本文将要讲解的是Apache Flink分布式流处理的轻量异步的快照原理。网上已经有几篇相关的博文,而本文的不同之处在于,它不是论文的纯粹翻译(论文地址),而是用自己的语言结合自己的理解对其原理的阐述。
本文将同下面几个方面讲解:
- 什么是快照?为什么需要快照?
- 跟其他系统的快照相比,Apache Flink快照的原理有哪些优点?
- Apache Flink的快照原理是什么?
1. 什么是快照?为什么需要快照?
快照,英文名字叫snapshot,是指对系统当前运行状态的存储,以便在系统故障宕机的时候恢复之前某一个时间点的状态信息,从而继续执行。快照是系统实现可用性的必要功能,是分布式系统实现容错性的常规方法。
一般将快照保存在本机硬盘上,或者暂时其他机器的内存或者直接存储在其他机器硬盘上面。对于暂时存储在其他机器的内存上面的情况,应当以批量的方式定时将内存中的快照刷的硬盘中,实现持久化。批量的方式的优点是减少硬盘的访问量,缺点是有很小的丢失快照的可能性。
2. 跟其他系统的快照相比,Apache Flink快照的原理有哪些优点?
这里我们将对比Apache Spark、Apache Hadoop和Apache Flink三个系统的快照功能。
下面是Spark的算子运算图,该图是有向无环的。数据从左边输入(A和C),最终以G为结束点。我们知道Spark采用批处理的方式来处理大数据,批处理区别于流处理。在Spark中,通过上游节点重新计算来恢复在宕机之前的数据。比如,如果B宕机了,那么重新计算A生成输入B的数据。这样做的优点是不需要存储算子的当前的状态信息,节省空间。缺点是增加了计算量以及计算所需要的时间。
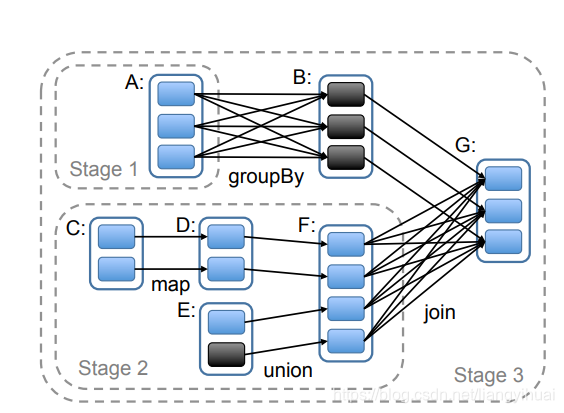
Apache Hadoop,这里具体指HDFS,它采用的是备份数据到不同的(机架)机器硬盘上面来实现。默认为复制三分。优点是干脆利落,能够同时支持HDFS作为存储系统的时候的数据容错备份,也可以作为Mapreduce计算的中间结果的容错备份。缺点是在速度方面有点慢。
Apache Flink采用了上面两种不同的快照功能。其优点是异步的(即使是单机)轻量级的,所需要存储的快照信息也相对较少。
3. Apache Flink的快照原理是什么?
Flink的快照功能针对两种计算网络分别阐述,第一种是有向无环计算网络,第二种是有向有环的计算网络。
下面第一张图是有向无环的计算网络,一个节点的计算结果没有出现返回倒流的情况。图中的表示分别表示为:
圆圈表示流中的数据,黄圈和紫圈表示屏障发送之前的数据,他们分别来自两个不同的数据源,白圈表示屏障发送之后的数据。图中的数据之间的黑色线段表示一个屏障。屏障也没有什么特别的地方,它只是流中有着特殊标志的数据。图中箭头表示一个数据流,红色箭头表示暂时停止接收该流中的数据(停止接收不等于丢弃)。
现在系统要生成一个快照,
- 首先在所有的数据源注入屏障数据,然后向所有的输出节点广播屏障数据
- 如果一个非数据源的节点收到屏障,就阻塞该屏障所在的输入流,也就是暂时不接受这一个输入流的数据,直到接收到其他输入流的所有屏障。所以,如果该节点只有一个输入流,不用阻塞等待。
- 当这个节点接收到了跟其连接的输入流的所有屏障,便开始生成一个当前节点的一个快照。
分析:
- 可中断性分析:因为它是有向无环图,所以只要节点没有宕掉,屏障肯定能够被每一个节点接收到,然后生成一个快照。
- 可行性分析:整个数据的处理过程满足先进先出的原则,所以,在屏障前面的数据和状态都为历史状态,不存在后到的数据先于屏障被处理。也就是上图中白圈的数据总是后于屏障被处理。
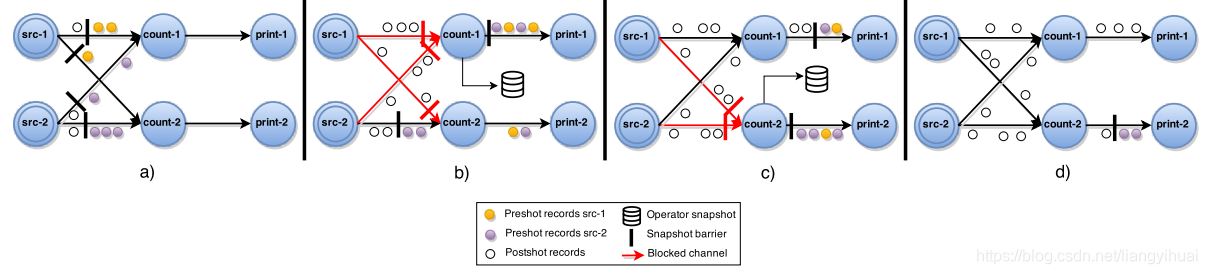
下面这张图表示有向有环图,相比于上面的图片,多了环。
如果要生成一个快照,同样地,
1 首先向每一个数据源发送屏障,
2 如果节点有多条输入流,在接收到某一条流的屏障之后需要暂时停止对该流的接收,直到接收到该节点所有输入流中的屏障。
3 对于某一个有倒向输入流的节点,记录下每一个倒向流动的数据,直到收到一个倒向的屏障(比如下图图c)。收到倒向的屏障之后,生成当前快照。
当前快照的内容包括当前节点的运行状态信息(这个跟有向无环图一样),还包含所有所记录的倒向的数据。在下图中,倒向的数据是被长方形圈住的三个红点。

这种情况下的可中断性和可行性跟上面差不多。对于倒向流的可中断性也容易理解,因为一个有倒向流的节点总能收到一个倒向的屏障数据。
整个快照生成的过程基本上都是异步的,除了在本节点的其他输入流的屏障到来之前需要同步等待。
对于快照的存储,对于有向无环图,只需要保存每一个计算节点的状态信息,对于有向有环图,需要保存节点的状态信息以及倒向的数据信息。两者都不需要保存其他流管道中的数据。所谓的状态信息,举一个例子,一个节点运行count统计计算,那么它的状态信息就是一个int或者long类型的变量。
对于快照的恢复,需要考虑一些问题,比如重复的数据应避免重复计算。这个本文不重点讲解,可以参考论文 Pietzuch. Making state explicit for imperative big data processing.
谢谢