1 数据集加载
pytorch中数据集加载相关的类主要有 DateSet 和 DateLoader;
数据集加载我打算分两个系列来写:基础版和升级版。基础版的数据加载,数据是现成的,不需要自己写程序进行额外处理,直接调用已有函数即可;升级版本中,涉及到了自己制作数据集的情况,有时候还需要自己实现dataset 类, 主要实现三个函数 __init__, __len__, __getitem__,实现起来会复杂些。接下来,要开始了~
1.1 数据集加载 (基础版)
选择一个现成用于视觉任务的数据集: torchvision。编写一个神经网络来对MNIST 数据集( 0-9 的手写数字集)进行分类。下面开始操作:
1、导入数据集的库;
2、加载 MNIST 数据集;将此数据集分为 train 和 test 两个部分。在执行这个步骤的时候,我们需要将数据强制转换成 tensor 格式,方便 pytorch 处理。
3、将数据分组(batch_size = 10),将数据一组一组的喂给模型训练;
分组的原因:
一是数据集太大了,比如10G,但GPU的RAM没那么大;
另外,机器学习中最快的学习方法就是记忆。但是 RAM 是有限的,而测试时出现的情况几乎是无限的。所以让机械学习每次只读取少量的数据,可以让模型不断的调整其中的参数,从而达到对于一般情况都额能够准确识别的能力。
然后,在我们的训练数据集中,我们通常希望尽可能地随机打乱输入数据,希望数据中没有任何可能导致机器停机的模式。(shuffle=True) 防止在训练时出现连续多个数据都是同一个类别的情况,因为这样的情况容易让机器将所有图片都分到那个它经常见到的类别之中。
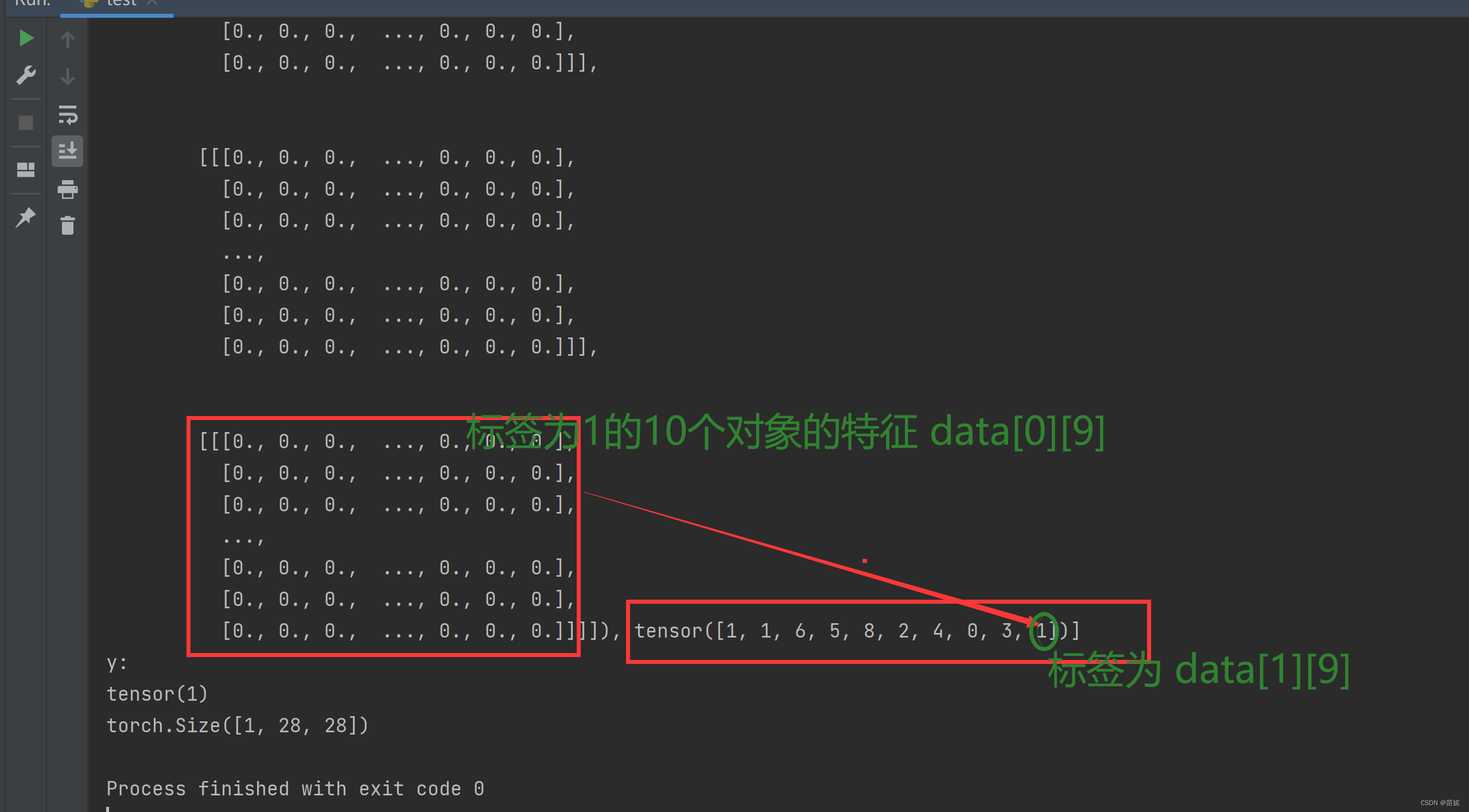
4、使用数据。每次迭代将包含一批 10 个元素(这是我们选择的批量大小)和 10 个类。我们来看一下其中一个组数据:(data[0] 是一堆事物的特征,而 data[1] 是所有的目标。)在这里要注意,随机取得10个元素,不一定能覆盖到10个类,有可能有的类没取到;一般实际情况下,batch_size 要大于10。
5、查看一下训练集中每一个标签都的数据量。用 词典 的数据结构来表示结果。
6、数据平衡。对于我们的模型来说,好的训练需要好的数据。数据平衡是其中一项指标。
想象一下,你有一个猫和狗的数据集。 7200 张图片是狗,1800 张是猫。 这是相当不平衡的。 分类器很可能会发现,通过简单的总是预测狗,它可以非常快速轻松地达到 72% 的准确率。 该模型极不可能从这种情况中恢复。
其他时候,这种不平衡并不那么严重,但仍然足以使模型几乎总是以某种方式预测,除非在最明显的情况下。 无论如何,如果我们能平衡数据集是最好的。
通过“平衡”,确保训练中的每个分类都有相同数量的示例。
# 1、导入数据集的库
import torch
from torchvision import datasets
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt
# 2、加载数据集,root 指的是存放数据集的路径,ToTensor()完成数据类型强制转换,
train_data = datasets.MNIST(root="mnist", train=True, transform=ToTensor(), download=False)
test_data = datasets.MNIST(root="mnist", train=False, transform=ToTensor(), download=False)
# 3、将数据分组,喂给模型训练,并随机打乱数据(shuffle=True)
trainset = torch.utils.data.DataLoader(train_data, batch_size=10, shuffle=True)
testset = torch.utils.data.DataLoader(test_data, batch_size=10, shuffle=False)
# 4、使用数据,每次迭代将包含一批 10 个元素(这是我们选择的批量大小)和 10 个类(data[0] 是一堆事物的特征,而 data[1] 是所有的目标)。
for data in trainset:
print(data)
x, y = data[0][0], data[1][0]
print(y)
# This is a 28x28 image
print(x.shape)
# data[0][0]表示第1个对象的特征
plt.imshow(data[0][0].view(28, 28), cmap='gray')
plt.show()
break
# 5、查看一下训练集中每一个标签都有多少数据。
total = 0
counter_dict = {0:0, 1:0, 2:0, 3:0, 4:0, 5:0, 6:0, 7:0, 8:0, 9:0}
for data in trainset:
Xs, ys = data
for y in ys:
counter_dict[int(y)]+=1
total +=1
print(counter_dict)
print(total)
# 6、数据平衡
for i in counter_dict:
print(f"{i}: {counter_dict[i]/total*10}")以上代码运行结果:
每个标签的数量及比例:
{0: 5923, 1: 6742, 2: 5958, 3: 6131, 4: 5842, 5: 5421, 6: 5918, 7: 6265, 8: 5851, 9: 5949}
60000
0: 0.9871666666666666
1: 1.1236666666666668
2: 0.993
3: 1.0218333333333334
4: 0.9736666666666667
5: 0.9035
6: 0.9863333333333334
7: 1.0441666666666667
8: 0.9751666666666667
9: 0.9915
1.2 数据集加载(升级版)
参考Dataset 加载图片 未完待续