目的:利用Python爬虫—利用百度地图API批量获取城市的POI点
经过一定阶段的学习,知道怎么在百度开放控制平台里获取有效地AK值,并且在网页里成功获取了POI的数据,根据得到的数据可以看出都是以json或xml格式的返回形式。
(一)、创建百度开放应用(http://lbsyun.baidu.com/)
①首先要注册百度账号,验证登陆;
②打开控制台;

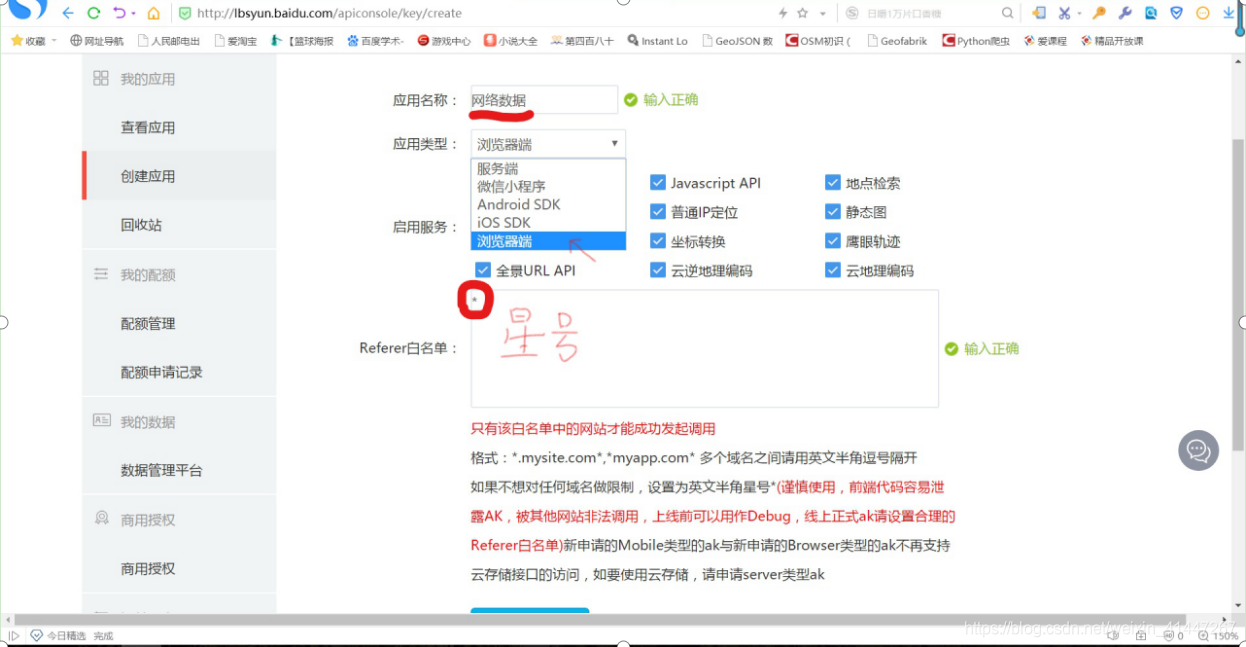
③创建应用,输入应用名称,选择应用类型(浏览器端),
输入refer白名单(星号:*)
,创建应用成功,得到ak值;


④打开开发文档,点击Web服务API;
⑤进行地点检索,得到一些API接口:(其中的“query=”是默认的示例,可以根据自己需要获取的数据做相应的更改)
行政区划区域检索:
http://api.map.baidu.com/place/v2/search?query=ATM机&tag=银行®ion=北京&output=json&ak=您的ak //GET请求
圆形区域检索:
http://api.map.baidu.com/place/v2/search?query=银行&location=39.915,116.404&radius=2000&output=xml&ak=您的密钥 //GET请求
矩形区域检索:
http://api.map.baidu.com/place/v2/search?query=银行&bounds=39.915,116.404,39.975,116.414&output=json&ak={您的密钥} //GET请求
地点详情检索服务:
http://api.map.baidu.com/place/v2/detail?uid=435d7aea036e54355abbbcc8&output=json&scope=2&ak=您的密钥 //GET请求

⑥输入URL,把获取到的ak值放在您的AK处,然后回车,您会得到返回数据;

(二)、利用python编程实现上述的数据
********************************************************************************************
*********************我以贵阳的学校为获取目标写出代码如下:**************************
********************************************************************************************
#-*-coding:UTF-8-*-
import json
import csv
import sys
import requests #导入requests库,这是一个第三方库,把网页上的内容爬下来用的
ty=sys.getfilesystemencoding()
#print(ty)#这个可以获取文件系统的编码形式
import time
lat_1=26.1994
lon_1=106.1327#东经106.1327—107.2864
lat_2=27.3697#北纬 26.1994—27.3697
lon_2=107.2864 #贵阳市的坐标范围
las=1 #给las一个值1
ak='自己申请'
#push=r'D:\python'
out=open('j_str.csv','a',newline='')
csv_write=csv.writer(out,dialect='excel')
print (time.time())
print ('开始')
urls=[] # 声明一个数组列表
lat_count=int((lat_2-lat_1)/las+0.1)
lon_count=int((lon_2-lon_1)/las+0.1)
for lat_c in range(0,lat_count):
lat_b1=lat_1+las*lat_c
for lon_c in range(0,lon_count):
lon_b1=lon_1+las*lon_c
for i in range(0,20):
page_num=str(i)
url='http://api.map.baidu.com/place/v2/search?query=学校&' \
' bounds='+str(lat_b1)+','+str(lon_b1)+','+str(lat_b1+las)+','+str(lon_b1+las)+'&page_size=20&page_num='+str(page_num)+'&output=json&ak='+ak
urls.append(url)
#urls.append(url)的意思是,将url添加入urls这个列表中。
#f=open(r'D:\python\guiyangxuexiao.csv','a',encoding='utf-8')
print ('url列表读取完成')
for url in urls:
time.sleep(10) #为了防止并发量报警,设置了一个10秒的休眠。
print(url)
html=requests.get(url)#获取网页信息
data=html.json() #获取网页信息的json格式数据
print(data)
for item in data['results']:
jname1 = item['province']
jname2 = item['city']
jname3 = item['area']
jname4 = item['name']
jname=jname1+jname2+jname3+jname4
j_uid=item['uid']
jstreet_id=item.get('street_id')
jlat=item['location']['lat']
jlon=item['location']['lng']
jaddress=item['address']
jphone=item.get('telephone')
j_str=(jname,j_uid,jstreet_id,str(jlat),str(jlon),jaddress,jphone)
print(j_str)
csv_write.writerow(j_str)
print("write over")
# f.write(j_str)
print (time.time())
#f.close()
print ('完成')
****************************************************************************************************************************************************************************************
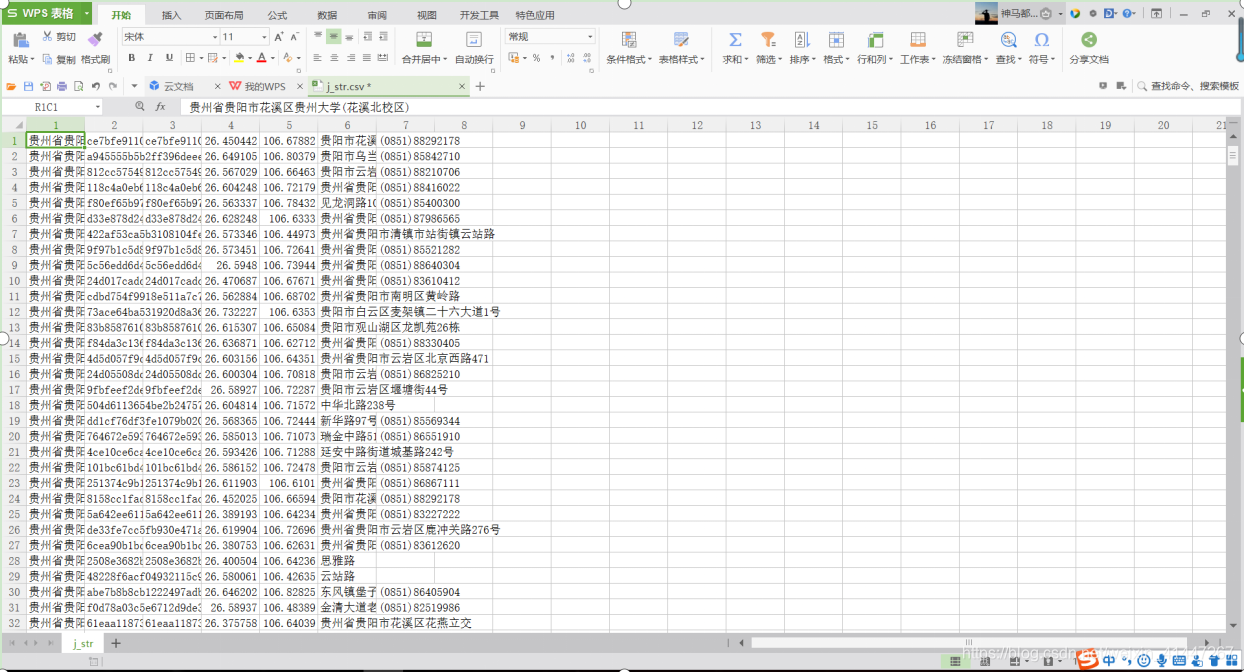
代码可以以CSV格式储存,也可以以TXT格式储存。给代码添加了一行睡眠时间为10秒的代码,给服务器减轻负担。
下面是获取的POI点的数据,一份CSV,一份TXT的。