1. 简介
分布式有状态的流处理支持在云端部署和执行大规模连续地计算,同时可以应对低延迟和高吞吐量场景。
这一模式最大的挑战之一是在系统可能失败的情况下提供数据可靠性保证。
现有方法依赖于可用于故障恢复的周期性全局状态快照。
此类方法有两个主要缺点:首先,它们通常会阻塞计算;其次,它们通常会保存传输中的所有记录和操作状态,这导致更多的快照数据。
而异步屏障快照(ABS)是一种适用于现代流处理引擎的轻量级算法,可最大限度地减少空间需求。Apache Flink上实现了ABS,评估的结果表明,ABS不会对执行产生重大影响,保持线性可扩展性并且能够在频繁快照的情况下表现良好。
2. 异步屏障快照原理描述
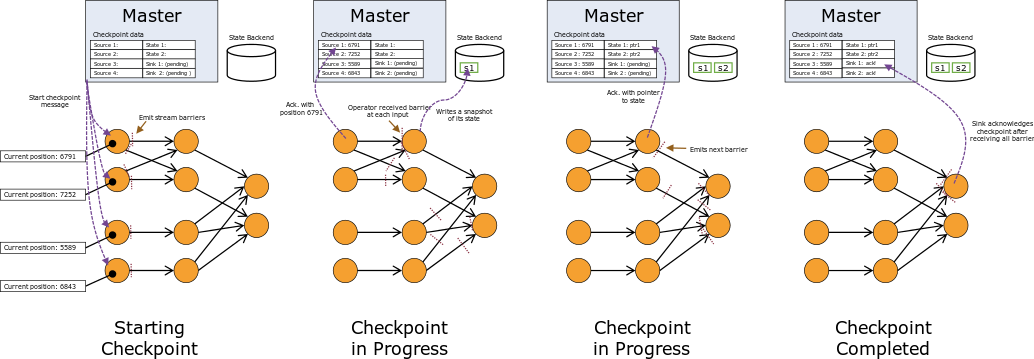
流式数据处理计算图中的节点可分为三类:Source(负责数据输入)、Sink(负责结果输出)和算子,它们之间由数据传输通道连接。
以T表示计算节点的集合,E表示边(数据传输通道)的集合,则计算图可表示为G=(T,E)
一个很自然的想法是对计算图在某些时间点上做快照,这样在故障发生后整个数据处理系统可以恢复到某个快照时间点的状态,以保证exactly once语义。
ABS的步骤如下:
- 引擎定期向Source节点插入检查点屏障(Barrier)。在收到作为控制消息的检查点屏障后,Source节点对自己的状态做快照,并在其输出通道上广播此检查点屏障消息。此外,不同的检查点屏障可以通过id区分。
- 当其从任意一个输入通道收到检查点屏障消息时,算子或Sink节点阻塞此输入通道,直至本节点从所有输入通道收到检查点屏障。
- 在其从所有输入通道收到检查点屏障后,算子或Sink节点对自己的状态做快照,然后对其所有输入通道解除阻塞。
3. 源码分析
JobManager 根据 JobGraph 生成ExecutionGraph。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。
public void enableCheckpointing(
long interval,
long checkpointTimeout,
long minPauseBetweenCheckpoints,
int maxConcurrentCheckpoints,
CheckpointRetentionPolicy retentionPolicy,
List<ExecutionJobVertex> verticesToTrigger,
List<ExecutionJobVertex> verticesToWaitFor,
List<ExecutionJobVertex> verticesToCommitTo,
List<MasterTriggerRestoreHook<?>> masterHooks,
CheckpointIDCounter checkpointIDCounter,
CompletedCheckpointStore checkpointStore,
StateBackend checkpointStateBackend,
CheckpointStatsTracker statsTracker) {
// simple sanity checks
checkArgument(interval >= 10, "checkpoint interval must not be below 10ms");
checkArgument(checkpointTimeout >= 10, "checkpoint timeout must not be below 10ms");
checkState(state == JobStatus.CREATED, "Job must be in CREATED state");
checkState(checkpointCoordinator == null, "checkpointing already enabled");
ExecutionVertex[] tasksToTrigger = collectExecutionVertices(verticesToTrigger);
ExecutionVertex[] tasksToWaitFor = collectExecutionVertices(verticesToWaitFor);
ExecutionVertex[] tasksToCommitTo = collectExecutionVertices(verticesToCommitTo);
checkpointStatsTracker = checkNotNull(statsTracker, "CheckpointStatsTracker");
// create the coordinator that triggers and commits checkpoints and holds the state
// 参数太多,如果用builder模式会好些
checkpointCoordinator = new CheckpointCoordinator(
jobInformation.getJobId(),
interval,
checkpointTimeout,
minPauseBetweenCheckpoints,
maxConcurrentCheckpoints,
retentionPolicy,
tasksToTrigger,
tasksToWaitFor,
tasksToCommitTo,
checkpointIDCounter,
checkpointStore,
checkpointStateBackend,
ioExecutor,
SharedStateRegistry.DEFAULT_FACTORY);
// register the master hooks on the checkpoint coordinator
for (MasterTriggerRestoreHook<?> hook : masterHooks) {
if (!checkpointCoordinator.addMasterHook(hook)) {
LOG.warn("Trying to register multiple checkpoint hooks with the name: {}", hook.getIdentifier());
}
}
checkpointCoordinator.setCheckpointStatsTracker(checkpointStatsTracker);
// interval如果是Long.MAX_VALUE表示禁用周期性checkpoint
if (interval != Long.MAX_VALUE) {
// job status changes (running -> on, all other states -> off)
registerJobStatusListener(checkpointCoordinator.createActivatorDeactivator());
}
}
- enableCheckpointing方法负责初始化CheckpointCoordinator并注册JobStatusListener
- interval等于Long.MAX_VALUE是,表示禁用了周期性checkpoint
public JobStatusListener createActivatorDeactivator() {
synchronized (lock) {
if (shutdown) {
throw new IllegalArgumentException("Checkpoint coordinator is shut down");
}
if (jobStatusListener == null) {
jobStatusListener = new CheckpointCoordinatorDeActivator(this);
}
return jobStatusListener;
}
}
- CheckpointCoordinator类createActivatorDeactivator方法返回jobStatusListener
- lock是个对象锁,粒度是CheckpointCoordinator实例级别
@Override
public void jobStatusChanges(JobID jobId, JobStatus newJobStatus, long timestamp, Throwable error) {
if (newJobStatus == JobStatus.RUNNING) {
// start the checkpoint scheduler
coordinator.startCheckpointScheduler();
} else {
// anything else should stop the trigger for now
coordinator.stopCheckpointScheduler();
}
}
- CheckpointCoordinatorDeActivator类是JobStatusListener的实现
- 当job状态是RUNNING时,启动调度器
- 当job状态为其他时,停止调度器
public void startCheckpointScheduler() {
synchronized (lock) {
if (shutdown) {
throw new IllegalArgumentException("Checkpoint coordinator is shut down");
}
// make sure all prior timers are cancelled
stopCheckpointScheduler();
periodicScheduling = true;
long initialDelay = ThreadLocalRandom.current().nextLong(
minPauseBetweenCheckpointsNanos / 1_000_000L, baseInterval + 1L);
currentPeriodicTrigger = timer.scheduleAtFixedRate(
new ScheduledTrigger(), initialDelay, baseInterval, TimeUnit.MILLISECONDS);
}
}
- CheckpointCoordinator类startCheckpointScheduler方法启动一个定时线程,定期触发checkpoint
- 此处使用ThreadLocalRandom兼顾了线程安全和效率
public void stopCheckpointScheduler() {
synchronized (lock) {
triggerRequestQueued = false;
periodicScheduling = false;
if (currentPeriodicTrigger != null) {
currentPeriodicTrigger.cancel(false);
currentPeriodicTrigger = null;
}
for (PendingCheckpoint p : pendingCheckpoints.values()) {
p.abortError(new Exception("Checkpoint Coordinator is suspending."));
}
pendingCheckpoints.clear();
numUnsuccessfulCheckpointsTriggers.set(0);
}
}
- CheckpointCoordinator类stopCheckpointScheduler方法停止定时线程
- 取消当前pending的checkpoint
private final class ScheduledTrigger implements Runnable {
@Override
public void run() {
try {
triggerCheckpoint(System.currentTimeMillis(), true);
}
catch (Exception e) {
LOG.error("Exception while triggering checkpoint for job {}.", job, e);
}
}
}
- ScheduledTrigger是个内部类,实现了Runnable接口
- 调用triggerCheckpoint触发checkpoint
public CheckpointTriggerResult triggerCheckpoint(
long timestamp,
CheckpointProperties props,
@Nullable String externalSavepointLocation,
boolean isPeriodic) {
// make some eager pre-checks
...
// check if all tasks that we need to trigger are running.
// if not, abort the checkpoint
...
// next, check if all tasks that need to acknowledge the checkpoint are running.
// if not, abort the checkpoint
...
// we will actually trigger this checkpoint!
// we lock with a special lock to make sure that trigger requests do not overtake each other.
// this is not done with the coordinator-wide lock, because the 'checkpointIdCounter'
// may issue blocking operations. Using a different lock than the coordinator-wide lock,
// we avoid blocking the processing of 'acknowledge/decline' messages during that time.
synchronized (triggerLock) {
final CheckpointStorageLocation checkpointStorageLocation;
final long checkpointID;
try {
// this must happen outside the coordinator-wide lock, because it communicates
// with external services (in HA mode) and may block for a while.
checkpointID = checkpointIdCounter.getAndIncrement();
checkpointStorageLocation = props.isSavepoint() ?
checkpointStorage.initializeLocationForSavepoint(checkpointID, externalSavepointLocation) :
checkpointStorage.initializeLocationForCheckpoint(checkpointID);
}
...
final PendingCheckpoint checkpoint = new PendingCheckpoint(
job,
checkpointID,
timestamp,
ackTasks,
props,
checkpointStorageLocation,
executor);
...
// schedule the timer that will clean up the expired checkpoints
final Runnable canceller = () -> {
synchronized (lock) {
// only do the work if the checkpoint is not discarded anyways
// note that checkpoint completion discards the pending checkpoint object
if (!checkpoint.isDiscarded()) {
LOG.info("Checkpoint {} of job {} expired before completing.", checkpointID, job);
checkpoint.abortExpired();
pendingCheckpoints.remove(checkpointID);
rememberRecentCheckpointId(checkpointID);
triggerQueuedRequests();
}
}
};
try {
// re-acquire the coordinator-wide lock
synchronized (lock) {
// since we released the lock in the meantime, we need to re-check
// that the conditions still hold.
...
pendingCheckpoints.put(checkpointID, checkpoint);
ScheduledFuture<?> cancellerHandle = timer.schedule(
canceller,
checkpointTimeout, TimeUnit.MILLISECONDS);
if (!checkpoint.setCancellerHandle(cancellerHandle)) {
// checkpoint is already disposed!
cancellerHandle.cancel(false);
}
// trigger the master hooks for the checkpoint
final List<MasterState> masterStates = MasterHooks.triggerMasterHooks(masterHooks.values(),
checkpointID, timestamp, executor, Time.milliseconds(checkpointTimeout));
for (MasterState s : masterStates) {
checkpoint.addMasterState(s);
}
}
// end of lock scope
final CheckpointOptions checkpointOptions = new CheckpointOptions(
props.getCheckpointType(),
checkpointStorageLocation.getLocationReference());
// send the messages to the tasks that trigger their checkpoint
for (Execution execution: executions) {
execution.triggerCheckpoint(checkpointID, timestamp, checkpointOptions);
}
numUnsuccessfulCheckpointsTriggers.set(0);
return new CheckpointTriggerResult(checkpoint);
}
...
} // end trigger lock
}
- CheckpointCoordinator类triggerCheckpoint方法负责触发一次checkpoint
- triggerLock是对象锁,粒度是CheckpointCoordinator实例级别
- 生成一个新的checkpointID
- 创建一个超时回调,并创建一个定时任务执行此超时回调
- 存在锁顺序死锁的隐患,triggerLock嵌套lock
public void triggerCheckpoint(long checkpointId, long timestamp, CheckpointOptions checkpointOptions) {
final LogicalSlot slot = assignedResource;
if (slot != null) {
final TaskManagerGateway taskManagerGateway = slot.getTaskManagerGateway();
taskManagerGateway.triggerCheckpoint(attemptId, getVertex().getJobId(), checkpointId, timestamp, checkpointOptions);
} else {
LOG.debug("The execution has no slot assigned. This indicates that the execution is " +
"no longer running.");
}
}
- Execution类的triggerCheckpoint方法,发送AKKA消息通知taskManager
/**
* Handler for messages related to checkpoints.
*
* @param actorMessage The checkpoint message.
*/
private def handleCheckpointingMessage(actorMessage: AbstractCheckpointMessage): Unit = {
actorMessage match {
case message: TriggerCheckpoint =>
val taskExecutionId = message.getTaskExecutionId
val checkpointId = message.getCheckpointId
val timestamp = message.getTimestamp
val checkpointOptions = message.getCheckpointOptions
log.debug(s"Receiver TriggerCheckpoint $checkpointId@$timestamp for $taskExecutionId.")
val task = runningTasks.get(taskExecutionId)
if (task != null) {
task.triggerCheckpointBarrier(checkpointId, timestamp, checkpointOptions)
} else {
log.debug(s"TaskManager received a checkpoint request for unknown task $taskExecutionId.")
}
case message: NotifyCheckpointComplete =>
val taskExecutionId = message.getTaskExecutionId
val checkpointId = message.getCheckpointId
val timestamp = message.getTimestamp
log.debug(s"Receiver ConfirmCheckpoint $checkpointId@$timestamp for $taskExecutionId.")
val task = runningTasks.get(taskExecutionId)
if (task != null) {
task.notifyCheckpointComplete(checkpointId)
} else {
log.debug(
s"TaskManager received a checkpoint confirmation for unknown task $taskExecutionId.")
}
// unknown checkpoint message
case _ => unhandled(actorMessage)
}
}
- 此处进入scala代码TaskManager类handleCheckpointingMessage函数
- 收到TriggerCheckpoint消息后触发task的triggerCheckpointBarrier方法
public void triggerCheckpointBarrier(
final long checkpointID,
long checkpointTimestamp,
final CheckpointOptions checkpointOptions) {
final AbstractInvokable invokable = this.invokable;
final CheckpointMetaData checkpointMetaData = new CheckpointMetaData(checkpointID, checkpointTimestamp);
if (executionState == ExecutionState.RUNNING && invokable != null) {
// build a local closure
final String taskName = taskNameWithSubtask;
final SafetyNetCloseableRegistry safetyNetCloseableRegistry =
FileSystemSafetyNet.getSafetyNetCloseableRegistryForThread();
Runnable runnable = new Runnable() {
@Override
public void run() {
// set safety net from the task's context for checkpointing thread
LOG.debug("Creating FileSystem stream leak safety net for {}", Thread.currentThread().getName());
FileSystemSafetyNet.setSafetyNetCloseableRegistryForThread(safetyNetCloseableRegistry);
try {
boolean success = invokable.triggerCheckpoint(checkpointMetaData, checkpointOptions);
...
}
...
}
};
executeAsyncCallRunnable(runnable, String.format("Checkpoint Trigger for %s (%s).", taskNameWithSubtask, executionId));
}
else {
LOG.debug("Declining checkpoint request for non-running task {} ({}).", taskNameWithSubtask, executionId);
// send back a message that we did not do the checkpoint
checkpointResponder.declineCheckpoint(jobId, executionId, checkpointID,
new CheckpointDeclineTaskNotReadyException(taskNameWithSubtask));
}
}
Task类的triggerCheckpointBarrier方法
- 创建了一个Runnable匿名类,并调用executeAsyncCallRunnable方法执行它。
private void executeAsyncCallRunnable(Runnable runnable, String callName) {
// make sure the executor is initialized. lock against concurrent calls to this function
synchronized (this) {
if (executionState != ExecutionState.RUNNING) {
return;
}
// get ourselves a reference on the stack that cannot be concurrently modified
ExecutorService executor = this.asyncCallDispatcher;
if (executor == null) {
// first time use, initialize
checkState(userCodeClassLoader != null, "userCodeClassLoader must not be null");
executor = Executors.newSingleThreadExecutor(
new DispatcherThreadFactory(
TASK_THREADS_GROUP,
"Async calls on " + taskNameWithSubtask,
userCodeClassLoader));
this.asyncCallDispatcher = executor;
// double-check for execution state, and make sure we clean up after ourselves
// if we created the dispatcher while the task was concurrently canceled
if (executionState != ExecutionState.RUNNING) {
executor.shutdown();
asyncCallDispatcher = null;
return;
}
}
...
}
}
Task类的executeAsyncCallRunnable方法
- 创建了一个单线程线程池,执行入参中的Runnable
@Override
public boolean triggerCheckpoint(CheckpointMetaData checkpointMetaData, CheckpointOptions checkpointOptions) throws Exception {
try {
// No alignment if we inject a checkpoint
CheckpointMetrics checkpointMetrics = new CheckpointMetrics()
.setBytesBufferedInAlignment(0L)
.setAlignmentDurationNanos(0L);
return performCheckpoint(checkpointMetaData, checkpointOptions, checkpointMetrics);
}
...
}
StreamTask类triggerCheckpoint方法
- 调用performCheckpoint执行checkpoint操作
private boolean performCheckpoint(
CheckpointMetaData checkpointMetaData,
CheckpointOptions checkpointOptions,
CheckpointMetrics checkpointMetrics) throws Exception {
LOG.debug("Starting checkpoint ({}) {} on task {}",
checkpointMetaData.getCheckpointId(), checkpointOptions.getCheckpointType(), getName());
synchronized (lock) {
if (isRunning) {
// we can do a checkpoint
// All of the following steps happen as an atomic step from the perspective of barriers and
// records/watermarks/timers/callbacks.
// We generally try to emit the checkpoint barrier as soon as possible to not affect downstream
// checkpoint alignments
// Step (1): Prepare the checkpoint, allow operators to do some pre-barrier work.
// The pre-barrier work should be nothing or minimal in the common case.
operatorChain.prepareSnapshotPreBarrier(checkpointMetaData.getCheckpointId());
// Step (2): Send the checkpoint barrier downstream
operatorChain.broadcastCheckpointBarrier(
checkpointMetaData.getCheckpointId(),
checkpointMetaData.getTimestamp(),
checkpointOptions);
// Step (3): Take the state snapshot. This should be largely asynchronous, to not
// impact progress of the streaming topology
checkpointState(checkpointMetaData, checkpointOptions, checkpointMetrics);
return true;
}
...
}
StreamTask类performCheckpoint方法分三步
- 执行checkpoint准备操作
- 广播checkpoint屏障信息
- 打快照
4. 总结
Apache Flink依赖ABS算法很好的兼顾低延迟和高吞吐,并支持exactly once.
5. 参考资料
[https://ci.apache.org/projects/flink/flink-docs-release-1.8/internals/stream_checkpointing.html#barriers]
[https://arxiv.org/abs/1506.08603]
[https://yq.aliyun.com/articles/622185]