为什么需要搜索引擎
数据库适合结构化数据的精确查询,而不适合半结构化,非结构化数据的模糊查询及灵活搜索(特别是数据量大时),无法提供想要的实时性。
结构化数据:用表、字段表示的数据
半结构化数据:XML HTML
非结构化数据:文本、文档、图片、音频、视频等
什么是反向索引(倒排索引)
要了解搜索引擎的原理就需要先了解什么是反向索引(或者叫倒排索引)。反向索引是区别于正向索引的。
问题:比如我们在查询“苍老师”时,想要得到标题或者内容中包含“苍老师”的新闻列表,我们如何快速查询呢?
解答:我们需要一个索引,这个索引能够根据关键字查找出对应的文章ID。结构类似如下

而这,就是反向索引,这也是搜索引擎的核心思想。那么搜索引擎是如何知道每一篇文章里面含有哪些关键字的呢?
分词器解析
搜索引擎是如何知道每一篇文章里面含有哪些关键字呢?
对于英文来说很简单,因为英文文章的特点是词与词之间有空格。比如这句英文
Zhang SAN said is right //张三说得对
我们很容易就可以拆成以下词汇
- Zhang
- SAN
- said
- is
- right
而对于中文
张三说的确实在理
虽然我们人知道怎么拆,但是对于计算机来说,他是不知道如何取拆的,这个时候就需要引出一个组件,叫中文分词器
其实中文分词器就是一个词库他里面记录的内容可能如下
看起来这个分词器会很大,其实不尽然,中文所有的词语常用的也就那么几十万个,对应系统来说这是个很快的速度
而电脑在匹配的时候会拿第一个字去匹配,这里为张,那么会得到如下结果
这个时候再拿第二个字去匹配,这里为三,那么会得到如下结果
再拿第三个字去匹配,这里为说,而词库中并没有张三说这个词,所以系统会把张三拆成一个词语。系统会记录张三这个词语在这篇文章中出现的次数(这里为一次)和出现的位置以及这篇文章的ID。结构类似
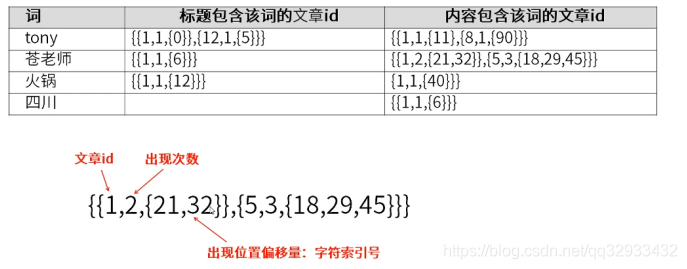
这里的次数可以用来做排名,ID这是用来快速找到这篇文章,那么出现的位置用来干嘛呢?这其实是用来高亮显示的,类似百度这种功能。
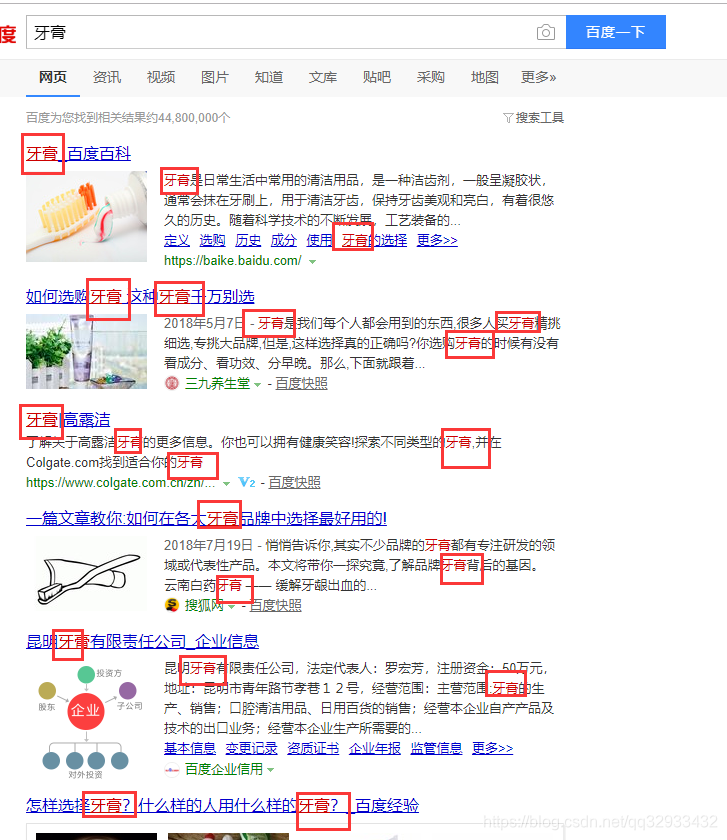
现在,我们知道了系统如何把一片文章拆成多个词汇。那么比如我们上面搜索牙膏,会在全网找到多篇包含牙膏的文章或者网页,搜索引擎是如何给这些文章排序的呢?
权重计算模型
可以看的出来,对于百度这种,网页的排序会是一个非常巨大的利益链。就比如牙膏厂可能会在百度做广告,在你搜索牙膏的时候出现这家厂商。而本文对于这种广告部分不予讨论,而只讨论不考虑广告搜索引擎是如何排序的。
权重:排序就会涉及到一个专业词汇,就是权重,也就是说这个词在这篇文章里面出现的重要程度,一般来说权重越高,应该排名越靠前。那么权重怎么计算呢?
规则1:文章包含某个词越多则说明这篇文章与这个词的相关性越高,标题中出现的词要比内容中出现的词相关性高。
理论上来说确实是这样,但这里有个BUG。比如在某个一共有一千词的网页中“原子能”、“的”和“应用”分别出现了 2 次、35 次 和 5 次,那么它们的词频就分别是 0.002、0.035 和 0.005。那么能说明这篇文章和“应用”、“的”的相关性要比“原子能”的相关性高吗?其实未必,词“的”占了总词频的 80% 以上,而它对确定网页的主题几乎没有用。我们称这种词叫“应删除词”(Stopwords),也就是说在度量相关性是不应考虑它们的频率。在汉语中,应删除词还有“是”、“和”、“中”、“地”、“得”等等几十个。忽略这些应删除词后,“原子能”频率为0.002,“应用”频率为0.005。细心的读者可能还会发现另一个小的漏洞。在汉语中,“应用”是个很通用的词,而“原子能”是个很专业的词,后者在相关性排名中比前者重要。因此我们需要给汉语中的每一个词给一个权重,那么这个词的权重如何判断呢:
我们很容易发现,如果一个关键词只在很少的网页中出现,我们通过它就容易锁定搜索目标,它的权重也就应该大。反之如果一个词在大量网页中出现,我们看到它仍然不是很清楚要找什么内容,因此它应该小。概括地讲,假定一个关键词 w 在 Dw 个网页中出现过,那么 Dw 越大,w的权重越小,反之亦然。
那么其实上诉我们会发现一个矛盾点,我们发现一个词在文章中出现的多也不能代表该文章就与这个词强相关,还要看这个词在别的文章中出现的频率,那么到底怎么计算一篇文章与某个词的关联性呢?我们可以不可以把这个词出现的次数除以这个词在别的文章中出现的次数呢?事实上也正是与这个类似,只是他们的公示不是这样算的。
TF-IDF算法
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
概括地讲,假定一个关键词 w 在 Dw 个网页中出现过,那么 Dw 越大,w的权重越小,反之亦然。在信息检索中,使用最多的权重是“逆文本频率指数” (Inverse document frequency 缩写为IDF),它的公式为log(D/Dw)其中D是全部网页数。比如,我们假定中文网页数是D=10亿,应删除词“的”在所有的网页中都出现,即Dw=10亿,那么它的IDF=log(10亿/10亿)= log (1) = 0。假如专用词“原子能”在两百万个网页中出现,即Dw=200万,则它的权重IDF=log(500) =2.7。又假定通用词“应用”,出现在五亿个网页中,它的权重IDF = log(2)则只有 0.3。也就是说,在网页中找到一个“原子能”的匹配相当于找到九个“应用”的匹配。
所以很容易看出其实上诉文章与“原子能”的相关性更高
java开源搜索引擎
看完上诉原理,还是感觉要实习一个搜索引擎其实挺复杂的,那么有没有什么开源的框架呢?
