMOTE算法中,邻域空间的确定采用了最为简单的K近邻法,即首先在少数类样本中随机选择一个主样本 x x x,然后在剩余全部少数类样本中找到它的K近邻样本,从中随机选取一个主近邻样本 x ′ x' x′,进而在主样本 x x x与其主近邻样本 x ′ x' x′的连接线的某个随机位置上生成新样本:
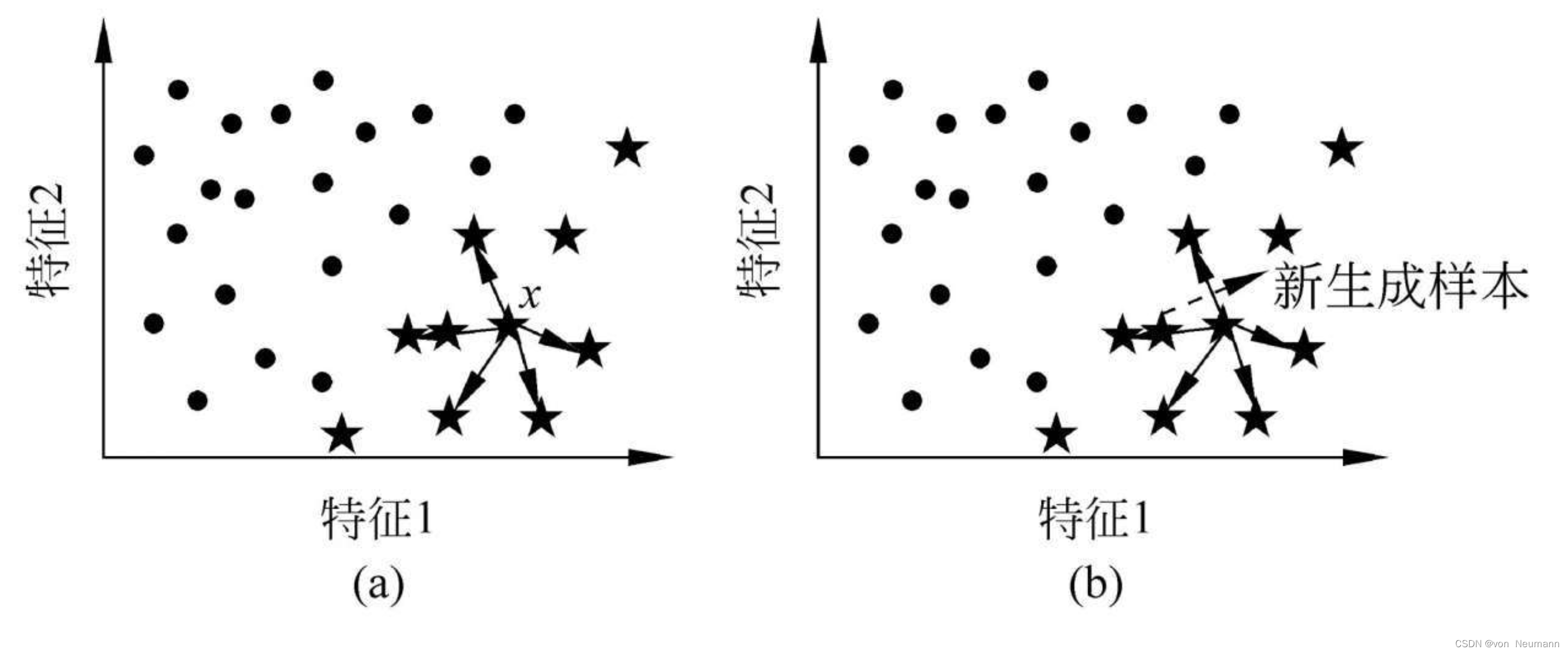
从上图中不难看出,采用SMOTE算法所新生成的样本往往都出现在少数类的决策空间内,从而足以保证其合理性。此外,新生成的样本与原始样本不再是简单的覆盖关系,这就可以保证经SMOTE算法处理后的训练集可近似逼近原始少数类样本训练集的分布,从而在一定程度上避免后期所训练的分类器出现过适应的现象。SMOTE算法的基本流程如下:
SMOTE(Synthetic Minority Oversampling Technique)算法
输入:训练集 S = { ( x i , y i ) , i = 1 , 2 , ⋯ , N , y i ∈ { + , − } } S=\{(x_i, y_i), i=1, 2, \cdots, N, y_i\in\{+, -\}\} S={ (xi,yi),i=1,2,⋯,N,yi∈{ +,−}};多数类样本数 N − N^- N−,少数类样本数 N + N^+ N+,其中 N − + N + = N N^-+N^+=N N−+N+=N;不平衡比率 IR = N − N + \text{IR}=\frac{N^-}{N^+} IR=N+N−;采样率 SR \text{SR} SR;邻近参数 K K K
输出:过采样后的训练集 S = { ( x i , y i ) , i = 1 , 2 , ⋯ , N + N + × SR , y i ∈ { + , − } } S=\{(x_i, y_i), i=1, 2, \cdots, N+N^+\times \text{SR}, y_i\in\{+, -\}\} S={ (xi,yi),i=1,2,⋯,N+N+×SR,yi∈{ +,−}}
( 1 ) 从训练集 S S S中取出全部多数类与少数类样本,组成多数类训练样本集 S − S^- S−及少数类训练样本集 S + S^+ S+
( 2 ) 置新生成样本集 S New S^\text{New} SNew为空
( 3 ) for i = 1 : N + × SR i=1:N^+\times \text{SR} i=1:N+×SR
( 4 ) \quad 在 [ 1 , N + ] [1, N^+] [1,N+]之间随机选择一个数字,于 S + S^+ S+中找到对应的样本 x x x
( 5 ) \quad 在 S + S^+ S+中找到主样本 x x x的 K K K近邻样本,并将其置于近邻样本集 S Near S^\text{Near} SNear中
( 6 ) \quad 在 [ 1 , K ] [1, K] [1,K]之间随机选择一个数字,并在 S New S^\text{New} SNew中找到对应的主近邻样本 x ′ x' x′
( 7 ) \quad 计算新少数类样本: x new = x + rand × ( x ′ − x ) x^\text{new}=x+\text{rand}\times (x'-x) xnew=x+rand×(x′−x),其中 rand ∈ [ 0 , 1 ] \text{rand}\in[0, 1] rand∈[0,1]
( 8 ) \quad 添加 x new x^\text{new} xnew至 S New S^\text{New} SNew: S New = S New ∪ x new S^\text{New}=S^\text{New}\cup x^\text{new} SNew=SNew∪xnew
( 9 ) \quad 置近邻样本集 S Near S^\text{Near} SNear为空
(10) return 过采样后的训练集 S ′ = S − ∪ S New S'=S^-\cup S^\text{New} S′=S−∪SNew
特别需要说明的是,近邻参数 K K K在SMOTE算法中是最为重要的一个参数,其设置得合理与否将直接影响到最终的分类性能,通常情况下, K K K取值为5。此外,尽管SMOTE算法有诸多优点,但也存在三个不可回避的缺点:
- 由于涉及大量的近邻关系运算,其时间复杂度过高
- 当少数类样本中含有较多噪声信息时,SMOTE算法会受其干扰,将噪声信息进一步传播,从而影响到分类的性能
- 由于每轮主样本的选取是完全随机的,故当少数类样本数较少时,可能会造成各原始少数类样本被选作主样本的频次差较大,从而偏离原始的样本分布。
Borderline-SMOTE采样法
Han等人注意到对分类面起决定作用的往往是那些处于分类边界上的样本,即处于类重叠区域或在这一区域附近的样本,因此,他们认为在全部少数类样本上运行SMOTE算法是没有必要的,只需要在边界区域生成新的少数类样本即可。他们所提出的改进算法为Borderline-SMOTE算法,即边界线SMOTE算法。在Borderline-SMOTE算法中,少数类样本被归为以下互不相交的三类:
- 安全样本:即远离边界区域,且处于少数类决策区域的样本
- 边界样本:即处于决策边界附近的样本
- 噪声样本:即远离边界区域,且处于多数类决策区域的样本。
Borderline-SMOTE算法给出了这三类样本的确定条件:首先,在整个训练集 S S S上确定每个少数类样本 x i + ( i = 1 , 2 , 3 , ⋯ , N + ) x^+_i(i=1, 2, 3,\cdots, N^+) xi+(i=1,2,3,⋯,N+)的 K K K近邻,其中,多数类近邻数记为 N major N^{\text{major}} Nmajor,若:
- N major < K 2 N^{\text{major}} < \frac{K}{2} Nmajor<2K:表明该样本的少数类近邻多于多数类近邻,该样本为处于少数类决策区域的安全样本,可以移除
- K 2 ≤ N major < K \frac{K}{2} \leq N^{\text{major}} < K 2K≤Nmajor<K:表明该样本的少数类近邻少于多数类近邻,该样本很可能处于决策边界附近,将其保留到一个命名为DANGER的样本集中
- N major = K N^{\text{major}} = K Nmajor=K:表明该样本的全部近邻样本均来自于多数类,极有可能处于多数类决策区域,应将其视为噪声样本,需移除。
下图给出了上述三类样本的判别示例: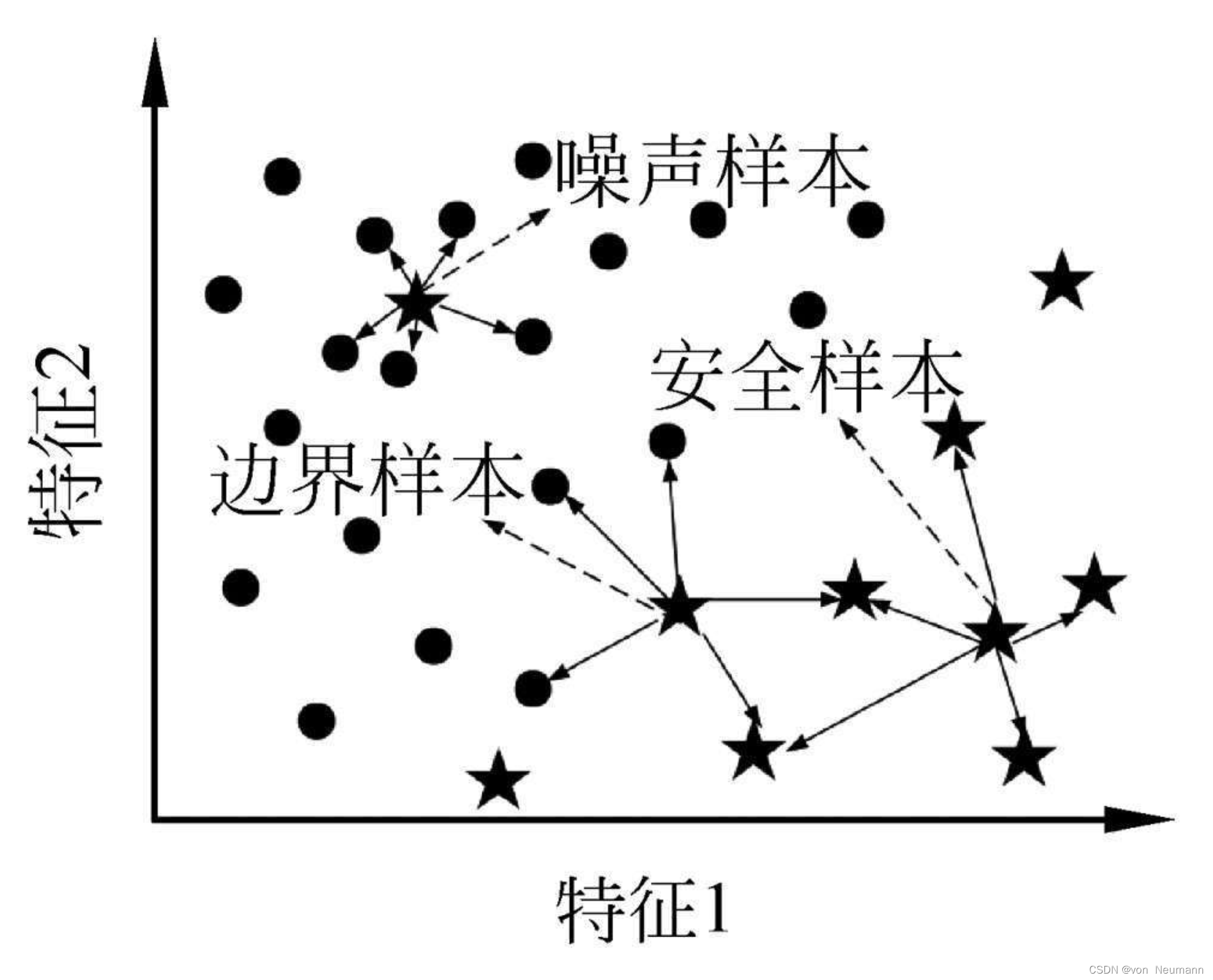
在经过上述判别操作后,仅对DANGER集中保留的少数类样本进行SMOTE操作即可,所生成的新样本均处于决策边界附近。特别地,Borderline-SMOTE算法有两个不同的版本,可分别将其命名为BSO1算法及BSO2算法,它们的具体流程分别描述如下:
BSO1算法
输入:训练集 S = { ( x i , y i ) , i = 1 , 2 , ⋯ , N , y i ∈ { + , − } } S=\{(x_i, y_i), i=1, 2, \cdots, N, y_i\in\{+, -\}\} S={ (xi,yi),i=1,2,⋯,N,yi∈{ +,−}};多数类样本数 N − N^- N−,少数类样本数 N + N^+ N+,其中 N − + N + = N N^-+N^+=N N−+N+=N;不平衡比率 IR = N − N + \text{IR}=\frac{N^-}{N^+} IR=N+N−;采样率 SR \text{SR} SR;邻近参数 K K K
输出:过采样后的训练集 S = { ( x i , y i ) , i = 1 , 2 , ⋯ , N + N + × SR , y i ∈ { + , − } } S=\{(x_i, y_i), i=1, 2, \cdots, N+N^+\times \text{SR}, y_i\in\{+, -\}\} S={ (xi,yi),i=1,2,⋯,N+N+×SR,yi∈{ +,−}}
( 1 ) 从训练集 S S S中取出全部多数类与少数类样本,组成多数类训练样本集 S − S^- S−及少数类训练样本集 S + S^+ S+
( 2 ) 置新生成样本集 S New S^\text{New} SNew为空+
( 3 ) 置DANGER集为空
( 4 ) for i = 1 : N + i=1:N^+ i=1:N+
( 5 ) \quad 在 S + S^+ S+中找到对应样本 x i x_i xi
( 6 ) \quad 在 S S S中找到 x i x_i xi的 K K K近邻,记录其多数类近邻数为 N major N^{\text{major}} Nmajor
( 7 ) 若 K 2 ≤ N major < K \frac{K}{2} \leq N^{\text{major}} < K 2K≤Nmajor<K,则将 x i x_i xi加入 DANGER \text{DANGER} DANGER,即: DANGER = DANGER ∪ x i \text{DANGER} = \text{DANGER}\cup x_i DANGER=DANGER∪xi
( 8 ) for i = 1 : N + × SR i=1:N^+\times \text{SR} i=1:N+×SR
( 9 ) \quad 在DANGER集中随机选出一个主样本 x x x
(10) \quad 在 S + S^+ S+中找到主样本 x x x的 K K K近邻样本,并将其置于近邻样本集 S Near S^\text{Near} SNear中
(11) \quad 在 [ 1 , K ] [1, K] [1,K]之间随机选择一个数字,并在 S New S^\text{New} SNew中找到对应的主近邻样本 x ′ x' x′
(12) \quad 计算新少数类样本: x new = x + rand × ( x ′ − x ) x^\text{new}=x+\text{rand}\times (x'-x) xnew=x+rand×(x′−x),其中 rand ∈ [ 0 , 1 ] \text{rand}\in[0, 1] rand∈[0,1]
(13) \quad 添加 x new x^\text{new} xnew至 S New S^\text{New} SNew: S New = S New ∪ x new S^\text{New}=S^\text{New}\cup x^\text{new} SNew=SNew∪xnew
(14) \quad 置近邻样本集 S Near S^\text{Near} SNear为空
(15) return 过采样后的训练集 S ′ = S − ∪ S New S'=S^-\cup S^\text{New} S′=S−∪SNew
BSO2算法
输入:训练集 S = { ( x i , y i ) , i = 1 , 2 , ⋯ , N , y i ∈ { + , − } } S=\{(x_i, y_i), i=1, 2, \cdots, N, y_i\in\{+, -\}\} S={ (xi,yi),i=1,2,⋯,N,yi∈{ +,−}};多数类样本数 N − N^- N−,少数类样本数 N + N^+ N+,其中 N − + N + = N N^-+N^+=N N−+N+=N;不平衡比率 IR = N − N + \text{IR}=\frac{N^-}{N^+} IR=N+N−;采样率 SR \text{SR} SR;邻近参数 K K K
输出:过采样后的训练集 S = { ( x i , y i ) , i = 1 , 2 , ⋯ , N + N + × SR , y i ∈ { + , − } } S=\{(x_i, y_i), i=1, 2, \cdots, N+N^+\times \text{SR}, y_i\in\{+, -\}\} S={ (xi,yi),i=1,2,⋯,N+N+×SR,yi∈{ +,−}}
( 1 ) 从训练集 S S S中取出全部多数类与少数类样本,组成多数类训练样本集 S − S^- S−及少数类训练样本集 S + S^+ S+
( 2 ) 置新生成样本集 S New S^\text{New} SNew为空+
( 3 ) 置DANGER集为空
( 4 ) for i = 1 : N + i=1:N^+ i=1:N+
( 5 ) \quad 在 S + S^+ S+中找到对应样本 x i x_i xi
( 6 ) \quad 在 S S S中找到 x i x_i xi的 K K K近邻,记录其多数类近邻数为 N major N^{\text{major}} Nmajor
( 7 ) 若 K 2 ≤ N major < K \frac{K}{2} \leq N^{\text{major}} < K 2K≤Nmajor<K,则将 x i x_i xi加入 DANGER \text{DANGER} DANGER,即: DANGER = DANGER ∪ x i \text{DANGER} = \text{DANGER}\cup x_i DANGER=DANGER∪xi
( 8 ) for i = 1 : N + × SR i=1:N^+\times \text{SR} i=1:N+×SR
( 9 ) \quad 在DANGER集中随机选出一个主样本 x x x
(10) \quad 在 S S S中找到主样本 x x x的 K K K近邻样本,并将其置于近邻样本集 S Near S^\text{Near} SNear中
(11) \quad 在 [ 1 , K ] [1, K] [1,K]之间随机选择一个数字,并在 S New S^\text{New} SNew中找到对应的主近邻样本 x ′ x' x′
(12) \quad 计算新少数类样本: x new = x + rand × ( x ′ − x ) x^\text{new}=x+\text{rand}\times (x'-x) xnew=x+rand×(x′−x),其中 rand ∈ [ 0 , 0.5 ] \text{rand}\in[0, 0.5] rand∈[0,0.5]
(13) \quad 添加 x new x^\text{new} xnew至 S New S^\text{New} SNew: S New = S New ∪ x new S^\text{New}=S^\text{New}\cup x^\text{new} SNew=SNew∪xnew
(14) \quad 置近邻样本集 S Near S^\text{Near} SNear为空
(15) return 过采样后的训练集 S ′ = S − ∪ S New S'=S^-\cup S^\text{New} S′=S−∪SNew
从上述算法流程可以看出,BSO1算法与BSO2算法略有不同,前者继承了SMOTE算法的思想,在生成新样本时,仅利用了主样本的同类近邻信息,即仅在两个邻近的少数类样本间生成新样本,而后者则利用了整个训练集的邻域信息,即同时在多数类与少数类样本中寻找 K K K近邻,为了防止新生成的样本过于靠近多数类决策区域,该算法将随机数设为[0,0.5]区间,从而可以保证新生成的样本更靠近主样本,而非主近邻样本。
Borderline-SMOTE算法有效地克服了SMOTE算法的第2个缺点,即可有效规避原始噪声信息在新样本集上的传播,从而在一定程度上提升了SMOTE算法的分类性能。但同时,由于在计算K近邻时,加入了全部多数类样本的信息,这也将不可避免地进一步增加了算法的时间开销。