之前在网上看到有流传VBA编写的版本,不过参数固定,通用性并不强.
趁空闲时间用Python来简单分析制作一个简单的爬虫小脚本。
三个参数主要考虑的,一个是地理位置,一个是关键词,一个是页数。在抓包的过程中对“页数”这个参数纠结了很久,一直没看明白,后面仔细对比才找到猫腻。
先说说地理位置:
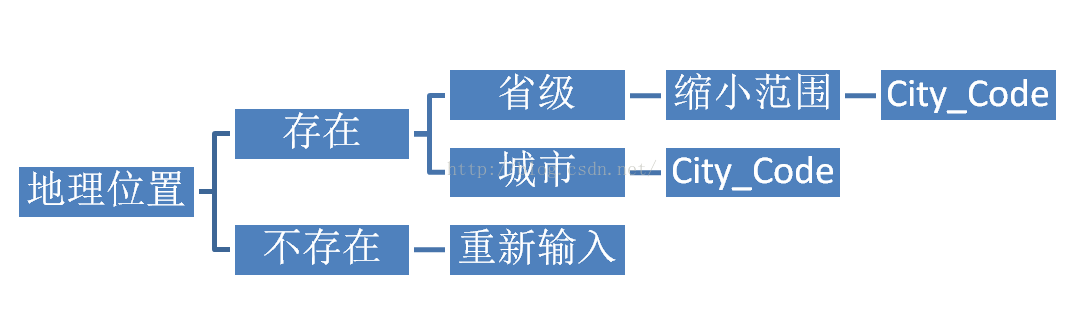
需要按指定地址搜索的时候会需要一个叫City_Code 的参数,输入搜索的时候可以爬取到,输入后有上述的几种情况,不存在会强制要求你重新输入,如果输入“广东”就会定位在广东省内,不过实际搜索关键词的时候页面并不会显示广东所有的结果,而是需要你做二次选择。
在百度的开发平台有城市代码可以直接下载,不过并不完整,有需要的可以自行下载查阅http://developer.baidu.com/map/devRes.htm
parameter = {
"newmap": "1",
"reqflag": "pcmap",
"biz": "1",
"from": "webmap",
"da_par": "direct",
"pcevaname": "pc4.1",
"qt": "con",
"c": City_Code, # 城市代码
"wd": key_word, # 搜索关键词
"wd2": "",
"pn": page, # 页数
"nn": page * 10,
"db": "0",
"sug": "0",
"addr": "0",
"da_src": "pcmappg.poi.page",
"on_gel": "1",
"src": "7",
"gr": "3",
"l": "12",
"tn": "B_NORMAL_MAP",
# "u_loc": "12621219.536556,2630747.285024",
"ie": "utf-8",
# "b": "(11845157.18,3047692.2;11922085.18,3073932.2)", #这个应该是地理位置坐标,可以忽略
"t": "1468896652886"
}pn=0,nn=0 第一页
pn=1,nn=10 第二页
pn=2,nn=20 第三页
pn=3,nn=30 第四页
"nn"参数在调试过程中试过固定的话但是返回的数据是一样的。
url = 'http://map.baidu.com/'
htm = requests.get(url, params=parameter)
htm = htm.text.encode('latin-1').decode('unicode_escape') # 转码
pattern = r'(?<=\baddress_norm":"\[).+?(?="ty":)'
htm = re.findall(pattern, htm) # 按段落匹配
for r in htm:
pattern = r'(?<=\b"\},"name":").+?(?=")'
name = re.findall(pattern, r)
if not name:
pattern = r'(?<=\b,"name":").+?(?=")'
name = re.findall(pattern, r)
print(name[0]) # 名称
pattern = r'.+?(?=")'
adr = re.findall(pattern, r)
pattern = r'\(.+?\['
address = re.sub(pattern, ' ', adr[0])
pattern = r'\(.+?\]'
address = re.sub(pattern, ' ', address)
print(address) # 地址
pattern = r'(?<="phone":").+?(?=")'
phone = re.findall(pattern, r)
print(phone[0]) #电话运行结果:

代码是Python3.4版本编写的,代码很简单,用requests和re就可以得到结果。
再谈谈城市代码,网页GET的参数都是一样的,要获取输入的城市代码的话,可以做个for循环匹配,试过拿0到10000的,结果抓不完,默认顺序是省份开始,然后到市区到县,前端现实是一样的,但代码不同,就像广州,抓出来有几个广州的代码,其实它分为广州市,广州市下面又按区来做了区分,同一个地址名称用不同代码去搜索,结果是不同的。