本文主要参考《Unix网络编程:卷1》第六章主要内容,以及结合多篇优秀博文写就。
参考博文:
https://segmentfault.com/a/1190000003063859#articleHeader17
https://zhuanlan.zhihu.com/p/63179839
https://www.cnblogs.com/fysola/p/6146063.html
分类
- 阻塞式IO
- 非阻塞式IO
- I/O复用
- 信号驱动式IO
- 异步IO
前四种为同步IO,最后一种为异步IO
IO模式
大多数文件系统的默认 I/O 操作都是缓存 I/O。在 Linux 的缓存 I/O 机制中,操作系统会将 I/O 的数据缓存在文件系统的页缓存( page cache )中,也就是说,数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。
所以说,对一个IO操作来说,它会经历两个阶段:
- 等待数据:数据可能来自其他应用程序或者网络,如果没有数据,操作系统就一直等待,应用程序就跟着等待。(Waiting for the data to be ready)
- 拷贝数据:将就绪的数据拷贝到应用程序工作区。(Copying the data from the kernel to the process)
在Unix系统中,操作系统的IO操作是一个系统调用recvfrom(),即一个系统调用recvfrom包含两步,等待数据就绪和拷贝数据。对于一个套接字上的输入操作,第一步通常涉及等待数据从网络中到达。当所等待分组到达时,它被复制到内核中的某个缓冲区。第二步是把数据从内核缓冲区复制到应用进程缓冲区。
阻塞式IO模型
如下图所示为典型的阻塞式I/O模型,当用户进程调用了recvfrom这个系统调用,kernel就开始了IO的第一个阶段:准备数据(对于网络IO来说,很多时候数据在一开始还没有到达。比如,还没有收到一个完整的UDP包。这个时候kernel就要等待足够的数据到来)。这个过程需要等待,也就是说数据被拷贝到操作系统内核的缓冲区中是需要一个过程的。而在用户进程这边,整个进程会被阻塞(当然,是进程自己选择的阻塞)。当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除block的状态,重新运行起来。
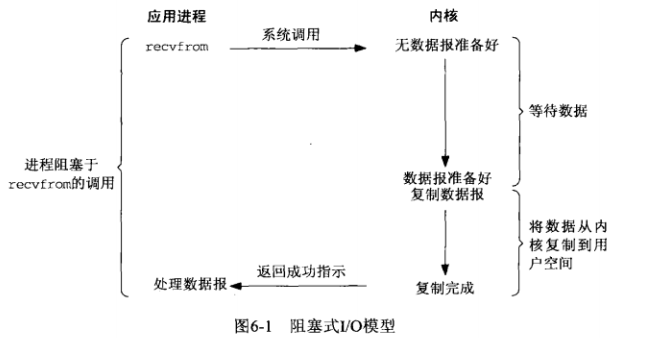
所以,blocking IO的特点就是在IO执行的两个阶段都被block了。
下面为一段典型的阻塞式调用的服务端代码:其中recv是个阻塞方法,当程序运行到recv时,它会一直等待,直到接收到数据才往下执行。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import socket
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.bind(('localhost', 6999)) # 绑定要监听的端口
server.listen(5)
while True:
conn, addr = server.accept() # 等待链接
print(conn, addr)
while True:
try:
data = conn.recv(1024) # 接收数据
print('recive:', data) # 打印接收到的数据
conn.send(data.upper()) # 然后再发送数据
except Exception as e:
print('关闭了正在占线的链接!')
break
conn.close()非阻塞式IO
linux下,可以通过设置socket使其变为non-blocking。当对一个non-blocking socket执行读操作时,流程如下图所所示。一个应用进程像这样对一个非阻塞socket循环调用recvform时,我们称之为轮询(polling),应用进程持续轮询内核,以查看某个操作是否就绪。这样做往往耗费大量cpu时间。
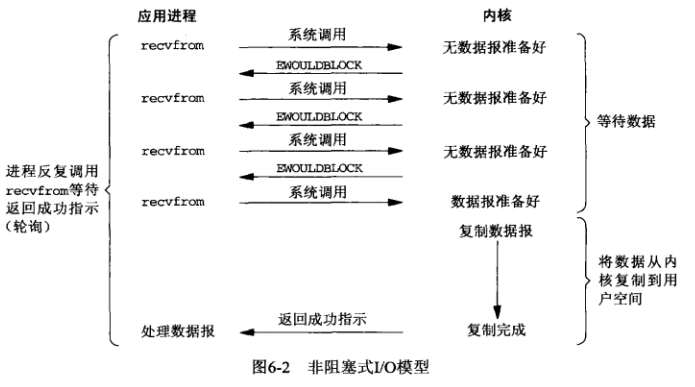
当应用程序发起了IO请求之后,系统调用recvfrom()被执行,并且立即返回,但是返回的并不是IO处理完成的结果,而是一个特定的错误,表示IO数据没有准备好,因此不需要进行IO操作。应用程序会不停地(即轮询)执行recvfrom()系统调用,直到数据已经就绪,然后操作系统完成IO操作,recvfrom()返回成功。这个过程中,没有数据就绪时系统调用recvfrom()是立即返回的,即应用程序并没有阻塞在底层操作系统的等待数据上面,而是轮询结果。
可见阻塞IO与非阻塞IO的关键区别在于,系统调用recvfrom是否立即返回。由于轮询会消耗大量CPU时间,因此这种模式并不常用。
下面为一段非阻塞式调用的Server端代码:
except Exception:
pass
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import socket
sk = socket.socket()
sk.bind(('127.0.0.1',8080))
sk.setblocking(False) # 把 socket 中所有需要阻塞的方法都改变成非阻塞
sk.listen(10)
conn_list = [] # 用来存储所有来请求 server端的 conn连接
while True:
try:
conn, addr = sk.accept() # 不阻塞,但是没有人连接会报错
print('conn:', addr, conn)
conn_list.append(conn)
except Exception:
pass
tmp_list = [conn for conn in conn_list]
for conn in tmp_list:
try:
data = conn.recv(1024) # 接收数据1024字节
if data:
print('收到的数据是{}'.format(data.decode()))
conn.send(data)
else:
print('close conn', conn)
conn.close()
conn_list.remove(conn)
print('remain conn:', len(conn_list))
except Exception:
pass
Client端代码:
import socket
client = socket.socket()
client.connect(('127.0.0.1', 9999))
while True:
msg = input(">>>")
if msg != 'q':
client.send(msg.encode())
data = client.recv(1024)
print('收到的数据{}'.format(data.decode()))
else:
client.close()
print('close client socket')
break非阻塞IO模型优点:实现了同时服务多个客户端,能够在等待任务完成的时间里干其他活了。
非阻塞IO模型缺点:不停地轮询recv,占用较多的CPU资源。对应BlockingIOError的异常处理也是无效的CPU花费。(注:进程阻塞不占用cpu资源)
I/O复用
IO multiplexing就是我们说的select,poll,epoll,有些地方也称这种IO方式为event driven IO。I/O复用,可以通过调用select或poll,阻塞在真正的I/O系统调用之上,而不是真正的I/O系统调用上。
select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。它的基本原理就是select,poll,epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。如下图所示:
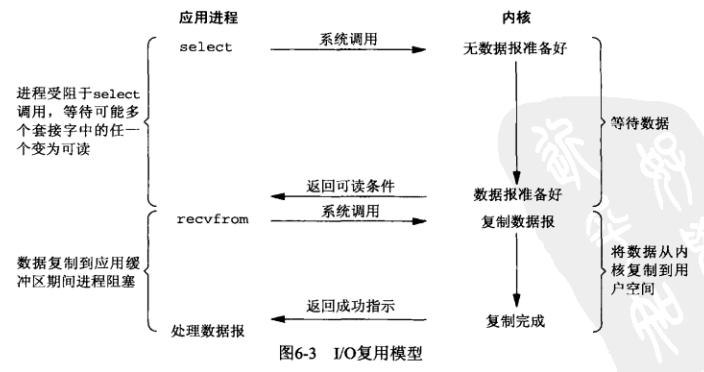
如上图所示, 应用进程阻塞于select调用,等待数据报套接字变为可读。当select返回套接字可读这一条件时,我们调用recvfrom把所读数据报复制到应用进程缓冲区。
比较I/O复用和阻塞式IO并不显得有什么优势,事实上,由于使用select需要两个系统调用,I/O还稍显劣势。不过使用select的优势在于我们可以等待多个描述符就绪。后面我们再具体说下I/O多路复用的优势。
信号驱动I/O
对于信号驱动IO, 我们首先开启套接字的信号驱动式I/O功能。并通过sigaction系统调用安装一个信号处理函数。该系统调用立即返回,我们的进程继续工作。(也即应用进程并没有被阻塞)。当数据报准备好读取时,内核就为该进程产生一个sigio信号。随后我们可以在信号处理函数中调用recvfrom读取数据报。
如下图所示:
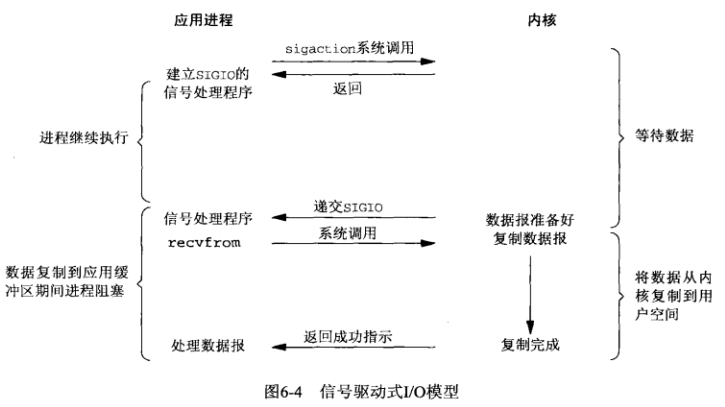
信号驱动也是一种非阻塞式的IO模型,比起上面的非阻塞式IO模型,信号驱动式IO模型不需要轮询检查底层IO数据是否就绪,而是被动接收信号,然后再调用recvfrom执行IO操作。
比起多路复用IO模型来说,信号驱动IO模型针对的是一个IO的完成过程, 而多路复用IO模型针对的是多个IO同时进行时候的场景。
异步IO
异步IO(asynchronous IO)由POSIX规范定义。POSIX异步I/O函数以aio_或lio_开头。这些函数的工作机制是:告知内核启动某个操作,并让内核在整个操作(包括将数据从内核复制到我们自己的缓冲区)完成后通知我们。这种模型与前面介绍的信号驱动模型的主要区别在于:信号驱动式IO是由内核通知我们何时启动一个IO操作,而异步IO模型是由内核通知我们IO操作何时完成。如下图所示:
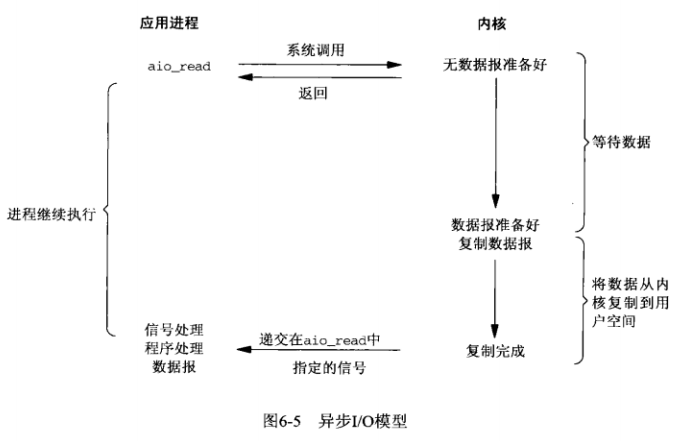
如上图所示,用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
总结
同步IO与异步IO的对比
POSIX把这两个术语定义如下:
同步IO:导致请求进程阻塞,知道IO操作完成。
异步IO:不导致进程阻塞。
如下图所示,前面4种模型都属于同步IO,因为其中正在的IO操作(recvfrom)将阻塞进程。
只有异步IO模型与POSIX定义的异步IO相匹配。
