简述
向量空间搜索引擎使用了一个非常简单的计数对于矩阵代数去比较基于词频的文档。
向量空间搜索引擎的第一个主要组成部分是概念术语空间。简单地说,术语空间由每个唯一的单词组成出现在文档集合中。
向量空间搜索引擎的第二个主要组成部分是项目计数。项目计数只是记录每个项在an中出现的次数个人文档。这通常表示为一个表,如下图阐述。
通过使用term空间作为坐标空间,和项目计数作为坐标在那个空间中,我们能够给每个文档建立一个向量,让我们看一个简单的例子。
通过使用项目空间作为坐标空间,然后将项目计数值作为空间中的坐标,我门能够对每个文档创建一个向量。为了让我们理解我们是如何产生这么一些向量的,让我们先看一个简单的例子。
你们可能熟悉笛卡尔坐标,绘制通过x,y,z坐标轴。相似的,在项目空间中包含着三种独特的项目我们把他们称为term1,term2 和term3(在向量搜索空间中我们通常把term1,term2,term3这样的轴在理论上我们称为维度),通过计数文件中每个项目的数量,然后绘制出他们的坐标在维度中,我们能够确定一个点对应的文件在一个项目空间中。使用这一点,我们可以为文档创建一个返回原点的向量。
一旦,我们绘制了一个文档的向量通过项目空间,我们能够计算出向量的大小。考虑到线的产百度在文档中点与点之间在项目空间,还有原点。这些向量大小将允许我们通过计算它们之间夹角的协号来比较文档。举个例子,同一文档相同的文档的协号为1,文档包含相似的项目会有一个相似的十进制协号,然后毫无关系的他们的协号为0。
一个简单的例子:
在本教程中,我们将使用a遍历整个索引和搜索过程简单的三维例子,例子很容易想象。
一开始,让我门假设我们有一集合的三个文档。每个文档包含着cat、dog和mouse的组合。单词cat、dog、mouse是项目空间。因此我们说每个文档有一个坐标,根据cat、dog、mouse维度。
这些坐标是通过文档中出现了多少次来定的。举个例子,下面文件1有一个cat-dog-mouse向量(3,1,4)

我们计算向量的大小对于每一个文档使用了勾股定理。但这时候我们有了大于2的维度,所以公式会是这样。
注意,勾股定理公式将继续适用,无论我们处理多少维数。例如,如果我们有一个有1000个独特单词的术语空间,因此有1000个维度,那么公式将继续是a2+b2+c2+d2 +e2……等等。,直到我们得到答案。
同时,我们发现不同的文件也可能向量大小相同。正如我们看到的,文档的相关度基于询问项目的维度找到的。因此同一大小的向量会返回不同的结果。换句话说,这并不一定意味着它们在空间项内指向相同的角度。
查询:
去查询文档集的索引,我们映射一个我们的查询到向量空间中,然后计算出他们的协方差。用英文来说,就是我们将我们要查询的结果映射到向量空间,然后看看哪个文档的向量接近它。
举个例子,如果我们要查询mouse,我们的查询向量会是:
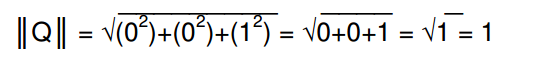
一个编程时的简单优化就是查看查询项目是否在向量空间中,那么大小会总是1,但这只会在单一项目时会有用。对于多个搜索项目,同理也可以找出他们的大小。但这个假设在每个查询中只出现1次在每个查询中,这并不一定是一个很好的假设,因为单词词干法,我将很快讨论。
计算协在查询和文档向量。我们对Q和V的向量积/q的长度*V的长度。
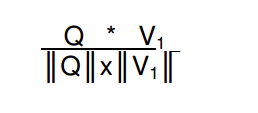

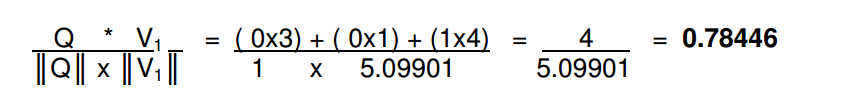
如果什么都不查询,那么查询的结果和其他内容的结果都是0。
如果我们对另外两个文档进行计算,我们将得到以下协号:
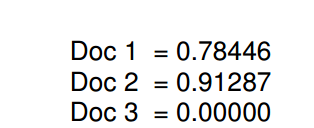
通过降序排列:
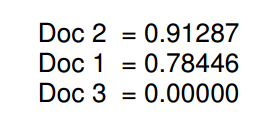
我们能够看到文档2跟拆线呢结果mouse的相似性最大,文档1 有点关系,文档3是完全不相关,因为它不包含任何的mouse。
协的值越接近1,那么说明他们越相关。
收集索引过程
为一个集合建立索引的过程是特定于被建立索引的文档类型的。向量空间搜索技术能够呗用到任何类型的信息,可以呗表示成一种结构化的方式,所以,他在文本上,图片上、密码关键字或者dna。然而,自定义的解析器必须呗构造去操作一种规划的格式,并且通常可以进行优化,使索引过程更有效。
作为一个例子,让我们假设我们想要去索引一个小网站。
首先每个html网站必须进行预处理,然后索引当作一个集合的部分。(集合只能够当作一个整体去索引,将索引后的附加文件添加到集合中会更改术语空间的维数,并否定存储的文档向量的大小。
我们一开始剥掉html的内容,因为内容没有语义文件。我们也同时能够去删除像一些格式、换行、回车,让它只是单纯的文本块。
然后我们删掉停用词,stop words就是英文中经常出现的没有语义的单词,就举个例子:就像单词the,of,or这样跟实际语义没有关系,但是如果把它们放在里面,就会人为地扩大术语空间,从而延长处理时间。就像ly之类的副词,也可以删掉,因为跟语义无关。
接下来,我们对文档中剩余的术语进行词干处理。词干处理,包括删除一些英文单词,到简单的根形态,就像running,runns,runner删除run。波特阻止算法就是用于这样的目的的。PorterThis在保持语义内容的同时,进一步减少了术语空间。
在我们进行了这3步之后,我们剩下了一些需要用来保持原文件语义的术语。
现在我们可以通过构建术语空间和计算每个文档的向量大小来为集合建立索引。

注意:要记住解析器怎么去分解信息会影响我们搜索结果。举个例子,如果你在索引一本书的内容,索引时间和搜索结果会很大程度上的依赖于你是否打破文本通过一个章节、页面或者段落。
你能够需要去实验去找到最佳划分通过特别的数据。
向量空间搜索引擎局限性
尽管向量搜索空间技术是如此的cool,它确实也有局限性。
首先,它计算非常密集,因此也很慢。因为所有的机器浮点数运算,都需要大量的处理器时间。这大大降低了性能,高性能要求大型系统的代码经过优化,只在RAM中运行计算。有希望的,
希望随着处理器速度的不断提高,这将不再是一个障碍。
第二个,动态收集会要求重新索引每一次当一个新的文档被加入。这是因为每个时间你引入一个新项目到你就给矩阵增加一个维度,因此所有存在的文档必须重新索引,因此向量是相关的新维度,这是也许大量的重要的障碍在广泛利用科技中,因为它让试试搜索结果的实时性不可能。
第三个,这要求额外的数学变化到集合矩阵中去探查另外的链接到文档中在一个语义层次。这超越这个文档的范围,这是一个下一个阶段的障碍对于实时性障碍。