目录
Python编程与智能车技术创新作业报告
高等理工学院 17376482 王育斌
写在前面
本次大作业我着重展示了以下在爬虫方面的个人心得。内容主要分为三部分:北航计算机学院官网出链图、安居客房价爬虫以及新浪新闻热门关键词词云生成。该三部分代码均在200行以内完成,并且没有重复造轮子。
一.北航计算机学院出链及pagerank算法
1.爬虫核心算法:广度优先
if __name__ == '__main__':
try:
max_depth = 4
base_url = 'http://scse.buaa.edu.cn/'
Cur = SQueue()
Son = SQueue()
relations = {}
# 当前深度,设base_url深度为1
now_depth = 1
# BFS
Cur.enqueue(base_url)
while now_depth <= max_depth and Cur.is_empty() == False:
while Cur.is_empty() is False:
cur_url = Cur.dequeue()
print("try to open: " + cur_url)
handle_url(cur_url)
# 下一深度
now_depth += 1
Cur, Son = Son, Cur
# 处理没出链的url
for link in relations:
if len(relations[link]) == 0:
relations[link][base_url] = 1
except KeyboardInterrupt:
sys.exit(0)每打开一个网址,对其starttag进行解析,找到子网址,子网址入队并且构造父网址与子网址的键值对。
应避免重复打开网址,并且应防止自环。
# 防止自环
if link == self.father:
continue如果是合法的子网址,需要记录父网址、子网址之间的键值对,并且记录父网址有几个该子网址的出链。
Son.enqueue(link)
father_map = relations[self.father]
if link not in father_map:
father_map[link] = 1
else:
father_map[link] += 1之后,按照广度优先算法层层遍历即可。
最后把出链图输出至文件:
with open(road + 'data.txt', 'w') as website_file:
website_file.write(str(relations))
website_file.close()2.继承HTMLParser,编写MyParser类
基本思路:一个网址,需要用Request类完成请求,此时会得到一个request对象,然后使用urlopen函数打开请求,得到response对象。使用response对象的read方法后,将其feed进parser
由于只需要解析网页上的网址,所以在继承HTMLParser类后,只需要重写其handle_starttag和handle_endtag这两个方法即可。其中最关键的是handle_starttag函数

def handle_starttag(self, tag, attrs):
global Son, relations, cur_url
if tag == 'a':
for attribute in attrs:
try:
if attribute[0] == 'href':
link = attribute[1]
# 防止自环
if link == self.father:
continue
pr = request.urlparse(link)
i = pr.path.find('.')
if (i > 0 and pr.path[i + 1:] in ['jpg', 'jpeg', 'gif', 'bmp', 'flv', 'mp4', 'wmv', 'swf',
'css']):
return
if pr.scheme == '':
if pr.path[0] == '/':
link = 'http://' + base_url.netloc + link
else:
if pr.path[3:6] == '../':
link = base_url[0: base_url.rindex('/') + 1] + link[6:]
elif pr.path[0:3] == '../':
link = base_url[0: base_url.rindex('/') + 1] + link[3:]
else:
link = base_url[0: base_url.rindex('/') + 1] + link
elif pr.scheme != 'http' or pr.netloc != base_url.netloc:
return
if link[-1] == '/':
link = link[0: -1]
link = link.strip()
if link == self.father:
continue
Son.enqueue(link)
father_map = relations[self.father]
if link not in father_map:
father_map[link] = 1
else:
father_map[link] += 1
except:
continue 解析网址需要urlparser函数。同时通过MyParser添加自己想要的方法,完成想要的功能。网页上有一些资源是不需要的,比如: jpg, gif, wmv, mp3等等。
对于每一个网址的以及之间的部分,标签为后的为子网址,可以通过字符串处理将子网址分离出来,因此是handle_starttag函数 中只需要对tag为的标签进行处理。
由于并不是所有的子网址的scheme部分都记录有http或https,因此需要对该部分不规范的子网址手动拼接前缀http:// 。
3.利用pagerank算法给网址打分
(1) 创建Markov矩阵
得到了所有爬取到的网站的出链图之后,利用该图,创建一个Markov矩阵S,S∈R^N×N^,Markov矩阵的创建可以有两种,p~ij~表示从第i个网页转移到第j个网页的概率。有两种方式表示:
normal方式:
$$
p_{ij}=\frac{n_j}{\sum_{n=1}^{N_i}{n_k}}
$$
mean方式:
$$
p_{ij}=\frac{1}{N_i}
$$
$$
S=p^T
$$
此时保证了每一行的和都是1
代码实现:
pagefile = []
for key in relations:
if key not in pagefile:
pagefile.append(key)
for nextkey in relations[key]:
if nextkey not in pagefile:
pagefile.append(nextkey)
n = len(pagefile) # S矩阵维数n
# 出链图矩阵S
matrix = []
for i in range(n):
matrix.append([])
if pagefile[i] in list(relations.keys()):
s = 0
for key in relations[pagefile[i]]:
s += relations[pagefile[i]][key]
for j in range(n):
if pagefile[j] in relations[pagefile[i]]:
matrix[i].append(relations[pagefile[i]][pagefile[j]] / s)
else:
matrix[i].append(0)
else:
for j in range(n):
matrix[i].append(1 / n)
S = np.array(matrix)
S = np.transpose(S)(2) 利用Markov过程的收敛性完成pagerank算法
$$
核心公式:A=αS+\frac{1-a}{N}ee^T
$$
其中α为S的权重,可调节,N为所有的网址数,e是一个全为1的向量,e∈R^N^。α用于表示用户习惯,假设用户有α的概率按着当前网站的出链进行网页跳转,1-α的概率对所有网页进行随机跳转。应保证A矩阵每一列的和都是1。
A = a * S + ((1 - a) / n) * np.ones((n, n))(3)利用 Markov 过程的收敛性完成 pagerank 分数的计算
初始化一个向量P~0~∈R^N^。满足:
$$
p=\begin{cases} 1,index(base_url)\0, others\end{cases}
$$
可以随机初始化,但不能有负数。
$$
对任意ε有|P_{n+1}-P_n|<ε,此时Markov过程收敛,得到的P_n为所求的向量。其中P_{N+1}=AP_N
$$
代码实现:
S = np.array(matrix)
S = np.transpose(S)
# 构建转移矩阵
a = 0.85
A = a * S + ((1 - a) / n) * np.ones((n, n))
# 初始化向量P0
P0 = [0 for i in range(n)]
for i in range(n):
if pagefile[i] == base_url:
P0[i] = 1
P0 = np.array(P0).reshape(-1, 1)
e = 0.0000000001 # 迭代精度
delta = np.linalg.norm(P0) # 范数
while delta >= e:
P1 = np.dot(A, P0)
delta = np.linalg.norm(P0 - P1)
P0 = P1
P0 = list(P0)
for i in range(n):
P0[i] = (P0[i][0], i)(4) 按照pagerank分数排序,并输出结果
P0 = sorted(P0, key=lambda x: x[0], reverse=True) # 按照pagerank分数排序
for i in range(20):
print(pagefile[P0[i][1]] + ':' + str(P0[i][0]))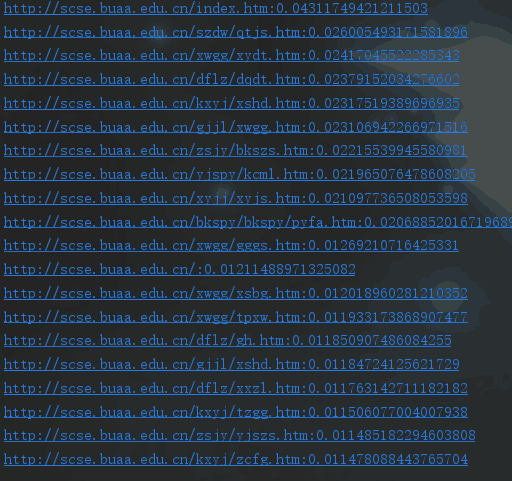
二.安居客房价爬虫
这部分的难点在于:安居客网的反爬措施真的太厉害了......
起初没注意,立即被反爬弄懵:

1.避开网站反爬的措施
1.减小访问网站的频率
import time
time.sleep(3)既然网站会对访问频率进行监测,那就缩短访问频率,避免被当成机器人。
2.每次访问网站使用不同header
首先要手动筛选可用的header,比如:
user_agent = [
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0",
]打开网站前,应设置header(随机抽取)
header = {
'User-Agent': random.choice(user_agent)
}
t = urlopen(Request(url, headers=header))3.每次打开网站前使用不同伪装IP
完成以上两步之后,仍然有可能被“怀疑”是机器人,让你去网站手动拖滑块才能继续执行。为彻底解决这一问题,可以采取伪装IP的方式。
def get_random_ip(ip_list):
proxy_list = []
for ip in ip_list:
proxy_list.append('http://' + ip)
proxy_ip = random.choice(proxy_list)
proxies = {'http': proxy_ip}
return proxies直接从ip池里随机选取一个IP,然后打开网站
t = urllib.urlopen(url, headers=header, proxies=proxy_temp).read()综合采用以上方式,就可以成功地避开网站反爬。
Ⅱ.爬取指定栏目数据
基于广度优先算法的爬虫。首先,我们需要分析网页源代码

我们可以发现,所需要的房价、跌涨幅、年月等信息均存在预于指定栏目中,可以通过BeautifulSoup的find_all方法获取指定标签,而后再进行相应的字符串处理,获取所需信息。
soup = BeautifulSoup(data, 'html.parser')
links = soup.find_all('li', class_='clearfix up')
links.append(soup.find_all('li', class_='clearfix down'))
for item in links:
for info in item:
str1 = str(info)
if '<b>' in str1:
try:
index1 = str1.index('<b>')
index2 = str1.index('</b>')
year_and_month = str1[index1 + 3:index2]
if '月' not in year_and_month:
continue
year = year_and_month[:year_and_month.index('年')]
month = year_and_month[year_and_month.index('年') + 1:year_and_month.index('月')]
worksheet.write(line_index, 0, year)
worksheet.write(line_index, 1, month)
index1 = str1.index('<span>')
index2 = str1.index('</span>')
money = str1[index1 + 6:index2]
indexnow = money.index('元')
money = money[:indexnow]
worksheet.write(line_index, 2, money)
index1 = str1.index('<em>')
index2 = str1.index('</em>')
print(str1[index1 + 4:index2])
up_down = str1[index1 + 4:index2]
if up_down[-1] == '↑':
up_down = up_down[:-2]
print(up_down)
else:
up_down = '-' + up_down[0:-2]
print(up_down)III.xlwt包的使用
我们平时常用的python导出到文件的方法,大多是导出到txt文件。根据作业要求,需要以excel表格的形式保存数据。而python具有直接对excel文件操作的包xlwt,并且功能较为齐全。
以下是对表头进行的操作:
workbook = xlwt.Workbook(encoding='utf-8')
worksheet = workbook.add_sheet('My Worksheet', cell_overwrite_ok=True)
worksheet.write(0, 0, label=U'year')
worksheet.write(0, 1, label=U'month')
worksheet.write(0, 2, label=U'房价')
worksheet.write(0, 3, label=U'涨跌幅')
worksheet.write(0, 4, label=U'省')
worksheet.write(0, 5, label=U'市')
worksheet.write(0, 6, label=U'县区')
worksheet.write(0, 7, label=U'链接')在对数据写入缓存之后,需要再进行保存。
workbook.save('房价信息.xls')这样我们就可以直接观察相对路径下“房价信息.xls”的数据了。
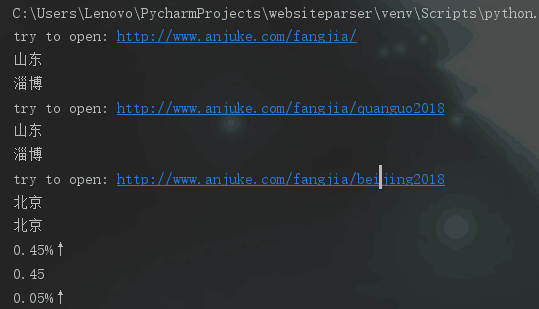
程序运行截图:
三.新浪热门新闻词云
分析新闻热点一直是一个很重要也很有趣的工作,很多可视化内容的展示更是表现出了一段时间内人们兴趣点和关注点的变化。
在实验任务(一)的支持下,已经实现了较好的热门网页排序,可以认为排名靠前的网页更受人们关注,之后的操作就非常简便了。
Ⅰ.新闻关键词的获取
首先利用基于广度优先的爬虫以及pagerank算法对网页进行打分和排序后,需要进行分词操作。jieba包的中文分词是常用的获取关键词的方法,经过我的尝试,发现其对于主题聚类等操作我认为不太灵活。不如直接对网页源代码进行精确地分析操作。
res1.encoding = 'utf-8'
soup1 = BeautifulSoup(res1.text, 'html.parser')
line = str(soup1.select('.keywords')[0])
templist1 = line.split('data-wbkey="')
templist2 = templist1[1].split(',新闻')
keylist = templist2[0].split(',')操作其实比较简单,直接对新闻栏目进行定位,之后进行字符串处理,可精确地获得网页新闻栏目的关键词。
运行截图:

Ⅱ.wordcloud包的使用
这个包确实是个好轮子,方便简洁,只需要完成比较基础的操作就可以实现词云生成。
font = r'FZSTK.TTF'
img = Image.open(r'china.png') # 打开图片
img_array = np.array(img) # 将图片装换为数组
print('picture is making, and you should wait for a while!')
wc = WordCloud(
background_color='pink',
width=8000,
height=6000,
mask=img_array,
font_path=font
)
wc.fit_words(dics) # 绘制图片只需要设定字体、背景图片、背景颜色、画布长宽就可以。
wc.to_file(r'新浪新闻词云.png') # 保存图片利用to_file方法,将生成的词云图片导出。

四.对课程改进的建议
Ⅰ.第一点
python编程方面,希望对代码风格也有一定涉及。
Ⅱ.第二点
除了基础的python编程之外,还希望能更多涉及硬件方面的知识,比如利用单片机的知识,真正动手做一个小车。
III.第三点
可以增加现场课次数,大部分同学可能对自动驾驶汽车方面非常感兴趣。