创建应用
登录网站
登录www.ai.baidu.com
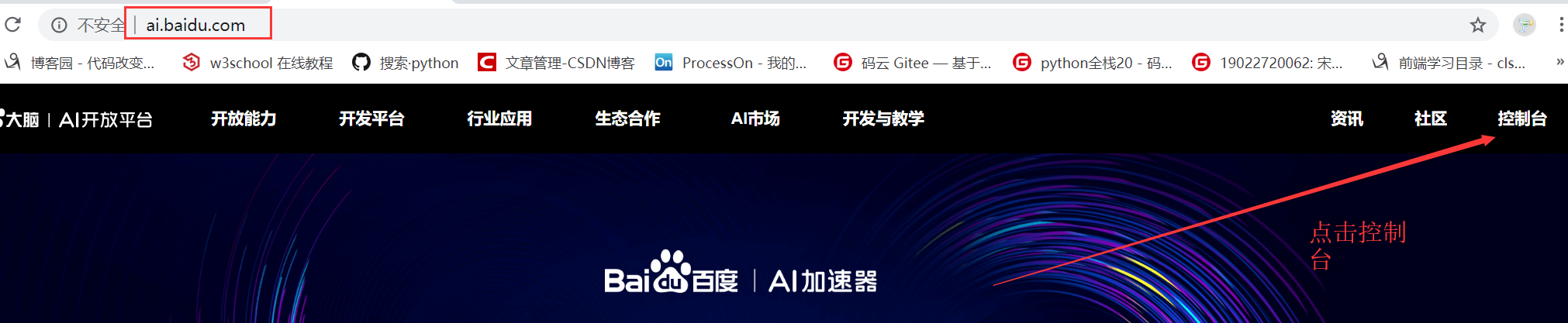
进入控制台

进入语音技术

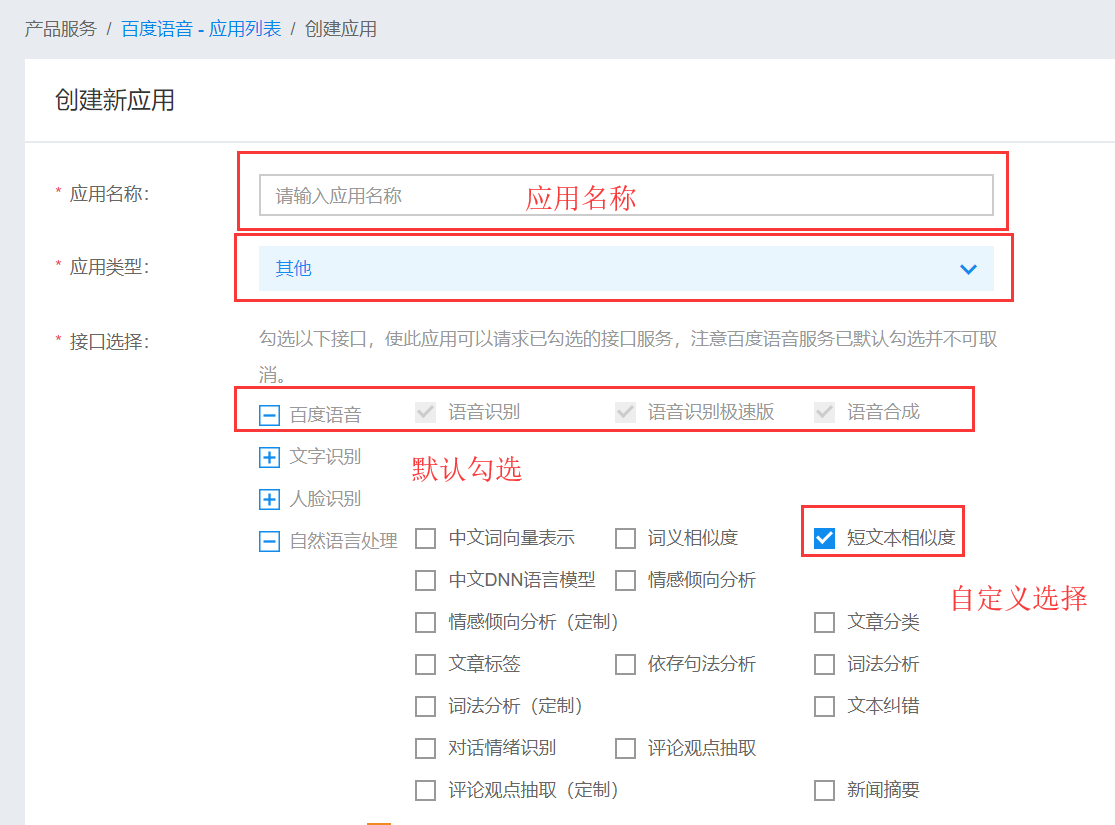
创建应用
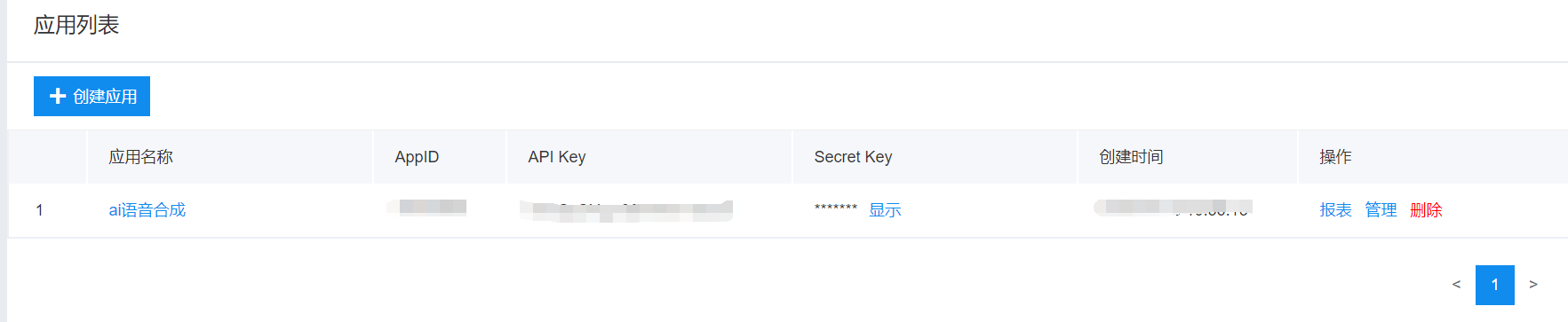
管理应用
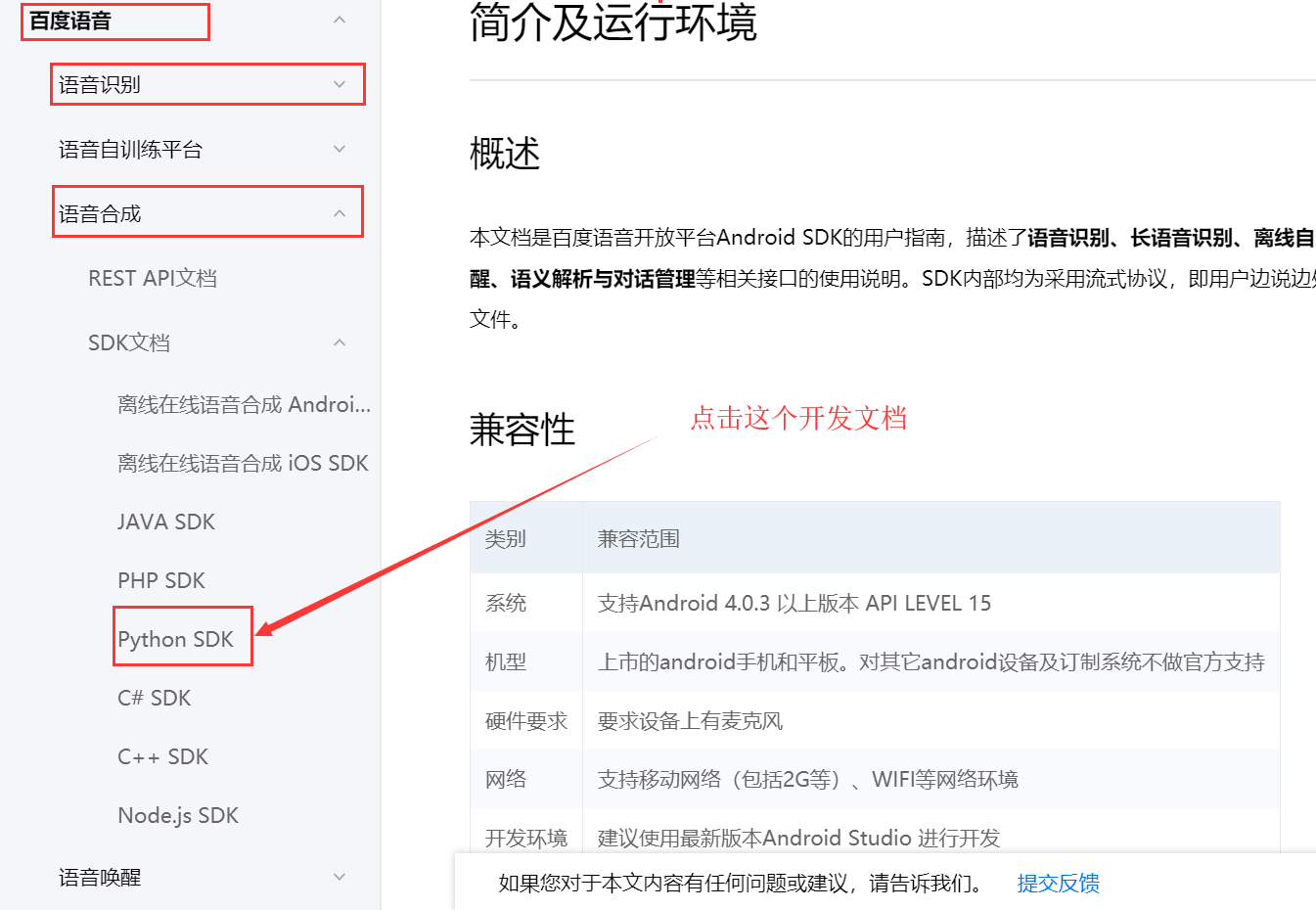
技术文档

SDK开发文档
接口能力

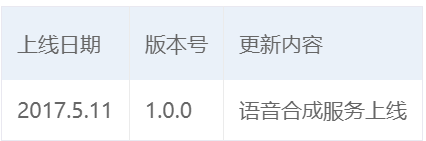
版本更新记录
注意事项
目前本SDK的功能同REST API,需要联网调用http接口 。REST API 仅支持最多512字(1024 字节)的音频合成,合成的文件格式为mp3。没有其他额外功能。 如果需要使用离线合成等其它功能,请使用Android或者iOS 合成 SDK
请严格按照文档里描述的参数进行开发。请注意以下几个问题:
- 合成文本长度必须小于1024字节,如果本文长度较长,可以采用多次请求的方式。切忌文本长度超过限制。
- 新创建语音合成应用不限制每日调用量,但有QPS限额。详细限额数据可在控制台中查看。完成个人实名认证及企业认证可提高QPS限额。若需更大QPS可进一步商务合作咨询。
- 必填字段中,严格按照文档描述中内容填写。
支持Python版本:2.7.+ ,3.+
安装使用Python SDK有如下方式:
- 如果已安装pip,执行
pip install baidu-aip即可。
语音合成
新建AipSpeech
from aip import AipSpeech """ 你的 APPID AK SK """ APP_ID = '你的 App ID' API_KEY = '你的 Api Key' SECRET_KEY = '你的 Secret Key' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) # 就是我们之前创建应用的那些信息
在上面代码中,常量APP_ID在百度云控制台中创建,常量API_KEY与SECRET_KEY是在创建完毕应用后,系统分配给用户的,均为字符串,用于标识用户,为访问做签名验证,可在AI服务控制台中的应用列表中查看。
请求说明
result = client.synthesis('你好百度', 'zh', 1, { 'vol': 5, }) # 识别正确返回语音二进制 错误则返回dict 参照下面错误码 if not isinstance(result, dict): with open('auido.mp3', 'wb') as f: f.write(result)
更多请求参数

返回样例
// 成功返回二进制文件流 // 失败返回 { "err_no":500, "err_msg":"notsupport.", "sn":"abcdefgh", "idx":1 }
错误信息返回
若请求错误,服务器将返回的JSON文本包含以下参数:
- error_code:错误码。
- error_msg:错误描述信息,帮助理解和解决发生的错误。
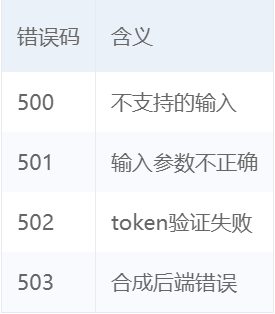
错误码
实战演示
from aip import AipSpeech """ 你的 APPID AK SK """ APP_ID = '16815805' API_KEY = 'G7dSyQYqyr3SrWO71rjivtuh' SECRET_KEY = 'NYfwjHWjRgGk8Rf2wP2bXoW7sW15ucmK' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) result = client.synthesis('先帝创业未半而中道崩殂,今天下三分,益州疲弊,此诚危急存亡之秋也。', 'zh', 1, { 'vol': 5, # 更多参数查看pythonSDK文档 }) # 识别正确返回语音二进制 错误则返回dict 参照下面错误码 if not isinstance(result, dict): with open('出师表.mp3', 'wb') as f: f.write(result) # 在本地生成一个mp3格式的语音文件
语音识别
语音格式转换工具:
链接:https://pan.baidu.com/s/1pfjXvJsANzjGvnn-cmVZMg
提取码:t0mc
# 将m4a格式的音频文件转换为pcm格式 # 配置完ffmpeg需要重启pycharm重新加载环境变量,环境变量不能有中文,pycharm不能识别中文路径
代码演示
import os from aip import AipSpeech """ 你的 APPID AK SK """ APP_ID = '16815805' API_KEY = 'G7dSyQYqyr3SrWO71rjivtuh' SECRET_KEY = 'NYfwjHWjRgGk8Rf2wP2bXoW7sW15ucmK' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) # 读取文件 def get_file_content(filePath): # 将m4a格式的音频文件转换为pcm格式 # 配置完ffmpeg需要重启pycharm重新加载环境变量,环境变量不能有中文,pycharm不能识别中文路径 cmd_str = f"ffmpeg -y -i {filePath} -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {filePath}.pcm" os.system(cmd_str) # 在cmd运行上面的命令 with open(f"{filePath}.pcm", 'rb') as fp: return fp.read() # 识别本地文件 res = client.asr(get_file_content('录音.m4a'), 'pcm', 16000, { 'dev_pid': 1536, }) # 将语音识别成文本 print(res.get("result")[0])
短文本相似度
自然语言处理—短文本相似度
新建AipNlp
from aip import AipNlp """ 你的 APPID AK SK """ APP_ID = '你的 App ID' API_KEY = '你的 Api Key' SECRET_KEY = '你的 Secret Key' client = AipNlp(APP_ID, API_KEY, SECRET_KEY)
短文本相似度接口用来判断两个文本的相似度得分。
text1 = "浙富股份" text2 = "万事通自考网" """ 调用短文本相似度 """ client.simnet(text1, text2); """ 如果有可选参数 """ options = {} options["model"] = "CNN" """ 带参数调用短文本相似度 """ client.simnet(text1, text2, options)
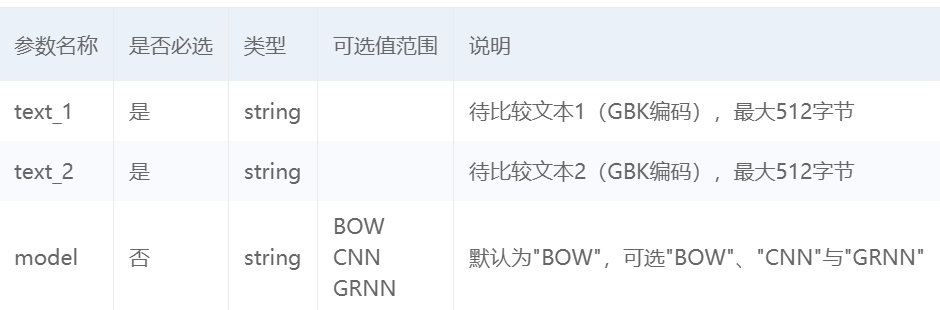
请求参数
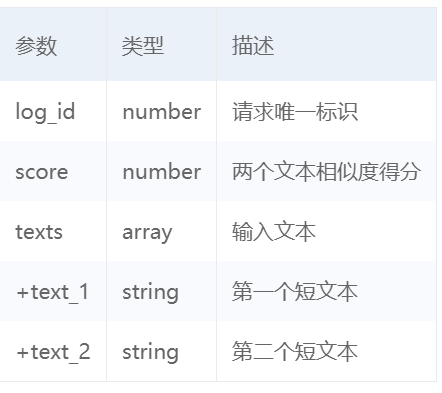
返回数据参数
代码演示
结合语音识别,判断两条数据的相似度
import os from aip import AipSpeech,AipNlp # 短文本相似度 """ 你的 APPID AK SK """ APP_ID = '16815805' API_KEY = 'G7dSyQYqyr3SrWO71rjivtuh' SECRET_KEY = 'NYfwjHWjRgGk8Rf2wP2bXoW7sW15ucmK' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) NLP_client = AipNlp(APP_ID, API_KEY, SECRET_KEY) # 读取文件 def get_file_content(filePath): cmd_str = f"ffmpeg -y -i {filePath} -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {filePath}.pcm" os.system(cmd_str) with open(f"{filePath}.pcm", 'rb') as fp: return fp.read() # 识别本地文件 res = client.asr(get_file_content('录音.m4a'), 'pcm', 16000, { 'dev_pid': 1536, }) # 将语音识别成文本 Q = res.get("result")[0] # 将两个文本进行对比 sim = NLP_client.simnet(Q,"你好").get("score") # {'log_id': 5728331156191316048, 'texts': {'text_2': '你好', 'text_1': '好'}, 'score': 0.614362} print(sim)