DynamoDB 流 是一项可选功能,用于捕获 DynamoDB 表中的数据修改事件。有关这些事件的数据将以事件发生的顺序近乎实时地出现在流中。
每个事件由一条流记录 表示。如果您对表启用流,则每当以下事件之一发生时,DynamoDB 流 都会写入一条流记录:
-
向表中添加了新项目:流将捕获整个项目的映像,包括其所有属性。
-
更新了项目:流将捕获项目中已修改的任何属性的“之前”和“之后”映像。
-
从表中删除了项目:流将在整个项目被删除前捕获其映像。
每条流记录还包含表的名称、事件时间戳和其他元数据。流记录具有 24 个小时的生命周期;在此时间过后,它们将从流中自动删除。
您可以将 DynamoDB 流 与 AWS Lambda 结合使用以创建触发器 — 在流中有您感兴趣的事件出现时自动执行的代码。例如,假设有一个包含某公司客户信息的 Customers 表。假设您希望向每位新客户发送一封“欢迎”电子邮件。您可对该表启用一个流,然后将该流与 Lambda 函数关联。Lambda 函数将在新的流记录出现时执行,但只会处理添加到 Customers 表的新项目。对于具有 EmailAddress 属性的任何项目,Lambda 函数将调用 Amazon Simple Email Service (Amazon SES) 以向该地址发送电子邮件。

注意
在此示例中,最后一位客户 Craig Roe 将不会收到电子邮件,因为他没有 EmailAddress。
除了触发器之外,DynamoDB 流 还提供了强大的解决方案,例如,AWS 区域内和跨 AWS 区域的数据复制、DynamoDB 表中的数据具体化视图、使用 Kinesis 具体化视图的数据分析等。
DynamoDB 支持表示数字、字符串或二进制值集的类型。集中的所有元素必须为相同类型。例如,数字集类型的属性只能包含数字,字符串集只能包含字符串,依此类推。
只要包含值的项目大小在 DynamoDB 项目大小限制 (400 KB) 内,集中的值的数量就没有限制。
当您的应用程序向 DynamoDB 表写入数据并收到 HTTP 200 响应 (OK) 时,该写入已发生并且持久。该数据最终将在所有存储位置中保持一致,通常只需一秒或更短时间。
DynamoDB 支持最终一致性 和强一致性 读取。
最终一致性读取
当您从 DynamoDB 表中读取数据时,响应反映的可能不是刚刚完成的写入操作的结果。响应可能包含某些陈旧数据。如果您在短时间后重复读取请求,响应将返回最新的数据。
强一致性读取
当您请求强一致性读取时,DynamoDB 会返回具有最新数据的响应,从而反映来自所有已成功的之前写入操作的更新。如果网络延迟或中断,可能会无法执行强一致性读取。全局二级索引 (GSI) 不支持一致性读取。
注意
除非您指定其他读取方式,否则 DynamoDB 将使用最终一致性读取。读取操作 (例如 GetItem,Query 和 Scan) 提供了一个 ConsistentRead 参数。如果您将此参数设置为 true,DynamoDB 将在操作过程中使用强一致性读取。
分区和数据分配
DynamoDB 将数据存储在分区。分区 是为表格分配的存储,由固态硬盘 (SSD) 提供支持,并可在 AWS 区域内的多个可用区中自动进行复制。分区管理由 DynamoDB 全权负责 — 您从不需要亲自管理分区。
在您创建表时,表的初始状态为 CREATING。在此期间,DynamoDB 会向表分配足够的分区,以便满足预置吞吐量需求。表的状态变为 ACTIVE 后,您可开始读取和写入表数据。
在以下情况下,DynamoDB 会向表分配额外的分区:
-
您增加的表的预置吞吐量设置超出了现有分区的支持能力。
-
现有分区填充已达到容量上限,并且需要更多的存储空间。
分区管理在后台自动进行,对程序是透明的。您的表将保留可用吞吐量并完全支持预置吞吐量需求。
有关更多详细信息,请参阅分区键设计。
DynamoDB 中的Global secondary index还包含分区。GSI 中的数据将与其基表中的数据分开存储,但索引分区与表分区的行为方式几乎相同。
数据分配:分区键
如果表具有简单主键 (只有分区键),DynamoDB 将根据其分区键值存储和检索各个项目。
DynamoDB 使用分区键的值作为内部散列函数的输入值,从而将项目写入表中。散列函数的输出值决定了项目将要存储在哪个分区。
要从表中读取某个项目,您必须为该项目指定分区键值。DynamoDB 使用此值作为其哈希函数的输入值,从而生成可从中找到该项目的分区。
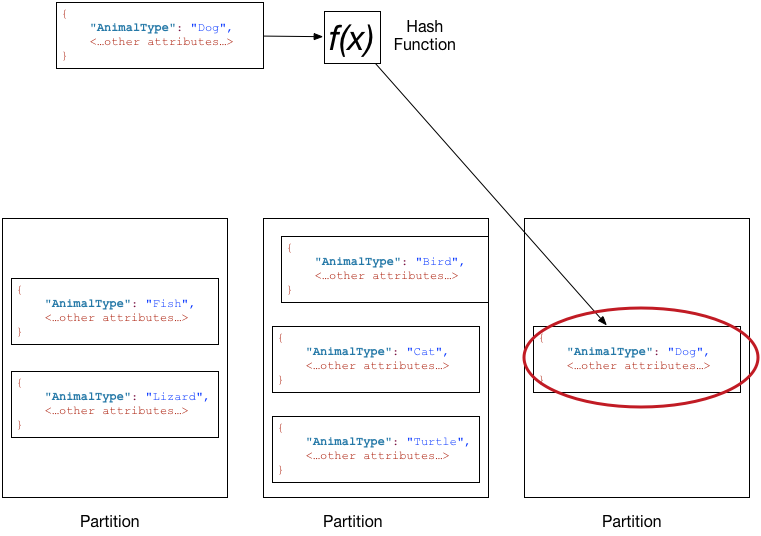
下图显示了名为 Pets 的表,该表跨多个分区。表的主键为 AnimalType(仅显示此键属性)。在这种情况下,DynamoDB 会根据字符串 Dog 的哈希值,使用其哈希函数决定新项目的存储位置。请注意,项目并非按排序顺序存储的。每个项目的位置由其分区键的哈希值决定。
注意
DynamoDB 经过优化,不论表有多少个分区,都可在这些分区上统一分配项目。我们建议您选择具有较多非重复值(相对于表中的项目数)的分区键。
数据分配:分区键和排序键
如果表具有复合主键(分区键和排序键),DynamoDB 将采用与数据分配:分区键中所述的方式相同的方式来计算分区键的哈希值 — 但会按排序键值有序地将具有相同分区键的项目存储在互相紧邻的物理位置。
为将某个项目写入表中,DynamoDB 会计算分区键的散列值以确定该项目的存储分区。在该分区中,可能有几个具有相同分区键值的项目,因此 DynamoDB 会按排序键的升序将该项目存储在其他项目中。
要读取表中的某个项目,您必须为该项目指定分区键值和排序键值。DynamoDB 会计算分区键的哈希值,从而生成可从中找到该项目的分区。
如果您想要的项目具有相同的分区键值,则可以通过单一操作 (Query) 读取表中的多个项目。DynamoDB 将返回具有该分区键值的所有项目。或者,您也可以对排序键应用某个条件,以便它仅返回特定值范围内的项目。
假设 Pets 表具有由 AnimalType(分区键)和 Name(排序键)构成的复合主键。下图显示了 DynamoDB 写入项目的过程,分区键值为 Dog、排序键值为 Fido。
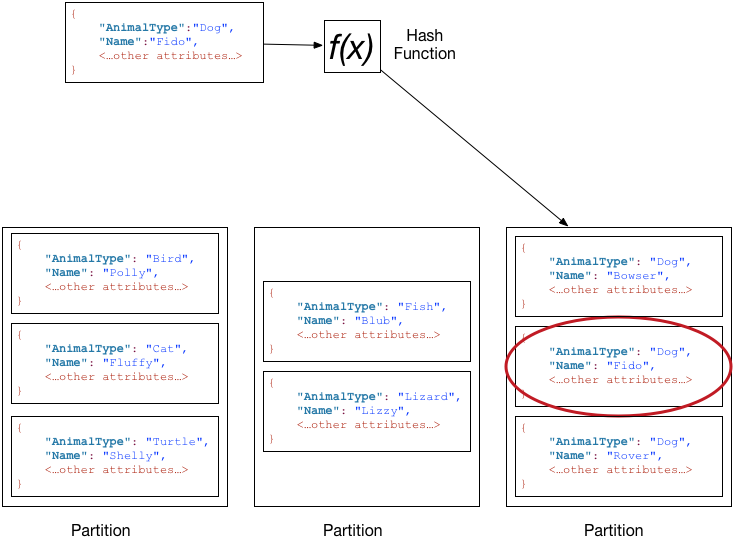
为读取 Pets 表中的同一项目,DynamoDB 会计算 Dog 的哈希值,从而生成这些项目的存储分区。然后,DynamoDB 会扫描这些排序键属性值,直至找到 Fido。
要读取 AnimalType 为 Dog 的所有项目,您可以执行 Query 操作,无需指定排序键条件。默认情况下,这些项目会按存储顺序 (即按排序键的升序) 返回。或者,您也可以请求以降序返回。
要仅查询某些 Dog 项目,您可以对排序键应用条件(例如,仅限 Name 以 A 至 K 范围内的字母开头的 Dog 项目)。
注意
在 DynamoDB 表中,每个分区键值的非重复排序键值无数量上限。如果您需要在 Pets 表中存储数十亿个 Dog 项目,DynamoDB 会自动分配足够的存储来满足这一需求。