GAN解决了非监督学习中的著名问题:给定一批样本,训练一个系统能够生成类似的新样本。
生成对抗网络主要包含以下两个子网络:
- 生成器:随机生成一个噪声,生成一张图片
- 判别器:判断输入的图片是真图片还是假图片
交替训练:
- 训练判别器时,需要利用真实图片和生成器生成的假图片,判别器希望判别真实图片尽可能为真,判别生成器生成的图片尽可能为假。(判别器希望能够尽可能地判别真假)
- 训练生成器时,只需要利用生成器生成的图片,将生成器生成的图片放到判别器中,判别器判别其尽可能为真。(生成器希望生成的图片尽可能为真)
训练到一定阶段,判别器和生成器会达到一个平衡 。即此时生成器生成的图片足以以假乱真,足以欺骗到判别器了。
对于生成器,其网络结构类似于下面,当然具体的通道数、步长、核尺寸、填充等,可根据具体的实例进行适当修改。

上面网络的输入是一个100维的噪声,输出是一个3x64x64的图片。这里的输入可以看成是一个100x1x1的图片,通过反卷积(转置卷积)慢慢增大为4x4、8x8、16x16、32x32、64x64。这种反卷积的做法可以理解为图片的信息保存于100个向量之中,神经网络根据这100个向量描述的信息,前几步的反卷积先勾勒出轮廓、色调等基础信息,后几步反卷积慢慢完善细节。网络越深,细节越详细。
转置卷积后特征图的尺寸大小为Hout = (Hin-1) x S + K - 2P (S为步长Stride,K为核大小Kernel,P为填充层Padding)。
步骤:

- 定义模型
- 数据加载
- 参数配置
- 模型训练
方法一:使用全连接层神经网络
定义模型:命名为mnist_model.py文件,放到models文件夹下
#判别器
#将图片28*28展开成784,然后通过多层感知器,最后接sigmoid激活得到0到1之间的概率进行二分类
from torch import nn
class NetD(nn.Module):
def __init__(self):
nn.Module.__init__(self)
self.main = nn.Sequential(
nn.Linear(784,256), #输入特征为784,输出为256
nn.LeakyReLU(0.2,inplace=True),
nn.Linear(256,256), #进行一个线性映射
nn.LeakyReLU(0.2,inplace=True),
nn.Linear(256,1),
nn.Sigmoid()
)
def forward(self,x):
x = self.main(x)
return x
#随机输入一个100维的噪声,噪声为均值为0方差为1的高斯分布
class NetG(nn.Module):
def __init__(self):
nn.Module.__init__(self)
self.main = nn.Sequential(
nn.Linear(100,256),#用线性变换将输入映射到256
nn.ReLU(inplace=True),
nn.Linear(256,256),
nn.ReLU(inplace=True),
nn.Linear(256,784),
nn.Tanh() #Tanh激活使得生成数据分布在【-1,1】之间
)
def forward(self,x):
x = self.main(x)
return x数据加载:
from torch.utils import data
from torchvision import datasets
from torchvision import transforms as T
img_transform=T.Compose([
T.ToTensor(),
T.Normalize(mean=([0.5]),std=([0.5]))
])
mnist = datasets.MNIST(root='.data/',train=True,transform=img_transform)
mnist_loader = data.DataLoader(mnist,256,shuffle=True,drop_last=True)参数配置:命名为config.py文件,放到config文件夹下
class Config(object):
data_path = 'data/'#数据集存放路径
num_workers = 4 #多进程加载数据所用的进程数
image_size = 96 #图片尺寸
batch_size = 256 #批量大小
max_epoch = 1000
lr1 = 4e-4 #生成器的学习率
lr2 = 4e-4 #判别器的学习率
nz = 100 #噪声维度
ngf = 64 #生成器feature map数
ndf = 64 #判别器feature map数
save_path = 'imgs/' #生成器图片保存路径
d_every = 1 #每一个batch训练一次判别器
g_every = 5 #每5个batch训练一次生成器
decay_every = 10 #每10个epoch保存一次模型
#预训练模型路径
netd_path = None
netg_path = None
#测试时用的参数
gen_img = 'result.png'
#从128张生成的图片中保存最好的24张
gen_num = 24
gen_search_num = 128
gen_mean = 0 #噪声的均值
gen_std = 1 #噪声的标准差
模型训练:命名为main.py文件
#导入相关包
import fire
import torch as t
from torch.autograd import Variable as V
from torch.utils import data
from torchvision import datasets
from torchvision import transforms as T
from models.DCGAN_mnist_model import NetG,NetD
from config.config import Config
#数据加载
img_transform=T.Compose([
T.ToTensor(),
T.Normalize(mean=([0.5]),std=([0.5]))
])
mnist = datasets.MNIST(root='.data/',train=True,transform=img_transform)
mnist_loader = data.DataLoader(mnist,256,shuffle=True,drop_last=True)
#模型训练
opt = Config()
def train(**kwargs):
for k_,v_ in kwargs.items():
setattr(opt,k_,v_)
#step1:模型
netg = NetG()
if opt.netg_path:
netg.load_state_dict(t.load(opt.netg_path))
netd = NetD()
if opt.netd_path:
netd.load_state_dict(t.load(opt.netd_path))
#step2:定义优化器和损失
optimizer_g = t.optim.Adam(netg.parameters(),lr = opt.lr1)
optimizer_d = t.optim.Adam(netd.parameters(),lr = opt.lr2)
#BCELoss:Binary CrossEntropyLoss的缩写,是CrossEntropyLoss的一个特例,只用于二分类问题
criterion = t.nn.BCELoss()
#真图片label为1,假图片label为0,noises为生成网络的输入噪声
true_labels = V(t.ones(opt.batch_size))
fake_labels = V(t.zeros(opt.batch_size))
for epoch in range(opt.max_epoch):
for i,(datas,labels) in enumerate(mnist_loader):
num_imgs = len(datas)
real_img = V(datas.view(num_imgs,-1))
#训练判别器
#尽可能把真图片判别为1
output = netd(real_img)
error_d_real = criterion(output,true_labels)
#尽可能把假图片判别为0
noises = V(t.randn(num_imgs,opt.nz))
#训练判别器时需要对生成器生成的图片用detach操作进行计算图截断,避免反向传播将梯度传到生成器中,因为训练判别器时我们不需要训练生成器,也就不需要生成器的梯度。
fake_img = netg(noises).detach()
fake_out = netd(fake_img)
error_d_fake = criterion(fake_out,fake_labels)
d_loss = error_d_real + error_d_fake
#梯度清零
optimizer_d.zero_grad()
#反向传播
d_loss.backward()
#梯度更新
optimizer_d.step()
#训练生成器
noises = V(t.randn(num_imgs,opt.nz))
fake_img = netg(noises)
fake_output = netd(fake_img)
#尽可能让判别器把假图片也判别为1
error_g = criterion(fake_output,true_labels)
optimizer_g.zero_grad()
error_g.backward()
optimizer_g.step()
#保存模型
if epoch % opt.decay_every==0:
t.save(netd.state_dict(),'checkpoints/netd_%s.pth' %epoch)
t.save(netg.state_dict(),'checkpoints/netg_%s.pth' %epoch)
#加载训练好的模型,并利用噪声随机生成图片
def generate(**kwargs):
for k,v in kwargs.items():
setattr(opt,k,v)
netg,netd = NetG().eval(),NetD().eval()
noises = t.randn(opt.gen_search_num,opt.nz)
with t.no_grad():
nosies = V(noises)
#加载预训练模型
netd.load_state_dict(t.load(opt.netd_path))
netg.load_state_dict(t.load(opt.netg_path))
#生成图片,并计算图片在判别器的分数
fake_img = netg(noises)
scores = netd(fake_img).data.squeeze()
#挑选最好的某几张
indexs = scores.topk(opt.gen_num)[1].squeeze() #[0]为前k个最大的数,[1]为其对应的索引
from torchvision.utils import save_image
fake_img = fake_img*0.5 + 0.5
fake_img = fake_img.clamp(0,1)
for i in indexs:
save_image((fake_img.data[i].view(28,28)),filename='imgs/%d.png' %(i))
return fake_img
if __name__=='__main__':
fire.Fire()
在命令行输入python main.py train进行训练,训练到一定的epoch可以人为终止,训练完后输入python generate netd_path='checkpoints/netd_50.pth' netg_path='checkpoints/netg_50.pth'
查看迭代50个epoch时生成对抗网络生成的mnist手写字体如下:
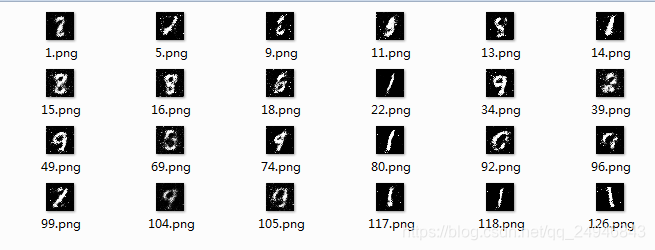
改变netd_path和netg_path路径,分别查看迭代100、150、200个epoch时GAN生成的mnist:



方法二:使用深度卷积神经网络
模型定义:
from torch import nn
#生成器网络
class NetG(nn.Module):
def __init__(self):
nn.Module.__init__(self)
self.main = nn.Sequential(
nn.ConvTranspose2d(100,128,3,1,0,bias=False), #输出3*3
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(128,64,3,2,0,bias=False),#输出7*7
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(64,32,3,2,0,bias=False),#输出15*15
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(32,1,3,2,2,bias=False),#输出单通道的27*27
nn.Tanh() #通过双曲正切函数将输出映射到【-1,1】之间
)
def forward(self,x):
x = self.main(x)
return x
#判别器网络
class NetD(nn.Module):
def __init__(self):
nn.Module.__init__(self)
self.main = nn.Sequential(
nn.Conv2d(1,32,3,2,2,bias=False),#输出为15*15
nn.BatchNorm2d(32),
nn.LeakyReLU(0.2,inplace=True),
nn.Conv2d(32,64,3,2,0,bias=False), #输出为7*7
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2,inplace=True),
nn.Conv2d(64,128,3,2,0,bias=False), #输出为3*3
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2,inplace=True),
nn.Conv2d(128,1,3,1,0,bias=False), #输出位1*1
nn.Sigmoid() #映射为0到1
)
def forward(self,x):
x = self.main(x)
return x数据加载:
#深度卷积网络数据预处理方法
img_transform2=T.Compose([
T.CenterCrop(27),
T.ToTensor(),
T.Normalize(mean=([0.5]),std=([0.5]))
])
mnist = datasets.MNIST(root='.data/',train=True,transform=img_transform2)
mnist_loader = data.DataLoader(mnist,256,shuffle=True,num_workers=4,drop_last=True)模型训练:
#导入相关包
import fire
import torch as t
from torch.utils import data
from torch.autograd import Variable as V
from torchvision import datasets
from torchvision import transforms as T
from models.DCGAN_mnist_model import NetG,NetD
from config.config import Config
#数据加载
opt = Config()
img_transform=T.Compose([
T.CenterCrop(27),
T.ToTensor(),
T.Normalize(mean=([0.5]),std=([0.5]))
])
mnist = datasets.MNIST(root='.data/',train=True,transform=img_transform)
mnist_loader = data.DataLoader(mnist,256,shuffle=True,num_workers=opt.num_workers,drop_last=True)
#模型训练
def train(**kwargs):
for k_,v_ in kwargs.items():
setattr(opt,k_,v_)
#step1:模型
netg = NetG()
if opt.netg_path:
netg.load_state_dict(t.load(None))
netd = NetD()
if opt.netd_path:
netd.load_state_dict(t.load(None))
#step2:定义优化器和损失
optimizer_g = t.optim.Adam(netg.parameters(),lr = opt.lr1)
optimizer_d = t.optim.Adam(netd.parameters(),lr = opt.lr2)
#BCELoss:Binary CrossEntropyLoss的缩写,是CrossEntropyLoss的一个特例,只用于二分类问题
criterion = t.nn.BCELoss()
#真图片label为1,假图片label为0,noises为生成网络的输入噪声
true_labels = V(t.ones(opt.batch_size))
fake_labels = V(t.zeros(opt.batch_size))
for epoch in range(opt.max_epoch):
for i,(datas,labels) in enumerate(mnist_loader):
num_imgs = len(datas)
real_img = V(datas) #用全连接这个地方要改成V(datas.view(num_imgs,-1))
#训练判别器
#尽可能把真图片判别为1
output = netd(real_img)
error_d_real = criterion(output,true_labels)
#尽可能把假图片判别为0
noises = V(t.randn(num_imgs,opt.nz,1,1)) #用全连接这个地方要改成V(t.randn(num_imgs,opt.nz)
fake_img = netg(noises).detach()
fake_out = netd(fake_img)
error_d_fake = criterion(fake_out,fake_labels)
d_loss = error_d_real + error_d_fake
optimizer_d.zero_grad()
d_loss.backward()
optimizer_d.step()
#训练生成器
fake_img = netg(noises)
fake_output = netd(fake_img)
#尽可能让判别器把假图片也判别为1
error_g = criterion(fake_output,true_labels)
optimizer_g.zero_grad()
error_g.backward()
optimizer_g.step()
#保存模型
if epoch % opt.decay_every==0:
print('epoch:{迭代次数}'.format(迭代次数=epoch))
t.save(netd.state_dict(),'checkpoints2/netd_%s.pth' %epoch)
t.save(netg.state_dict(),'checkpoints2/netg_%s.pth' %epoch)
#加载训练好的模型,并利用噪声随机生成图片
def generate(**kwargs):
for k,v in kwargs.items():
setattr(opt,k,v)
netg,netd = NetG().eval(),NetD().eval()
noises = t.randn(opt.gen_search_num,opt.nz)
with t.no_grad():
nosies = V(noises)
#加载预训练模型
netd.load_state_dict(t.load(opt.netd_path))
netg.load_state_dict(t.load(opt.netg_path))
#生成图片,并计算图片在判别器的分数
fake_img = netg(noises)
scores = netd(fake_img).data.squeeze()
#挑选最好的某几张
indexs = scores.topk(opt.gen_num)[1].squeeze() #[0]为前k个最大的数,[1]为其对应的索引
from torchvision.utils import save_image
fake_img = fake_img*0.5 + 0.5
fake_img = fake_img.clamp(0,1)
#fake_img = fake_img.view(-1,1,28,28)
for i in indexs:
save_image((fake_img.data[i].view(28,28)),filename='imgs/%d.png' %(i))
if __name__=='__main__':
fire.Fire()迭代10epoch和20epoch生成的mnist字体如下:
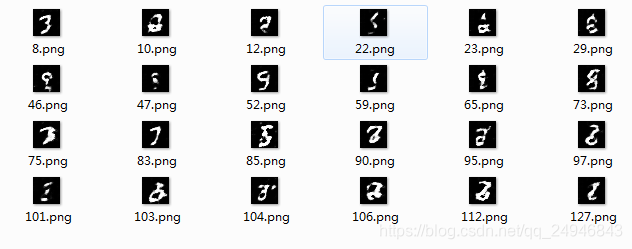

深度卷积神经网络迭代20epoch就能取得不错的效果而且几乎没有噪音,而全卷积神经网络迭代200epoch才取得不错的效果还存在噪音。所以深度卷积神经网络能取得更好的效果。