基于 PyTorch 的图像分类器的设计与实现
一、Cifar数据集的定义
Ciafar是一类用于普世物体识别用的数据集,与Mnist数据不同,Mnist数据只有0-9(10种)的手写体,但大体上都是数字而且均为黑白。Cifar里面有60000张彩色图片,由的十种数据为('plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck')这几种属于完全不同的种类构成,每张图片为32*32的图片,6万张图片又分为五万张训练集以及一万张测试集。
二、分类问题的定义及对求解问题建模
我们在对Cifar数据进行分类时,一共使用了三种分类方法,线性分类,全连接分类,以及卷积网络分类。由于Cifar数据集是彩色图片,因此在使用时考虑到3通道,我们将每张图片变换为3*32*32的tensor,在经过不同的神经网络层的映射之后,最后都会把它映射为一个维度为10的Tensor,对这个数据使用softmax函数映射为不同的类别,一般我们在使用交叉熵损失函数的时候,就已经内置了softmax,来进行最终的分类判别,不同的类别对应的class值,我们在对不同的模型训练之后,对一万的测试集进行测试。由于Cifar数据集涉及的种类较多,并且属于三通道图像,因此在刚开始训练时正确率都较低,需要不断的优化网络结构体,调整超参数来进一步提高正确率,目前来看线性回归分类器<全连接分类器<卷积神经网络分类器
三、三种分类器的设计细节
3.1线性回归分类器40%
线性回归分类器只是用一层神经网络的模型,在本次实验中,我们加载的Cifar数据为三通道,分辨率为32*32大小的图片,因此,对于只有一层网络的线性回归器,我们只需要考虑,超参数中,batch_size的选择为100,学习率设置为0.001。
关于batch_size,它决定了分批处理数据时,每批数据包含多少图片,batch_size如果太小,会导致经过多次循环仍然不收敛的情况,随着batch_size的增大,处理数据的速度也会变快,但是当batch_size过大时,达到相同的精度就会需要越来越多的epoch,因此要选择合适的Batch_size,根据吴恩达的课程推荐2的幂次,因此实验128和64两种。比较收敛速度和精度。
学习率决定了训练后,梯度每次修改的大小,虽然学习率越小收敛的越精确,但是收敛速度很慢。一般都设置为0.001。
输入的size为3*32*32=3072,而输出的size为10,其中不包含其他隐藏层,关于损失函数,我们使用交叉熵损失,在交叉熵损失中就已经自动包含了softmax函数,该函数多用于多分类问题的激活函数,优化器使用SDG梯度下降优化,经过以上步骤,线性回归分类器模型初始化就做好了。接下来就要训练加载的数据了。
数据通过自带的函数会对数据进行下载,通过data_lodaer对数据进行加载,这里的训练数据要进行打乱。在训练的过程中,我们使用epoch=50(ps毕竟只有一层Linear,50次有点多,其实早早收敛了,但是在运行全连接的分类器时发现前十层只有20%的正确率让我有点怀疑人生,因此能多训练就多训练)。
最后的结果还是大概收敛在40%的正确率附近,已经不错了。由下图可知,在第23次训练时结果最好loss=1.5548(batch_size=128)

图一 线性batch_size=128

图二 线性batch_size=64
当batch_size=64时在第43次epoch中,将loss降低到1.37,经过60次的训练,平均精度也从40%升到41%,但是耗费的时间也就增大,因此可以验证之前结论,随着batch_size增大,训练时间减少,但是收敛到精确度最高所消耗时间变长。
3.2全连接人工神经网络分类器56%
全连接神经网络,要考虑到输入层,隐藏层和输出层,输入固定为3*32*32=3072,输出固定为10,对于其中的隐藏层可以是任意大小,以及数量的,只要保证由输入层接受的数据和输出层输出的数据维度相同即可。在这次试验里,我采用的是
3072->2048->1024->512->128->10
这样的映射方式,也就是说隐藏层为四层,隐藏层越多,计算量就会按照指数级增长,同样运算精度也就越高,但是也要考虑过拟合的风险。其中,每经过一次线性层的映射,都要相应的经过激活函数Relu()来将上一层的数据通过线性整流激活函数神经元输出:
![]()
同样batch_size有两种选择,128与64两个。学习率为0.001。在本次模型中,采用的是最后一层采用log_softmax充当激活函数。通过NLLLoss计算损失值。
Log_Softmax是在softmax基础上增加log运算:

与之相对应的损失函数NLLLoss函数,输入为对数概率向量和目标标签,但是并不会为我们计算概率。

通过以上做法就相当于nn.CrossEntropyLoss(),实际上,这样跟在线性回归中单独使用交叉熵损失是一样的。
由于全连接相比线性回归分类器,增加了多个隐藏层的映射,因此计算量相比线性回归分类也是增加了许多,由于电脑显卡不支持CUDA因此都是统一CPU计算进行对比时间,在实验过程中,设置epoch为50,全连接分类器的计算时间较慢,效率较低,但是精度的提升还是很大的(相比于线性分类器),提高了大概10%左右,但是在时间方面花费过大,不是很适合于这种分类。
在之前的Minist数据集中,通过全连接可以做到94%的正确率,因此在一开始对Cifar数据进行训练时,只有10%的正确率。随着训练次数增加,正确率也会不断提升,就是提升速度较慢,每次训练后会提升1%到2%左右,直到50%附近开始收敛,我觉得全连接网络相当于是对线性回归分类的一种优化,通过多重的隐藏层的映射,每个隐藏层维度大小也不同,避免了过拟合的问题。

图三 全连接 50 epoch
跑了49个epoch,花费50分钟左右,我们可以看到随着训练次数增加,loss值不断减少,不过对于是否是收敛于50%,还不太确定,需要下次跑100个epoch(大概100分钟)不过效果还是很明显的,相比于线性回归的每次epoch都是不稳定的波动,全连接的loss值减少的还是很快的(应该还是没法跟卷积网络相比)。
综合线性回归分类器和全连接回归分类器,以及他们在Minist和Cifar中的表现我们不难看出,对于一个图片,输入值为每个像素点*通道,Minist因为是单通道,所以输入值为1*28*28=728,但在Cifar中,每张图片都是彩色的图片,因此每个图像都有三个通道,在进行Linear层的输入时数据亮就有的三倍的提升(3*32*32),在每次隐藏层的映射时计算量也就过大.
我觉得可以在处理彩色图片前对颜色进行处理,将三通道转换为单通道图像,然而前提就是色彩不在识别的范围内(不能是分辨红色小汽车还是黑色小汽车这样的)
因此对于图片处理(尤其是彩色)还是更倾向于通过卷积神经网络分类器来完成。
以下为运行100个epoch的结果

图四 全连接 100 epoch
事实证明再60次左右就能够收敛,最后loss值再0.0002左右,经过测试正确率为56%,这大概也就是目前我所设计的模型的精度的最高值,如果还想要优化的话,需要更改全连接层,根据网上的讲解,层数越多越好,直到精度不再提升,但是,层数越多,计算量又会大量增加,两者是按指数集增长,因此为了精度精度的提升,而大量增加层数,时间也会大大增加,显然是十分不合理的。
3.3卷积神经网络分类器63%
卷积神经网络顾名思义,就是基于输入的图像根据kernel大小的矩阵求取其卷积,我们可以定义kernel的大小,以及每次移动的步长。在实验中我们的输入为3*32*32的图像,因此我们选择滤波器参数为输入为3,输出为8,kernel为5*5。第二个滤波器参数,输入为8,输出为24,kernel为5*5。

图五 卷积的过程
在padding跟滤波器大小输入输出的大小的选择:
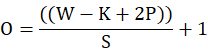
通过以上公式,我们可以根据输入输出的大小,以及选择好的内核的大小和卷积每次移动步长的大小来确定padding的大小,经过这个公式可以知4求1。一般来说输入,内核,步长都是确定好的,我们可以根据输出来用padding来扩充我们的矩阵,也可以根据给定的padding来判断输出的维度大小。
每次卷积过后都要使用max_pooling来对卷积后的结果进行筛选,pooling的大小就设置为常用的2*2,通过这种方法能够将该层内的强特征值保留下来,将弱特征值抛弃,这样还可以避免过拟合,还可以避免无用的参数增加时间复杂度。
而且在我们做窗口滑动卷积的时候,卷积值代表了窗口的特征值,由于每个窗口有很大的重叠,因此卷积结果可能是是冗余的,通过pooling可以减少这种冗余。

图六 Polling的过程
经过pooling之后将其通过Relu函数充当激活函数,Relu还增加了该模型的非线性属性,同时也不会影响该网络中卷积层的接受野,对于Relu函数,在计算时比其他激活函数更高效,还可以抵抗梯度消失效应,之后将经过卷积处理的数据传入到一个两层的全连接层的神经网络之中,在这个三层的全连接网络中,输入的是我们在卷积层中定义的经过卷积核处理的大小为24*5*5的输入,在Linear层中我们从128->64->10将其映射到不同的分类中去,损失函数还是使用CrossEntropyLoss(),将我们的数据通过softmax处理。
图七 卷积 50 epoch
在经过50个epoch的训练下,大概是收敛在0.145左右,如果再训练下去可能效果会更好一些,目前正确率在63%左右,采取的方案是两层卷积层,经过pooling之后,再通过一个3层的全连接网络

图八 卷积 100 epoch
在训练100次之后,虽然loss值不断地减少,并且依旧没有收敛的迹象,在第89次训练中,已经达到0.081,但是最后的测试结果依旧是63%,没有提升,因此可以认为,之后再进行训练也只会导致过拟合,该模型设计只能达到这个正确率,下一步只能去尝试修改超参数以及网络结构。单凭提高训练次数是不行的。
四、神经网络超参数的选择和评估
针对卷积神经网络,之前使用的是5*5的卷积,整个的维度变换如下:
3*32*32->8*28*28->8*14*14->24*10*10->24*5*5->128->64->10
为了验证不同的卷积内核对准确度的影响,将其修改为7*7的内核:
3*32*32->8*26*26->8*14*14->24*6*6->24*3*3->128->64->10
通过使用不同的卷积内核,中间的卷积层输出的维度也就不一样,但是最后在全连接层都要输出为10,用于分类的鉴别。
虽然这两个过滤器的维度不同,一个是5*5一个是7*7,但是设置的过滤器数量却是相同的,我们也可以通过修改过滤器的数量来修改最终提取的特征值的数量。

图九 卷积训练准确度
由上图可以看出,仅仅是把卷积维度修改为7*7,在batch_size为16,训练epoch为40的情况下,对最终的预测精准度并没有产生很大的影响。
通过修改batchsize=4,而卷积维度仍是7*7,训练40个epoch后,最终的预测精度为58%,表面上看精度下降了,但是实际上,当batch_size变小之后,训练的时间就会越大,但是更容易收敛至最优点。散点图分布如下:

图十 卷积 batch_size=4

图十一 卷积 batch_szie=4的准确度
上图为batch_size为4,kernal为7的卷积网络在训练80次后,最终结果的精度,依旧只能到56%。因此我们可以得出一个较为简单的结论,对于卷积网络,batch_size只会影响其收敛速度,单位时间内,收敛的速度会随batch_size的增大而增大,但是对于精度的提升可以忽略不计,由于在设计卷积网络模型时,还增加了池化层和全连接层,最终的精度结果却和之前全连接层的精度差不多,因此我们可以认为,只能通过更改卷积模型整体的网络结构。在卷积层中,每次修改输入输出的滤波器的个数,会相应的产生不同的特征值,但特征也并非越多越好,特征越多也就越容易发生拟合(在训练的过程中,损失值越降越低,但是最终的测试值始终在波动,而非变大)