前言
安装环境是学习ceph的第一步,安装ceph的过程可以学习到非常多ceph的相关概念,尤其可以避免很多后续使用的坑
ceph的安装并没有什么难度,但是在实际操作中,不少新学ceph的同学总会遇到这样那样的部署问题,搞好久,集群也还没跑起来。实际上,ceph部署不应该在学习ceph过程中耗费太多时间和精力,初学时候,能快速部署集群,多接触、操作集群、解决集群产生的问题,才是快速成长的方式,在对ceph有一定程度的熟悉和认识后,再尝试手工部署,甚至编译集群进行安装,或许对ceph会有更深的认识。
环境准备:
测试环境是5台服务器,Centos7.6系统
- ceph-node1 - osd节点和mon节点(3块硬盘)
- ceph-node2 - osd节点和mon节点(3块硬盘)
- ceph-node3 - osd节点和mon节点(3块硬盘)
- ceph-node4 - 部署节点(deploy)、MDS节点、osd节点(3块硬盘)
- ceph-client- 客户端访问节点
首先修改主机名;(所有节点)
hostnamectl set-hostname ceph-node1
hostnamectl set-hostname ceph-node2
hostnamectl set-hostname ceph-node3
hostnamectl set-hostname ceph-node4
hostnamectl set-hostname ceph-client
关闭防火墙和selinux,如果没关;(所有节点)
[root@ceph-node4 ~]# setenforce 0
[root@ceph-node4 ~]# sed -i 's/enforcing/disabled/g' /etc/selinux/config
[root@ceph-node4 ~]# systemctl stop firewalld.service
[root@ceph-node4 ~]# systemctl disable firewalld.service
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
[root@ceph-node4 ~]# reboot
在所有节点创建一个部署、管理ceph集群的用户,并授予sudo权限,不建议使用root来运行ceph (所有节点)
[root@ceph-node4 ~]# useradd cephfsd
[root@ceph-node4 ~]# echo "ceph123"|passwd cephfsd --stdin
Changing password for user cephfsd.
passwd: all authentication tokens updated successfully.
[root@ceph-node4 ~]# echo "cephfsd ALL = (root,ceph) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/cephfsd
cephfsd ALL = (root,ceph) NOPASSWD:ALL
[root@ceph-node4 ~]# chmod 0440 /etc/sudoers.d/cephfsd
修改本地解析文件(所有节点)
[root@ceph-node4 ~]#cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.4.81 ceph-node1
192.168.4.83 ceph-node2
192.168.4.84 ceph-node3
192.168.4.94 ceph-node4
192.168.4.95 ceph-client
配置Ceph源(每个节点,要求都能访问外网)
[root@ceph-node4 ~]# vi /etc/yum.repos.d/ceph.repo
[Ceph]
name=Ceph packages for $basearch
baseurl=http://mirrors.aliyun.com/ceph/rpm-luminous/el7/$basearch
enabled=1
gpgcheck=0
type=rpm-md
gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc
priority=1
[Ceph-noarch]
name=Ceph noarch packages
baseurl=http://mirrors.aliyun.com/ceph/rpm-luminous/el7/noarch
enabled=1
gpgcheck=0
type=rpm-md
gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc
priority=1
[ceph-source]
name=Ceph source packages
baseurl=http://mirrors.aliyun.com/ceph/rpm-luminous/el7/SRPMS
enabled=1
gpgcheck=0
type=rpm-md
gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc
priority=1
完成后在deploy节点使用cephfsd用户登陆,开始下一步工作(所有节点)
[root@ceph-node4 ~]# su - cephfsd
上一次登录:四 6月 20 14:44:14 CST 2019pts/0 上
[cephfsd@ceph-node4 ~]$
简单粗暴,在每个节点上加入ceph源后,先安装epel-release,如果我们不安装,就会缺少部分包,然后再安装ceph(所有节点)
[cephfsd@ceph-node4 ~]$ sudo yum -y install epel-release
[cephfsd@ceph-node4 ~]$ sudo yum -y install ceph ceph-radosgw ceph-deploy
[cephfsd@ceph-node4 ~]$ sudo yum -y install htop sysstat iotop iftop ntpdate net-tools
配置所有节点的时间同步(所有节点)
[cephfsd@ceph-node1 ~]$ sudo ntpdate 192.168.4.43
[cephfsd@ceph-node2 ~]$ sudo ntpdate 192.168.4.43
[cephfsd@ceph-node3 ~]$ sudo ntpdate 192.168.4.43
[cephfsd@ceph-node4 ~]$ sudo ntpdate 192.168.4.43
[cephfsd@ceph-client ~]$ sudo ntpdate 192.168.4.43
部署集群
部署集群主要是用ceph-deploy来进行(接下来都是node4节点)
首先是初始化集群配置
[cephfsd@ceph-node4 ~]$ ceph-deploy new ceph-node1 ceph-node2 ceph-node3
[cephfsd@ceph-node4 ~]$ ls -l
total 16
-rw-rw-r--. 1 cephfsd cephfsd 238 Apr 23 15:03 ceph.conf
-rw-rw-r--. 1 cephfsd cephfsd 5330 Apr 23 15:03 ceph-deploy-ceph.log
-rw-------. 1 cephfsd cephfsd 73 Apr 23 15:03 ceph.mon.keyring
初始化集群主要是生成最基本的配置文件ceph.conf和monitor key文件ceph.mon.keyring,我们要手动修改ceph.conf
[cephfsd@ceph-node4 ~]$ cat ceph.conf
[global]
fsid = 54a9ee80-2339-407d-8fb8-e0b04480b132 ## 集群ID
mon_initial_members = ceph-node1, ceph-node2, ceph-node3 ## mon节点信息
mon_host = 192.168.4.81,192.168.4.83,192.168.4.84 ## mon节点ip
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx ## auth = cephx 开启认证
## 空行不能删
osd_pool_default_size = 2 ## 集群副本数
osd_pool_default_min_size = 1 ## 集群最小副本数
mon_osd_full_ratio = .85 ## osd使用率
注意到,这里new,我们初始化三个monitor,接下来我们创建monitor
[cephfsd@ceph-node4 ~]$ ceph-deploy mon create-initial
[cephfsd@ceph-node4 ~]$ ls -l
total 88
-rw-------. 1 cephfsd cephfsd 71 Apr 23 15:11 ceph.bootstrap-mds.keyring
-rw-------. 1 cephfsd cephfsd 71 Apr 23 15:11 ceph.bootstrap-mgr.keyring
-rw-------. 1 cephfsd cephfsd 71 Apr 23 15:11 ceph.bootstrap-osd.keyring
-rw-------. 1 cephfsd cephfsd 71 Apr 23 15:11 ceph.bootstrap-rgw.keyring
-rw-------. 1 cephfsd cephfsd 63 Apr 23 15:11 ceph.client.admin.keyring
-rw-rw-r--. 1 cephfsd cephfsd 304 Apr 23 15:06 ceph.conf
-rw-rw-r--. 1 cephfsd cephfsd 58107 Apr 23 15:11 ceph-deploy-ceph.log
-rw-------. 1 cephfsd cephfsd 73 Apr 23 15:03 ceph.mon.keyring
mon create-initial会根据ceph.conf进行创建mon,判断monitor都创建成功后,会进行keyring的收集,这些keyring在后续创建其他成员的时候要用到,接下来我们分发集群keyring
[cephfsd@ceph-node4 ~]$ ceph-deploy admin ceph1 ceph2 ceph3
这个操作是将集群的admin.keyring分发给指定的节点,这样这些节点就可以使用ceph命令了,接下来创建mgr
[cephfsd@ceph-node4 ~]$ ceph-deploy mgr create ceph-node1 ceph-node2 ceph-node3
mgr分担了很多原本monitor的工作,目前它也是重要的一个组件,根据集群规模,可以创建2-3个mgr,不过也没有必要太多,接下来可以开始创建osd了
[cephfsd@ceph-node4 ~]$ ceph-deploy osd create --data /dev/sdb ceph-node1
[cephfsd@ceph-node4 ~]$ ceph-deploy osd create --data /dev/sdc ceph-node1
[cephfsd@ceph-node4 ~]$ ceph-deploy osd create --data /dev/sdd ceph-node1
[cephfsd@ceph-node4 ~]$ ceph-deploy osd create --data /dev/sdb ceph-node2
[cephfsd@ceph-node4 ~]$ ceph-deploy osd create --data /dev/sdc ceph-node2
[cephfsd@ceph-node4 ~]$ ceph-deploy osd create --data /dev/sdd ceph-node2
[cephfsd@ceph-node4 ~]$ ceph-deploy osd create --data /dev/sdb ceph-node3
[cephfsd@ceph-node4 ~]$ ceph-deploy osd create --data /dev/sdc ceph-node3
[cephfsd@ceph-node4 ~]$ ceph-deploy osd create --data /dev/sdd ceph-node3
创建后,可以查看集群是否添加成功 (不能使用deploy节点和client节点查看)
[cephfsd@ceph-node1 ~]$ ceph -s
cluster:
id: 9c2268c8-eb8f-4bc1-a6f0-a45802a2955b
health: HEALTH_WARN OK
services:
mon: 3 daemons, quorum ceph-node1,ceph-node2,ceph-node3
mgr: ceph-node1(active), standbys: ceph-node2, ceph-node3
osd: 9 osds: 9 up, 9 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0B
usage: 10.02GiB used, 450.0GiB / 450.0GiB avail
pgs:
osd全部创建成功了
块场景存储
首先创建rbd使用的存储池,因为deploy节点没有admin授权,无法直接使用ceph命令,所以这里切换到ceph-node1节点进行操作
[cephfsd@ceph-node1 ~]$ sudo ceph osd pool create rbd 64 64
pool 'rbd' created
[cephfsd@ceph-node1 ~]$ sudo rbd pool init rbd
[cephfsd@ceph-node1 ~]$ sudo ceph -s
cluster:
id: 9c2268c8-eb8f-4bc1-a6f0-a45802a2955b
health: HEALTH_WARN OK
services:
mon: 3 daemons, quorum ceph-node1,ceph-node2,ceph-node3
mgr: ceph-node1(active), standbys: ceph-node2, ceph-node3
osd: 9 osds: 9 up, 9 in
data:
pools: 1 pools, 64 pgs ## 创建64了pg
objects: 0 objects, 0B
usage: 10.02GiB used, 450.0GiB / 450.0GiB avail
pgs:
```
##### 可以看到,rbd池的pg创建完成了,默认情况下,使用的pool是3副本配置,我们修改成了2副本,测试创建一块rbd试下
```java
[cephfsd@ceph-node1 ~]$ sudo rbd create testrbd --size=10G
[cephfsd@ceph-node1 ~]$ sudo rbd info rbd/testrbd
rbd image 'testrbd':
size 10GiB in 2560 objects
order 22 (4MiB objects)
block_name_prefix: rbd_data.107c6b8b4567
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
flags:
create_timestamp: Thu Jun 20 14:50:29 2019
没有问题
对象存储场景
对象存储需要使用到radosgw,即对象存储网关,所以需要先起一个网关,在起网关的时候,它会检查它需要的存储池是否存在,不存在则自动创建,创建网关在deploy节点上进行
[cephfsd@ceph-node4 ~]$ ceph-deploy rgw create ceph1
创建没问题到集群节点查看
[cephfsd@ceph-node1 ~]$ sudo ceph -s
cluster:
id: 9c2268c8-eb8f-4bc1-a6f0-a45802a2955b
health: HEALTH_WARN OK
services:
mon: 3 daemons, quorum ceph-node1,ceph-node2,ceph-node3
mgr: ceph-node1(active), standbys: ceph-node2, ceph-node3
osd: 9 osds: 9 up, 9 in
rgw: 1 daemon active ##添加了rgw节点
data:
pools: 1 pools, 64 pgs
objects: 0 objects, 0B
usage: 10.02GiB used, 450.0GiB / 450.0GiB avail
pgs:
可以看到,rgw有1个active了,我们看一下pool的情况
[cephfsd@ceph-node1 ~]$ sudo ceph osd pool ls
rbd
.rgw.root
default.rgw.control
default.rgw.meta
default.rgw.log
创建了默认的几个pool,这些池的pg数也是默认的,如果觉得不合适,可以在起rgw前手动创建好
到此集群就搭建完毕
集群MDS节点搭建,在deploy节点创建,
[cephfsd@ceph-node4 ~]$ ceph-deploy mds create ceph-node4
创建两个存储池。MDS需要使用两个pool,一个pool用来存储数据,一个pool用来存储元数据
[cephfsd@ceph-node1 ~]$ ceph osd pool create fs_data 32
pool 'fs_data' created
[cephfsd@ceph-node1 ~]$ ceph osd pool create fs_metadata 32
pool 'fs_metadata' created
[cephfsd@ceph-node1 ~]$ rados lspools
rbd
.rgw.root
default.rgw.control
default.rgw.meta
default.rgw.log
pool1
fs_data
fs_metadata
创建Cephfs
[cephfsd@ceph-node1 ~]$ ceph fs new cephfs fs_metadata fs_data
new fs with metadata pool 8 and data pool 7
[cephfsd@ceph-node1 ~]$ ceph fs ls
name: cephfs, metadata pool: fs_metadata, data pools: [fs_data ]
查看MDS状态
[cephfsd@ceph-node1 ~]$ ceph mds stat
cephfs-1/1/1 up {0=ceph-node3=up:active}
[cephfsd@ceph-node1 ~]$ sudo ceph -s
cluster:
id: 9c2268c8-eb8f-4bc1-a6f0-a45802a2955b
health: HEALTH_WARN OK
services:
mon: 3 daemons, quorum ceph-node1,ceph-node2,ceph-node3
mgr: ceph-node1(active), standbys: ceph-node2, ceph-node3
mds: cephfs-1/1/1 up {0=ceph-node3=up:active}
osd: 9 osds: 9 up, 9 in
rgw: 1 daemon active
data:
pools: 1 pools, 64 pgs
objects: 0 objects, 0B
usage: 10.02GiB used, 450.0GiB / 450.0GiB avail
pgs:
挂载使用CephFS文件系统,使用ceph-fuse工具挂载 (客户端root就可以)
客户端安装ceph-fuse
[root@ceph-client~]$ yum -y install ceph-fuse
创建挂载的文件夹
[rootd@ceph-client~]$ mkdir /cephfs
将key文件发送给client客户端
[root@ceph-node4 ~]$ ceph-deploy admin ceph-client
客户端进行挂载
[root@ceph-client ~]# ceph-fuse -m 192.168.4.81:6789 /cephfs/
ceph-fuse[16770]: starting ceph client
2019-06-20 15:19:58.756083 7fc8691050c0 -1 init, newargv = 0x561a27cd6840 newargc=9
ceph-fuse[16770]: starting fuse
查看挂载情况
[root@ceph-client ~]# df -h /cephfs/
文件系统 容量 已用 可用 已用% 挂载点
ceph-fuse 207G 2.0G 205G 1% /cephfs
[root@ceph-client ~]# df -hT
文件系统 类型 容量 已用 可用 已用% 挂载点
ceph-fuse fuse.ceph-fuse 208G 0 208G 0% /cephfs
写入文件测试,先查看当前osd使用率
[cephfsd@ceph-node1 ~]$ sudo ceph -s
cluster:
id: 9c2268c8-eb8f-4bc1-a6f0-a45802a2955b
health: HEALTH_WARN OK
services:
mon: 3 daemons, quorum ceph-node1,ceph-node2,ceph-node3
mgr: ceph-node1(active), standbys: ceph-node2, ceph-node3
mds: cephfs-1/1/1 up {0=ceph-node3=up:active}
osd: 9 osds: 9 up, 9 in
rgw: 1 daemon active
data:
pools: 1 pools, 64 pgs
objects: 0 objects, 0B
usage: 10.02GiB used, 450.0GiB / 450.0GiB avail ##10G已用
pgs: 288 active+clean
客户端创建一个1G的文件测试
[root@ceph-client cephfs]# dd if=/dev/zero of=/cephfs/1.file bs=1G count=1
记录了1+0 的读入
记录了1+0 的写出
1073741824字节(1.1 GB)已复制,11.9959 秒,89.5 MB/秒
查看OSD使用情况
[cephfsd@ceph-node1 ~]$ sudo ceph -s
cluster:
id: 9c2268c8-eb8f-4bc1-a6f0-a45802a2955b
health: HEALTH_WARN OK
services:
mon: 3 daemons, quorum ceph-node1,ceph-node2,ceph-node3
mgr: ceph-node1(active), standbys: ceph-node2, ceph-node3
mds: cephfs-1/1/1 up {0=ceph-node3=up:active}
osd: 9 osds: 9 up, 9 in
rgw: 1 daemon active
data:
pools: 1 pools, 64 pgs
objects: 0 objects, 0B
usage: 10.02GiB used, 450.0GiB / 450.0GiB avail ##多了2.2G(因为采用两副本,备份了一份)
pgs: 288 active+clean
io:
client: 82.9MiB/s wr, 0op/s rd, 21op/s wr
集群搭建成功
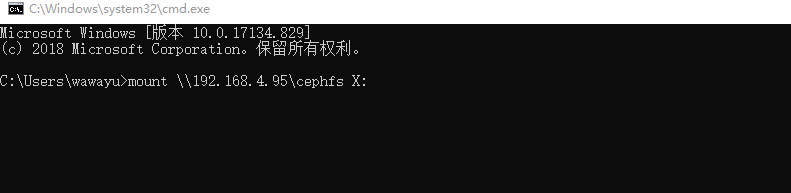
使用NFS挂载windows
[root@ceph-client ~]# vi /etc/exports
/cephfs *(rw,sync,no_root_squash,fsid=54a9ee80-2339-407d-8fb8-e0b04480b132)
[root@ceph-client ~]# exportfs -ar
[root@ceph-client ~]# systemctl restart rpcbind
[root@ceph-client ~]# systemctl restart nfs