一、可视化比较
1、示例一

上图描述了在一个曲面上,6种优化器的表现,从中可以大致看出:
① 下降速度:
三个自适应学习优化器Adagrad、RMSProp与AdaDelta的下降速度明显比SGD要快,其中,Adagrad和RMSProp齐头并进,要比AdaDelta要快。
两个动量优化器Momentum和NAG由于刚开始走了岔路,初期下降的慢;随着慢慢调整,下降速度越来越快,其中NAG到后期甚至超过了领先的Adagrad和RMSProp。
② 下降轨迹:
SGD和三个自适应优化器轨迹大致相同。两个动量优化器初期走了“岔路”,后期也调整了过来。
2、示例二
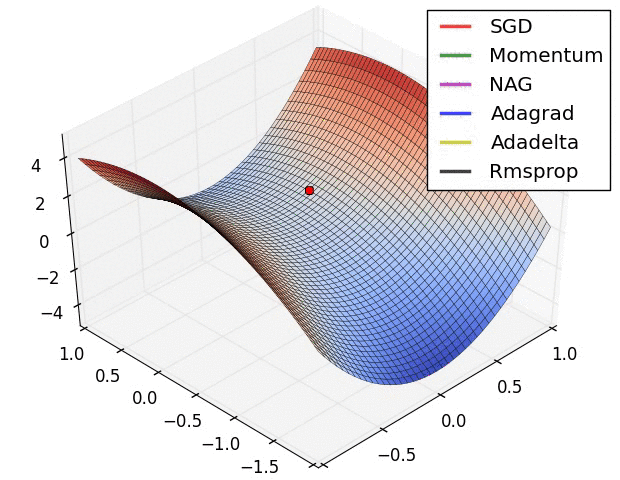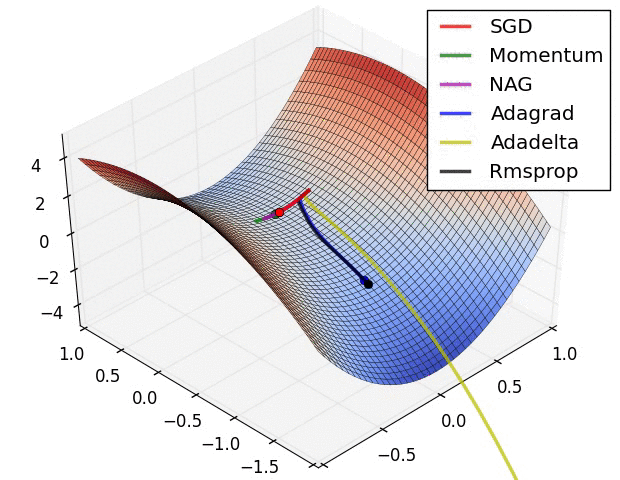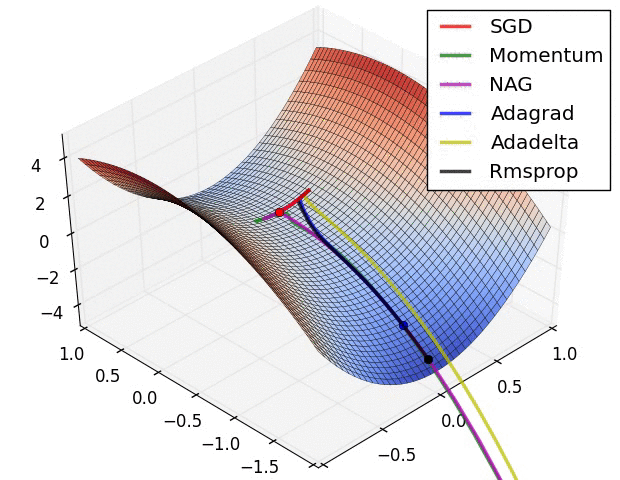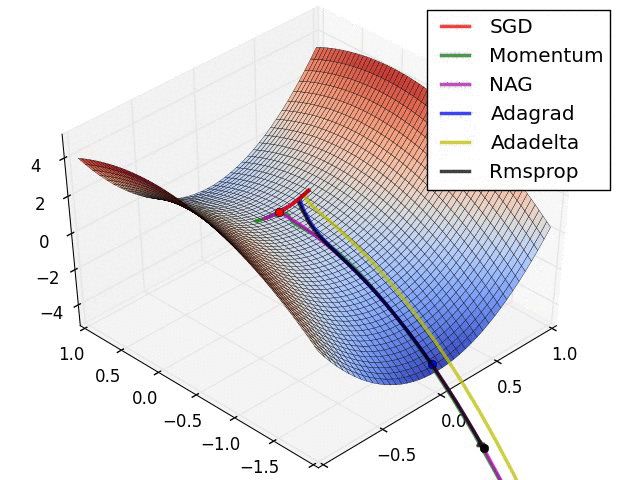
上图在一个存在鞍点的曲面,比较6个优化器的性能表现,从图中大致可以看出:
三个自适应学习率优化器没有进入鞍点,其中,AdaDelta下降速度最快,Adagrad和RMSprop则齐头并进。
两个动量优化器Momentum和NAG以及SGD都顺势进入了鞍点。但两个动量优化器在鞍点抖动了一会,就逃离了鞍点并迅速地下降,后来居上超过了Adagrad和RMSProp。
很遗憾,SGD进入了鞍点,却始终停留在了鞍点,没有再继续下降。
3、示例三
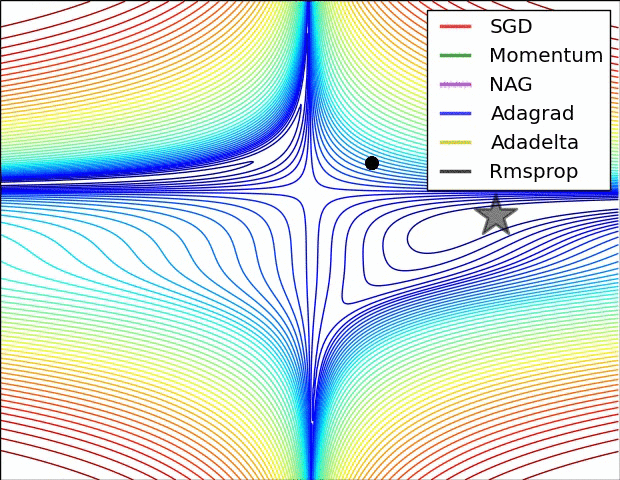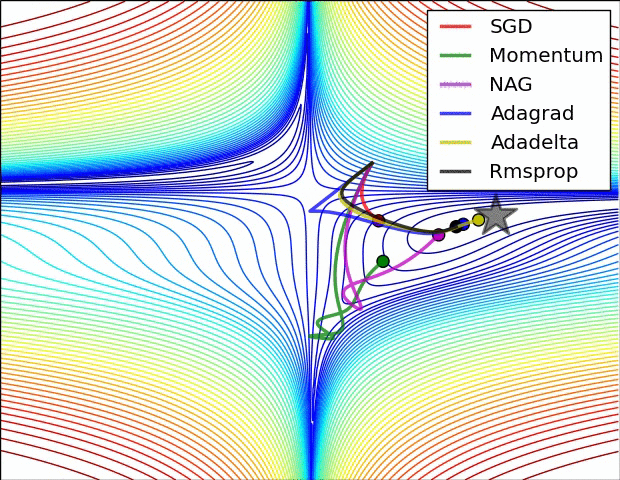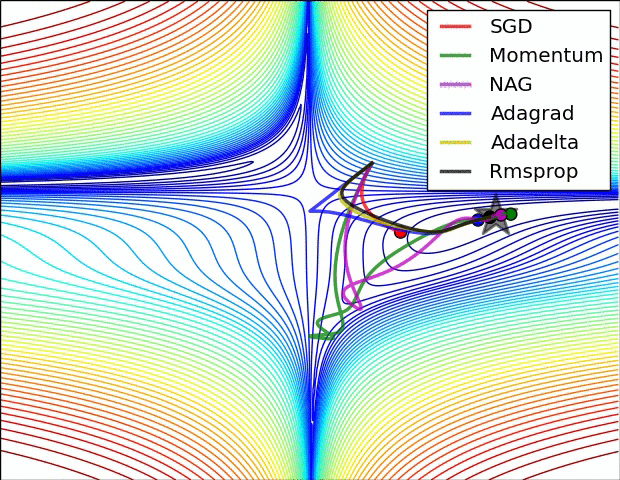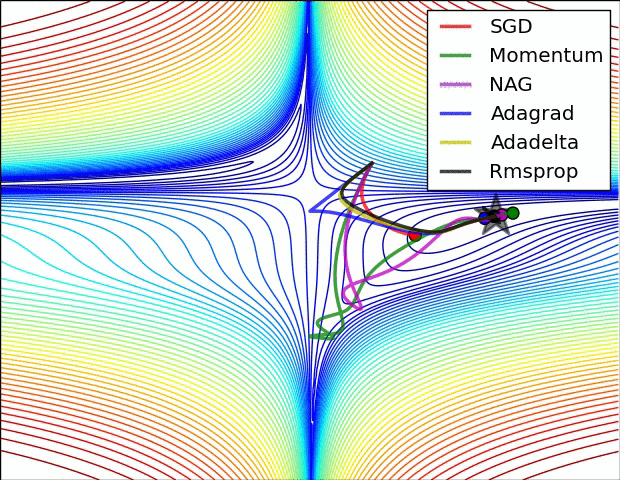
上图比较了6种优化器收敛到目标点(五角星)的运行过程,从图中可以大致看出:
① 在运行速度方面
两个动量优化器Momentum和NAG的速度最快,其次是三个自适应学习率优化器AdaGrad、AdaDelta以及RMSProp,最慢的则是SGD。
② 在收敛轨迹方面
两个动量优化器虽然运行速度很快,但是初中期走了很长的”岔路”。
三个自适应优化器中,Adagrad初期走了岔路,但后来迅速地调整了过来,但相比其他两个走的路最长;AdaDelta和RMSprop的运行轨迹差不多,但在快接近目标的时候,RMSProp会发生很明显的抖动。
SGD相比于其他优化器,走的路径是最短的,路子也比较正。
二、应用于简单分类问题的比较Tensorflow中封装了一系列的优化器:
1. tf.train.GradientDescentOptimizer
2. tf.train.AdadeltaOptimizer
3. tf.train.AdagradOptimizer
4. tf.train.AdagradDAOptimizer
5. tf.train.MomentumOptimizer
6. tf.train.AdamOptimizer
7. tf.train.FtrlOptimizer
8. tf.train.ProximalGradientDescentOptimizer
9. tf.train.ProximalAdagradOptimizer
10. tf.train.RMSPropOptimizer
下面采用选取几种优化器应用于UCI数据集iris.data简单的分类问题。为了简单起见,初始代码可以参考机器学习:过拟合、神经网络Dropout中没使用Dropout之前的代码。修改一行调用优化器的代码:
1、使用SGD优化器
优化器的代码为:
train_step = tf.train.GradientDescentOptimizer(0.2).minimize(loss)
运行结果
第1个训练周期训练集的准确率为:33.3%, 测试集的准确率为:32.2%
第2个训练周期训练集的准确率为:33.3%, 测试集的准确率为:32.2%
第3个训练周期训练集的准确率为:38.9%, 测试集的准确率为:35.6%
第4个训练周期训练集的准确率为:62.2%, 测试集的准确率为:62.7%
第5个训练周期训练集的准确率为:66.7%, 测试集的准确率为:66.1%
第6个训练周期训练集的准确率为:66.7%, 测试集的准确率为:67.8%
第7个训练周期训练集的准确率为:66.7%, 测试集的准确率为:67.8%
第8个训练周期训练集的准确率为:67.8%, 测试集的准确率为:67.8%
第9个训练周期训练集的准确率为:67.8%, 测试集的准确率为:67.8%
第10个训练周期训练集的准确率为:67.8%, 测试集的准确率为:67.8%
2、使用AdaGrad优化器
优化器的代码为:
train_step = tf.train.AdagradOptimizer(0.01).minimize(loss)
运行结果
第1个训练周期训练集的准确率为:33.3%, 测试集的准确率为:32.2%
第2个训练周期训练集的准确率为:35.6%, 测试集的准确率为:32.2%
第3个训练周期训练集的准确率为:66.7%, 测试集的准确率为:66.1%
第4个训练周期训练集的准确率为:66.7%, 测试集的准确率为:66.1%
第5个训练周期训练集的准确率为:66.7%, 测试集的准确率为:66.1%
第6个训练周期训练集的准确率为:66.7%, 测试集的准确率为:66.1%
第7个训练周期训练集的准确率为:66.7%, 测试集的准确率为:67.8%
第8个训练周期训练集的准确率为:66.7%, 测试集的准确率为:67.8%
第9个训练周期训练集的准确率为:67.8%, 测试集的准确率为:69.5%
第10个训练周期训练集的准确率为:68.9%, 测试集的准确率为:69.5%
点评:从运行结果上可以看出使用AdaGrad优化器相比于SGD似乎没有较大的提升。
3、使用Momentum优化器优化器的代码为:
train_step = tf.train.MomentumOptimizer(learning_rate=0.01, momentum=0.9).minimize(loss)
运行结果
第1个训练周期训练集的准确率为:58.9%, 测试集的准确率为:61.0%
第2个训练周期训练集的准确率为:40.0%, 测试集的准确率为:42.4%
第3个训练周期训练集的准确率为:66.7%, 测试集的准确率为:66.1%
第4个训练周期训练集的准确率为:66.7%, 测试集的准确率为:66.1%
第5个训练周期训练集的准确率为:66.7%, 测试集的准确率为:66.1%
第6个训练周期训练集的准确率为:66.7%, 测试集的准确率为:66.1%
第7个训练周期训练集的准确率为:67.8%, 测试集的准确率为:67.8%
第8个训练周期训练集的准确率为:67.8%, 测试集的准确率为:67.8%
第9个训练周期训练集的准确率为:67.8%, 测试集的准确率为:69.5%
第10个训练周期训练集的准确率为:70.0%, 测试集的准确率为:67.8%
点评:Momentum优化器略优于AdaGrad优化器和SGD,但收敛速度要比后两者快(第1-2个训练周期就可以达到60%的准确率)。
4、使用NAG优化器优化器的代码为:
train_step = tf.train.MomentumOptimizer(learning_rate=0.01, momentum=0.9, use_nesterov=True).minimize(loss)
运行结果
第1个训练周期训练集的准确率为:37.8%, 测试集的准确率为:39.0%
第2个训练周期训练集的准确率为:66.7%, 测试集的准确率为:66.1%
第3个训练周期训练集的准确率为:66.7%, 测试集的准确率为:66.1%
第4个训练周期训练集的准确率为:66.7%, 测试集的准确率为:66.1%
第5个训练周期训练集的准确率为:66.7%, 测试集的准确率为:66.1%
第6个训练周期训练集的准确率为:66.7%, 测试集的准确率为:66.1%
第7个训练周期训练集的准确率为:66.7%, 测试集的准确率为:67.8%
第8个训练周期训练集的准确率为:67.8%, 测试集的准确率为:69.5%
第9个训练周期训练集的准确率为:70.0%, 测试集的准确率为:69.5%
第10个训练周期训练集的准确率为:71.1%, 测试集的准确率为:69.5%
点评:NAG和Momentum结果差不多,NAG似乎好那么一点点。
5、使用RMSProp优化器优化器的代码为:
train_step = tf.train.RMSPropOptimizer(0.01).minimize(loss)
运行结果(RMSProp运行结果不稳定,下面是出现比较多的相近结果)
第1个训练周期训练集的准确率为:33.3%, 测试集的准确率为:32.2%
第2个训练周期训练集的准确率为:33.3%, 测试集的准确率为:32.2%
第3个训练周期训练集的准确率为:35.6%, 测试集的准确率为:35.6%
第4个训练周期训练集的准确率为:48.9%, 测试集的准确率为:49.2%
第5个训练周期训练集的准确率为:35.6%, 测试集的准确率为:35.6%
第6个训练周期训练集的准确率为:38.9%, 测试集的准确率为:42.4%
第7个训练周期训练集的准确率为:51.1%, 测试集的准确率为:50.8%
第8个训练周期训练集的准确率为:66.7%, 测试集的准确率为:66.1%
第9个训练周期训练集的准确率为:60.0%, 测试集的准确率为:62.7%
第10个训练周期训练集的准确率为:66.7%, 测试集的准确率为:66.1%
点评:RMSProp优化器的效果有点不理想,而且不稳定。
6、使用Adam优化器
优化器的代码为:
train_step = tf.train.AdamOptimizer(0.001).minimize(loss)
运行结果
第1个训练周期训练集的准确率为:33.3%, 测试集的准确率为:33.9%
第2个训练周期训练集的准确率为:36.7%, 测试集的准确率为:37.3%
第3个训练周期训练集的准确率为:66.7%, 测试集的准确率为:66.1%
第4个训练周期训练集的准确率为:66.7%, 测试集的准确率为:66.1%
第5个训练周期训练集的准确率为:66.7%, 测试集的准确率为:67.8%
第6个训练周期训练集的准确率为:67.8%, 测试集的准确率为:67.8%
第7个训练周期训练集的准确率为:67.8%, 测试集的准确率为:67.8%
第8个训练周期训练集的准确率为:71.1%, 测试集的准确率为:67.8%
第9个训练周期训练集的准确率为:71.1%, 测试集的准确率为:69.5%
第10个训练周期训练集的准确率为:71.1%, 测试集的准确率为:69.5%
点评:Adam优化器的表现可圈可点,比RMSProp优化器要稳定。
7、使用AdaDelta优化器优化器的代码为:
train_step = tf.train.AdadeltaOptimizer(1).minimize(loss)
运行结果
第1个训练周期训练集的准确率为:60.0%, 测试集的准确率为:64.4%
第2个训练周期训练集的准确率为:66.7%, 测试集的准确率为:66.1%
第3个训练周期训练集的准确率为:66.7%, 测试集的准确率为:66.1%
第4个训练周期训练集的准确率为:66.7%, 测试集的准确率为:67.8%
第5个训练周期训练集的准确率为:67.8%, 测试集的准确率为:69.5%
第6个训练周期训练集的准确率为:70.0%, 测试集的准确率为:69.5%
第7个训练周期训练集的准确率为:72.2%, 测试集的准确率为:71.2%
第8个训练周期训练集的准确率为:73.3%, 测试集的准确率为:76.3%
第9个训练周期训练集的准确率为:75.6%, 测试集的准确率为:84.7%
第10个训练周期训练集的准确率为:76.7%, 测试集的准确率为:88.1%
点评:AdaDelta优化器似乎能在本例中夺魁。
三、总评:
通过对比10个训练周期的准确率结果可以看出,其他的优化器(除了RMSProp,有点意外,可能本例不适合)或多或少都优于SGD。从收敛速度上看,两个动量优化器Momentum和NAG的速度相比于除了AdaDelta之外的优化器要快,1-2个周期就能达到60%的准确率。而本例中表现最好的优化器是AdaDelta,无论是收敛速度还是十周期的准确率都比其他优化器要好的多。
四、优化器的选择
那种优化器最好?该选择哪种优化算法?目前还没能够达达成共识。Schaul et al (2014)展示了许多优化算法在大量学习任务上极具价值的比较。虽然结果表明,具有自适应学习率的优化器表现的很鲁棒,不分伯仲,但是没有哪种算法能够脱颖而出。
目前,最流行并且使用很高的优化器(算法)包括SGD、具有动量的SGD、RMSprop、具有动量的RMSProp、AdaDelta和Adam。在实际应用中,选择哪种优化器应结合具体问题;同时,也优化器的选择也取决于使用者对优化器的熟悉程度(比如参数的调节等等)。
2. 应用于简单分类问题的比较
Tensorflow中封装了一系列的优化器: